







系列文章目录
1.tesseract ocr5.3.3源码编译方法一(基于cmake)
2.tesseract ocr5.3.3源码编译方法二(基于cmake+sw)
3.tesseract ocr5.3.3自定义训练
文章目录
前言
提示:以下是本篇文章正文内容,下面案例可供参考
一、准备工作
1.安装tesseract.exe
我这边选择的是 tesseract-ocr-w64-setup-5.3.3.20231005.exe
下载地址:https://digi.bib.uni-mannheim.de/tesseract/
安装好后,目录如下
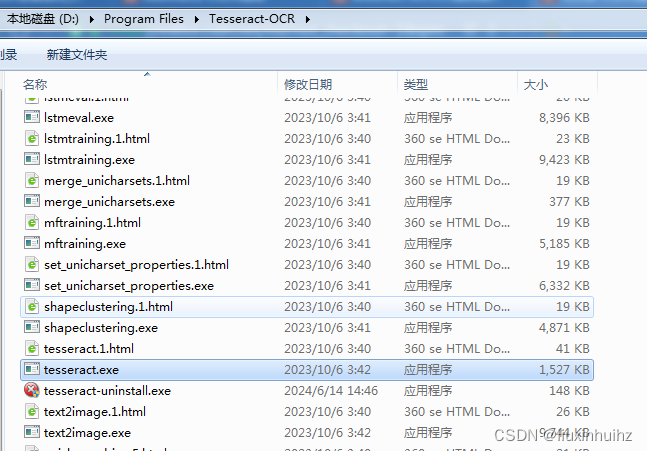
安装完成之后,需要把安装目录(我的安装位置是:D:\Program Files\Tesseract-OCR)加入Path环境变量,以方便后面执行命令行工具。
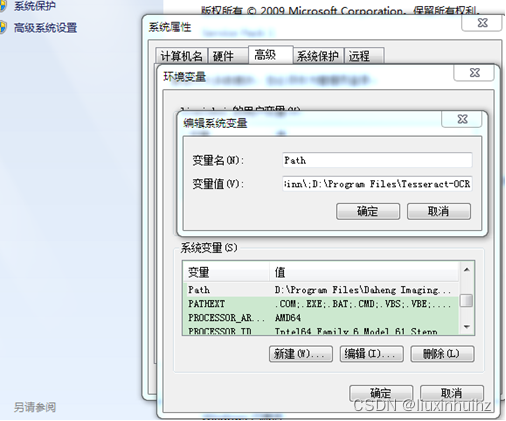
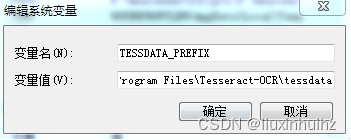
注意:Tesseract-OCR4.0安装之后,需要设置TESSDATA_PREFIX环境变量,指向D:\Program Files \Tesseract-OCR\tessdata;Tesseract-OCR5.0,64位版本则不需要此操作。但我还是加了
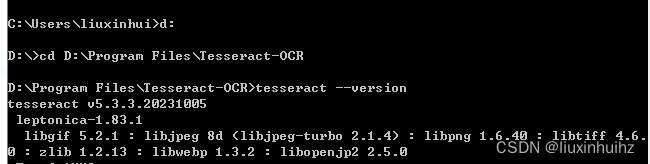
备注:如果不想添加系统环境,那每次使用tesseract之前,先cd 到安装目录,如下图所示
2.下载所需字库到tessdata
下载地址:https://github.com/tesseract-ocr/tessdata_best
国内gitee下载:https://gitee.com/acgnhiki/tessdata_best/tree/main,要识别简体中文需要下载chi_sim.traindata字库。
备注:从tessdata_best下载对应data,是因为后续训练自己的库时,需要从这些.traineddata文件提取.lstm文件,如果从原有tesseract-OCR中的.traineddata文件提取.lstm文件,会造成无法进行训练。
3.安装jTessBoxEditor
jTessBoxEditor是用java写的box编辑器,用于编辑、生成新的字库
下载地址:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
我这边选择的是jTessBoxEditor-2.5.0
下载并解压即可,打开就是双击train.bat即可
备注:如果运行不了,先查看一下是否有java环境,没有的话,则需要先安装java虚拟环境,如安装open jdk等。

二、训练步骤
1.准备训练素材
图片格式必须为tif格式的,如果是bmp格式的,可以先通过windows自带的画图工具来另存为tif格式
2.合成tiff文件
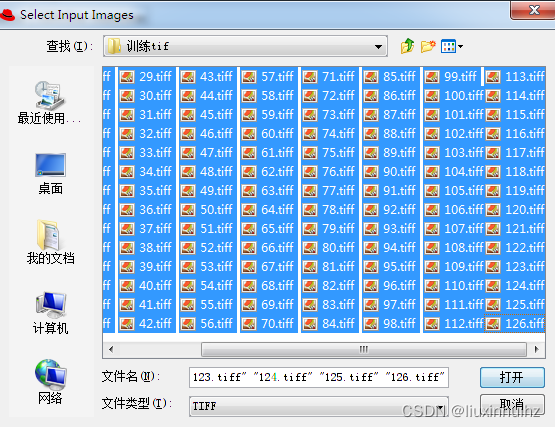
打开jTessBoxEditor,在Tools–>Merge TIFF 然后选择准备好的所有tif图片(注意:全部选中),然后点击打开,然后输入要保存的文件名称,如ahTest,点击保存,这样我们就将多张tif图片merge到了一个文件里面了,如ahTest.tif
3.生成box
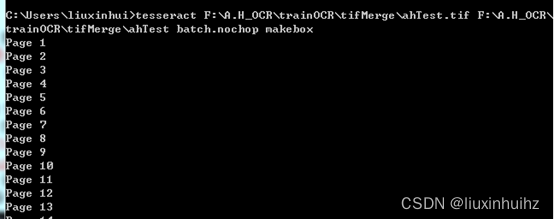
打开cmd.exe窗口,输入如下指令生成box:
tesseract F:\A.H_OCR\trainOCR\tifMerge\ahTest.tif F:\A.H_OCR\trainOCR\tifMerge\ahTest batch.nochop makebox
备注:
输入目录为 F:\A.H_OCR\trainOCR\tifMerge\ahTest.tif
输出目录为 F:\A.H_OCR\trainOCR\tifMerge\ahTest (在此目录下生成名为ahTest.box的文件,该文件记录了识别出来的每个字和它对应的位置坐标)
4.纠正box内容
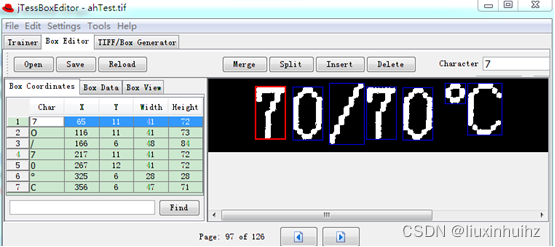
双击train.bat,打开jTessBoxEditor工具,点击Box Editor,然后open打开ahTest.tif(确保ahTest.box文件在同目录)。通过右上角的X,Y,W,H对每个需要改正的字符进行调整,注意调整好后别忘记保存 ,可以每次纠正后都点击一下save。
5.生成lstmf文件
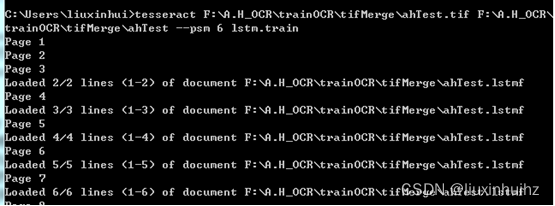
利用.tif和.box文件生成.lstmf文件,打开cmd.exe,输入一下命令:
tesseract F:\A.H_OCR\trainOCR\tifMerge\ahTest.tif F:\A.H_OCR\trainOCR\tifMerge\ahTest.box --psm 6 lstm.train
备注参数含义:
ahTest.tif 上一步生成的.tif 格式的文件
ahTest指明要生成的.lstmf文件的名称
-l eng 表示用到的语言
–psm 6 表示采用的识别模式,通常6 效果会好些
运行后工作目录会多出一个ahTest.lstmf文件
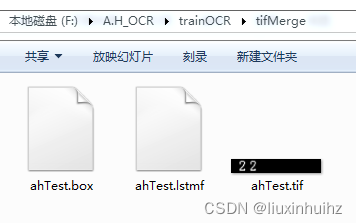
6.提取.lstm文件
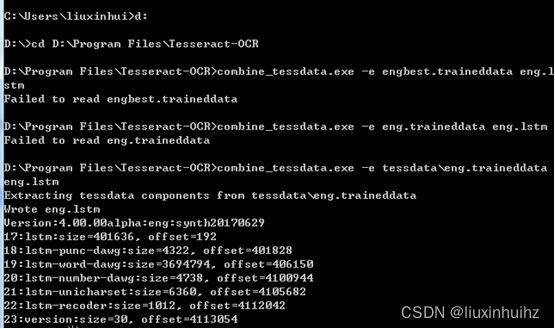
从已有的.traineddata中提取.lstm文件,将下载好的.traineddata文件拷贝到工作目录,我这里是eng.traineddata,命令行工具执行:
combine_tessdata -e tessdata\eng.traineddata eng.lstm

备注:如果出现读取失败
可以先cd 到ocr目录
比如我的安装在d盘先输入d: 回车 然后cd D:\Program Files\Tesseract-OCR 回车 然后在输入
combine_tessdata -e tessdata\eng.traineddata eng.lstm
eng.lstm也可以放置到我们选择的位置
combine_tessdata -e tessdata\eng.traineddata F:\A.H_OCR\trainOCR\tifMerge\eng.lstm
7.设置.lstm文件路径
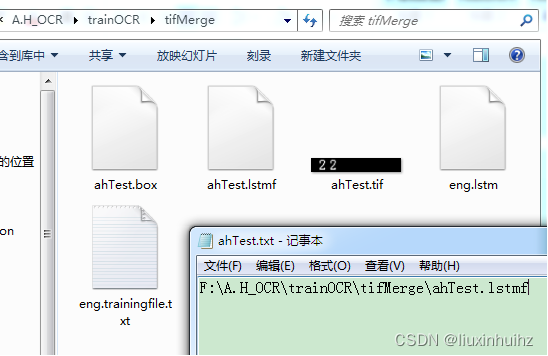
8.训练并生成traindata
在工作目录创建output子目录,使用lstmtraining命令开始训练,这一步生成output_checkpoint文件:
lstmtraining.exe --model_output="F:\A.H_OCR\trainOCR\tifMerge\output\output "
–continue_from=“F:\A.H_OCR\trainOCR\tifMerge\eng.lstm”
–train_listfile=“F:\A.H_OCR\trainOCR\tifMerge\eng.trainingfile.txt”
–traineddata=“F:\A.H_OCR\trainOCR\tifMerge\eng.traineddata” --debug_interval -1 --max_iterations 5000 --target_error_rate 0.01
注意路径冒号不要有空格
–modeloutput 模型训练输出的路径
–continue_from 训练从哪里继续,这里指定从上面提取的 eng.lstm文件,
–train_listfile 指定上一步创建的文件的路径
–traineddata 指定.traineddata文件的路径
–debug_interval 当值为-1时,训练结束,会显示训练的一些结果参数
–max_iterations 指明训练遍历次数
–target_error_rate 0.01 期望错误率
此时命令窗口中会有滚动的训练历程,这一步操作比较耗费时间。
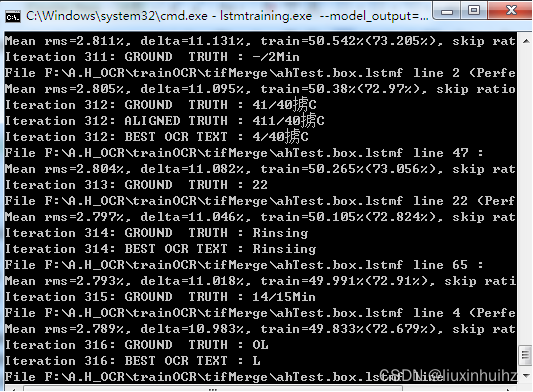
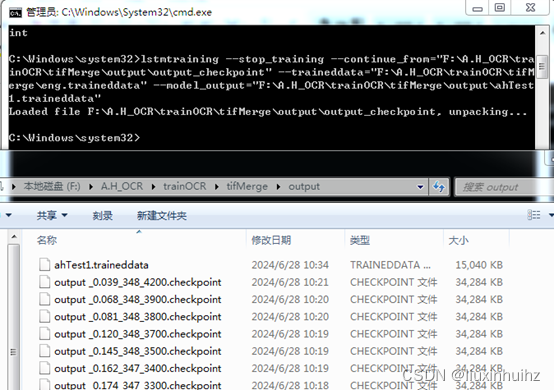
训练结束后,在output文件夹中会生成i一个output_checkpoint文件和多个类似output0.012_3.checkpoint的.checkpoint文件。
将checkpoint文件和.traineddata文件合并成新的.traineddata文件
lstmtraining --stop_training --continue_from=“F:\A.H_OCR\trainOCR\tifMerge\ output\output_checkpoint”
–traineddata=“F:\A.H_OCR\trainOCR\tifMerge\ eng.traineddata” --model_output=“F:\A.H_OCR\trainOCR\tifMerge\output \ahTest1.traineddata”
参数含义:
–stop_training 停止训练
–traineddata=eng.traineddata 训练使用的字体
–continue_from=“F:\A.H_OCR\trainOCR\tifMerge\ output\output_checkpoint”
–model_output=“F:\A.H_OCR\trainOCR\tifMerge\output \ahTest1.traineddata” 生成字体文件的traineddata目录及文件名称
测试应用
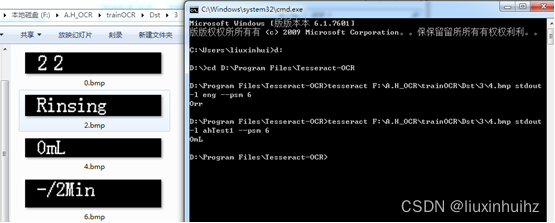
打开cmd 输入 ,可以先用eng看看识别效果,然后用我们训练的在看看效果,如下图所示,使用eng训练数据
tesseract F:\A.H_OCR\trainOCR\Dst\3\4.bmp stdout –l eng –psm 6
结果:0rr
tesseract F:\A.H_OCR\trainOCR\Dst\3\4.bmp stdout –l ahTest1 –psm 6
结果:0mL 还是有效果的。
参考
Tesseract-OCR 5.0LSTM训练流程
https://www.cnblogs.com/nayitian/p/15240143.html
Tesseract-OCR5.0字体训练以及提高准确率、提升训练效率的方法
https://blog.csdn.net/juzicode00/article/details/121538270?spm=1001.2101.3001.4242.1&utm_relevant_index=3















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









