







1.storm概述
在大数据中数据处理有两种基本的方式:批处理和实时流处理,在大数据组件中,Hadoop中的MapReduce可以处理批处理,对应的Strom即为处理实时流数据的组件。
Storm是一个开源的分布式实时计算系统。
2.Storm集群的基本架构
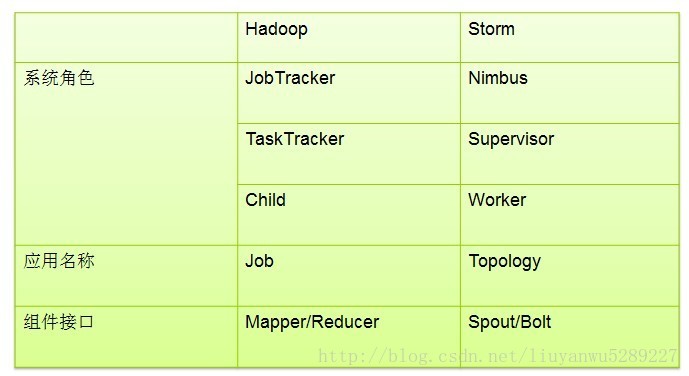
如果你对Hadoop有些了解的话,那么你应该知道Hadoop集群采用的是主从模式(master和slaves)。Hadoop中MapReduce框架是有一个单独运行在主节点上的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。
Storm集群和Hadoop集群很相似。但是不用于Hadoop上运行的MapReduce的job,而storm上运行的是Topology,它们之间的一个关键区别是:一个MapReduce Job最终会结束,而一个Topology会永远运行(除非显式的杀掉它)。
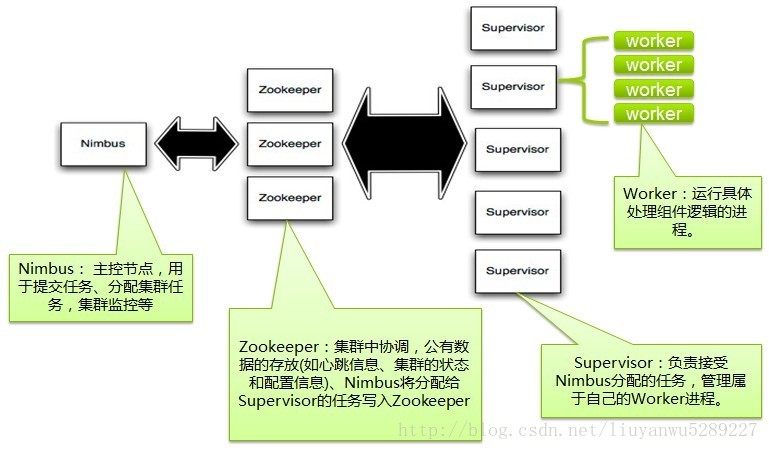
Storm集群中也有两种节点:控制节点(master node)和工作节点(worker node)。控制节点上面运行一个后台程序:Nimbus,它的作用类似于hadoop中的Job Tracker。Nimbus负责在集群中分布代码,分配工作给工作节点,并且监控storm集群状态。
每一个工作节点上运行一个Supervisor的节点(类似于TaskTracker)。Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程。每一个工作进程执行一个Topology(类似Job)的一个子集;一个运行的Topology由运行在很多机器上的很多工作进程Worker(类似Child)组成。
storm topology结构
Storm VS MapReduce
Zookeeper是Nimbus和Supervisor之间的一个协调者。最重要的是,Nimbus进程和Supervisor进程都是快速失败(fail-fast)和无状态的。所有的状态要么在Zookeeper里面,要么在本地磁盘上。也就是说,如果你用kill -9 杀死Nimbus和Supervisor进程,然后再重启它们,集群不会受任何影响,这也是Storm异常稳定的主要原因。
3.storm的基本概念
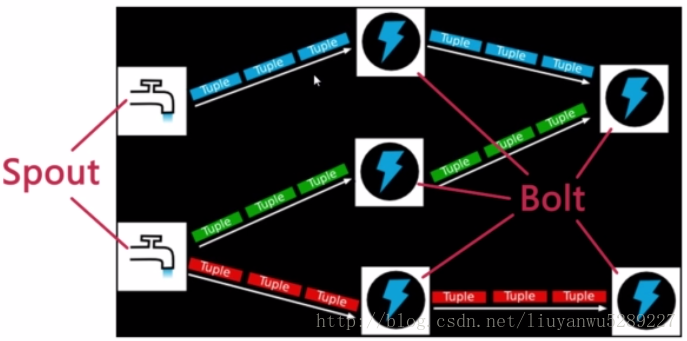
如果抽象理解流式数据处理和storm,将流式数据想象成自来水,自来水从水库源头,到水处理加工厂,再到各个分水站,最后到每家每户的自来水龙头。这整个水路网络可以理解为是一个topology,这个topology决定了水的源头在哪,有多少个水处理加工厂,有多少个分水站等等。其中spout可以理解为水的源头,而bolt即为中间的水处理厂和分水站等。而其中的每一条路径可以理解为stream。
3.1 Spout
Spout是数据流的源头,比如一个spout可以从kafka中作为消费者读取消息并且把这些消息发射成一个流。
通常spout会从外部数据源(队列,kafka,数据库,文件等)读取数据,然后封装成Tuple形式,之后发送到stream中。Spout是一个主动的角色,在接口内部有一个nextTuple函数,storm框架会不停的调用该函数。
3.2 Bolt
Bolt是普通的计算节点,处理输入的stream(Bolt可以接收任意多个输入stream),并产生新的输出stream。Bolt可以执行过滤、函数操作、join、操作数据库等任何操作。Bolt是一个被动的角色,其接口中有一个execute(Tuple input)方法,在接收到消息之后会调用此函数,用户可以在此方法中执行自己的处理逻辑。
3.3 Stream
Stream即为数据流(消息流),是storm里面的关键抽象。一个stream是一个没有边界的tuple序列,而这些tuple序列会以一种分布式的方式并行地创建和处理。Storm提供一些原语来分布式地、可靠地把一个stream传输进一个新的stream。
Tuple的字段类型可以是:integer,long,short,byte,string,double,float,boolean和byte array。也可以自定义类型(前提是可以实现相应的序列化器)。
一个Tuple代表数据流中的一个基本的处理单元,例如一条cookie日志,它可以包含多个Field,每个Field表示一个属性。

Tuple本来应该是一个Key-Value的Map,由于各个组件间传递的tuple的字段名称已经事先定义好了,所以Tuple只需要按序填入各个value,所以就是一个Value List。
一个没有边界的、源源不断的、连续的Tuple序列就组成了stream。
3.4 Topology
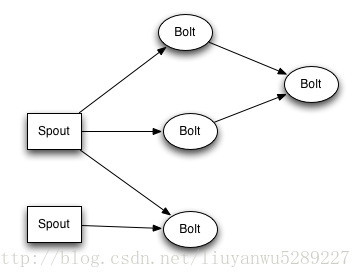
一个Topology是由spouts和bolts组成的图,Topology是storm里面的最高一级的抽象(类似job),Topology里面的每一个处理节点都包含处理逻辑,而节点之间的连接则表示数据流动的方向。
Topology里面的每一个节点都是并行运行的,在topology里面,你可以指定每个节点的并行度,storm则会在集群里分配那么多线程来同时计算。
一个topology会一直执行,知道你手动kill掉他,storm会自动重新执行失败的任务,并且storm可以保证不会有数据丢失(如果开启了高可靠性的话)。
3.5 Grouping
如图中所示的Stream Grouping,上游Spout将tuple通过stream发送给下游的Bolt,可以设置多种的grouping方式。(grouping有些类似SQL中的Group By,用来执行这些计算是怎么分组的)
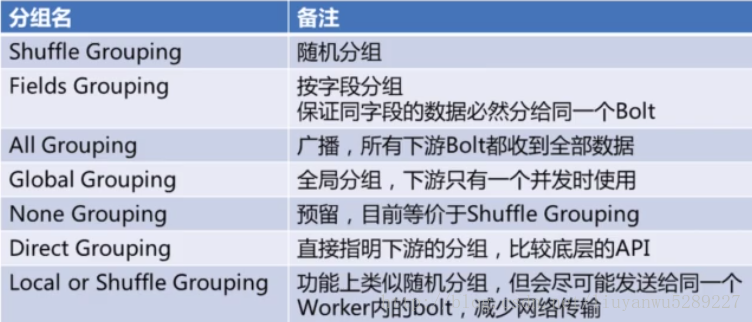
**Fields Grouping 保证同样的字段移动落到同一个Bolt里
3.6 Task&Worker
Task数量:表示每个Spout或Bolt逻辑上有多少个并发。它影响输出结果;
Worker数量:代表总共有几个JVM进程去执行我们的作业;
Executor数量:表示每个Spout或Bolt启动几个线程来运行。

下面代码中的数字表示Executor数量,它不影响结果,影响性能。

Worker 的数量一般在Config中设置,下图代码中的部分代表Worker数量。
(**本地模式中,Worker数不生效,只会启动一个JVM进程来执行作业
**只有在集群模式中设置worker才有效。而且集群模式的时候一定要设置才能体现集群的价值。)
storm例子-WordCount
代码:
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import java.util.StringTokenizer;
/**
* Created by ASUS on 2017/7/14 16:52.
*/
public class WordCountTopologyLyw {
/**
* 创建一个spout类
*/
public static class WordCountSpout extends BaseRichSpout{
SpoutOutputCollector _collector;
Random _rand;
/**
* 初始化
* @param conf
* @param context
* @param collector
*/
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector){
_collector=collector;
_rand = new Random();
}
@Override
public void nextTuple(){
// 睡眠一段时间后再产生一个数据
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 句子数组
String[] sentences = new String[] {
"Kafka Monitor supports Apache Kafka 0.8",
"We advise advanced users to run Kafka Monitor with",
"The full list of configs and their documentation can be",
"found in the code of Config class for respective"
};
// 随机选择一个句子
String sentence = sentences[_rand.nextInt(sentences.length)];
// 发射该句子给Bolt
System.out.print("[--------------]Spout emit=" + sentence + "\n");
_collector.emit(new Values(sentence));
}
/**
* 定义一个字段“word”
* @param declarer
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 定义一个字段word
declarer.declare(new Fields("word"));
}
}
/**
* 创建一个Bolt类,用来分句子
*/
public static class WordSplitBolt extends BaseRichBolt{
OutputCollector _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector){
_collector=collector;
}
@Override
public void execute(Tuple input){
// 接收到一个句子
String sentence = input.getString(0);
// 把句子切割为单词
StringTokenizer iter = new StringTokenizer(sentence);
// 发送每一个单词
while(iter.hasMoreElements()){
_collector.emit(new Values(iter.nextToken()));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer){
// 定义一个字段
declarer.declare(new Fields("word"));
}
}
/**
* 创建一个Bolt类,用来对单词计数
*/
public static class WordCountBolt extends BaseRichBolt{
OutputCollector _collector;
Map<String, Integer> counts = new HashMap<>();
@Override
public void prepare(Map conf,TopologyContext context,OutputCollector collector){
_collector=collector;
}
@Override
public void execute(Tuple input){
// 接收一个单词
String word = input.getString(0);
// 获取该单词对应的计数
Integer count = counts.get(word);
// 计数增加
if(count == null) {
count = 0;
} else {
count++;
}
// 将单词和对应的计数加入map中
counts.put(word, count);
System.out.println(word + ":" + count);
// 发送单词和计数(分别对应字段word和count)
_collector.emit(new Values(word, count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer){
// 定义一个字段
declarer.declare(new Fields("word","count"));
}
}
/**
* 主函数,创建topology
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception{
//创建一个Topology
TopologyBuilder builder=new TopologyBuilder();
// 设置Spout,这个Spout的名字叫做"Spout",设置并行度为5
builder.setSpout("spout", new WordCountSpout(), 5);
// 设置分词Bolt,并行度为8,它的数据来源是spout的
builder.setBolt("split", new WordSplitBolt(), 8).shuffleGrouping("spout");
// 设置计数Bolt,你并行度为12,它的数据来源是split的word字段
builder.setBolt("count", new WordCountBolt(), 12).fieldsGrouping("split", new Fields("word"));
Config conf = new Config();
conf.setDebug(false);
conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
}
}将上面代码打包之后运行
Storm jar WordCount-1.0.jar WordCountTopologyLyw wordcounttopology
打开Storm的UI界面查看添加的这个topology,可以从界面上看到这个topology的详细信息。

从这个图上可以看到这个topology的Workers,executor,tasks的数量等。
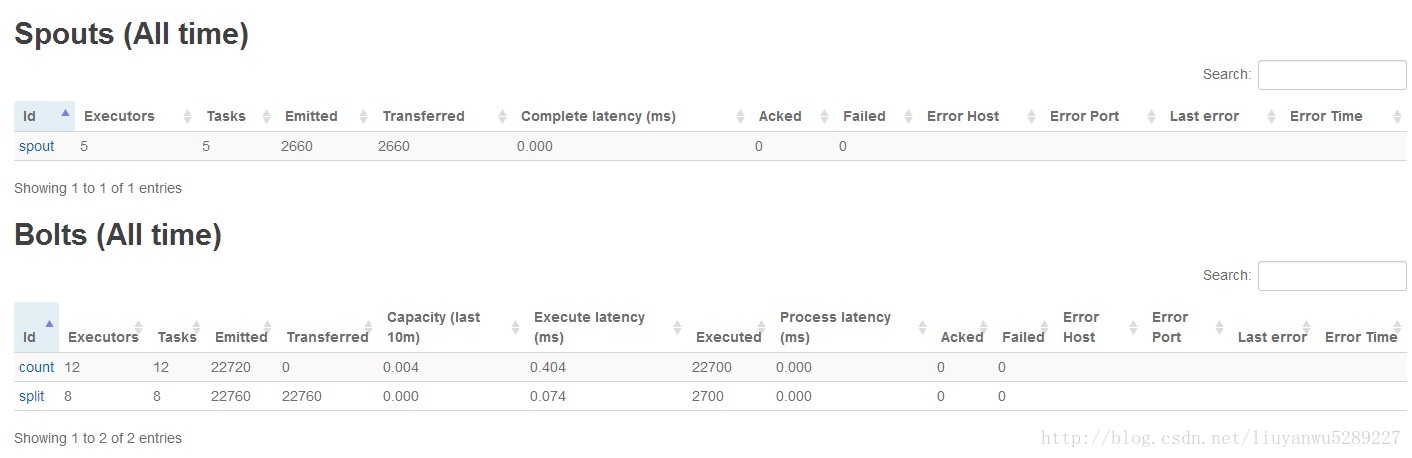
这是Spout和Bolts的信息,可以看到这个topology有1个spout和2个Bolts,两个Bolt的id分别是split和count
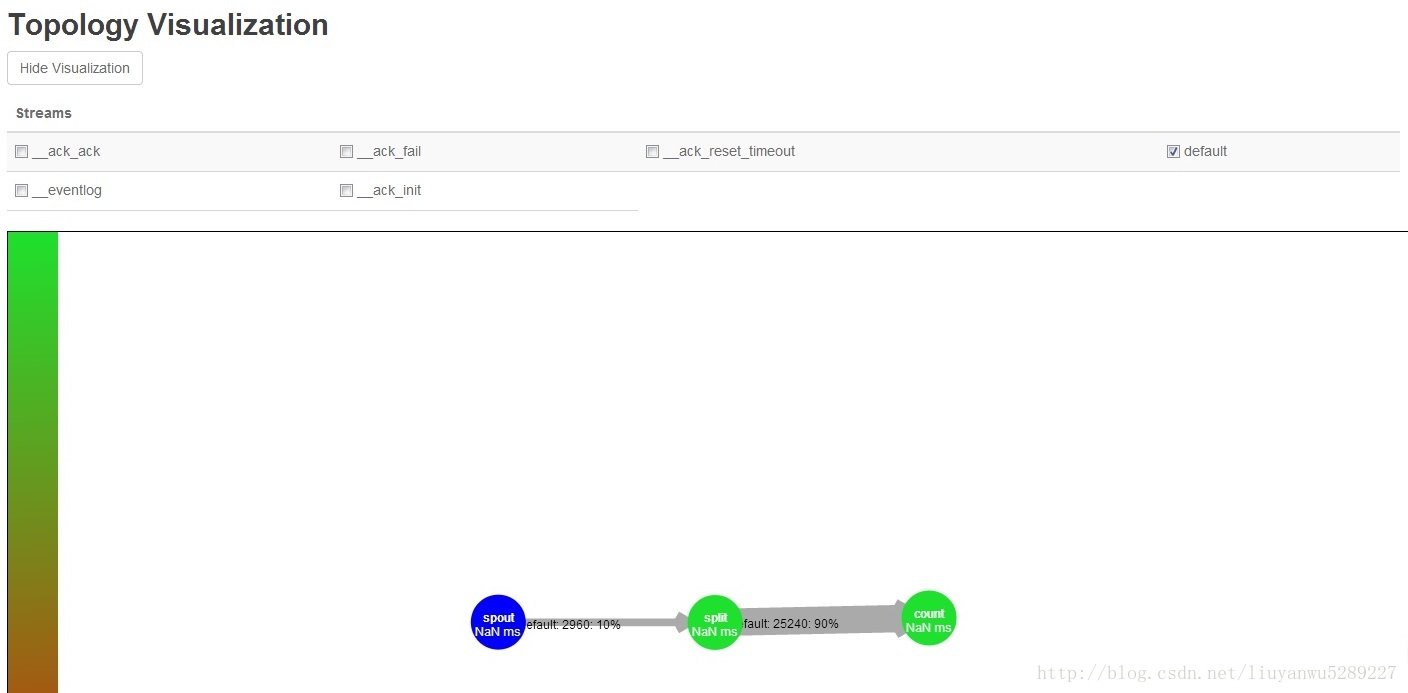
这张图是topology的整体结构。
刚接触storm没多久,这只是对storm学习的笔记,随着工程实践,会对storm有更多的认识和了解,也会持续更新。
参考文档:
《Storm入门学习随记》 http://www.cnblogs.com/quchunhui/p/5370191.html
《storm入门原理介绍》 http://www.cnblogs.com/wuxiang/p/5629138.html
《storm入门》 译者:魏勇















 596
596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









