







解决多卡机器CentOS7安装完CUDA后,出现802错误码:Fabric Manager需要和Driver具有完全一致的版本号。
现象

检查
查看service状态:

显示failed,查看nvidia-smi中的Driver版本:
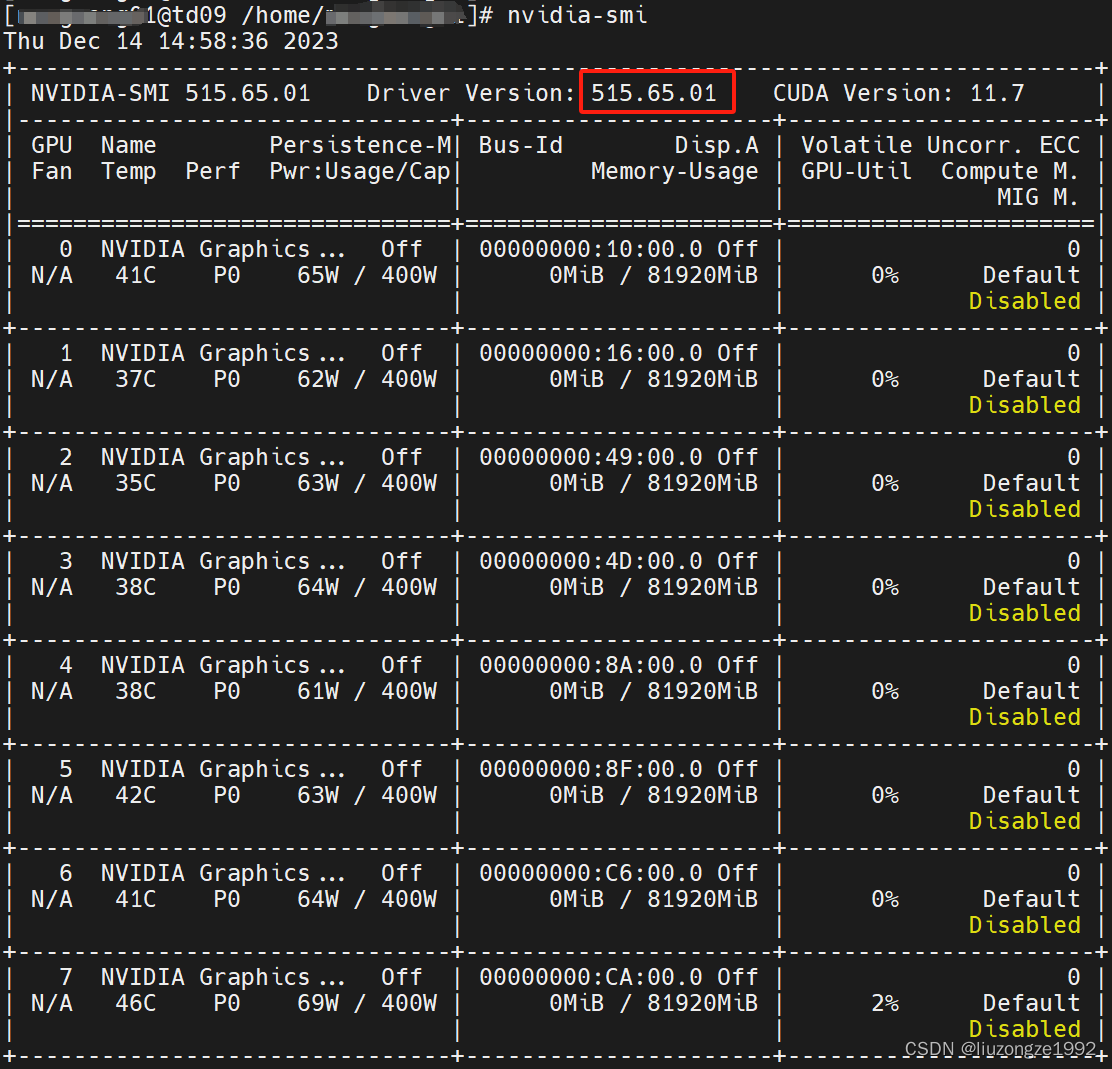
切换版本
sudo yum list installed | grep nvidia
sudo yum remove nvidia-fabric-manager.x86_64
# 注意版本后的-1
sudo yum install -y nvidia-fabric-manager-515.65.01-1
# 启动服务
sudo systemctl disable nvidia-fabricmanager
sudo systemctl enable nvidia-fabricmanager
sudo systemctl start nvidia-fabricmanager
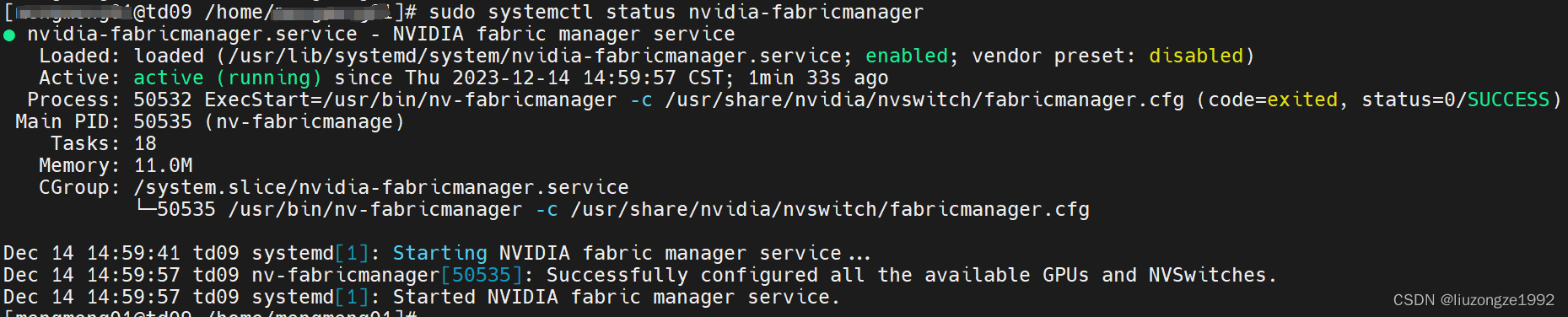
sudo systemctl status nvidia-fabricmanager
确认状态:
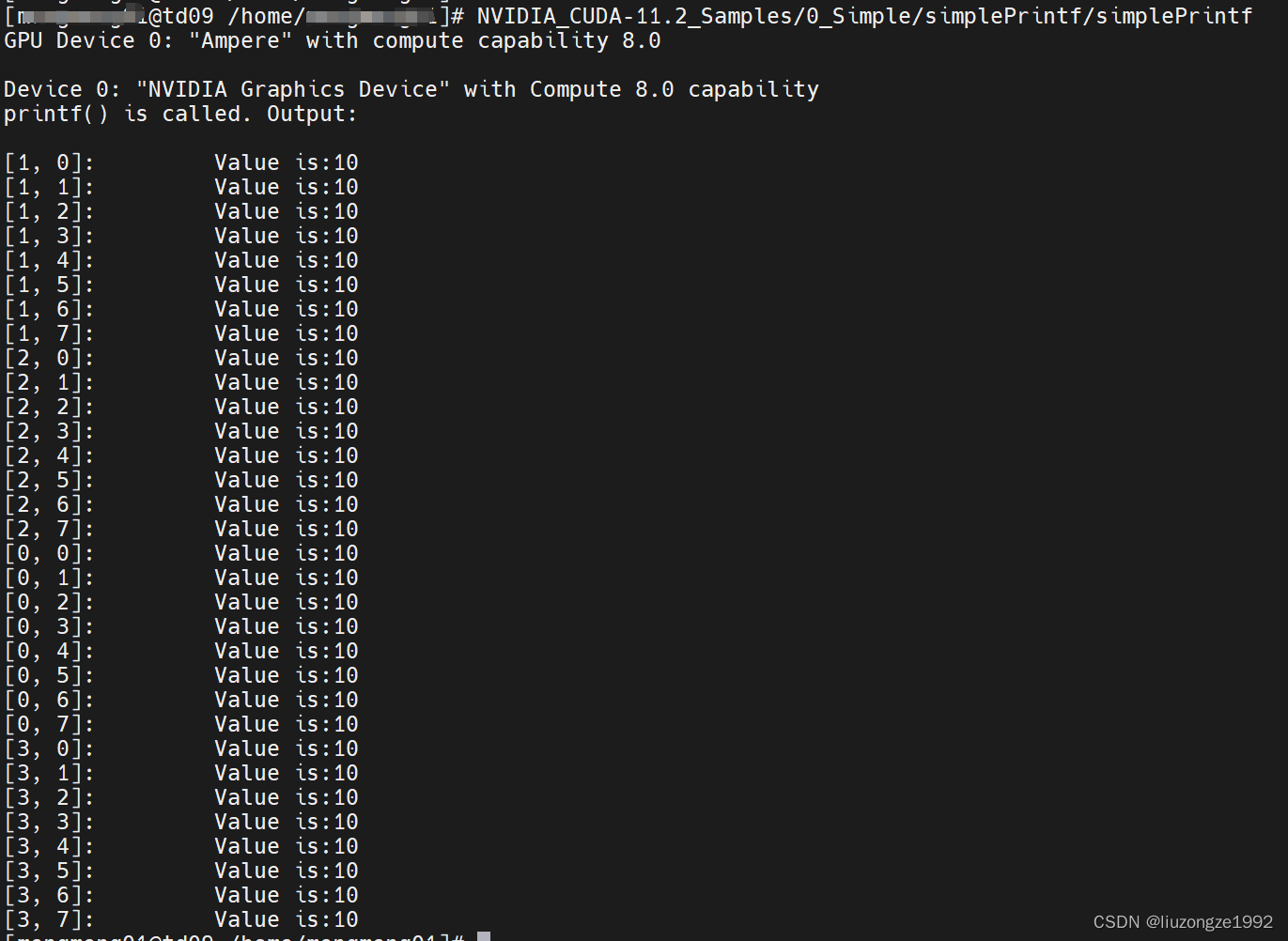
cuda bin可以正常工作:
参考链接
NVIDIA-Fabric Manager安装
NVIDIA trouble shooting docs
On systems with NVSwitch, if you notice the CUDA_ERROR_SYSTEM_NOT_READY error being reported, then make sure that you install the same version of Fabric Manager as the CUDA driver.
Ubuntu 2004
ubuntu 2004上,安装cuda driver后,遇到同样的问题,解决略有差异:
下载deb包安装:
# 相应替换$main_version和$version为指定版本:nvidia-fabricmanager-$main_version_$version-1_amd64.deb
wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2004/x86_64/nvidia-fabricmanager-515_515.65.01-1_amd64.deb
dpkg -i nvidia-fabricmanager-515_515.65.01-1_amd64.deb
之前一步使用apt remove nvidia-fabricmanager-530卸载不彻底:

使用如下命令删除rc状态的包:
状态 rc 表示软件包已被卸载,但是配置文件仍然存在。这通常发生在卸载软件包时选择保留配置文件的情况下。
















 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









