






k8s helm 搭建prometheus
prometheus与zabbix区别:
-
相比较zabbix,prometheus可以自动发现服务,zabbix自己也可以通过脚本自动服务发现端口并监控,但是假如端口挂了,zabbix会变黑,提示历史的端口不在了。也就是在每个pod中都有这个脚本,比较繁琐
-
zabbix从数据库中读取数据,以key-value形式在页面展示,prometheus则是把一个页面的静态资源抓取并展示出来。只有当查询的时候才会使用,而zabbix必须一致运行一个进程来维护
谷歌开发了一个猫头鹰,部署在各个节点,并开启一个监控页,k8s在1.1版本后,把猫头鹰集成了。prometheus对接到每个节点的猫头鹰接口就可以监控到各个节点资源。prometheus实际上就是一个时序数据库。我们可以用grafana监控,grafana只展示页面。另外一个插件也可以通过alter监控告警。grafana也可以告警,看自己需求选择
部署prometheus可以有三种方法:
- 自己写yaml部署
- 通过helm部署
- 通过operator部署
1.1 Operator是什么
Kubernetes Operator 是一种封装、部署和管理 Kubernetes 应用的方法。我们使用 Kubernetes API(应用编程接口)和 kubectl 工具在 Kubernetes 上部署并管理 Kubernetes 应用,可以理解为一个自定义控制器
2.1 相关地址信息
coreos开发的自定义控制器,专门部署prometheus的
Prometheus github 地址:https://github.com/coreos/kube-prometheus2.1.1 组件说明
当我们使用coreos的prometheus控制器时,就会安装下面内容
- 1.MetricServer:是 kubernetes 集群资源使用情况的聚合器,收集数据给 kubernetes 集群内使用,如kubectl,hpa,scheduler等
- 2.PrometheusOperator:是一个系统监测和警报工具箱,用来存储监控数据
- 3.NodeExporter:用于各 node 的关键度量指标状态数据
- 4.KubeStateMetrics:收集kubernetes 集群内资源对象数据,制定告警规则
- 5.Prometheus:采用pull方式收集 apiserver,scheduler,controller-manager,kubelet 组件数据,通过http 协议传输
- 6、Grafana:是可视化数据统计和监控平台
3.1 构建记录
$ git clone https://github.com/coreos/kube-prometheus.git
cd /root/kube-prometheus/manifests因为构建需要很多镜像,有些镜像不能在国内直接下载,我都放到网盘上了
链接:https://pan.baidu.com/s/1nW5Z_aJRiugKL7b_XtteAA
提取码:lepa
//google官方基于php开发的压缩工具
hpa.tar
//prometheues的git工程
kube-prometheus.git.tar.gz
//导入镜像导入
load-images.sh
//镜像
prometheus.tar.gz把镜像解压发送到各个节点
tar zxvf prometheus.tar.gz
mv prometheus load-images.sh /root/
cd /root/;scp -r prometheus/ load-images.sh root@192.168.50.122:/root/
bash load-images.sh
tar zxvf kube-prometheus.git.tar.gz;cd kube-prometheus/manifests
//cd后,进入都是yml文件,这里我们执行后,后面会有几个报错,是因为第一次执行没创建但是有依赖,所以有报错再运行一次apply就可以了
kubectl apply -f ../manifests/
kubectl get pods -n monitoring
kubectl get svc -n monitoring
//到这里我们已经部署好了,但是目前是不可访问你的,因为svc都是clusterIp模式
//为了对外访问,我们可以修改为nodePort或者ingress方式暴露
vim kube-prometheus/manifests/prometheus-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
prometheus: k8s
name: prometheus-k8s
namespace: monitoring
spec:
type: NodePort
ports:
- name: web
port: 9090
targetPort: web
nodePort: 30200
selector:
app: prometheus
prometheus: k8s
//修改grafana的service
vim kube-prometheus/manifests/grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: grafana
name: grafana
namespace: monitoring
spec:
type: NodePort
ports:
- name: http
port: 3000
targetPort: http
nodePort: 30100
selector:
app: grafana
//修改alter告警权限
vim kube-prometheus/manifests/alertmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
alertmanager: main
name: alertmanager-main
namespace: monitoring
spec:
type: NodePort
ports:
- name: web
port: 9093
targetPort: web
nodePort: 30300
selector:
alertmanager: main
app: alertmanager
sessionAffinity: ClientIP
kubectl apply -f kube-prometheus/manifests/
//查看资源使用详情
kubectl top pods -A
kubectl top nodes3.1.1 访问grafana
浏览器打开: 192.168.50.121是集群的Ip地址http://192.168.50.121:30100/login
默认账号密码: admin/admin
点击设置的data source,可以看到已经为我们创建了prometheus的数据源
我们点击数据源可以测试
点击dashboard 导入模板
点击图标,然后点击Home,可以选择查看你想要看的选项
以查看节点为例
选择节点
点击explore,可以看到页面后面对应的pkl语句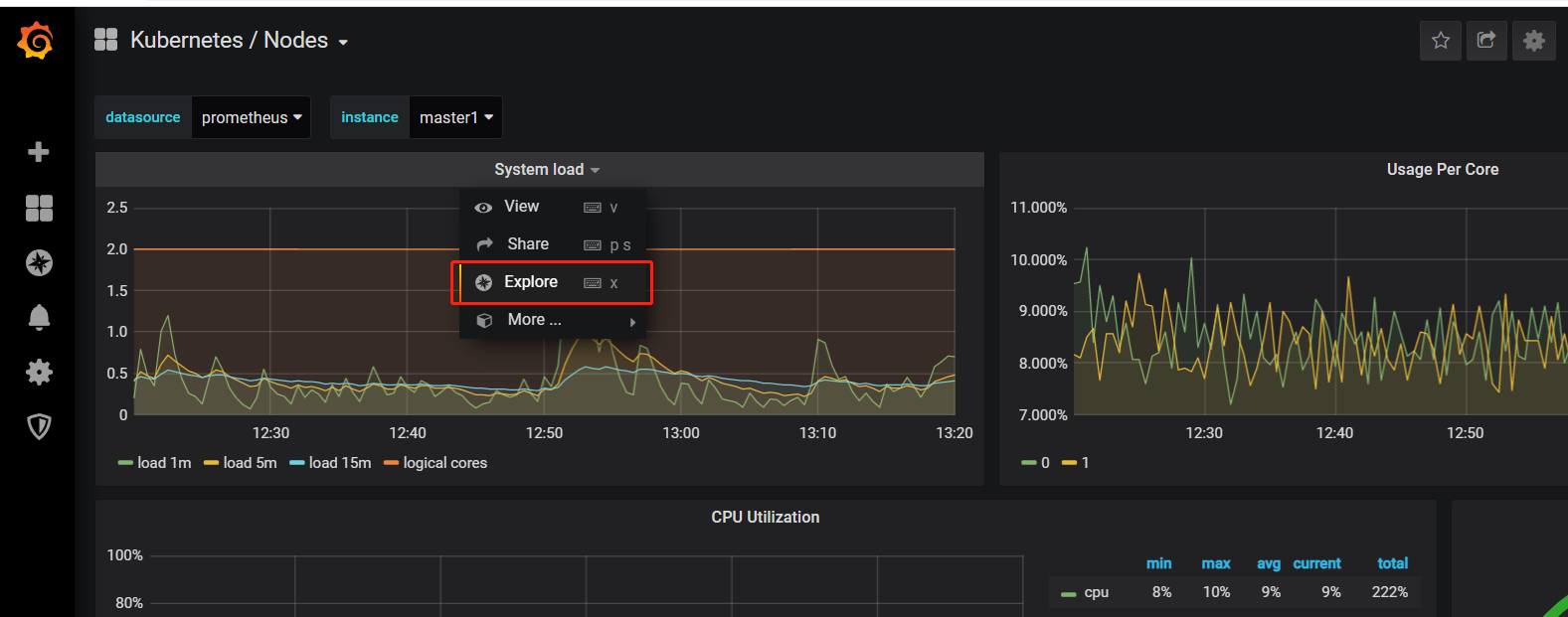
粘贴复制这些pkl语句,可以到alter里面去查询,也可以直接在grafana上修改查询语句

3.1.2 访问alter
浏览器打开: 192.168.50.121是集群的Ip地址http://192.168.50.121:30300/login
4.1 Horizontal Pod Autoscaling
我们上面说的hpa.tar是google官方基于php开发的压缩工具
我们把它拷贝到各个节点,docker load镜像
docker load -i hpa.tar
//重新打个tag,否则他会一直拉最新的下载不下来,注意这里全部节点都要打tag
docker tag wangyanglinux/hpa:latest wangyanglinux/hpa:v1//HPA 可以根据 CPU 利用率自动伸缩 RC、Deployment、RS 中的 Pod 数量
kubectl run php-apache --image=wangyanglinux/hpa:v1 --requests=cpu=200m --expose --port=80
//我们在这里增加负载,对节点进行压测
kubectl run -i --tty work1 --image=busybox /bin/sh
while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
//压测后,kubectl top nodes对节点查看,可能短时间内无法获取状态,因为他需要先被应用监控检测到,然后信息发送给prometheus,prometheus发送给apiserver,我们使用top才能查看到
kubectl top nodes
//创建一个autoscale,基于deployment控制器,名字叫php-apache,定义超过50%的区间了,扩容2-10个
kubectl autoscale deployment php-apache --cpu-percent=50 --min=2 --max=10
//创建后,我们可以查看hpa了
kubectl get hpa
如上图,我们可以看到压测对节点没压力,如果 500%/50%,副本数会从2自动扩容到10















 1852
1852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









