







背景
作为一个java开发者,我们日常工作中经常会碰到选择A实现还是选择B实现的问题,比如我们是选择Gson的json序列化反序列化实现,还是选择使用FastJson的json序列化反序列化实现,最终决定使用方法A和方法B的最重要的依据是比较两者的性能指标,比如吞吐量和响应时间,而此时JMH(the Java Microbenchmark Harness) 就是这样一个能够做基准测试的工具,本文主要是简单记录使用JMH过程中的一些注意点
技术讲解
我们使用以下一个评测RoaringBitMap32位和RoaringBitMap64位创建耗时+操作性能的例子来讲解:
package org.example.jmh;
import org.apache.commons.lang3.RandomUtils;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import org.openjdk.jmh.results.format.ResultFormatType;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import org.roaringbitmap.RoaringBitmap;
import org.roaringbitmap.longlong.Roaring64Bitmap;
import java.util.concurrent.TimeUnit;
@BenchmarkMode({Mode.Throughput, Mode.SampleTime})
@Warmup(iterations = 2, time = 1, timeUnit= TimeUnit.SECONDS)
@Measurement(iterations = 3, time = 5, timeUnit= TimeUnit.SECONDS)
@Threads(1)
@Fork(1)
@State(value = Scope.Benchmark)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class JMHTestFor32VS64BitMap {
@Param(value = {"10000000", "100000000"})
private int length;
@Benchmark
public void testBitMap32(Blackhole blackhole) {
RoaringBitmap r1 = new RoaringBitmap();
RoaringBitmap r2 = new RoaringBitmap();
for (int i = 0; i < length; i++) {
r1.add(RandomUtils.nextInt());
r2.add(RandomUtils.nextInt());
}
r1.and(r2);
r2.or(r1);
blackhole.consume(r1);
blackhole.consume(r2);
}
@Benchmark
public void testBitMap64(Blackhole blackhole) {
Roaring64Bitmap r1 = new Roaring64Bitmap();
Roaring64Bitmap r2 = new Roaring64Bitmap();
for (int i = 0; i < length; i++) {
r1.add(RandomUtils.nextLong());
r2.add(RandomUtils.nextLong());
}
r1.and(r2);
r2.or(r1);
blackhole.consume(r1);
blackhole.consume(r2);
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(JMHTestFor32VS64BitMap.class.getSimpleName())
.resultFormat(ResultFormatType.JSON)
.result("d://result.json")
.build();
new Runner(opt).run();
}
}
部分结果如下图所示:
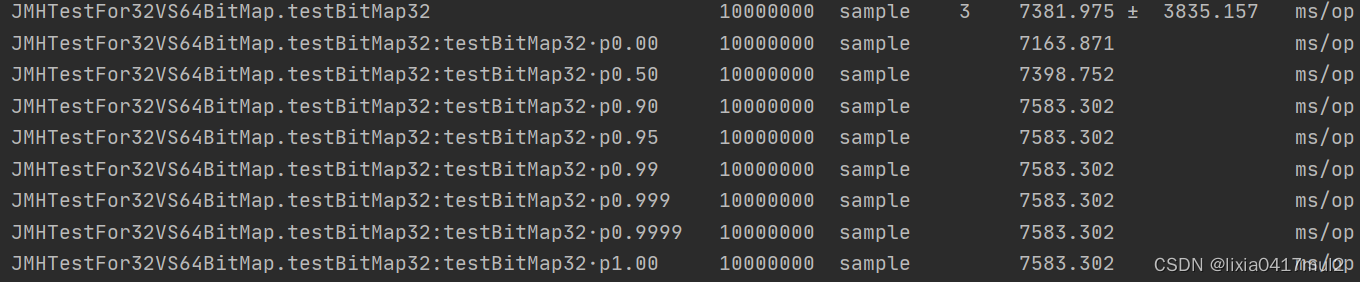
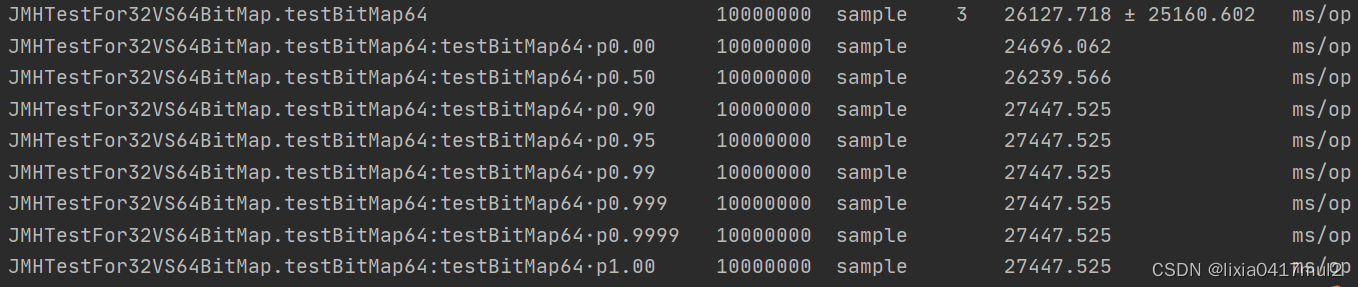
上面两张图可以看出对于Roaring64Bitmap操作来说,99分位的时间是27447ms/op,而Roaring32BitMap操作来说,99分位的时间是7583ms/op,两者的相差还是比较大的
总结
一. @BenchmarkMode({Mode.Throughput, Mode.SampleTime}) 表示我们要进行评测的指标,比如这里表示我们要评估吞吐量和百分位耗时.
二.@Warmup(iterations = 2, time = 1, timeUnit= TimeUnit.SECONDS) 表示在每一轮性能测试前提前迭代预热两次,每次预热的时间是2秒–注:总共进行多少轮测试我们不需要指定,jmh自己决定
三.@Measurement(iterations = 3, time = 5, timeUnit= TimeUnit.SECONDS)表示在每一轮性能测试时,每一轮迭代3次,每次迭代进行5秒–注:总共进行多少轮测试我们不需要指定,jmh自己决定
四.@Threads(1) 表示进行基准测试时使用多少个线程并发进行,这个参数在和@State(BenchMark)进行组合时,有线程安全问题,因为@State(BenchMark)表示变量是实例级别的,也就是多线程共享的,所以这种情况下需要注意线程安全问题
五.@Fork(1)表示进行基准测试的时候使用的进程数,进程之间的数据都是隔离的,所以这个只是表示用多个进程操作时的性能指标
六.@State(value = Scope.Benchmark)这里Benchmark表示类变量是单例的,多个线程会共享这个变量,会有线程安全问题,如果使用Scope.Thread表示类变量是线程级别的,每个线程有自己的实例变量,没有线程安全问题
七 @Param(value = {“10000000”, “100000000”})表示基于多个不同的变量进行基准测试,以便在单次测试中比较不同参数下的性能对比
八 blackhole.consume()这个目的是为了让这个变量不会被代码优化器优化掉,因为代码优化器会优化掉无用的代码,所以保险起见,对于这些变量要么return明确返回,要么添加Blockhold.consume让代码优化器不要优化掉这部分代码.这样测试才会是准确的.
九 此外还有一点是我们可以把结果保存到文件中,然后使用jmh的可视化工具展示性能测试的结果















 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









