







写在前面
中文互联网上缺少关于二项分布估计的知识,而对二项分布参数如何准确且合理的估计的技巧,实际上在商业数据分析领域用处极多。尤其是在互联网企业,算法排名的依据很大程度要依赖这个统计量。我试图抛砖引玉,以steamDB的评分算法为背景,逐步展开讲解,并试图向你证明,为什么要选择这种方法评估数据。
关于评分算法#1#2#3的优劣讨论
简单说下分享及讨论这个评分算法的理由。对现在外卖平台,打分APP上五花八门的排名和排行榜已经感到厌倦了,互联网的同事们,在评估一个视频的好坏时,也比较在意具体的点赞率和完播率指标。我需要一个真实的评价指标。同样的,也厌倦了steam商店里那些毫无用处的好评。同样的,部分游戏先入为主的打分和判断,也同样会因为潜在的,那些众口难调的原因使得优秀的先发游戏被差评埋没(想象下 无人深空no man sky这个游戏的背景,以及它的好评是怎么一步步扭转的,真的是十年如一日坚持更新的制作组,以及越来越充实的内容,最终赢得了各方的赞誉。毕竟几年前它刚出来时候,真的很烂)
这个算法的介绍如下:
T o t a l R e v i e w s = P o s i t i v e R e v i e w s + N e g a t i v e R e v i e w s Total Reviews = Positive Reviews + Negative Reviews TotalReviews=PositiveReviews+NegativeReviews
R e v i e w S c o r e = P o s i t i v e R e v i e w s T o t a l R e v i e w s Review Score = \frac{Positive Reviews}{Total Reviews} ReviewScore=TotalReviewsPositiveReviews
R a t i n g = R e v i e w S c o r e − ( R e v i e w S c o r e − 0.5 ) ∗ 2 − l o g 10 ( T o t a l R e v i e w s + 1 ) Rating = Review Score - (Review Score - 0.5)*2^{-log_{10}(Total Reviews + 1)} Rating=ReviewScore−(ReviewScore−0.5)∗2−log10(TotalReviews+1)
steamDB评分算法的作者是如此解释的,我在此尽可能的尊重原作者的思路和想法,并针对性的对一些可能存疑的点进行补充。
推导过程如下,
-
现行的steam排序算法比较糟糕,评价一个游戏是“特别好评”,“好评”,“多半好评”,“褒贬不一”,“差评”,依靠的只是将正面评论除以总评论即可获得评级(just divide the positive reviews by the total reviews to get the rating)。
举例说明这种评价算法的不合理性,就是:A游戏获得了1条好评(100%),B游戏获得了24条好评和1条差评(96%),C游戏获得了99条好评和1条差评(99%)。尽管steam考虑到了过少的评论造成的潜在影响,但也只是设置了一个50评价数和500评价数的阶梯值。兼顾这个阶梯值的影响,最终的评价优先级可能就是C>A>B,但B真的比A要差吗?
这种规则之下,极端的捡漏者(某款游戏)如果一款评分 48 比 1 的游戏突然多了 11 个负面评价,Steam 仍然会奇迹般地把它排在比以前更高的位置(it’s still a bad system. Because if our 48 to 1 rated game suddenly accrued 11 more negative ratings, Steam would miraculously still place it higher than it was before.)。
在这里,我推荐大家看一遍来自evanmiller.org发布于2009.6的一篇文章How Not To Sort By Average Rating,同步理解对比不同评分法的差异,简要论述那些简单粗暴的评分法,其实并不合理。
#1 倾向于大样本的不合理评分算法(评分 = 好评数 - 差评数)(Score = (Positive ratings) − (Negative ratings))
很显而易见,好评数与差评数直接做差
假设I类样本有 600个正面评价记录和 400个负面评价记录:好评率60%,算法得分为200。假设II类有 5,500 个正面评价记录和 4,500 个负面评价记录:好评率55%,算法得分为1000。因为两条评价记录的基数都足够大(至少steam官方是这么认为的),所以按照这样的算法去排序,II就应该大于I。但如果让你来评价,你怎么看呢? 或者更极端一点,I类样本(600,400),II类(10000,9700),此时的score分别是200和300,还是II大于I,此时你又怎么看?
#2 倾向于小样本的不合理评分算法(评分 = 好评数/总评数)(Score = (Positive ratings)/(Total ratings))
如果说上述的算法倾向的还是大样本下的绝对好评数量结果,下面这个就更加不合理了。仅有一条评价且为好评的游戏,他的分值是1/1=1=100%,这样的得分比99/100 = 0.99=99%还要更高。这显然也是不合理的。
#3.Wilson区间评分办法,取下界数值作为评价标准(Score = Lower bound of Wilson score confidence interval for a Bernoulli parameter)
( p ^ + z α / 2 2 2 n ± z α / 2 [ p ^ ( 1 − p ^ ) + z α / 2 / 4 n ] / n ) / ( 1 + z α / 2 2 / n ) \left (\hat p +\frac{z^2_{\alpha/2}}{2n} \ \pm \ z_{\alpha/2}\sqrt{[\hat p(1-\hat p)+z_{\alpha/2}/4n]/n}\right)/(1+z^2_{\alpha/2}/n ) (p^+2nzα/22 ± zα/2[p^(1−p^)+zα/2/4n]/n)/(1+zα/22/n)
以下是一段原作者使用ruby语言计算置信区间的下界数值的原始代码,在原始的代码基础上,我添加了一些注释内容:
# 计算置信区间下界的方法
require 'statistics2'
def ci_lower_bound(pos, n, confidence)
# 如果样本数量为0,直接返回0,避免除以0的错误
if n == 0
return 0
end
# 计算Z值,用于计算置信区间下界
z = Statistics2.pnormaldist(1-(1-confidence)/2)
# 计算正样本比例
phat = 1.0 * pos / n
# 使用置信区间计算公式,计算置信区间下界
(phat + z * z / (2 * n) - z * Math.sqrt((phat * (1 - phat) + z * z / (4 * n)) / n)) / (1 + z * z / n)
end
于此同时,我自己也给出一段python的代码傻瓜化实现逻辑:
import math # 导入数学函数库
# 计算置信区间下界的方法
def ci_lower_bound(pos, n, confidence):
if n == 0: # 如果样本数量为0,直接返回0,避免除以0的错误
return 0
z = 1.96 # 1.96是95%置信水平对应的Z值,confidence参数可以在这里调整使用,也可以直接写死
phat = 1.0 * pos / n # 计算正样本比例
# 使用置信区间计算公式,计算置信区间下界
return (phat + z * z / (2 * n) - z * math.sqrt((phat * (1 - phat) + z * z / (4 * n)) / n)) / (1 + z * z / n)
end
在查看同行的讲解深度的过程中,还看到了一位B站上的同行小姐姐@石小秀1210的,看起来是一段用来对月度内短视频的已知质量得分计算威尔逊区间评分的代码,我觉得内容很清晰,而且同步实现了对每条记录的wilson分值添加到dataframe的方法,我不需要做额外的改进。因此直接搬到这里:
import numpy as np
#计算威尔逊区间下限
def wilson_score(pos_rat,total,p_z = 3):
"""
威尔逊得分计算函数
:param pos:正例数
:param total:总数
:param p_z:正态分布的分位数
:return 威尔逊得分
"""
score = (pos_rat + (np.square(p_z)/(2. * total)) - ((p_z/(2. * total)) * np.sqrt(4.* total * (1. - pos_rat) * pos_rat + np.square(p_z)))) / (1. + np.square(p_z) / total)
return score
# 应用dataframe 创建新列
data['wilson_high_quality_rate'] = data[['high_quality_rate','month_video']].apply(lambda x:wilson_score(x['high_quality_rate'],x['month_video']),axis = 1)
根据原作者后续多年的内容更新,在此,我也附上这个算法在SQL和excel里的实现方法:
SELECT widget_id
, ((positive + 1.9208) / (positive + negative) - 1.96 * SQRT((positive * negative) / (positive + negative) + 0.9604) / (positive + negative)) / (1 + 3.8416 / (positive + negative)) AS ci_lower_bound
FROM widgets
WHERE positive + negative > 0
ORDER BY ci_lower_bound DESC;
以下是excel的公式,我对原作者的格式做了一定的处理,其中的@[Up Votes] 和 @[Down Votes]可以直接替换为你的对应行/列的对应值:
=IFERROR(
(
(
[@[Up Votes]] + 1.9208
) / (
[@[Up Votes]] + [@[Down Votes]]
) - 1.96 * SQRT(
( [@[Up Votes]] * [@[Down Votes]]
) / (
[@[Up Votes]] + [@[Down Votes]]
) + 0.9604
) / (
[@[Up Votes]] + [@[Down Votes]]
)
) / (
1 + 3.8416 / ([@[Up Votes]] + [@[Down Votes]])
), 0)
这种使用Wilson区间下界作为评分办法,
首创是,
在这里附上作者博客的原文:
I initially devised this method for a Chuck Norris-style fact generator to honor of one of my professors, but it has since caught on at places like Reddit, Yelp, and Digg.
如果想深入了解这种算法的推导过程,可以查看原始论文Wilson, E.B. (1927). “Probable inference, the law of succession, and statistical inference”. Journal of the American Statistical Association. 22 (158): 209–212. doi:10.1080/01621459.1927.10502953. JSTOR 2276774.
(这是一条华丽的分割线,以下过程皆为迂腐的解释过程,并不适用实用主义者)
对 #3 Wilson区间评分办法 的理解和延申
我会在接下来的内容中穿插解释,为什么对于评分这件事,使用Wilson的评分法是合理的。穿插内容不会影响阅读,以及我的推导过程,内容会在其中用灰色【】表示。
Wilson的区间评分办法,基于对二项分布中对参数p的区间估计逐步推导得到。
1.基础原理及假设:正态分布近似二项分布
还记得二项分布的式子么?
B ( r ; n , p ) ≡ n C r . p r ( 1 − p ) ( n − r ) B(r;n,p) \equiv nCr.p^r(1-p)^{(n-r)} B(r;n,p)≡nCr.pr(1−p)(n−r)
* nCr :二项式系数, 计算公式 n C r = n ! ( n − r ) ! nCr= \frac{n!}{(n-r)!} nCr=(n−r)!n!
此处也有必要补充说明一下。在中国大陆的授课过程中,多数会在概率论课本中如此介绍,这里供大家对应参考。因为我不清楚为什么这里不引入经典的牛顿二项式定理中的二项式系数符号,而用了一个奇怪的 ( n k ) \binom{n}{k} (kn),建议在各位阅读和理解的过程中,以我的blog为准,请注意对应:
随机变量 X X X服从参数为 n n n和 p p p的二项分布,记为 X ∼ B ( n , p ) X \sim B(n,p) X∼B(n,p) ,其中n次试验中正好得到k次成功的概率由概率质量函数为:
P { X = k } = ( n k ) p k ( 1 − p ) n − k P\{X=k\} = \binom{n}{k}p^k(1-p)^{n-k} P{X=k}=(kn)pk(1−p)n−k– 引自百度百科及某概率论课本
实际上我们统计学的估计体系总是在做着这样的事,因为总体无法计算(典型的测试炮弹质量的例子),又或者是计算的难度太大(几百年前的统计学家并没有计算机辅助,处理二项分布时,nCr的阶乘计算实在太恶心了。)人性总是趋利避害的,于是统计学家的先驱们提出了一个假设,因为二项式分布与正态分布大致相同,所以用正态分布近似了二项分布。
后来根据大数定律和中心极限定理,我们也可以印证上述的这个假设。样本均值的分布会无限接近正态分布。二项分布的样本均值 p ^ \hat p p^ 在样本量较大时,可以近似为正态分布。这样一来,我们可以使用正态分布的一些性质来计算置信区间。
2.收集样本数据,样本对应的总体数据中包含一个p
对参数p的估计,求其估计值 p ^ \hat p p^,需要一组足够多的样本量,即生成一组满足二项分布的数据。什么样的数据满足二项分布?遵循它的定义,多次重复伯努利试验的样本记录满足二项分布,投多次硬币就好了。这里并不局限于一个规则的硬币,甚至我不希望使用一枚质地均匀规则的硬币来获取数据。因为我不想提前预知“投掷一次XX硬币,其正面向上的概率是0.5 。或者你其实也可以这样去近似,看看你能不能理解,比如我现在更换了一个20面骰子,把其中一面定义为正面,其余19面我统一把他们叫做“不是正面”,那么得到正面的概率,就是1/20。【对于一款游戏,其真实游戏受众及水准是客观存在的,这个好评率取决于多少人打了好评,多少人给了差评,对于GTA5这样制作水准的游戏,基于极大量的样本得到的 p ^ \hat p p^, 无限向真实的 p p p 逼近】
3.当正态分布近似二项分布时,所犯的第Ⅰ类和第Ⅱ类错误
正态分布是连续且对称的。它很好地遵循二项式分布。我使用等效的连续分布曲线去替换离散分布曲线(阶梯直方图)时,两个分布之间存在一些轻微的分歧,此处标记为“错误”。
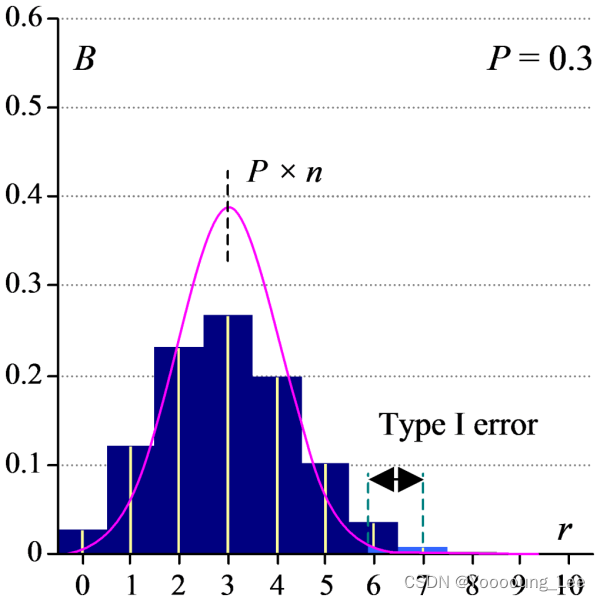
第一类错误,我们通常解释为,拒绝了实际上成立的、正确的假设,为“弃真”的错误。在未指定特定业务背景下,我们应当尽可能关注第一类错误带来的影响。用粉色线(正态分布是一种连续性分布)去近似拟合一个深蓝色直方图的二项分布(离散分布),其中必定不能做到百分百的拟合。那么差异在哪里呢?
- 如果该线位于“台阶”的中点之外,则该错误是保守的“II 类”错误。这意味着通过使用正态分布而不是二项式分布,我们增加了无法拒绝真实零假设的机会。当我们应该接受一个结果是重要的时,我们却未能接受。
- 如果该线位于“台阶”的中点内,则出现根本性“I 型”错误。使用正态分布可能会导致我们拒绝原假设,如果我们使用更准确的二项式分布,我们就不会这样做。换句话说,我们承认结果是重要的,而我们不应该这样做。
可能这么说,你听着相隔口诀一样的,但不知道对全文思路有什么作用。
所以还是要聊到那个二十面骰子。
收集一份由二十面骰子生成的二项分布数据。它的分布是这样的。
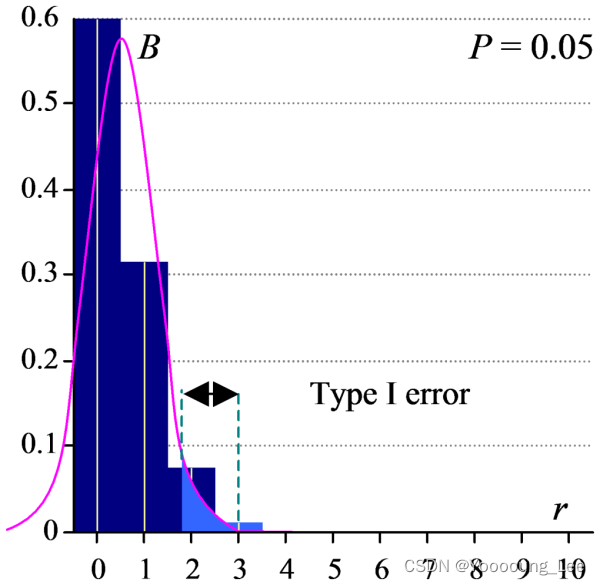
标准正态分布和二项分布的总和均为 1。也就是说,曲线下的总面积是恒定的。您可以看到,当P接近于零时,正态分布“聚集”,就像二项分布一样。然而,它也跨越了图表左侧的一个不可能的区域。不可能有 -1 的骰子面,但曲线似乎包含此概率。这意味着事实上,正态分布的可能部分下的总面积小于 1,并且这块不合理的面积部分,本身就意味着P的偏斜值,这也就意味着,正态分布的估计办法正在越来越“激进”。甚至变得不合理。请记住这个不合理的地方,接下来我会严谨的讨论“p可能有负或者大于1”的情况。
4.使用正态分布的性质逼近真实的p,以及讨论正态近似估计p这种方法的局限性
接下来,要基于正态分布的性质来计算置信区间。根据正态分布的性质,我们知道在置信水平为下,临界值 z z z 满足 P ( − z < Z < z ) = 1 − α P(−z<Z<z)=1−α P(−z<Z<z)=1−α ,其中 Z Z Z 是标准正态分布的随机变量。如果用正态方法去近似对参数p求它的区间估计范围,计算公式为:
p ^ ± z ∗ p ^ ( 1 − p ^ ) n \hat{p} \pm z*\sqrt{\frac{\hat{p}(1-\hat{p})}{n}} p^±z∗np^(1−p^)
需要注意的是,在样本大小较小或 p ^ \hat p p^ 接近边界值(0或1)时,正态近似可能不适用,此时可以考虑使用其他的方法来计算置信区间。
为什么会在接近0,1时,会存在不适用的情况呢?
p ^ ± z ∗ p ^ ( 1 − p ^ ) n \hat{p} \pm z*\sqrt{\frac{\hat{p}(1-\hat{p})}{n}} p^±z∗np^(1−p^)
我先顺着思路,把正态近似的式子化简下去。将真实的p表示在一个范围内:
p ≈ p ^ ± z α n p ^ ( 1 − p ^ ) p \approx \hat p \pm \frac{z_\alpha}{\sqrt{n}} \sqrt{\hat{p}(1-\hat{p})} p≈p^±nzαp^(1−p^)
再给一个,可以便于快速计算的直接表达式:
p
≈
n
s
n
±
Z
α
n
n
s
n
n
f
n
p \approx \frac{n_s}{n} \pm \frac{Z_\alpha}{\sqrt{n}}\sqrt{\frac{n_s}{n}\frac{n_f}{n}}
p≈nns±nZαnnsnnf
其中: n s n_s ns代表样本中的正样本success数量, n f n_f nf代表样本中的负样本failed数量,n代表总样本数, n = n s + n f n=n_s+n_f n=ns+nf 。在你规定好对应的置信度之后,查表(例如 z 0.975 = 1.96 z_{0.975}=1.96 z0.975=1.96),带入即可快速求上下界。
观察p的计算公式,其实可以看到两个不合理的地方,
-
对于 p ^ \hat p p^ 接近1或0时,间隔会无限缩小到零宽度(即每一次伯努利事件发生的概率为1或0,变成了绝对的结果)
-
而当 p ^ < 1 1 + n / z α 2 \hat{p} < \frac{1}{1+n/z^2_\alpha} p^<1+n/zα21的时候,会发生什么呢?此时变成了一种名为“overshoot”的状态(没看到教材有翻译的很好的中文,所以引用overshoot一词,它指的是置信区间估计范围超出了参数真实值的情况),在这个取值范围内确定的区间估计,即p的区间,变成了小于0或大于1。
但p可能有负或者大于1的情况吗?
当然,尤其是当样本量较少,或真实的成功概率p及其接近0或者1的时候,当使用样本计算 p ^ \hat{p} p^进行估计的时候,就会出现这种情况。

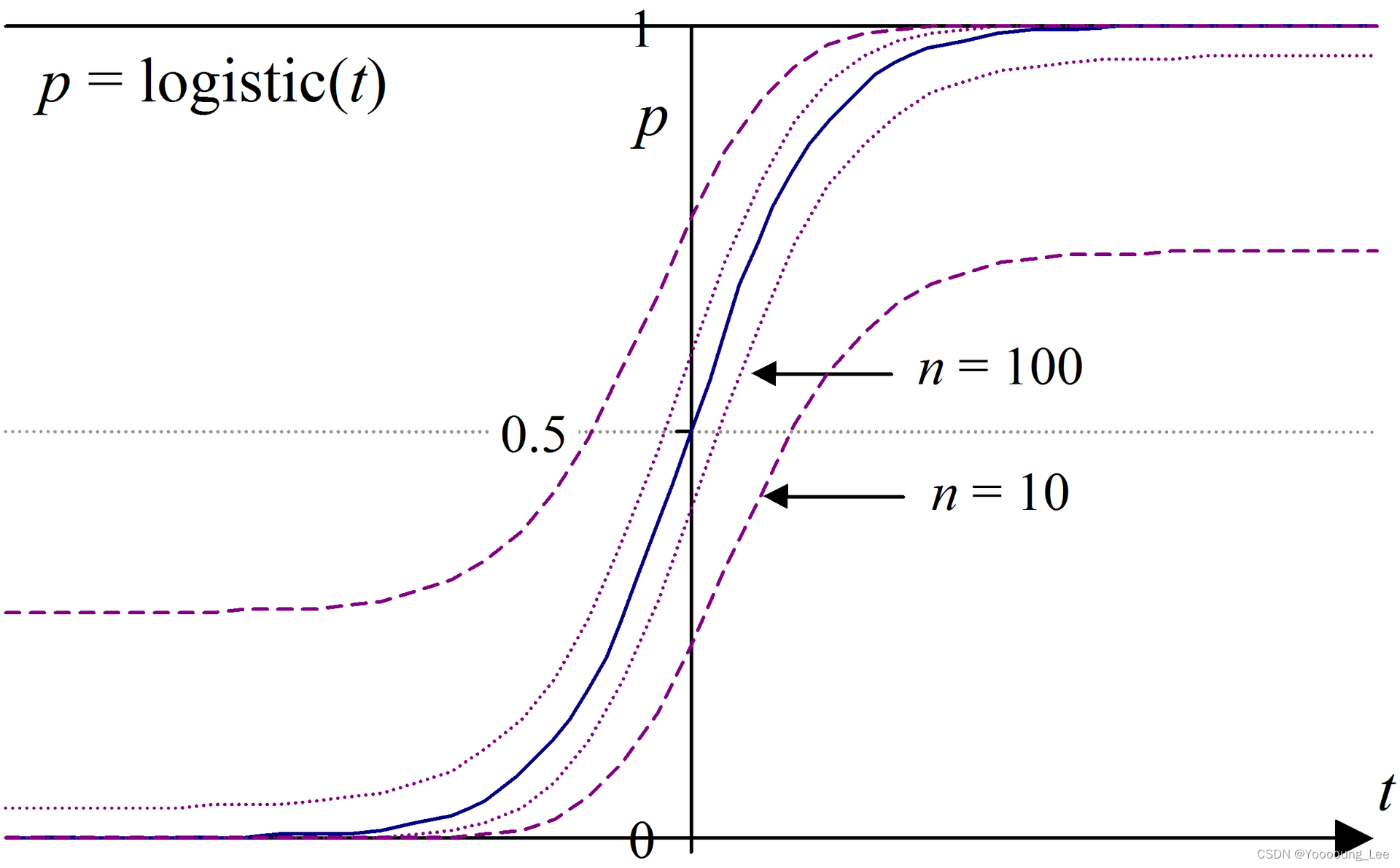
还是根据中心极限定理,大样本下的logistic分布估计值可以近似服从正态分布。因此可以使用正态分布的性质来构建参数的置信区间。一般情况下,使用样本均值和标准差构建置信区间。
这里附上一张图,我引入一个 标准logistic分布, 它是一般logistic分布函数,
F
(
x
)
=
1
1
+
e
−
k
(
x
−
x
0
)
F(x) = \frac{1}{1+e^{-k(x-x_0)}}
F(x)=1+e−k(x−x0)1
在
k
=
1
,
x
0
=
0
,
L
=
1
k=1,x_0=0,L=1
k=1,x0=0,L=1时的情形。
插入一段说明,表述推广到一般的logistic分布函数有如下的性质:
- x 0 x_0 x0 为S形曲线中点的x值;
- L L L 为曲线的最大值;
- k k k 为logistic增长率或曲线的陡度;
- 当 x x x 趋向于正无穷时, f ( x ) f(x) f(x) 的值逼近 L L L ,而 x x x 趋向于负无穷时, f ( x ) f(x) f(x) 的值逼近 0 0 0。
可以看到对比真实的分布情况,利用正态近似的方法对p做区间估计,以确定取值范围。然后可以看到,在上下界都有着overshoot的情况,这种情况可以随着样本量n的增加而减少出现异常情况的概率,但无法完全避免,这是由于正态分布图像两端那两个长长的尾巴导致的。而出现负值,或者大于1,这种显然是不合理的。
5.结合二项分布的特性,以及置信区间本身的对称性,wilson提出优化的区间估计方法
Wilson是怎么尝试解决这一问题的呢?
正态近似的区间估计方法,因为没有加入修正参数的原因,置信区间本身是关于真实值对称的结果,这种对称性在真实值临近0或者1时,区间估计的上/下界可能会overshoot,而这显然是不合理的。【就像你不能对一款游戏估计它的好评率下界是-0.03%,即使这个游戏做的奇差无比。卧槽,蒸!】
通过制造一个不对称的区间,将临近上下界的结果,平滑修正到一个合理的范围内。用大白话解释就是:在首先保证结果显著的前提下,当真实的p临近max时,则适度将边界下移以保证上界不超过max,反之亦然。举例说明就是p=0.99,正态近似的区间估计方法 p ^ ∈ [ 0.975 , 1.025 ] \hat{p}\in [0.975,1.025] p^∈[0.975,1.025], wilson方法可以将结果修正到 p ^ ∈ [ 0.96 , 0.995 ] \hat{p}\in [0.96,0.995] p^∈[0.96,0.995]
Wilson 区间评分方法通过将样本比率
p
^
\hat p
p^ 进行修正,并结合样本量
n
n
n 和置信水平所对应的标准正态分布的临界值
z
z
z,得到置信区间的上限和下限。
这个公式提供了在给定置信水平下参数
p
p
p 的置信区间,其中
p
^
\hat p
p^ 是样本比率,
n
n
n 是样本大小,
z
z
z 是标准正态分布的临界值。
得到Wilson区间估计上下界的解,取其下界即可得到合理的评分结果:
p ∈ ≈ α ( p ^ + z α / 2 2 2 n ± z α / 2 [ p ^ ( 1 − p ^ ) + z α / 2 / 4 n ] / n ) / ( 1 + z α / 2 2 / n ) p \underset{\approx\alpha}{\in} \left (\hat p +\frac{z^2_{\alpha/2}}{2n} \ \pm \ z_{\alpha/2}\sqrt{[\hat p(1-\hat p)+z_{\alpha/2}/4n]/n}\right)/(1+z^2_{\alpha/2}/n ) p≈α∈(p^+2nzα/22 ± zα/2[p^(1−p^)+zα/2/4n]/n)/(1+zα/22/n)
最后,我再给出一个基于上式转化的,便于快速计算的直接表达式,
p ∈ ≈ α n s + 1 2 z α 2 n + z α 2 ± z α n + z α 2 n s n f n + z α 2 4 p \underset{\approx\alpha}{\in} \frac{n_s+\frac{1}{2}z_\alpha^2}{n+z_\alpha^2} \pm \frac{z_\alpha}{n+z_\alpha^2} \sqrt{\frac{n_sn_f}{n}+\frac{z_\alpha^2}{4}} p≈α∈n+zα2ns+21zα2±n+zα2zαnnsnf+4zα2
其中: n s n_s ns代表样本中的正样本success数量, n f n_f nf代表样本中的负样本failed数量,n代表总样本数, n = n s + n f n=n_s+n_f n=ns+nf 。在你规定好对应的置信度之后,查表(例如 z 0.975 = 1.96 z_{0.975}=1.96 z0.975=1.96),带入即可快速求上下界。
事实上,Wilson 区间也可以从单样本 z 检验或两类Pearson 卡方检验中得出,这里不再推导,有兴趣可以自己试试看,或者自行求解。
它的完整推导过程详见上面的论文原文链接。
下期预告:针对含伯努利参数的Wilson区间评分办法,其实还有改进之处,在下一期,我将引入由另一位同仁提出的拉普拉斯平滑的办法,并简练说明二者的差异,及其独到的方法优化思路,敬请期待。
联系我 交流请署名👇



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









