







Oracle全文索引总结
2008-3-13 Sevenli http://www.hnisi.com.cn/
步骤:
1. 设置词法分析器(lexer)
保证登录用户具有和CTXSYS用户相应的权权限和CTXAPP角色,或者直接用CTXSYS用户登录,语句如下
BEGIN
ctx_ddl.create_preference ('context_lexer', 'chinese_vgram_lexer');
END;
其中蓝色部分为词法分析器名(可自己定),红色部分为词法分析器(可选basic_lexer,chinese_vgram_lexer,chinese_lexer三种,其中默认为basic_lexer,具体可查阅相关资料)
2. 对相应的表字段创建全文索引(这里以表ylqx_reg中的字段ggxh为例)
用与该表相应的用户登录,用以下语句创建全文索引
Create Index context_ind_ylqx_reg On ylqx_reg(ggxh) Indextype Is
Ctxsys.Context Parameters('lexer context_lexer')
这里可以通过
Select Token_Text, Token_Count From Dr$context_ind_ylqx_reg$i
语句查看词法分析器分析的结果
3. 对已创建的索引进行自动更新和自动优化,通过两个job实现,如下(这里要保证登录用户具有对ctx_ddl包的访问权,可用系统用户登录给相应用户授权)
3.1.自动更新索引job,如下图(其中Interval中sysdate+( 1/24/4 )表示每隔15分钟更新一次)

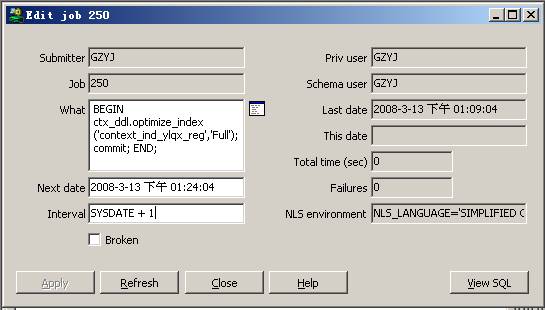
3.2.自动优化索引job,如下图(其中Interval中sysdate+1表示每隔一天优化一次)
其他相关资料
以下是oracle全文索引的一些信息
oracle中关于全文索引中score的计算方法信息为:
The standard Salton formula used to assign each score is as follows:
3f (1+log(N/n))
Where...
f = the frequency of the search term in the document,
N = the total number of "rows in the table" (or documents in the library), and
n = the number of rows (or documents) which contain the search term.
Score can be between 0 and 100, but the top-scoring document in the query will not
necessarily have a score of 100 -- scoring is relative, not absolute. This means that scores
are not compatible across indexes, or even across queries on the same index.
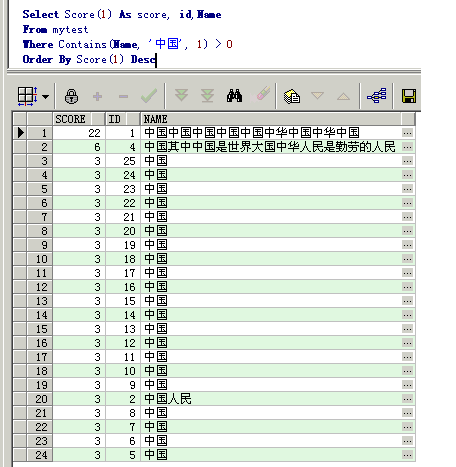
新建mytest表,对score值进行测试,如果如下:
表mytest如下

查询“中国”时得到的score值如下
用命令
Begin
Ctx_Ddl.Create_Preference('my_lexer2', 'chinese_lexer');
End;
Create Index Myindex On mytest(Name) Indextype Is Ctxsys.Context Parameters('lexer my_lexer2')
生成关键字信息如下
















 5854
5854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









