






1.在声明变量(declare)时,vatchar2需要指定长度,number无需指定,因为number默认长度为38。
declare
v_i number := 4;
v_a varchar2(200) := '哈哈哈哈哈';
v_aa constant varchar2(200) :='常量';
v_d date := sysdate;--系统时间
v_ename emp.ename%type;
--动态追踪表中某个字段类型,就意味着v_ename类型永远与emp表中的ename类型保持一致。
v_emp_row emp%rowtype;--动态追踪表中整行字段类型
--必须指定长度,并且字符串需要用单引号,不能用双引号,用双引号报错。常量也得指定长度。
变量名前加上constant,就表示常量。常量不能再次赋值。
2.plsql中连接符为“||”,类似于java中的“+”
在查询数据库时,最好使用别名。因为这样可以提高效率。
3.关系型数据库三范式
第一范式:确保每列都保持原子性。每个表都必须遵守
第二范式:确保表中的每列都和主键相关
第三范式:确保每列都和主键列直接相关,而不是间接相关。即消除传递依赖。
4.赋值语句
select 查询结果 into 赋值变量 from ;select e.ename into v_ename from emp e where e.deptno=7369;
select e.ename,e.deptno into v_ename,v_deptno from emp e where e.deptno=7369;声明类型,格式为
type 类型名字 is table of table元素的类型 index by binary_integer;
--index by binary_integer不是必须写,可以省略。①零散赋值
--当然,声明是在declare中
type tab_type is table of varchar2(100) index by binary_integer;
--这只是声明了类型,并不是定义table
v_tab1 tab_type;--这才是定义table型数据
begin
v_tab1(0) := 'aaa';
v_tab1(1) := 'bbb';
v_tab1(2) := 'ccc';v_tab2 := tab_type('aaa','bbb','ccc');
dbms_output.put_line(v_tab2(1));7.exist是用来替代in的,因为exist查询效率高。exist可以使用索引,而in不能。
where column in(select * from ... where ...);
where exist(select * from ... where ...);
--变量
declare
v_a varchar2(100) := 'aaa';
--参数
create or replace procedure p_emp_copy(
l_result1 out varchar2 --没有指定长度,也不用加分号
)for 变量名(不需要声明,自动匹配in后集合的单个元素类型) in 集合 loop
end loopfor v_r in 1..100 loop
v_sum := v_sum+ v_r; --v_r无需提前声明
end loop;declare
v_begin number := 1;--这个没必要声明,只是为了整齐
v_sum number := 0; --sum必须赋初值,否则报错
begin
for v_begin in 1..100 loop--1..100表示1到100
if v_begin mod 2<>0 then --注意不要丢then
v_sum := v_sum + v_begin;
end if;--if的结束标签
end loop;--loop的结束标签
end;declare
v_begin number := 1;--这个没必要声明,只是为了整齐
v_sum number := 0; --sum必须赋初值,否则报错
begin
while v_sum<100 loop
v_sum := v_sum + v_begin;
v_begin := v_begin + 1;
end loop;
end;10.游标就是指在某个结果集上的指针,通过这个指针的移动,我们得以遍历整个结果集。即游标就是一个结果集list
游标的属性有4种,%found %notfound %rowcount(用来记录遍历到的总行数) %isopen
游标需与commit或rollback连用
简单画下游标的分类
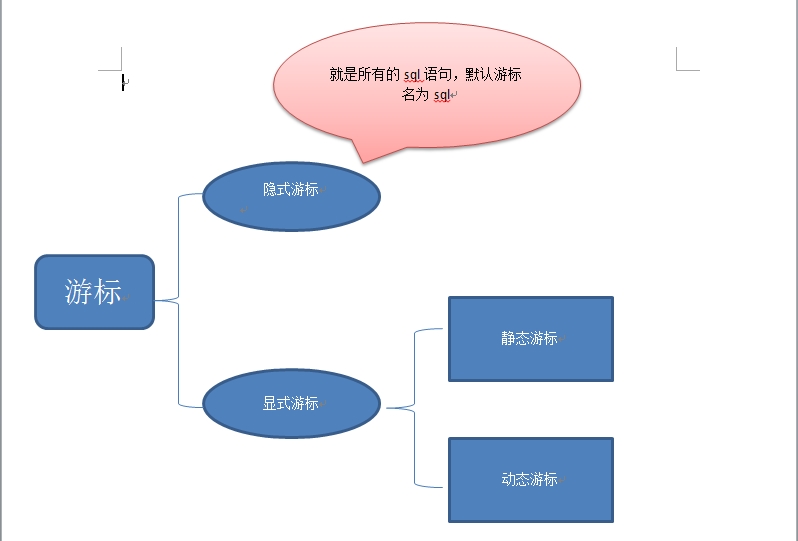
静态游标分为无参和 有参,推荐 for 遍历
动态 游标则是 ①先定义一个游标类型 ②搞游标类型对应的一个变量 。它还分为弱类型和强类型
弱类型 : type my_cursor is ref cursor; 就是定义行变量时 必须指定具体的类型
强类型 : type my_cursor is ref cursor return emp%rowtype; 定义行变量可以动态匹配游标的rowtype;
使用步骤为:①声明游标 ②打开游标 ③处理游标中的数据 ④关闭游标
遍历游标最常用的是for循环,因为它不需要打开游标,也不需要关闭,甚至不用声明循环变量,非常简单。如:
begin
delete from emp e where e.deptno = 20;--无需声明游标,直接begin。这为隐式游标
if sql%found then
dnms_output.put_line('游标自动关闭');
end if;
commit; --commit不能丢
end;cursor 名字(参数名 参数类型) is select 语句 ;--注意参数无需加长度declare
cursor c_emp(l_job varchar2) is select * from emp e where e.job = l_job;
--游标c_emp中存储的是sql语句的结果集,l_job只是一个变量名,可以换位其它值
begin
for emp_row in c_emp('CLERK') loop
--使用for循环变量emp_row无需声明,但在loop循环中就需要声明了
dbms_output.put_line(emp_row.ename);
end loop;
end;declare
cursor c_emp(l_job varchar2) is select * from emp e where e.job = l_job;
v_emp_row c_emp%rowtype;--v_emp_row在loop循环中需要声明,在for循环中无需声明
begin
--打开游标
open c_emp('CLERK');
--处理数据
loop
--读数据
fetch c_emp into v_emp_row;
exit when c_emp%notfound;
dbms_output.put_line(v_emp_row.ename);--注意是v_emp_row.name,而不是c_emp.ename
end loop;
--关闭游标
close c_emp;
end;11.使用游标也可以更新结果集。select语句后边要加for update来锁定记录用来更新。用where current of 来指明操作是添加在当前游标所指向的记录上。如
declare
cursor c_emp is select * from emp for update;
begin
for v_t in c_emp loop
if v_t.deptno = 10 then
delete from emp e where current of v_t;
end if;
end loop;
end;create [or replace] procedure 存储过程名 (参数名 in 类型…………参数名 out 类型)
is --用来定义变量
begin
exception
end;如写一个存储过程,可以完成对emp的增删改(没有查);
create or replace procude p_emp_cud(
l_remark in number,--0:add 1:update 2:delete
l_hiredate in varchar2,
l_deptno in number,
l_result out varchar2
--l_result可以不写,但一般用来判断结果是否正确
)
is
begin
l_result := '00000';
if l_remark=0 then
insert into emp values(
to_date(l_hiredate,'yyyy-mm-dd'),
l_deptno
);
else if l_remark=1 then
update emp e
set
e.hiredate = to_date(l_hiredate,'yyyy-mm-dd')
where emp.deptno = l_deptno;
else
delete from emp e where emp.deptno = l_deptno;
end if;
commit;
exception
when others then
rollback;
l_result := '1111111';
end;13.在嵌套循环中,外层循环控制列,内层循环控制行。
14.复制表的内容,可以先建一个与原表结构相同的表,再用类似于
insert into emp_copy select * from emp;15.oracle查询有两种形式,索引查询和全表扫描。索引类似于书的目录,主要用于查询频率高、增删改频率低的地方。并不是索引查询就比较快,还得分情况,当有大量数据时,索引查询就比较快。当数据量较小时,全表扫描就比较快。
16.plsql中处理结果集只能用游标。
下面写一个常用的存储过程实例
17.写一个存储过程 ,传入表名和重复值的字段名 实现删除重复数据功能.
先说一下正常的删除重复数据的sql语句为
delete from emp e where rowid <>(select min(rowid) from emp c where c.empno= e.empno);rowid是一个伪列,一般不常用,但在要锁定某一列时就需要用到这。因为它的值不会重复,在plsql常用在删除重复数据中。
为成固定格式,很重要。
ceeate procedure p_del(
l_tab_name in varchar2,
l_col_name in varchar2
)
is
v_sql varchar2(2000);--声明sql
begin
v_sql := 'delete from '||l_tab_name||' t1 where rowid <> (select min(rowid) from '||l_tab_name||' t2 where t2.'||l_col_name||'=t1.'||l_col_name);
execute immediate v_sql;
commit;
--这儿其实可以定义一个out类型的result的,只是省略了
exception
when others then
rollback;
end;














 1892
1892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









