










一些面试的知识点:
http://blog.csdn.net/yy008871/article/details/7705940
今天想着随便写点,为日后回忆做点准备:
=======================过滤器和拦截器===================================================
过滤器<filter>:
拦截器<inteceptor>
过滤器,【还没有进入业务里面】是在java web中,你传入的request,response提前过滤掉一些信息,或者提前设置一些参数,
所以过滤器是拦截在业务请求之前
然后再传入servlet或者struts的 action进行业务逻辑,
比如:
1:过滤掉非法url(不是login.do的地址请求,如果用户没有登陆都过滤掉),
2:在传入servlet或者 struts的action前统一设置字符集,或者去除掉一些非法字符
拦截器,【已结进入到了业务里面】是在面向切面编程的,
1:在你的service或者一个方法前调用一个方法,preHandle(){xxxxx}
2:在你的service或者一个方法后调用一个方法比如动态代理就是拦截器的简单实现,在你调用方法前打印出字符串(或者做其它业务逻辑的操作),也可以在你调用方法后打印出字符串,甚至在你抛出异常的时候做业务逻辑的操作
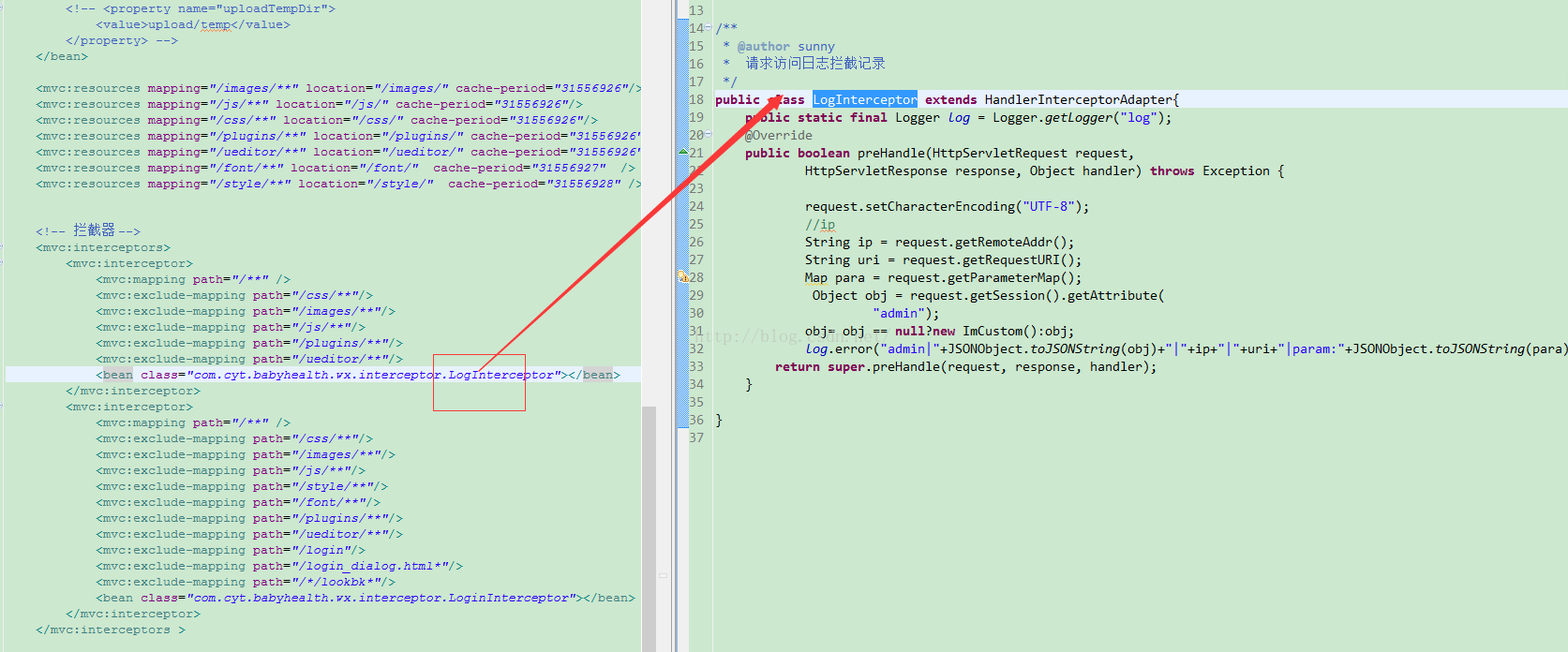
拦截器与过滤器的区别 :
- 拦截器是基于java的反射机制的【因为他用的是动态代理,里面实现使用的是java反射】,而过滤器是基于函数回调。
- 拦截器不依赖与servlet容器,过滤器依赖与servlet容器。【因为他的参数是HttpServletrequest,HttpServletresponse】
- 拦截器只能对action请求起作用,而过滤器则可以对几乎所有的请求起作用。(下面提到,可以过滤html,指定文件夹等)
- 拦截器可以访问action上下文、值栈里的对象【因为他的参数是ActionInvocation】,而过滤器不能访问。
- 在action的生命周期中,拦截器可以多次被调用,而过滤器只能在容器初始化时被调用一次
执行顺序 :过滤前 - 拦截前 - Action处理 - 拦截后 - 过滤后。个人认为过滤是一个横向的过程,首先把客户端提交的内容进行过滤(例如未登录用户不能访问内部页面的处理);过滤通过后,拦截器将检查用户提交数据的验证,做一些前期的数据处理,接着把处理后的数据发给对应的Action;Action处理完成返回后,拦截器还可以做其他过程(还没想到要做啥),再向上返回到过滤器的后续操作。
这样看来,AOP其实只是OOP的补充而已。OOP从横向上区分出一个个的类来,而AOP则从纵向上向对象中加入特定的代码。有了AOP,OOP变得立体了。如果加上时间维度,AOP使OOP由原来的二维变为三维了,由平面变成立体了。从技术上来说,AOP基本上是通过代理机制实现的。
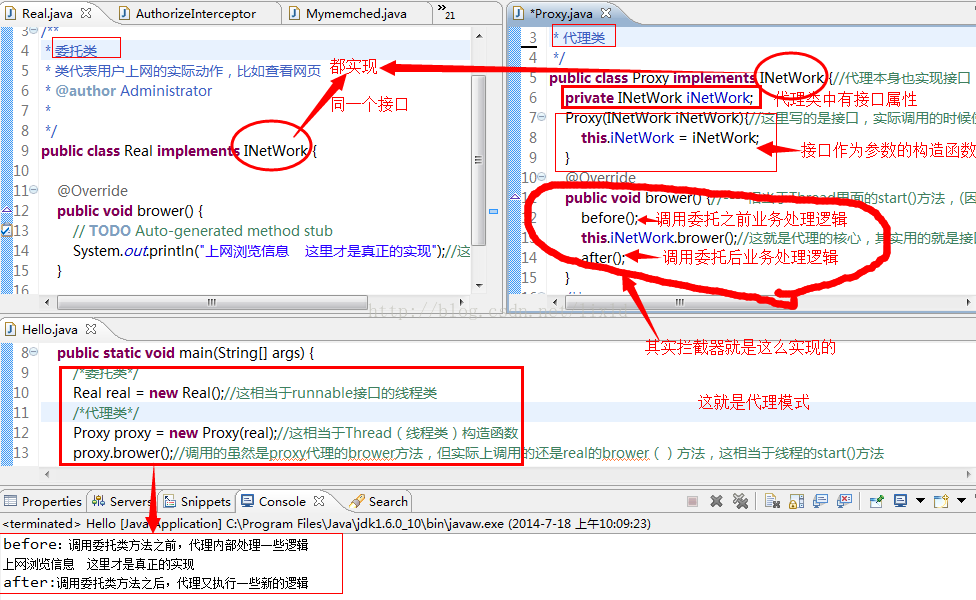
下面看看静态代理实例
二者的配置都在web.xml中:
Filter过滤器是一个Web应用组件,和Servlet类似,也需要在Web应用配置文件中进行配置:首先是过滤器的Web应用定义包含在<filter>…</filer>元素中,其次是Web应用的过滤器映射配置文件<filter-mapping>…</filter-mapping>
过滤器的应用很广泛,在这里介绍利用过滤器进行中文转码。
一般在JavaWeb应用中,当利用request.getParameter(String str)方法获取从表单或是页面传过来的中文参数都会是一个乱码。
通常的做法是:会采用如下的转码方式在Servlet或是JSP中进行转码设置:
(1)request.setCharacterEncoding("gb2312");
(2)String username = request.getParameter("username");
username = new String(username.getBytes("ISO-8859-1"), "GB2312");
这样做的缺点是:
假设:一个表单有多数据传到Servlet或是JSP,那么就可能在这些Servlet或是JSP中写下多个request.setCharacterEncoding("gb2312")或是多个类似于String username = request.getParameter("username");
username = new String(username.getBytes("ISO-8859-1"), "GB2312");这样子肯定加大代码工作量。
解决办法是:
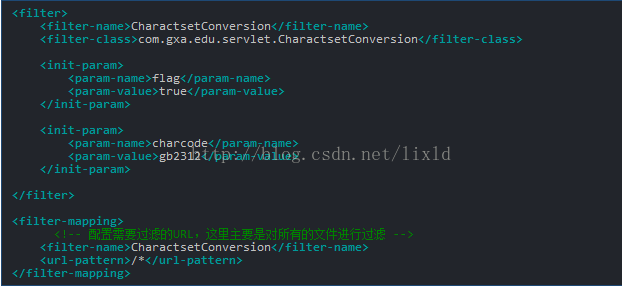
针对上面的一些常见的问题,下面利用过滤器进行中文转码就可以迎刃而解。配置Filter的步骤如下:
1.配置web.xml
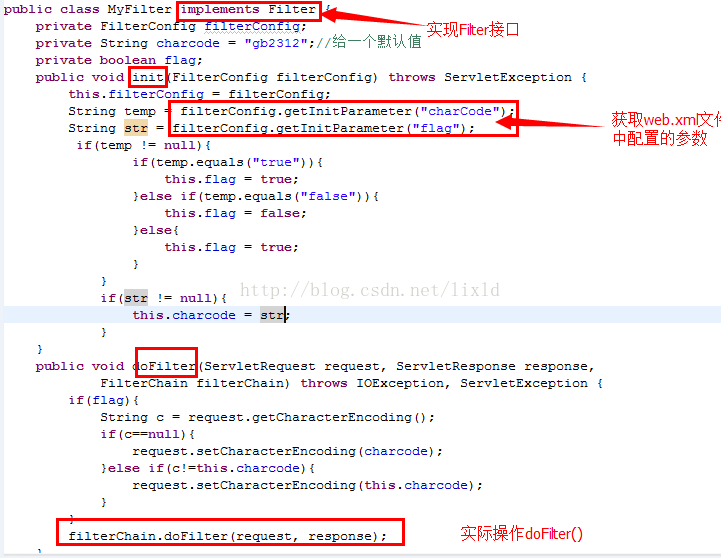
2.开发过滤器:比如类CharactsetConversion【该类必须实现filter接口】,同时实现Filter接口提供的三个方法:
(1)void doFilter(ServletRequest req,ServletResponse res,FilterChain filterChain)
(2)void init(FilterConfig filterConfig)
(3)void destroy()
对于配置的提升:
1。如果要映射过滤应用程序中所有资源:
<filter-mapping>
<filter-name>loggerfilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
2.过滤指定的类型文件资源
<filter-mapping>
<filter-name>loggerfilter</filter-name>
<url-pattern>*.html</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>loggerfilter</filter-name>
<url-pattern>*.jsp</url-pattern>
</filter-mapping>
可以一下写多个过来类型,其中<url-pattern>注意没有“/”斜杠
3.过滤指定的目录
<filter-mapping>
<filter-name>loggerfilter</filter-name>
<url-pattern>/folder_name/*</url-pattern>
</filter-mapping>
4.过滤指定的servlet
<filter-mapping>
<filter-name>loggerfilter</filter-name>
<servlet-name>loggerservlet</servlet-name>//注意这里是servlet
</filter-mapping>
5.过滤指定文件
<filter-mapping>
<filter-name>loggerfilter</filter-name>
<url-pattern>/simplefilter.html</url-pattern>
</filter-mapping>
下面总结三种经常用到的过滤器:
一、使浏览器不缓存页面的过滤器
public class ForceNoCacheFilter implements Filter {
public void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain) throws IOException, ServletException
{
((HttpServletResponse) response).setHeader("Cache-Control","no-cache");
((HttpServletResponse) response).setHeader("Pragma","no-cache");
((HttpServletResponse) response).setDateHeader ("Expires", -1);
filterChain.doFilter(request, response);
}
public void destroy()
{
}
public void init(FilterConfig filterConfig) throws ServletException
{
}
}
二、检测用户是否登陆的过滤器
/**
* 用于检测用户是否登陆的过滤器,如果未登录,则重定向到指的登录页面
* filter中配置参数
* checkSessionKey 需检查的在 Session 中保存的关键字
* redirectURL 如果用户未登录,则重定向到指定的页面,URL不包括 ContextPath
* notCheckURLList 不做检查的URL列表,以分号分开,并且 URL 中不包括 ContextPath
*/
public class CheckLoginFilter
implements Filter
{
protected FilterConfig filterConfig = null;
private String redirectURL = null;
private List notCheckURLList = new ArrayList();
private String sessionKey = null;
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException
{
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
HttpSession session = request.getSession();
if(sessionKey == null)
{
filterChain.doFilter(request, response);
return;
}
if((!checkRequestURIIntNotFilterList(request)) && session.getAttribute(sessionKey) == null)
{
response.sendRedirect(request.getContextPath() + redirectURL);
return;
}
filterChain.doFilter(servletRequest, servletResponse);
}
public void destroy()
{
notCheckURLList.clear();
}
private boolean checkRequestURIIntNotFilterList(HttpServletRequest request)
{
String uri = request.getServletPath() + (request.getPathInfo() == null ? "" : request.getPathInfo());
return notCheckURLList.contains(uri);
}
public void init(FilterConfig filterConfig) throws ServletException
{
this.filterConfig = filterConfig;
redirectURL = filterConfig.getInitParameter("redirectURL");
sessionKey = filterConfig.getInitParameter("checkSessionKey");
String notCheckURLListStr = filterConfig.getInitParameter("notCheckURLList");
if(notCheckURLListStr != null)
{
StringTokenizer st = new StringTokenizer(notCheckURLListStr, ";");
notCheckURLList.clear();
while(st.hasMoreTokens())
{
notCheckURLList.add(st.nextToken());
}
}
}
}
三、字符编码的过滤器 (上面的实例代码)
四、资源保护过滤器
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
/**
* This Filter class handle the security of the application.
* It should be configured inside the web.xml.
*/
public class SecurityFilter implements Filter {
//the login page uri
private static final String LOGIN_PAGE_URI = "login.jsp";
//the logger object
private Log logger = LogFactory.getLog(this.getClass());
//a set of restricted resources
private Set restrictedResources;
/**
* Initializes the Filter.
*/
public void init(FilterConfig filterConfig) throws ServletException {
this.restrictedResources = new HashSet();
this.restrictedResources.add("/createProduct.jsf");
this.restrictedResources.add("/editProduct.jsf");
this.restrictedResources.add("/productList.jsf");
}
/**
* Standard doFilter object.
*/
public void doFilter(ServletRequest req, ServletResponse res, FilterChain chain)
throws IOException, ServletException {
this.logger.debug("doFilter");
String contextPath = ((HttpServletRequest)req).getContextPath();
String requestUri = ((HttpServletRequest)req).getRequestURI();
this.logger.debug("contextPath = " + contextPath);
this.logger.debug("requestUri = " + requestUri);
if (this.contains(requestUri, contextPath) && !this.authorize((HttpServletRequest)req)) {
this.logger.debug("authorization failed");
((HttpServletRequest)req).getRequestDispatcher(LOGIN_PAGE_URI).forward(req, res);
}
else {
this.logger.debug("authorization succeeded");
chain.doFilter(req, res);
}
}
public void destroy() {}
private boolean contains(String value, String contextPath) {
Iterator ite = this.restrictedResources.iterator();
while (ite.hasNext()) {
String restrictedResource = (String)ite.next();
if ((contextPath + restrictedResource).equalsIgnoreCase(value)) {
return true;
}
}
return false;
}
private boolean authorize(HttpServletRequest req) {
//处理用户登录
/* UserBean user = (UserBean)req.getSession().getAttribute(BeanNames.USER_BEAN);
if (user != null && user.getLoggedIn()) {
//user logged in
return true;
}
else {
return false;
}*/
}
}
==========================================================================
接下来看看拦截器:
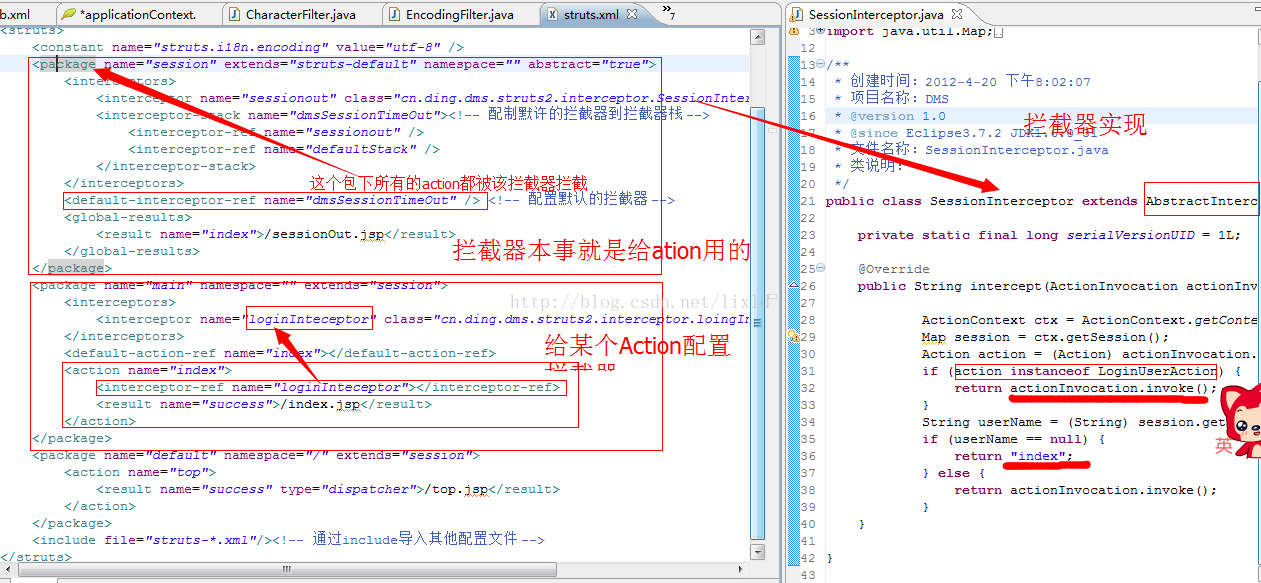
=============================================================================
struts1基本被抛弃了,下面主要讨论struts2
核心包:
struts2-core-2.0.11.1.jar
xwork-2.0.4.jar
commons-logging-1.0.4.jar
freemarker-2.3.8.jar
Struts2入口是过滤器:
下面是web.xml文件中struts的配置:
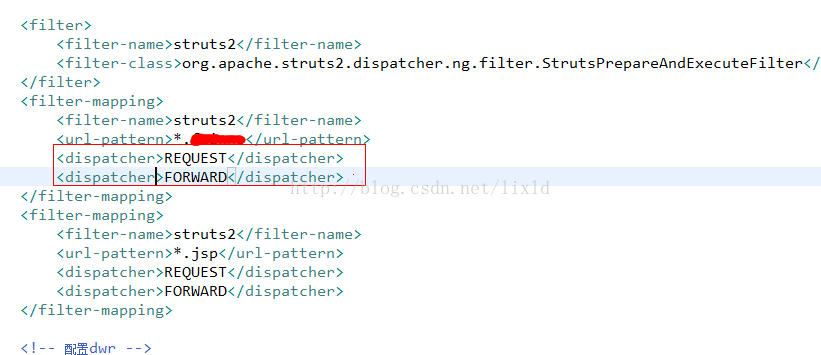
注意下这里的dispatcher
<dispatcher>元素,这个元素有四个可能的值:即
1.REQUEST,默认是这个【其实就是redirect】
2.FORWARD,
3.INCLUDE
4.ERROR,
使得filter将会作用于直接从客户端过来的request,通过forward过来的request,通过include过来的request和通过<error-page>过来的request。如果没有指定任何<dispatcher>元素,默认值是REQUEST
struts.xml中的配置点:
1.struts2的拦截器intercepter:
首先拦截器是配置在struts.xml文件中:
其次看结构
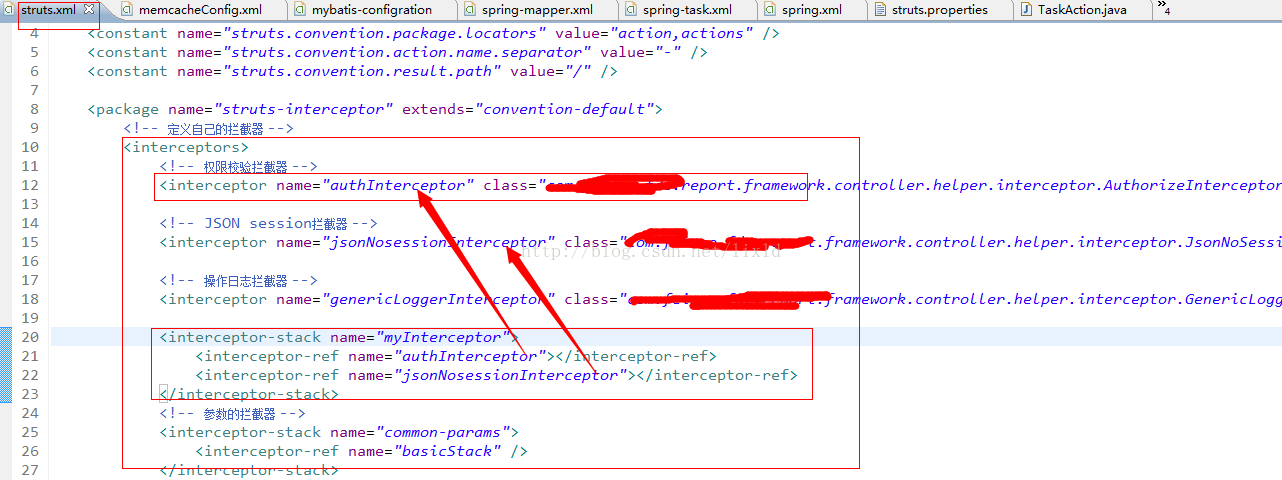
从上面的调用过程我们可以总结出来:过滤器和拦截器在struts2中调用顺序:
过滤前 - 拦截前 - Action处理 - 拦截后 - 过滤后。个人认为过滤是一个横向的过程,首先把客户端提交的内容进行过滤(例如未登录用户不能访问内部页面的处理);过滤通过后,拦截器将检查用户提交数据的验证,做一些前期的数据处理,接着把处理后的数据发给对应的Action;Action处理完成返回后,拦截器还可以做其他过程(还没想到要做啥),再向上返回到过滤器的后续操作。
我想说的是:这里的interceptor-stak,拦截器栈,并且这种写法是旧的写法,
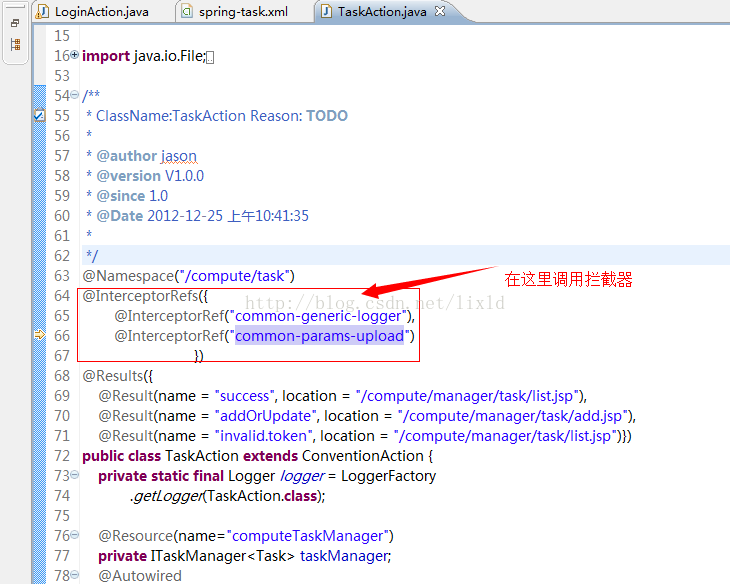
JDK5.0以后有了标注,struts2提供了标注写法支持,不用像上图中这么写了。下面的截图那样在action中直接写
InterceptorRefs({
InterceptorRef("aaaa"),
InterceptorRef("bbbbb"),
})
里面的多个拦截器interceptor-ref是递归调用,肿么解释呢:
1.aaa拦截器invoke()之前的代码,
2.bbb拦截器invoke()之前的代码
3.bbb拦截器invoke()之后的代码
4.aaa拦截器invoke()之后的代码
再次看调用[也即是写Action]
区别在于:
Struts1.x中的动作类必须从Action类中继承,而Struts2.x的动作类需要从com.opensymphony.xwork2.ActionSupport类继承
=========== 监听器[spring用的就是contextLoaderlistener监听]=============================
监听器概述
1.Listener是Servlet的监听器
2.可以监听客户端的请求、服务端的操作等。
3.通过监听器,可以自动激发一些操作,如监听在线用户数量,当增加一个HttpSession时,给在线人数加1。
4.编写监听器需要实现相应的接口
5.编写完成后在web.xml文件中配置一下,就可以起作用了
6.可以在不修改现有系统基础上,增加web应用程序生命周期事件的跟踪
常用的监听接口
1.ServletContextAttributeListener
监听对ServletContext属性的操作,比如增加/删除/修改
2.ServletContextListener
监听ServletContext,当创建ServletContext时,激发 contextInitialized(ServletContextEvent sce)方法;当销毁ServletContext时,激发contextDestroyed(ServletContextEvent sce)方法。
3.HttpSessionListener
监听HttpSession的操作。当创建一个 Session时,激发session Created(SessionEvent se)方法;当销毁一个Session时,激发sessionDestroyed (HttpSessionEvent se)方法。
4.HttpSessionAttributeListener
监听HttpSession中的属性的操作。当在Session增加一个属性时,激发 attributeAdded(HttpSessionBindingEvent se) 方法;当在Session删除一个属性时,激发attributeRemoved(HttpSessionBindingEvent se)方法;当在Session属性被重新设置时,激发attributeReplaced(HttpSessionBindingEvent se) 方法。
使用范例:
由监听器管理共享数据库连接
生命周期事件的一个实际应用由context监听器管理共享数据库连接。在web.xml中如下定义监听器:
<listener>
<listener-class>XXX.MyConnectionManager</listener-class>
</listener> ?server创建监听器的实例,接受事件并自动判断实现监听器接口的类型。要记住的是由于监听器是配置在部署描述符web.xml中,所以不需要改变任何代码就可以添加新的监听器。
public class MyConnectionManager implements ServletContextListener{
public void contextInitialized(ServletContextEvent e) {
Connection con = // create connection
e.getServletContext().setAttribute("con", con);
}
public void contextDestroyed(ServletContextEvent e) {
Connection con = (Connection) e.getServletContext().getAttribute("con");
try {
con.close();
}
catch (SQLException ignored) { } // close connection
}
}
监听器保证每新生成一个servlet context都会有一个可用的数据库连接,并且所有的连接对会在context关闭的时候随之关闭。
在web.xml中加入:
<listener><listener-class>servletlistener111111.SecondListener</listener-class> </listener>

==================================================
关于用户超时的例子:
public class OnlineUserListener implements HttpSessionListener {
public void sessionCreated(HttpSessionEvent event) {
}
public void sessionDestroyed(HttpSessionEvent event) {
HttpSession session = event.getSession();
ServletContext application = session.getServletContext();
// 取得登录的用户名
String username = (String) session.getAttribute("username");
// 从在线列表中删除用户名
List onlineUserList = (List) application.getAttribute("onlineUserList");
onlineUserList.remove(username);
System.out.println(username + "超时退出。");
}
}
以下两种情况下就会发生sessionDestoryed(会话销毁)事件:
1.执行session.invalidate()方法时。例如:request.getSession().invalidate();
2.如果用户长时间没有访问服务器,超过了会话最大超时时间,服务器就会自动销毁超时的session。会话超时时间可以在web.xml中进行设置。
========================================
使用HttpSessionBindingListener
HttpSessionBindingListener虽然叫做监听器,但使用方法与HttpSessionListener完全不同。我们实际看一下它是如何使用的。
我们的OnlineUserBindingListener实现了HttpSessionBindingListener接口,接口中共定义了两个方法:valueBound()和valueUnbound(),分别对应数据绑定,和取消绑定两个事件。
所谓对session进行数据绑定,就是调用session.setAttribute()把HttpSessionBindingListener保存进session中。我们在LoginServlet.java中进行这一步。
// 把用户名放入在线列表
session.setAttribute("onlineUserBindingListener", new OnlineUserBindingListener(username));
这就是HttpSessionBindingListener和HttpSessionListener之间的最大区别:HttpSessionListener只需要设置到web.xml中就可以监听整个应用中的所有session。 HttpSessionBindingListener必须实例化后放入某一个session中,才可以进行监听。
从监听范围上比较,HttpSessionListener设置一次就可以监听所有session,HttpSessionBindingListener通常都是一对一的。
正是这种区别成就了HttpSessionBindingListener的优势,我们可以让每个listener对应一个username,这样就不需要每次再去session中读取username,进一步可以将所有操作在线列表的代码都移入listener,更容易维护。
valueBound()方法的代码如下:
public void valueBound(HttpSessionBindingEvent event) {
HttpSession session = event.getSession();
ServletContext application = session.getServletContext();
// 把用户名放入在线列表
List onlineUserList = (List) application.getAttribute("onlineUserList");
// 第一次使用前,需要初始化
if (onlineUserList == null) {
onlineUserList = new ArrayList();
application.setAttribute("onlineUserList", onlineUserList);
}
onlineUserList.add(this.username);
}
username已经通过构造方法传递给listener,在数据绑定时,可以直接把它放入用户列表。
与之对应的valueUnbound()方法,代码如下:
public void valueUnbound(HttpSessionBindingEvent event) {
HttpSession session = event.getSession();
ServletContext application = session.getServletContext();
// 从在线列表中删除用户名
List onlineUserList = (List) application.getAttribute("onlineUserList");
onlineUserList.remove(this.username);
System.out.println(this.username + "退出。");
}
这里可以直接使用listener的username操作在线列表,不必再去担心session中是否存在username。
valueUnbound的触发条件是以下三种情况:
1.执行session.invalidate()时。
2.session超时,自动销毁时。
3.执行session.setAttribute("onlineUserListener", "其他对象");或
session.removeAttribute("onlineUserListener");将listener从session中删除时。
因此,只要不将listener从session中删除,就可以监听到session的销毁
======================================下面看看配置================================================
action的配置:Struts1.x的动作一般都以.do结尾,而Struts2是以.action结尾。
这一步struts1.x和struts2.x都是必须的,只是
在struts1.x中的配置文件一般叫struts-config.xml(当然也可以是其他的文件名),而且一般放到WEB-INF目录中。
而在truts2.x中的配置文件一般为struts.xml

这里的type可以取:
dispatcher:(其实就是forward),转发可以保存request中的值
redirect:
stream:
用标注的新写法:
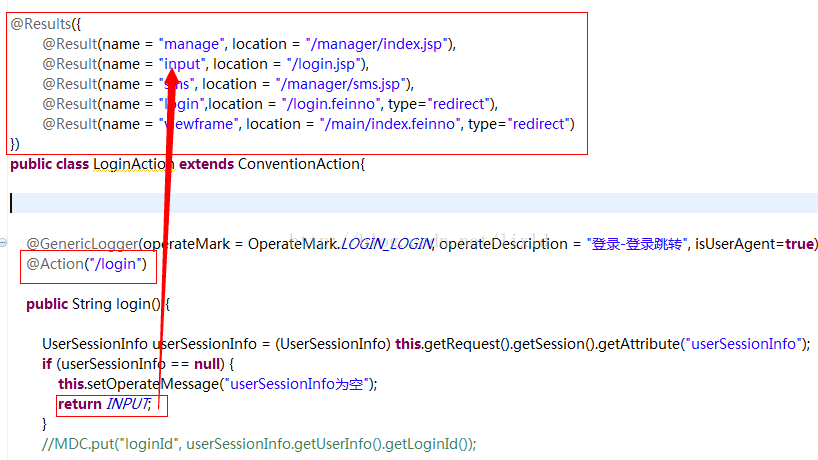
还要注意一点:
<?xmlversion="1.0"encoding="UTF-8"?><!DOCTYPEstrutsPUBLIC
"-//ApacheSoftwareFoundation//DTDStrutsConfiguration2.0//EN""http://struts.apache.org/dtds/struts-2.0.dtd"><struts>
<package name="struts2" namespace="/mystruts" extends="struts-default">
<action name="sum" class="action.FirstAction">
<result name="positive">/positive.jsp</result>
<result name="negative">/negative.jsp</result>
</action>
</package>
</struts>
在<struts>标签中可以有多个<package>,第一个<package>可以指定一个Servlet访问路径(不包括动作名),如“/mystruts”
不能这样写
===============================================jsp页面中设计的struts2内容
Struts2自带的tag:struts2
在
Struts2
中已经将
Struts1.x
的好几个标签库都统一了,
在
Struts2
中只有一个标签库
/struts-tags
================================分割线=============================
下面看看struts的线程安全问题
sruts1.x是单例模式,所以线程不安全
strut2.本身是线程安全的,因为他为每一个请求都产生一个新实例,从根源上杜绝了这个问题
但是使用spring来管理Action后,IOC容器中管理的bean都是单例的,所以问题又出来了,和struts1一样,
解决的办法是:在spring的bean配置中,设置scope="prototype"
======================================================
spring IOC容器对象的调用
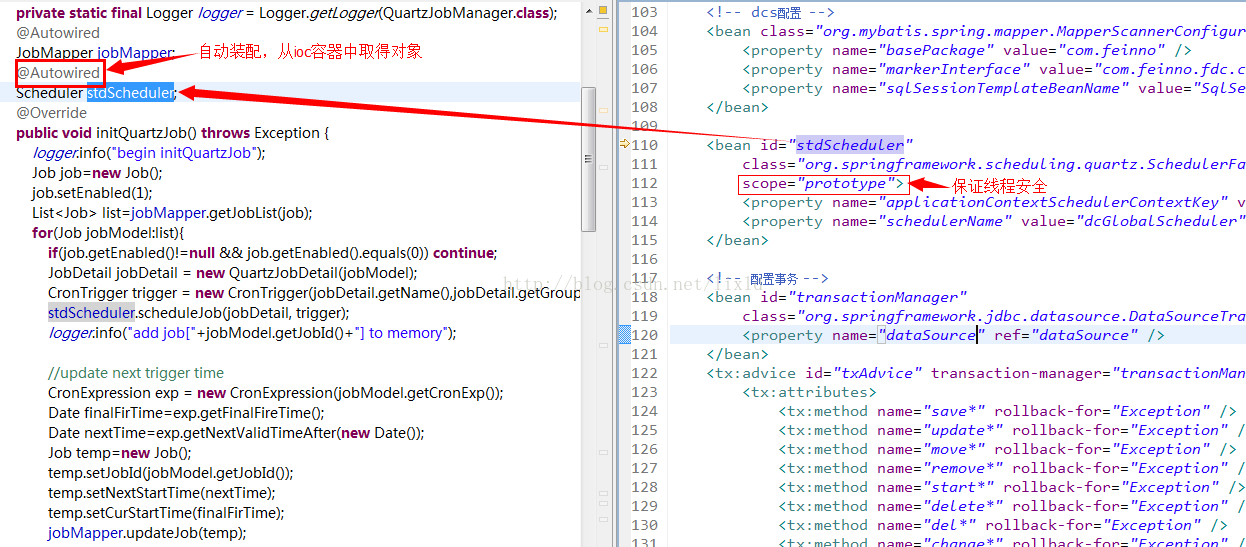
如果要想在普通的java代码中使用IoC容器中的bean实体:
则这样写:
1.实例化spring容器 和 从容器获取Bean对象
实例化Spring容器常用的两种方式:
方法一:
在类路径下寻找配置文件来实例化容器 [推荐使用]
ApplicationContext ctx = new ClassPathXmlApplicationContext(new String[]{"beans.xml"});
方法二:
在文件系统路径下寻找配置文件来实例化容器 [这种方式可以在开发阶段使用]
ApplicationContext ctx = new FileSystemXmlApplicationContext(new String[]{“d:\\beans.xml“});
Spring的配置文件可以指定多个,可以通过String数组传入。
当spring容器启动后,因为spring容器可以管理bean对象的创建,销毁等生命周期,
所以我们只需从容器直接获取Bean对象就行,而不用编写一句代码来创建bean对象。
从容器获取bean对象的代码如下:
ApplicationContext ctx = new ClassPathXmlApplicationContext(“beans.xml”);
OrderService service = (OrderService)ctx.getBean("personService");
查看文章:http://www.blogjava.net/stevenjohn/archive/2012/08/20/385846.html
============================有关标签================================

=============================spring 相关===============================
IoC,
直观地讲,就是容器控制程序之间的关系,而非传统实现中,由程序代码直接操控。这也就是所谓“控制反转”的概念所在。控制权由应用代码中转到了外部容器,控制权的转移是所谓反转。IoC还有另外一个名字——“依赖注入(Dependency Injection)”。从名字上理解,所谓依赖注入,即组件之间的依赖关系由容器在运行期决定,形象地说,即由容器动态地将某种依赖关系注入到组件之中。
spring依赖注入的三种方式:
1.通过接口注射--类必须实现容器给定的一个接口,然后容器会利用这个接口给我们这个类注射它所依赖的类。
2.通过setter方法注射,这种方式也是Spring推荐的方式
public class Girl {
private Kissable kissable;
public void setKissable(Kissable kissable) {
this.kissable = kissable;
}
public void kissYourKissable() {
kissable.kiss();
}
}
<beans>
<bean id="boy" class="Boy"/>
<bean id="girl" class="Girl">
<property name="kissable">
<ref bean="boy"/>
</property>
</bean>
</beans>
3.通过构造方法注射类,这种方式Spring同样给予了实现,它和通过setter方式一样,都在类里无任何侵入性,但是,不是没有侵入性,只是把侵入性转移了,显然第1种方式要求实现特定的接口,侵入性非常强,不方便以后移植。
public class Girl {
private Kissable kissable;
public Girl(Kissable kissable) {
this.kissable = kissable;
}
public void kissYourKissable() {
kissable.kiss();
}
}
PicoContainer container = new DefaultPicoContainer();
container.registerComponentImplementation(Boy.class);
container.registerComponentImplementation(Girl.class);
Girl girl = (Girl) container.getComponentInstance(Girl.class);
girl.kissYourKissable();
下面看一个特别的类:OpenSessionInview

=================================三个框架整合===========================================


===================全局事务与本地事务的区别==========
全局事务:
资源管理器管理和协调的事务,
可以跨越多个数据库和进程。
资源管理器一般使用
本地事务: 在单个 EIS 或数据库的本地并且 限制在单个进程内的事务 。本地事务 不涉及多个数据来源
在Hibernate配置文件中有这么两种配置方式: 1.如果使用的是本地事务(jdbc事务)
<property name="hibernate.current_session_context_class">thread</property>,这个是我们常用的选项,只针对一个数据库进行操作,也就是说只针对一个事务性资源进行操作. 2. 如果使用的是全局事务(jta事务)
<property name="hibernate.current_session_context_class">jta</property>
以前我们学习的事务类型都属于本地事务。 JTA(全局事务)和thread(本地事务)有什么区别呢?在某些应用场合,只能使用全局事务,比如:
有两个数据库:
1.mysql 2.oracle 现在有个业务需求--转账
step 1> update mysql_table set amount=amount-xx where id=aaa 发生扣钱,假设是在mysql数据库扣钱的。
step 2> update oracle_table set amount=amount+xx where id=bbb 加钱,假设是在oracle数据库扣钱的。
现在怎么确保两个语句在同一个事务里执行呢?
以前在JDBC里是这样做 connection = mysql 连接mysql
connection.setAutoCommit(false); 不自动提交
1> update mysql_table set amount=amount-xx where id=aaa 发生扣钱,假设是在mysql数据库扣钱的。
2> update oracle_table set amount=amount+xx where id=bbb 发生在oracle数据库 connection.commit();
执行这两条语句,然后通过connection对象提交事务.我们这样子做只能确保这两个语句在同一个数据库mysql里面实现在同一个事务里执行。 但是问题是我们现在是要连接到oracle数据库,是不是需要connection2啊?
connection = mysql 连接mysql connection2 = oracle 连接oracle
connection.setAutoCommit(false); 不自动提交
1> update mysql_table set amount=amount-xx where id=aaa 发生扣钱,假设是在mysql数据库扣钱的。
2> update oracle_table set amount=amount+xx where id=bbb 发生在oracle数据库 connection.commit();
connection2.setAutoCommit(false)
connection2.commit();
事务只能在一个connection里打开,并且确保两条语句都在该connection里执行,这样才能让两条语句在同一事务里执行,现在问题就在于connection2是连接到oracle数据库的,那么connection2再开事务有意义吗?它能确保吗?不能,所以在这种情况下就只能使用全局事务了。
这种情况下用普通JDBC操作是满足不了这个业务需求的,这种业务需求只能使用全局事务,本地事务是无法支持我们的操作的,因为这时候,事务的生命周期不应该局限于connection对象的生命周期范围
全局事务怎么做呢?
JPA.getUserTransaction().begin(); 首先要全局事务的API,不需要我们编写,通常容器已经提供给我们了,我们只需要begin一下 connection = mysql 连接mysql connection2 = oracle 连接oracle
connection--> update mysql_table set amount=amount-xx where id=aaa 发生扣钱,假设是在mysql数据库扣钱的。
connection2--> update oracle_table set amount=amount+xx where id=bbb 发生在oracle数据库 JPA.getUserTransaction().commit();
那么它是怎么知道事务该提交还是回滚呢?
这时候它使用了二次提交协议。二次提交协议简单说就这样:如果你先执行第一条语句,执行的结果先预提交到数据库,预提交到数据库了,数据库会执行这条语句,然后返回一个执行的结果,这个结果假如我们用布尔值表示的话,成功就是true,失败就是false.然后把执行的结果放入一个(假设是List)对象里面去,接下来再执行第二条语句,执行完第二条语句之后(也是预处理,数据库不会真正实现数据的提交,只是说这条语句送到数据库里面,它模拟下执行,给你返回个执行的结果),假如这两条语句的执行结果在List里面都是true的话,那么这个事务就认为语句是成功的,这时候全局事务就会提交。二次提交协议,数据库在第一次提交这个语句时,只会做预处理,不会发生真正的数据改变,当我们在全局事务提交的时候,这时候发生了第二次提交,那么第二次提交的时候才会真正的发生数据的改动。
如果说在执行这两条语句中,有一个出错了,那么List集合里就有个元素为false,那么全局事务就认为你这个事务是失败的,它就会进行回滚,回滚的时候,哪怕你的第二条语句在第一次提交的时候是成功的,它在第二次提交的时候也会回滚,那么第一次的更改也会恢复到之前的状态,这就是二次提交协议。(可以查看一下数据库方面的文档来了解二次提交协议
===========================getCurrentSession() 和openSession()=======================
1、getCurrentSession()与openSession()的区别?
<property name="hibernate.current_session_context_class">jta</property>
openSession() 与 getCurrentSession() 有何不同和关联呢?
在 SessionFactory 启动的时候, Hibernate 会根据配置创建相应的 CurrentSessionContext ,在getCurrentSession() 被调用的时候,实际被执行的方法是 CurrentSessionContext.currentSession() 。在currentSession() 执行时,如果当前 Session 为空, currentSession 会调用 SessionFactory 的 openSession 。所以 getCurrentSession() 对于 Java EE 来说是更好的获取 Session 的方法。
许多时候出现session is close();原因就是你在hibernate.cfg.xml里面设置了
- <property name="hibernate.current_session_context_class">thread</property>
系统在commit();执行完之后就关闭了session,这时候你手动再关闭session就当然提示错误了
利于ThreadLocal模式管理Session
早在Java1.2推出之时,Java平台中就引入了一个新的支持:java.lang.ThreadLocal,给我们在编写多线程程序
时提供了一种新的选择。ThreadLocal是什么呢?其实ThreadLocal并非是一个线程的本地实现版本,它并不是一个Thread,
而是thread local variable(线程局部变量)。也许把它命名为ThreadLocalVar更加合适。线程局部变量(ThreadLocal)
其实的功用非常简单,就是为每一个使用某变量的线程都提供一个该变量值的副本,是每一个线程都可以独立地改变自己的副本,
而不会和其它线程的副本冲突。从线程的角度看,就好像每一个线程都完全拥有一个该变量。
ThreadLocal是如何做到为每一个线程维护变量的副本的呢?其实实现的思路很简单,在ThreadLocal类中有一个Map,
用于存储每一个线程的变量的副本。比如下面的示例实现(为了简单,没有考虑集合的泛型):
public class HibernateUtil {
public static final ThreadLocal session =new ThreadLocal();
public static final SessionFactory sessionFactory;
static {
try {
sessionFactory = new Configuration().configure().buildSessionFactory();
} catch (Throwable ex) {
throw new ExceptionInInitializerError(ex);
}
}
public static Session currentSession() throws HibernateException {
Session s = session.get();
if(s == null) {
s = sessionFactory.openSession();
session.set(s);
}
return s;
}
public static void closeSession() throws HibernateException {
Session s = session.get();
if(s != null) {
s.close();
}
session.set(null);
}
}
技巧:利于ThreadLocal模式管理Session |
|
在利用Hibernate开发DAO模块时,我们和Session打的交道最多,所以如何合理的管理Session,避免Session的频繁创建和销毁,对于提高系统的性能来说是非常重要的,以往是通过eclipse的插件来自动完成这些代码的,当然效果是不错的,但是总是觉得不爽(没有读懂那些冗长的代码),所以现在打算自己实现Session管理的代码。 我们知道Session是由SessionFactory负责创建的,而SessionFactory的实现是线程安全的,多个并发的线程可以同时访问一个SessionFactory并从中获取Session实例,那么Session是否是线程安全的呢?很遗憾,答案是否定的。Session中包含了数据库操作相关的状态信息,那么说如果多个线程同时使用一个Session实例进行CRUD,就很有可能导致数据存取的混乱,你能够想像那些你根本不能预测执行顺序的线程对你的一条记录进行操作的情形吗? 在Session的众多管理方案中,我们今天来认识一种名ThreadLocal模式的解决方案。 早在Java1.2推出之时,Java平台中就引入了一个新的支持:java.lang.ThreadLocal,给我们在编写多线程程序时提供了一种新的选择。ThreadLocal是什么呢?其实ThreadLocal并非是一个线程的本地实现版本,它并不是一个Thread,而是thread local variable(线程局部变量)。也许把它命名为ThreadLocalVar更加合适。线程局部变量(ThreadLocal)其实的功用非常简单,就是为每一个使用某变量的线程都提供一个该变量值的副本,是每一个线程都可以独立地改变自己的副本,而不会和其它线程的副本冲突。从线程的角度看,就好像每一个线程都完全拥有一个该变量。 ThreadLocal是如何做到为每一个线程维护变量的副本的呢?其实实现的思路很简单,在ThreadLocal类中有一个Map,用于存储每一个线程的变量的副本。比如下面的示例实现(为了简单,没有考虑集合的泛型):
那麽具体如何利用ThreadLocal来管理Session呢?Hibernate官方文档手册的示例之中,提供了一个通过ThreadLocal维护Session的好榜样:
只要借助上面的工具类获取Session实例,我们就可以实现线程范围内的Session共享,从而避免了线程中频繁的创建和销毁Session实例。当然,不要忘记在用完后关闭Session。写到这里,想再多说一些,也许大多数时候我们的DAO并不会涉及到多线程的情形,比如我们不会将DAO的代码写在Servlet之中,那样不是良好的设计,我自己通常会在service层的代码里访问DAO的方法。但是我还是建议采用以上的工具类来管理Session,毕竟我们不能仅仅考虑今天为自己做什么,还应该考虑明天为自己做什么! |
=====================今天遇到spring事物的一个问题==================================================
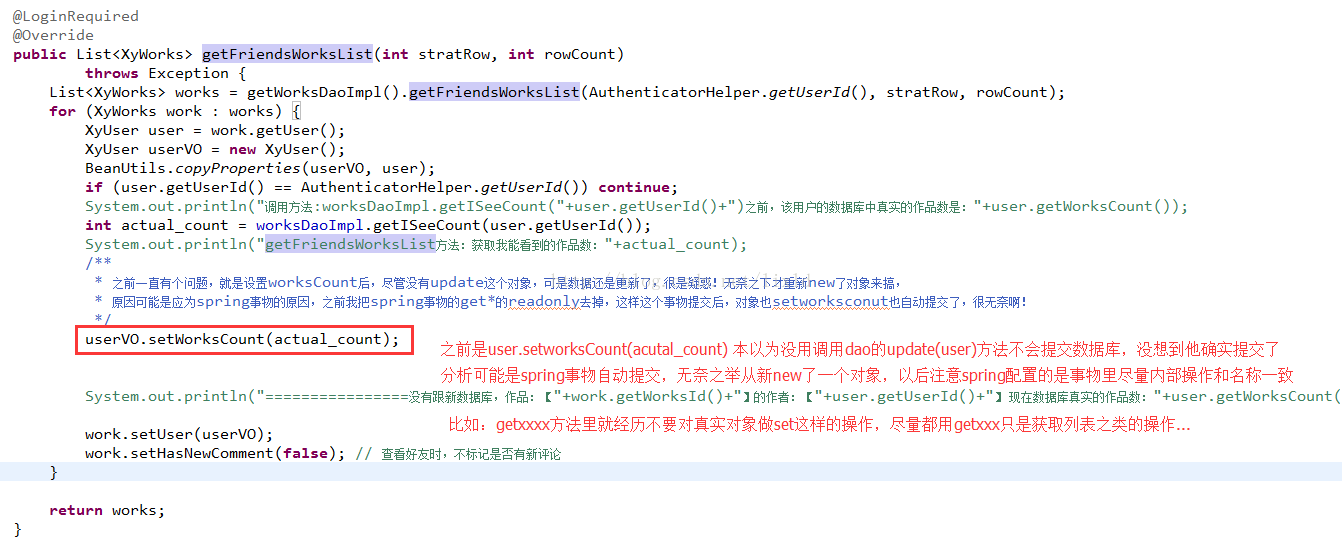
下面的代码,每次调用方法,数据库自动值就会跟新,很纳闷
我认为没有调用dao.update(user)这个对象,事务是提交不了的,可是每次调用结束,数据库都更新了
分析了下原因:如下:深刻教训,以后多吸取,
总结就是:spring控制事物,多安装名称中事物来做逻辑
getxxx里面尽量不能要set之类的更新操作。。
========================================================
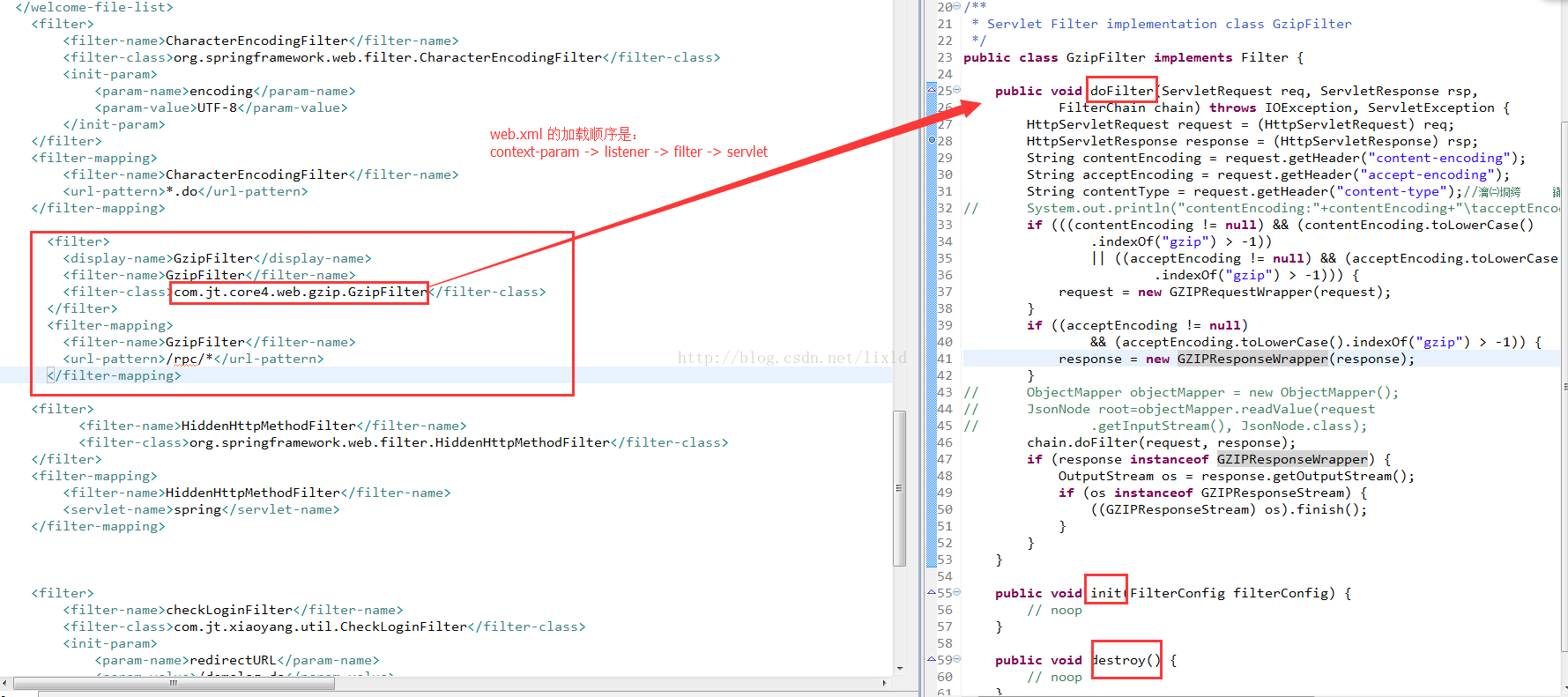
web.xml 的加载顺序是:context-param -> listener -> filter -> servlet ,
而同个类型之间的实际程序调用的时候的顺序是根据对应的 mapping 的顺序进行调用的。
下面是总结的很全面的一片文字:
http://www.cnblogs.com/JesseV/archive/2009/11/17/1605015.html














 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









