







集合框架
知识体系结构图
集合容器主要包括collection和Map两种,Collection存储着对象的集合,而Map存储着键值对的映射表
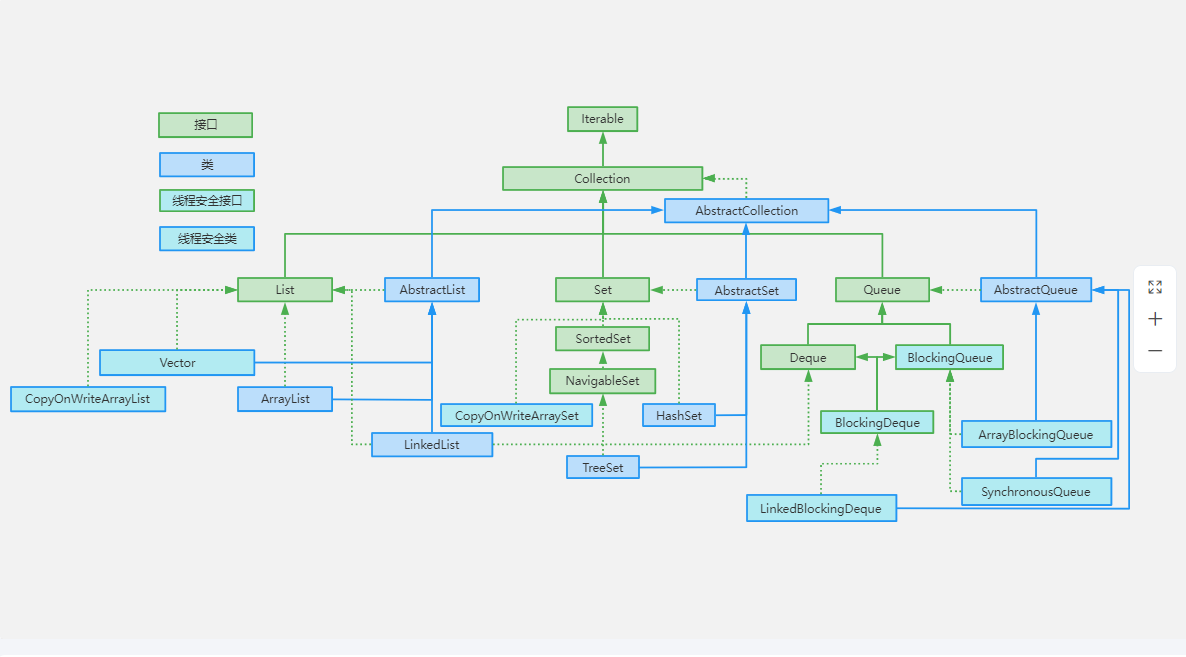
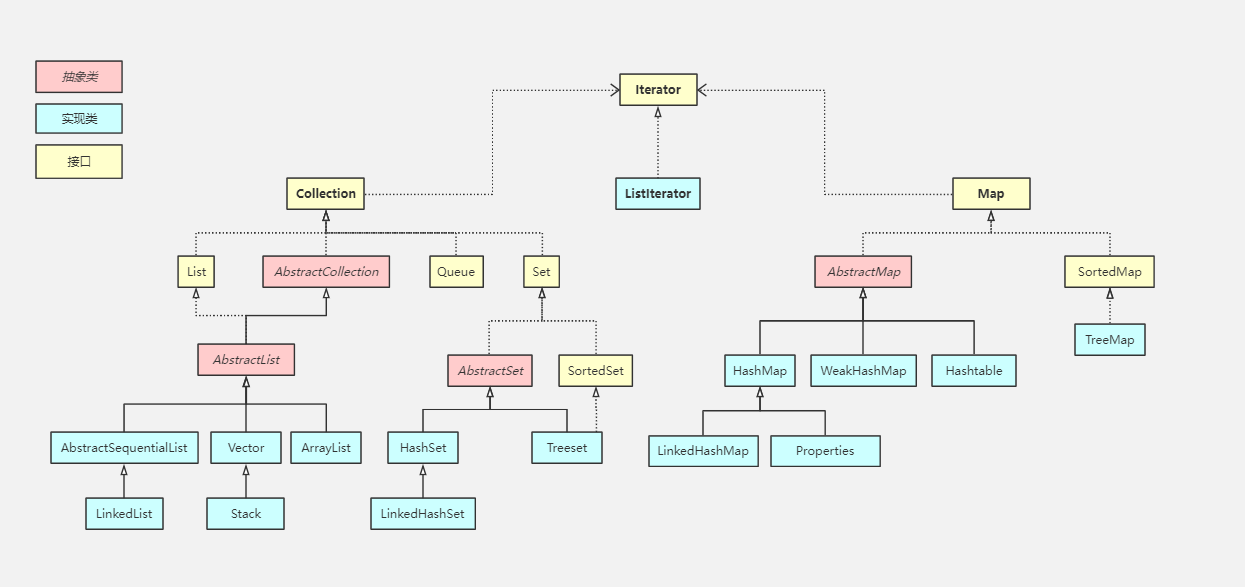
Collection
List
ArrayList
ArrayList实现了List接口,是顺序容器,即元素存放的数据与放进去的顺序相同,允许存Null元素,底层通过
数组实现(Object数组)。为追求效率,ArrayList没有实现同步(synchronized),如果需要多个线程并发访问,用户可以手动同步,也可使用Vector替代。
数组结构
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
//transient声明不序列化
transient Object[] elementData; // non-private to simplify nested class access
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
构造函数
/**
* Constructs an empty list with the specified initial capacity.
*
* @param initialCapacity the initial capacity of the list
* @throws IllegalArgumentException if the specified initial capacity
* is negative
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
自动扩容
每当向数组中添加元素时,都会去检查元素的个数是否超出数组的长度,如果超出,数组会进行扩容。数组通过ensureCapacity(int minCapacity)来实现扩容。 也可以手动调用ensureCapacity来扩容。
数组进行扩容时,会将老数组中的数据重新拷贝一份到新数组中,每次数组容器增长大约为原容器的1.5倍。
/**
* Increases the capacity of this <tt>ArrayList</tt> instance, if
* necessary, to ensure that it can hold at least the number of elements
* specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
public void ensureCapacity(int minCapacity) {
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
Vector
Vector与ArrayList类似,但它是线程安全的。使用Synchonized关键字保证线程安全
LinkedList
LinkedList实现了List接口和Deque接口,也就说它即可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack)。
LinkedList底层通过双向链表实现。
底层数据结构
// -------------------------------
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
Node内部类
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
Arraylist 和 Vector 的区别?
- ArrayList底层是
使用Object [] 存储,线程不安全。 - Vector底层也是使用Object[] 存储,但是他是线程安全的,使用Synchonized关键字保证同步。
ArrayList与LinkedList区别
- 线程是否安全: ArrayList和LinkedList都不是同步的,也就是县城不安全。
- 底层数据结构: ArrayList底层是Object[] 数组实现;而LinkendList底层使用的是双向链表。
- 对于查询来说Arraylist速度要优于LinkedList
- 对于新增和删除操作来说LinkedList要更快一些。
Set
TreeSet
TreeSet和Treemap有着相同的实现,前者只是对后者的一层包装。
TreeSet实现了SortedMap接口,也就是说按照key的大小顺序对Map的元素进行排序,key的大小可以通过其本身的自然顺序(natural ordering),也可以通过构造时传入的比较器(Comparator)。
TreeMap底层通过红黑树(Red-Black tree)实现
HashSet
HashSet和HashMap两者有着相同的实现,前者是对后者的一层包装。也就是说HashSet里面有一个HashMap(适配器)。
HashSet、LinkedHashSet 和、TreeSet 的区别
HashSet、LinkedHashSet 和 TreeSet 都是 Set 接口的实现类,都能保证元素唯一,并且都不是线程安全的。
HashSet、LinkedHashSet 和 TreeSet 的主要区别在于底层数据结构不同。HashSet 的底层数据结构是哈希表(基于 HashMap 实现)。LinkedHashSet 的底层数据结构是链表和哈希表,元素的插入和取出顺序满足 FIFO。TreeSet 底层数据结构是红黑树,元素是有序的,排序的方式有自然排序和定制排序。
底层数据结构不同又导致这三者的应用场景不同。HashSet 用于不需要保证元素插入和取出顺序的场景,LinkedHashSet 用于保证元素的插入和取出顺序满足 FIFO 的场景,TreeSet 用于支持对元素自定义排序规则的场景。
Map
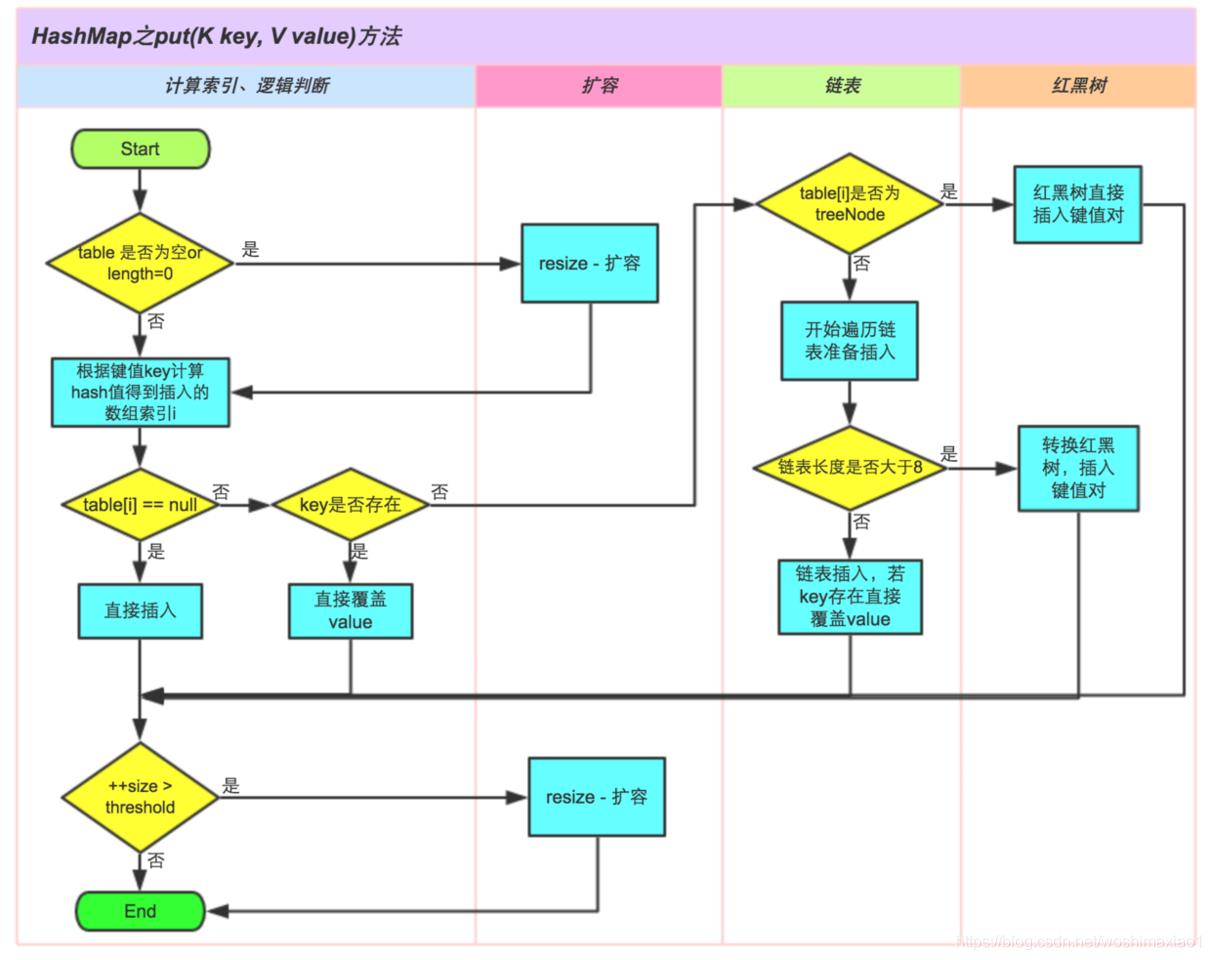
HashMap实现原理
我们都知道HashMap在
jdk1.7及以前采用的是数组+链表,1.8以后采用的是数组+链表+红黑树来实现的。在学习之前需要先了解一些数据结构。
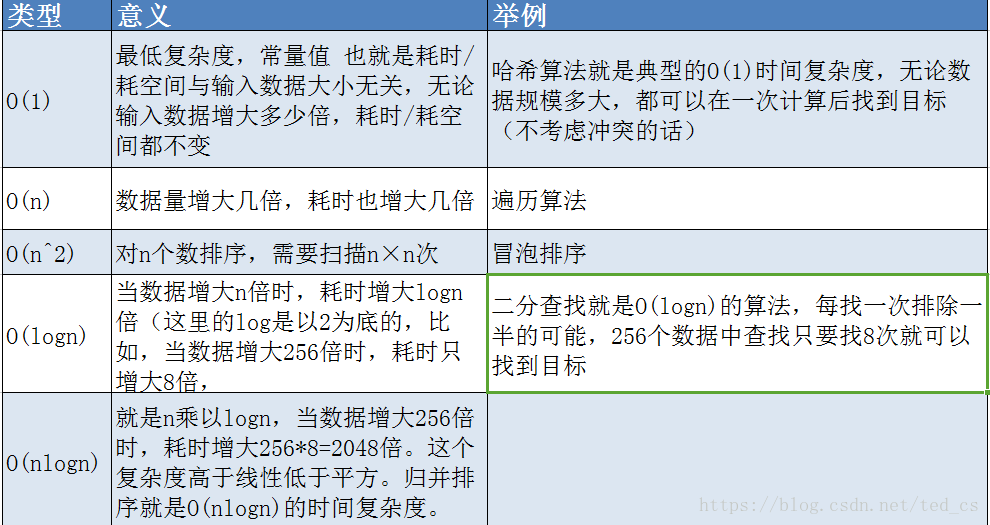
什么是哈希表?
**数组:**数组采用一段连续的存储单元来存储数据。对于指定下标的查找,其时间复杂度为O(1);通过定值来查找需要遍历数组,时间复杂度为O(n);
**链表:**对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)
**哈希表:**相对上面的数据结构,在hash表中进行添加、删除、查找等操作,性能十分之高,不考虑hash冲突的情况下,其时间复杂度为O(1); 哈希表的主干就是数组。 比如我们要新增或查找某个元素,我们通过把当前元素的关键字通过hash算法(某个函数)得到数组下标索引,从而确定元素的位置。
什么是哈希冲突?
如果两个不同的元素,通过哈希算法函数得到的存储地址相同就是哈希冲突。 hashmap使用数组+链表处理hash冲突。
HashMap
-
HashMap: JDK1.8 之前HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间 -
底层数组+链表实现,可以存储null键和null值,线程不安全
-
初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂
-
扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入
HashMap、Hashtable、ConcurrentHashMap的原理与区别
HashTable
- 底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化
- 初始size为11,扩容:newsize = olesize*2+1
HashMap
- 底层数组+链表实现,可以存储null键和null值,线程不安全
- 初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂
- 扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入
ConcurrentHashMap
- 底层采用分段的数组+链表实现,线程安全
- 通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。)
- Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术
- 有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁
- 扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容















 918
918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









