






免责声明:我日常开发过程中遇到的问题记录一下,不保证正确性。
/_cat/命令 访问 http://ip:port/_cat/:
/_cat/allocation #查看单节点的shard分配整体情况
/_cat/shards #查看各shard的详细情况
/_cat/shards/{index} #查看指定分片的详细情况
/_cat/master #查看master节点信息
/_cat/nodes #查看所有节点信息
/_cat/indices #查看集群中所有index的详细信息
/_cat/indices/{index} #查看集群中指定index的详细信息
/_cat/segments #查看各index的segment详细信息,包括segment名, 所属shard, 内存(磁盘)占用大小, 是否刷盘
/_cat/segments/{index}#查看指定index的segment详细信息
/_cat/count #查看当前集群的doc数量
/_cat/count/{index} #查看指定索引的doc数量
/_cat/recovery #查看集群内每个shard的recovery过程.调整replica。
/_cat/recovery/{index}#查看指定索引shard的recovery过程
/_cat/health #查看集群当前状态:红、黄、绿
/_cat/pending_tasks #查看当前集群的pending task
/_cat/aliases #查看集群中所有alias信息,路由配置等
/_cat/aliases/{alias} #查看指定索引的alias信息
/_cat/thread_pool #查看集群各节点内部不同类型的threadpool的统计信息,
/_cat/plugins #查看集群各个节点上的plugin信息
/_cat/fielddata #查看当前集群各个节点的fielddata内存使用情况
/_cat/fielddata/{fields} #查看指定field的内存使用情况,里面传field属性对应的值
/_cat/nodeattrs #查看单节点的自定义属性
/_cat/repositories #输出集群中注册快照存储库
/_cat/templates #输出当前正在存在的模板信息
我使用 http://ip:port/_cat/indices?v 查看索引:

查询索引中的所有文档:
http://ip:port/索引/_search?pretty
查询索引中指定参数的文档:
http://ip:port/索引/_search?q=要检索的字段名称:检索字段的值
如:http://ip:port/index/_search?q=id:114906 会单独返回id=114906这篇文档
查看索引信息:(我理解相当于关系型数据库的表结构)
http://ip:port/索引/_mappings
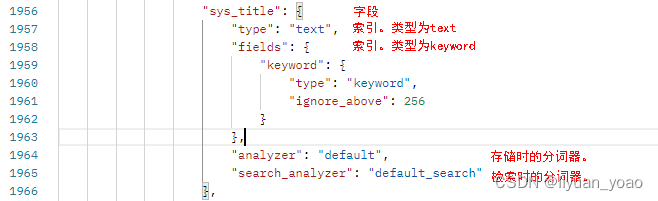
其中
text:可分词,不参与聚合
keyword:不可分词,数据会作为完整字段进行匹配,可参与聚合
在搜索时,通过下面参数依次检查搜索时使用的分词器:
- 搜索时指定
analyzer参数 - 创建mapping时指定字段的
search_analyzer属性 - 创建索引时指定
setting的analysis.analyzer.default_search - 查看创建索引时字段指定的
analyzer属性
如果上面几种都未设置,则使用默认的standard分词器。
对于搜索来说,如果analyzer、search_analyzer分词不一致,搜索是会出现不准确的问题的,搜索结果不是我们想要的。
查看索引 http://ip:port/索引/_settings

可见分词器确实不同,我们现在分别使用这个分词器来试着分词:
请求 http://ip:port/索引/_analyze
使用 index_ansj 分词器,参数:
{
"analyzer":"index_ansj",
"text":"我在使用搜索"
}
得到的结果是:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "r",
"position": 0
},
{
"token": "在",
"start_offset": 1,
"end_offset": 2,
"type": "p",
"position": 1
},
{
"token": "使用",
"start_offset": 2,
"end_offset": 4,
"type": "v",
"position": 2
},
{
"token": "使",
"start_offset": 2,
"end_offset": 3,
"type": "v",
"position": 3
},
{
"token": "用",
"start_offset": 3,
"end_offset": 4,
"type": "p",
"position": 4
},
{
"token": "搜索",
"start_offset": 4,
"end_offset": 6,
"type": "vn",
"position": 5
},
{
"token": "搜",
"start_offset": 4,
"end_offset": 5,
"type": "v",
"position": 6
},
{
"token": "索",
"start_offset": 5,
"end_offset": 6,
"type": "vg",
"position": 7
}
]
}
使用 query_ansj 分词器,参数:
{
"analyzer":"query_ansj",
"text":"我在使用搜索"
}
返回结果为:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "r",
"position": 0
},
{
"token": "在",
"start_offset": 1,
"end_offset": 2,
"type": "p",
"position": 1
},
{
"token": "使用",
"start_offset": 2,
"end_offset": 4,
"type": "v",
"position": 2
},
{
"token": "搜索",
"start_offset": 4,
"end_offset": 6,
"type": "vn",
"position": 3
}
]
}
结论:两种分词器不同。查询出现偏差,有的数据查不出来;
个人理解:
查询时,检索字段为”使用搜索“,不指定分词器的情况下,这里默认用query_ansj;
使用 match_phrase 来搜索,我发现我是搜索不到的,
短词:使用、搜索,它的顺序不能乱,要相邻。
------------------------------------------------2023-11-16记录------------------------------------------
1、索引相当于一本书的目录,分词器来创建目录。所以分词器没有优劣之分,根据业务场景来选择分词器构建索引;
2、检索时分词器的使用,也很重要,并不是可有可无的。
shouldBuilder.should(QueryBuilders.matchPhraseQuery("sys_title.search", keyword).analyzer("default_search").slop(10).boost(2000f));这段代码使用matchPhraseQuery,它指定了分词器.analyzer("default_search"),它代表要对检索的关键字进行分词,分词后去匹配索引。
例如:一段文字“我在使用搜索”,使用index_ansj分词器,分出的词为:“我”、“在”、“使用”、“使”、“用”、“搜索”、“搜”、“索”。
检索关键字“使用搜索”使用query_ansj分词器,被分出“使用”、“搜索”两个词。使用matchPhraseQuery(match_phrase)匹配时,“使用”、“搜索”两个词的顺序不能乱且要连续,索引里必须是“使用”后面紧跟“搜索”才能匹配到。而我们用index_ansj分词器构建出的索引“使用”后面跟的是“使”,这不会被匹配上。
那要是使用matchQuery(match)匹配呢?答案肯定是可以匹配出来啊,match的匹配比较宽松,能命中一个词就行。
小结:使用什么分词器,使用什么匹配模式,我理解还不够,根据自己的业务来使用分词器和匹配模式。
例如我们想实现单个字的匹配,类似数据库那种LIKE模式,则应该使用index_ansj分词器,匹配就用match。如果不相匹配太多无用的结果,命中精确度要高一些,使用query_ansj分词器,匹配就用match_phrase。但是query_ansj分词器也有自己的问题,例如“使用”、“搜索”两个分词结果,假设我检索关键字是“用搜”,这是匹配不到的。
灵活运用:假设业务要做到联想搜索怎么办?例如我搜关键字“快”,我期望“快”、“迅速”、“高速”、“光速”、“慢”等等跟速度相关的都被检索出来。index_ansj分词器尽量细分,检索时把输入的关键字“快”指定特定的分词器来分词(例如近义词分词器、反义词分词器,这个怎么写代码我没有实际操作,但是肯定可以),最后关键字“快”被分出一系列跟速度相关的词即可。















 3586
3586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









