







For English, it’s quite straightforward that whiespace can be used to break sentences to words, but for Chinese it’s a little more complex since different breaks can change the meaning totally…
Thanks to SmartChineseAnalyzer shipped with solr6.2.1, we can do Chinese words out of box, the using of SmartChineseAnalyzer is list as below:
1.Add the lib to solr server
cp $SOLR_HOME/contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-6.2.1.jar $SOLR_HOME/server/solr-webapp/webapp/WEB-INF/lib/2.Add field type & field definition in managed-schema
<fieldType name="text_scn" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="org/apache/lucene/analysis/cn/smart/stopwords.txt" ignoreCase="true"/>
</analyzer>
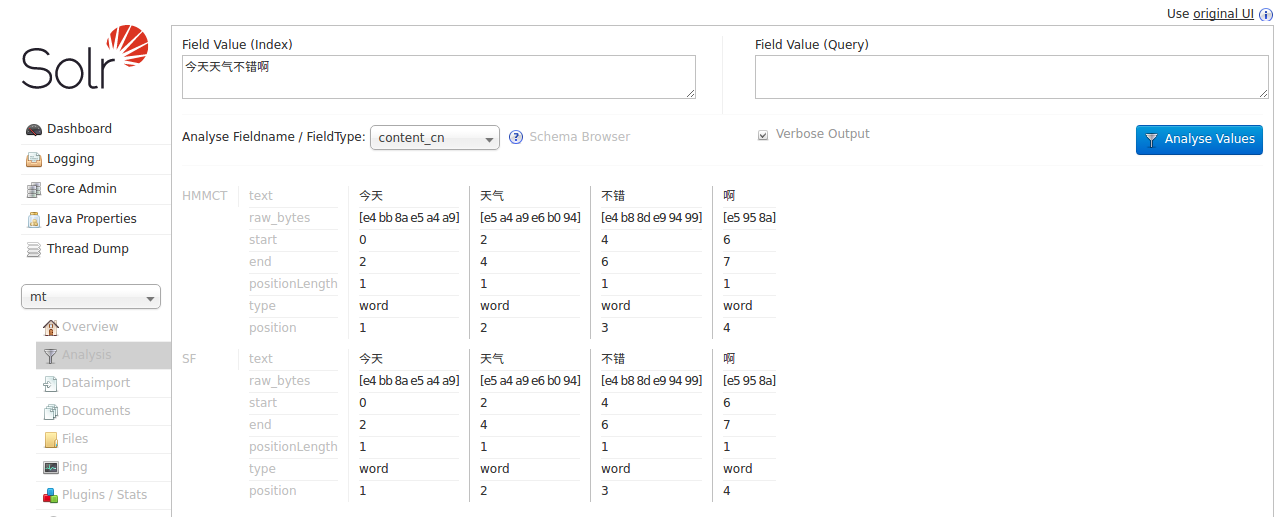
</fieldType><field name="content_cn" type="text_scn" indexed="true" stored="true"/>3.Start solr, navigate to Test it















 879
879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









