







实验-Lab4-Shard KV Service
ShardCtler
shardCtler 是一个分片控制器,利用raft进行配置的统一,下面是 ShardCtler 的总体架构:
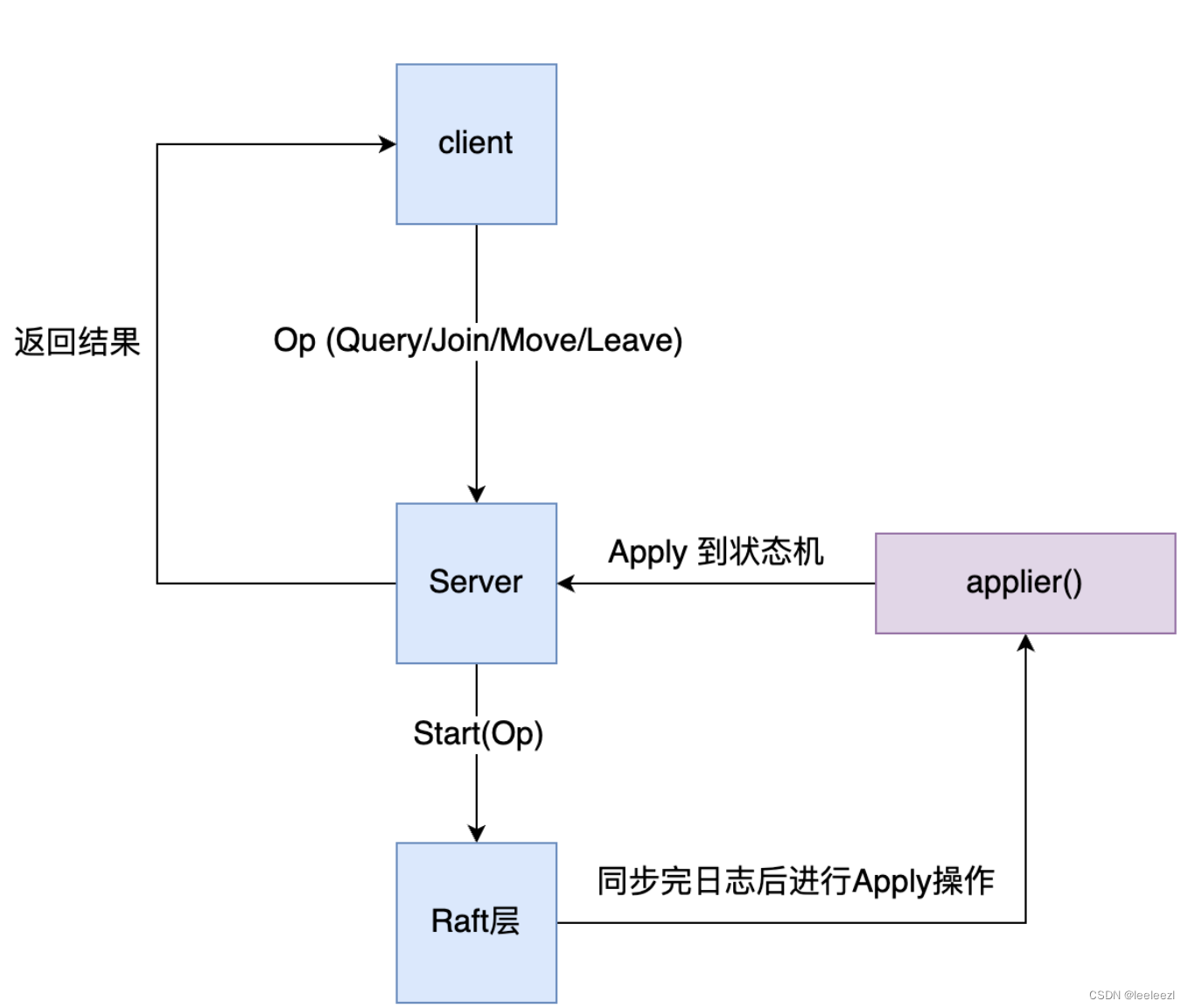
客户端
客户端的主要作用就是发送请求给服务端,其中请求中包含的操作有 Query/Join/Move/Leave,即查询当前配置信息,加入新的 group,移动分片和删除 group,我们将这四类请求都使用一个 RPC Request 进行封装,这样可以简化程序
type CommandRequest struct {
Servers map[int][]string // for Join
GIDs []int // for Leave
Shard int // for Move
GID int // for Move
Num int // for Query
Op OperationOp
ClientId int64
CommandId int64
}
type CommandResponse struct {
Err Err
Config Config
}
此外,同 Lab3 一样,我们依然使用一个(clientId,commandId)唯一确定一个客户端,shardCtler 客户端的实现和 Lab3 客户端的实现大同小异,将 Lab3 中的 get/put 换成 Query/Join/Move/Leave 即可.而且shardCtler 中并没有快照的逻辑
状态机
状态机中维护了 MemoryConfigStateMachine ,包含了配置相关的数据,客户端的操作最终都会落在状态机上,此外,状态机中要有处理 Join/Leave/Query/Move 的逻辑。
type MemoryConfigStateMachine struct {
Configs []Config
}
type Config struct {
Num int // config number
Shards [NShards]int // shard -> gid
Groups map[int][]string // gid -> servers[]
}
Join 的处理逻辑:将新的 gid --> servers[],加入到新的 Config 中对于,新加入的 group 为了保证负载均衡,需要将 shard 分配地更为均匀且尽量产生较少的迁移任务。对于 Join,可以通过多次平均地方式来达到这个目的:每次选择一个拥有 shard 数最多的 raft 组和一个拥有 shard 数最少的 raft 组,将前者管理的一个 shard 分给后者,周而复始,直到它们之前的差值小于等于 1 且 0 raft 组无 shard 为止。
func (cf *MemoryConfigStateMachine) Join(groups map[int][]string) Err {
//取到上一个的config
lastConfig := cf.Configs[len(cf.Configs)-1]
newConfig := Config{len(cf.Configs), lastConfig.Shards, deepCopy(lastConfig.Groups)}
for gid, servers := range groups {
if _, ok := newConfig.Groups[gid]; !ok {
//加入
newServers := make([]string, len(servers))
copy(newServers, servers)
newConfig.Groups[gid] = newServers
}
}
//得到 shard->group的映射
s2g := Group2Shards(newConfig)
//循环 知道最大分片数量的group 和最小分片数量的group的分片数相差 <=1
for {
//找到分片最多和分片最少得 group
source, target := GetGIDWithMaximumShards(s2g), GetGIDWithMinimumShards(s2g)
if source != 0 && len(s2g[source])-len(s2g[target]) <= 1 {
break
}
s2g[target] = append(s2g[target], s2g[source][0])
s2g[source] = s2g[source][1:]
}
// 拿到分片调整后的新分片
var newShards [NShards]int
for gid, shards := range s2g {
for _, shard := range shards {
newShards[shard] = gid
}
}
//将新的分片更新到新config中
newConfig.Shards = newShards
cf.Configs = append(cf.Configs, newConfig)
return OK
}
Leave 的处理逻辑:有 raft 组离开后,我们需要对离开的 raft 组的 shard 进行分配,如果 Leave 后集群中无 raft 组,则将分片所属 raft 组都置为无效的 0;否则将删除 raft 组的分片均匀地分配给仍然存在的 raft 组。通过这样的分配,可以将 shard 分配地十分均匀且产生了几乎最少的迁移任务。
func (cf *MemoryConfigStateMachine) Leave(gids []int) Err {
lastConfig := cf.Configs[len(cf.Configs)-1]
newConfig := Config{len(cf.Configs), lastConfig.Shards, deepCopy(lastConfig.Groups)}
s2g := Group2Shards(newConfig)
orphanShards := make([]int, 0)
for _, gid := range gids {
if _, ok := newConfig.Groups[gid]; ok {
delete(newConfig.Groups, gid)
}
if shards, ok := s2g[gid]; ok {
orphanShards = append(orphanShards, shards...)
delete(s2g, gid)
}
}
var newShards [NShards]int
// load balancing is performed only when raft groups exist
if len(newConfig.Groups) != 0 {
for _, shard := range orphanShards {
target := GetGIDWithMinimumShards(s2g)
s2g[target] = append(s2g[target], shard)
}
for gid, shards := range s2g {
for _, shard := range shards {
newShards[shard] = gid
}
}
}
newConfig.Shards = newShards
cf.Configs = append(cf.Configs, newConfig)
return OK
}
对于 Query 和 Move,直接实现就好:
func (cf *MemoryConfigStateMachine) Move(shard, gid int) Err {
lastConfig := cf.Configs[len(cf.Configs)-1]
newConfig := Config{len(cf.Configs), lastConfig.Shards, deepCopy(lastConfig.Groups)}
newConfig.Shards[shard] = gid
cf.Configs = append(cf.Configs, newConfig)
return OK
}
func (cf *MemoryConfigStateMachine) Query(num int) (Config, Err) {
if num < 0 || num >= len(cf.Configs) {
return cf.Configs[len(cf.Configs)-1], OK
}
return cf.Configs[num], OK
}
服务端
服务端要做的就是,提供一个 Rpc 接口 Command(request *CommandRequest, response *CommandResponse),客户端通过 Rpc 将请求发送给服务端,服务端处理请求时,首先会判断请求是否是重复的,如果是重复的会返回上一次的结果,不进行 Raft 集群的日志同步操作,若是新的请求,服务端会将请求发送给 Raft 集群进行日志的同步,随后 Server 立即开启一个 Channel 来监听结果,Leader 提交日之后可以进行 Apply,服务端在启动时,会启动 applier 协程去监听 applyChan,当有 applyMsg 后,Server 会将操作 apply 到状态机,随后通过 index 取到 server 开启的 Channel,将状态机返回的结果发送至这个 Channel,取到结果后返回客户端。
Command(request *CommandRequest, response *CommandResponse) RPC 接口:
func (sc *ShardCtrler) Command(request *CommandRequest, response *CommandResponse) {
defer DPrintf("{Node %v}'s state is {}, processes CommandRequest %v with CommandResponse %v", sc.rf.Me(), request, response)
// return result directly without raft layer's participation if request is duplicated
sc.mu.RLock()
// 如果是重复请求直接返回之前的结果
if request.Op != OpQuery && sc.isDuplicateRequest(request.ClientId, request.CommandId) {
lastResponse := sc.lastOperations[request.ClientId].LastResponse
response.Config, response.Err = lastResponse.Config, lastResponse.Err
sc.mu.RUnlock()
return
}
sc.mu.RUnlock()
// do not hold lock to improve throughput
//这里进入到raft的逻辑,服务端会监听applyChan, raft处理完日志之后会提交操作到applychan
index, _, isLeader := sc.rf.Start(Command{request})
if !isLeader {
response.Err = ErrWrongLeader
return
}
sc.mu.Lock()
ch := sc.getNotifyChan(index)
sc.mu.Unlock()
select {
case result := <-ch:
response.Config, response.Err = result.Config, result.Err
case <-time.After(ExecuteTimeout):
response.Err = ErrTimeout
}
// release notifyChan to reduce memory footprint
// why asynchronously? to improve throughput, here is no need to block client request
go func() {
sc.mu.Lock()
sc.removeOutdatedNotifyChan(index)
sc.mu.Unlock()
}()
}
applier()协程:
func (sc *ShardCtrler) applier() {
for sc.killed() == false {
select {
// raft 提交了
case message := <-sc.applyCh:
DPrintf("{Node %v} tries to apply message %v", sc.rf.Me(), message)
//判断是操作还是快照
if message.CommandValid {
var response *CommandResponse
//将interface{} 转为 CommandRequest
command := message.Command.(Command)
sc.mu.Lock()
if command.Op != OpQuery && sc.isDuplicateRequest(command.ClientId, command.CommandId) {
DPrintf("{Node %v} doesn't apply duplicated message %v to stateMachine because maxAppliedCommandId is %v for client %v", sc.rf.Me(), message, sc.lastOperations[command.ClientId], command.ClientId)
response = sc.lastOperations[command.ClientId].LastResponse
} else {
// 应用到状态机中
response = sc.applyLogToStateMachine(command)
if command.Op != OpQuery {
sc.lastOperations[command.ClientId] = OperationContext{command.CommandId, response}
}
}
// only notify related channel for currentTerm's log when node is leader
// 将结果发送到 notifyChan
if currentTerm, isLeader := sc.rf.GetState(); isLeader && message.CommandTerm == currentTerm {
ch := sc.getNotifyChan(message.CommandIndex)
ch <- response
}
sc.mu.Unlock()
} else {
panic(fmt.Sprintf("unexpected Message %v", message))
}
}
}
}
ShardKV
整体架构
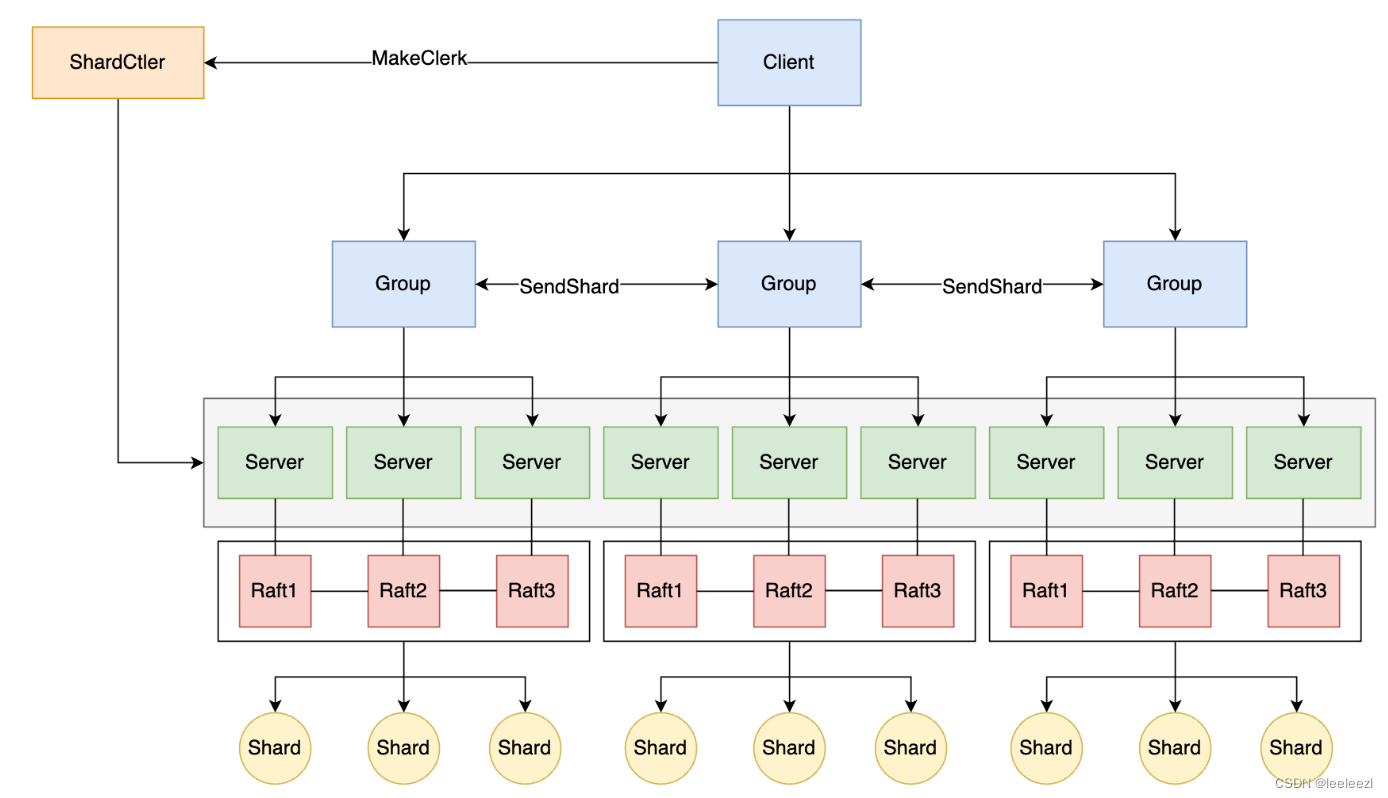
client
client 发送 Get/Put/Append 请求,客户端会将请求中的 key 通过 key2shard 方法,定位到这个 key 应该存储到哪个 shard 中,并通过 shard 找到管理这个分片的 group,随后通过 gid 找打 leader server 将请求通过 Rpc 发送给服务器。
func (ck *Clerk) Command(request *CommandRequest) string {
request.ClientId, request.CommandId = ck.clientId, ck.commandId
for {
// 找到这个key对应于哪个分片
shard := key2shard(request.Key)
// 找到分片对应的group
gid := ck.config.Shards[shard]
if servers, ok := ck.config.Groups[gid]; ok {
if _, ok = ck.leaderIds[gid]; !ok {
ck.leaderIds[gid] = 0
}
oldLeaderId := ck.leaderIds[gid]
newLeaderId := oldLeaderId
for {
var response CommandResponse
ok := ck.makeEnd(servers[newLeaderId]).Call("ShardKV.Command", request, &response)
if ok && (response.Err == OK || response.Err == ErrNoKey) {
ck.commandId++
return response.Value
} else if ok && response.Err == ErrWrongGroup {
break
} else {
newLeaderId = (newLeaderId + 1) % len(servers)
if newLeaderId == oldLeaderId {
break
}
continue
}
}
}
time.Sleep(100 * time.Millisecond)
// ask controller for the latest configuration.
ck.config = ck.sm.Query(-1)
}
}
服务端
服务端的逻辑相对复杂,服务端不仅要处理来自客户端的对分片的读写请求,还要有负责监测配置更新的协程,负责分片迁移的协程和负责及时清理不再属于本分片的数据的协程。
Lab4 有两个 challenge:
- challenge1 要求及时清理不再属于本分片的数据
- challenge2 不仅要求分片迁移时不影响未迁移分片的读写服务,还要求不同地分片数据能够独立迁移
解决方案:
- 每个 raft 组需要有一个协程去向 shardctler 拉去最新的配置,一旦拉取到最新的配置,就要提交到当前 raft 组中更新配置
- 为了解决两个 challenge 我们需要将分片独立,因此,ShardKV 应该对每个分片额外维护其它的一些状态变量。对分片的状态进行分类:
Serving:默认状态,表示这个分片是由这个 raft 组负责管理的,并且可以进行读写操作Pulling:表示这个分片是由这个 raft 组负责管理的,但是这个分片的数据当前并不在这个 Raft 组,需要到lastConfig中负责管理这个分片的 raft 组中去拉去数据BePulling:表示当前这个分片不是由这个 raft 进行管理的,但是当前 raft 组在上一个 config 中是负责管理这个分片的GCing:表示当前这个分片是由这个 raft 组进行管理的,可以进行正常的读写操作,但需要清理掉上一个配置该分片所属 raft 组的数据
日志类型:
一共有五中日志类型,这样 apply 协程可以根据不同的类型来强转 Data 来实现下一步的操作:
- Operation:客户端传来的读写操作,Put/Get/Append
- Configuration:配置更新日志,包含一个配置
- InsertShard:分片更新日志,至少包含一个分片的数据和配置版本
- DeleteShard:分片删除日志,至少包含一个分片的 Id 和配置版本
- EmptyEntry:空日志,Data 为空,使得状态机达到最新
以上即为服务端的实现,首先看一下服务端启动的实现:
func StartServer(servers []*labrpc.ClientEnd, me int, persister *raft.Persister, maxRaftState int, gid int, ctrlers []*labrpc.ClientEnd, makeEnd func(string) *labrpc.ClientEnd) *ShardKV {
// call labgob.Register on structures you want
// Go's RPC library to marshall/unmarshall.
labgob.Register(Command{})
labgob.Register(CommandRequest{})
labgob.Register(shardctrler.Config{})
labgob.Register(ShardOperationResponse{})
labgob.Register(ShardOperationRequest{})
applyCh := make(chan raft.ApplyMsg)
kv := &ShardKV{
dead: 0,
rf: raft.Make(servers, me, persister, applyCh),
applyCh: applyCh,
makeEnd: makeEnd,
gid: gid,
sc: shardctrler.MakeClerk(ctrlers),
lastApplied: 0,
maxRaftState: maxRaftState,
currentConfig: shardctrler.DefaultConfig(),
lastConfig: shardctrler.DefaultConfig(),
stateMachines: make(map[int]*Shard),
lastOperations: make(map[int64]OperationContext),
notifyChans: make(map[int]chan *CommandResponse),
}
kv.restoreSnapshot(persister.ReadSnapshot())
// start applier goroutine to apply committed logs to stateMachine
go kv.applier()
// start configuration monitor goroutine to fetch latest configuration
go kv.Monitor(kv.configureAction, ConfigureMonitorTimeout)
// start migration monitor goroutine to pull related shards
go kv.Monitor(kv.migrationAction, MigrationMonitorTimeout)
// start gc monitor goroutine to delete useless shards in remote groups
go kv.Monitor(kv.gcAction, GCMonitorTimeout)
// start entry-in-currentTerm monitor goroutine to advance commitIndex by appending empty entries in current term periodically to avoid live locks
//启动entry-in-currentTerm monitor例程,通过定期在当前term中添加空条目来推进commitIndex,以避免活锁
go kv.Monitor(kv.checkEntryInCurrentTermAction, EmptyEntryDetectorTimeout)
DPrintf("{Node %v}{Group %v} has started", kv.rf.Me(), kv.gid)
return kv
}
再看一下appler(),比较清晰:
func (kv *ShardKV) applier() {
for kv.killed() == false {
select {
case message := <-kv.applyCh:
DPrintf("{Node %v}{Group %v} tries to apply message %v", kv.rf.Me(), kv.gid, message)
if message.CommandValid {
kv.mu.Lock()
if message.CommandIndex <= kv.lastApplied {
DPrintf("{Node %v}{Group %v} discards outdated message %v because a newer snapshot which lastApplied is %v has been restored", kv.rf.Me(), kv.gid, message, kv.lastApplied)
kv.mu.Unlock()
continue
}
kv.lastApplied = message.CommandIndex
var response *CommandResponse
command := message.Command.(Command) //包括 Op 和 Data
switch command.Op {
case Operation:
operation := command.Data.(CommandRequest)
response = kv.applyOperation(&message, &operation)
case Configuration:
nextConfig := command.Data.(shardctrler.Config)
response = kv.applyConfiguration(&nextConfig)
case InsertShards:
shardsInfo := command.Data.(ShardOperationResponse)
response = kv.applyInsertShards(&shardsInfo)
case DeleteShards:
shardsInfo := command.Data.(ShardOperationRequest)
response = kv.applyDeleteShards(&shardsInfo)
case EmptyEntry:
response = kv.applyEmptyEntry()
}
// only notify related channel for currentTerm's log when node is leader
if currentTerm, isLeader := kv.rf.GetState(); isLeader && message.CommandTerm == currentTerm {
ch := kv.getNotifyChan(message.CommandIndex)
ch <- response
}
needSnapshot := kv.needSnapshot()
if needSnapshot {
kv.takeSnapshot(message.CommandIndex)
}
kv.mu.Unlock()
} else if message.SnapshotValid {
kv.mu.Lock()
if kv.rf.CondInstallSnapshot(message.SnapshotTerm, message.SnapshotIndex, message.Snapshot) {
kv.restoreSnapshot(message.Snapshot)
kv.lastApplied = message.SnapshotIndex
}
kv.mu.Unlock()
} else {
panic(fmt.Sprintf("unexpected Message %v", message))
}
}
}
}
配置更新协程的工作流程:
首先服务启动的时候就启动了一个检测配置更新协程go kv.Monitor(kv.configureAction, ConfigureMonitorTimeout),检测配置更新协程会去遍历 kv.stateMachines 中的每个分片(shard)。对于每个分片,它检查其状态是否为 “Serving”。如果有任何一个分片的状态不是 “Serving”,则不进配置的拉去,待所有分片的状态都为 “Serving” 后进行配置的拉去,如果有新的配置,则立刻进行 Raft 的日志的同步,更新配置。
//配置更新协程
func (kv *ShardKV) configureAction() {
canPerformNextConfig := true
kv.mu.RLock()
for _, shard := range kv.stateMachines {
if shard.Status != Serving {
canPerformNextConfig = false
DPrintf("{Node %v}{Group %v} will not try to fetch latest configuration because shards status are %v when currentConfig is %v", kv.rf.Me(), kv.gid, kv.getShardStatus(), kv.currentConfig)
break
}
}
currentConfigNum := kv.currentConfig.Num
kv.mu.RUnlock()
if canPerformNextConfig {
nextConfig := kv.sc.Query(currentConfigNum + 1)
if nextConfig.Num == currentConfigNum+1 {
DPrintf("{Node %v}{Group %v} fetches latest configuration %v when currentConfigNum is %v", kv.rf.Me(), kv.gid, nextConfig, currentConfigNum)
kv.Execute(NewConfigurationCommand(&nextConfig), &CommandResponse{})
}
}
}
func (kv *ShardKV) Execute(command Command, response *CommandResponse) {
// do not hold lock to improve throughput
// when KVServer holds the lock to take snapshot, underlying raft can still commit raft logs
index, _, isLeader := kv.rf.Start(command)
if !isLeader {
response.Err = ErrWrongLeader
return
}
defer DPrintf("{Node %v}{Group %v} processes Command %v with CommandResponse %v", kv.rf.Me(), kv.gid, command, response)
kv.mu.Lock()
ch := kv.getNotifyChan(index)
kv.mu.Unlock()
select {
case result := <-ch:
response.Value, response.Err = result.Value, result.Err
case <-time.After(ExecuteTimeout):
response.Err = ErrTimeout
}
// release notifyChan to reduce memory footprint
// why asynchronously? to improve throughput, here is no need to block client request
go func() {
kv.mu.Lock()
kv.removeOutdatedNotifyChan(index)
kv.mu.Unlock()
}()
}
分片迁移协程的工作流程:
分片迁移协程负责定时检测分片的 Pulling 状态,利用 lastConfig 计算出对应 raft 组的 gid 和要拉取的分片,然后并行地去拉取数据,使用了 waitGroup 来保证所有独立地任务完成后才会进行下一次任务
func (kv *ShardKV) migrationAction() {
kv.mu.RLock()
//获取状态为 pulling 的分片
gid2shardIDs := kv.getShardIDsByStatus(Pulling)
// 使用了 waitGroup 来保证所有独立地任务完成后才会进行下一次任务
var wg sync.WaitGroup
for gid, shardIDs := range gid2shardIDs {
DPrintf("{Node %v}{Group %v} starts a PullTask to get shards %v from group %v when config is %v", kv.rf.Me(), kv.gid, shardIDs, gid, kv.currentConfig)
wg.Add(1)
go func(servers []string, configNum int, shardIDs []int) {
defer wg.Done()
pullTaskRequest := ShardOperationRequest{configNum, shardIDs}
for _, server := range servers {
var pullTaskResponse ShardOperationResponse
srv := kv.makeEnd(server)
if srv.Call("ShardKV.GetShardsData", &pullTaskRequest, &pullTaskResponse) && pullTaskResponse.Err == OK {
DPrintf("{Node %v}{Group %v} gets a PullTaskResponse %v and tries to commit it when currentConfigNum is %v", kv.rf.Me(), kv.gid, pullTaskResponse, configNum)
kv.Execute(NewInsertShardsCommand(&pullTaskResponse), &CommandResponse{})
}
}
}(kv.lastConfig.Groups[gid], kv.currentConfig.Num, shardIDs)
}
kv.mu.RUnlock()
wg.Wait()
}
分片清理工作流程:
分片清理协程负责定时检测分片的 GCing 状态,利用 lastConfig 计算出对应 raft 组的 gid 和要拉取的分片,然后并行地去删除分片。
func (kv *ShardKV) gcAction() {
kv.mu.RLock()
gid2shardIDs := kv.getShardIDsByStatus(GCing)
var wg sync.WaitGroup
for gid, shardIDs := range gid2shardIDs {
DPrintf("{Node %v}{Group %v} starts a GCTask to delete shards %v in group %v when config is %v", kv.rf.Me(), kv.gid, shardIDs, gid, kv.currentConfig)
wg.Add(1)
go func(servers []string, configNum int, shardIDs []int) {
defer wg.Done()
gcTaskRequest := ShardOperationRequest{configNum, shardIDs}
for _, server := range servers {
var gcTaskResponse ShardOperationResponse
srv := kv.makeEnd(server)
if srv.Call("ShardKV.DeleteShardsData", &gcTaskRequest, &gcTaskResponse) && gcTaskResponse.Err == OK {
DPrintf("{Node %v}{Group %v} deletes shards %v in remote group successfully when currentConfigNum is %v", kv.rf.Me(), kv.gid, shardIDs, configNum)
kv.Execute(NewDeleteShardsCommand(&gcTaskRequest), &CommandResponse{})
}
}
}(kv.lastConfig.Groups[gid], kv.currentConfig.Num, shardIDs)
}
kv.mu.RUnlock()
wg.Wait()
}
func (kv *ShardKV) DeleteShardsData(request *ShardOperationRequest, response *ShardOperationResponse) {
// only delete shards when role is leader
if _, isLeader := kv.rf.GetState(); !isLeader {
response.Err = ErrWrongLeader
return
}
defer DPrintf("{Node %v}{Group %v} processes GCTaskRequest %v with response %v", kv.rf.Me(), kv.gid, request, response)
kv.mu.RLock()
if kv.currentConfig.Num > request.ConfigNum {
DPrintf("{Node %v}{Group %v}'s encounters duplicated shards deletion %v when currentConfig is %v", kv.rf.Me(), kv.gid, request, kv.currentConfig)
response.Err = OK
kv.mu.RUnlock()
return
}
kv.mu.RUnlock()
var commandResponse CommandResponse
kv.Execute(NewDeleteShardsCommand(request), &commandResponse)
response.Err = commandResponse.Err
}
func (kv *ShardKV) applyDeleteShards(shardsInfo *ShardOperationRequest) *CommandResponse {
if shardsInfo.ConfigNum == kv.currentConfig.Num {
DPrintf("{Node %v}{Group %v}'s shards status are %v before accepting shards deletion %v when currentConfig is %v", kv.rf.Me(), kv.gid, kv.getShardStatus(), shardsInfo, kv.currentConfig)
for _, shardId := range shardsInfo.ShardIDs {
shard := kv.stateMachines[shardId]
if shard.Status == GCing {
shard.Status = Serving
} else if shard.Status == BePulling {
kv.stateMachines[shardId] = NewShard()
} else {
DPrintf("{Node %v}{Group %v} encounters duplicated shards deletion %v when currentConfig is %v", kv.rf.Me(), kv.gid, shardsInfo, kv.currentConfig)
break
}
}
DPrintf("{Node %v}{Group %v}'s shards status are %v after accepting shards deletion %v when currentConfig is %v", kv.rf.Me(), kv.gid, kv.getShardStatus(), shardsInfo, kv.currentConfig)
return &CommandResponse{OK, ""}
}
DPrintf("{Node %v}{Group %v}'s encounters duplicated shards deletion %v when currentConfig is %v", kv.rf.Me(), kv.gid, shardsInfo, kv.currentConfig)
return &CommandResponse{OK, ""}
}















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









