







 本文介绍了一个爬虫程序中出现IncompleteRead错误的原因及解决方案。错误发生在使用read()方法时,由于读取字节数不足导致。通过调整read()方法参数,成功解决了该问题。
本文介绍了一个爬虫程序中出现IncompleteRead错误的原因及解决方案。错误发生在使用read()方法时,由于读取字节数不足导致。通过调整read()方法参数,成功解决了该问题。
在执行一个爬虫程序时,出现了IncompleteRead的报错:
IncompleteRead: IncompleteRead(196171 bytes read, 209626 more expected)
download代码如下:
def download(url, user_agent='Mozilla/5.0 (X11; Linux x86_64; rv:38.0) Gecko/20100101 Firefox/38.0',num_retries=2):
headers = {'User-agent': user_agent}
request = urllib.request.Request(url, headers=headers)
try:
html = urllib.request.urlopen(request).read()
except urllib.request.URLError as e:
print ('Downloading error:', e.reason)
html = None
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
return download(url, num_retries -1)
return html报错如下:
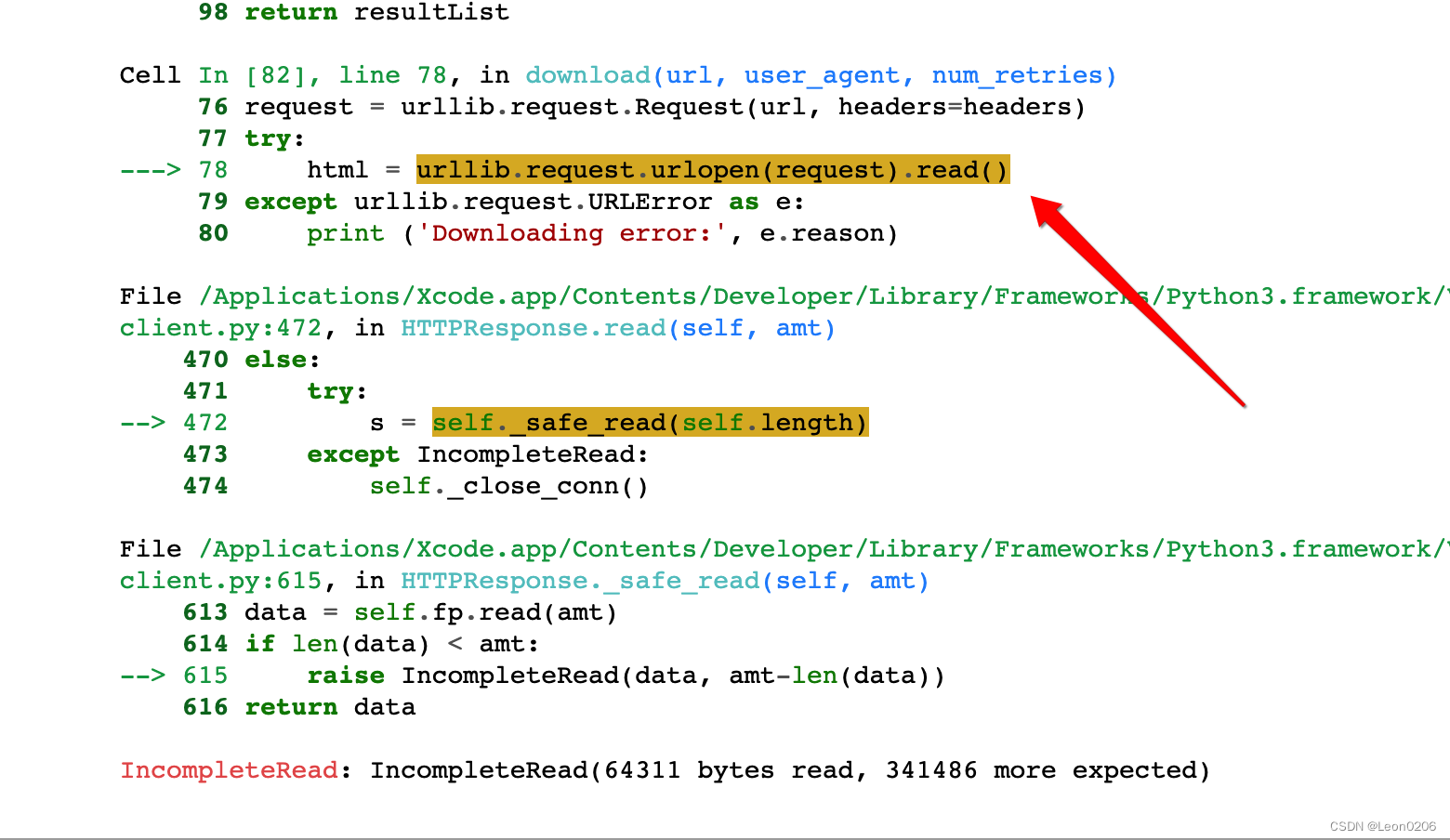
经过调试,是read()方法报错,这个网页返回的response有341486个字节,但是读到64311个字节时就终止,并提示“imcompleteRead错误”,大概率是因为超时了。看到有人通过延长timeout来解决,这个不推荐,因为这个值太大太小都没意义。
查阅了文档,发现read()这个方法可以指定读取字节数来控制,read(10),所以最终我是这样解决的:
resp = urllib.request.urlopen(request)
html = resp.read(resp.length)目前验证下来,没有报错。

















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









