







引言
首先先思考一个问题: 一个APP展示出来的数据是从哪里获取的?
数据来的来源一般分为两种, 一种是本地读取, 一种是网络请求.
本地读取是静态的, 除非手动更改数据的源数据 否则显示的内容是一直不变的. 这种数据称为假数据.
另一种是通过网络请求, 通常是给一个网络链接作为接口. 接口里的内容是可以根据网络数据动态修改的.
我们通常使用的APP的数据绝大多数都是通过网络请求而来. 而怎么把网络请求来的数据展示到界面上呢? 网络请求来的数据又是怎么样的形式转化给应用呢?
我们需要知道, 数据在内存中是以二进制编码的形式保存的. 编码的格式有很多种, 在iOS的应用中通常都是用UTF-8格式进行编码. 一串二进制数据, 我们要怎么才能把其变成我们需要展示的数据呢?
将二进制数据按找某种方式, 转化成我们需要操作的数据的过程就是一个数据解析的过程.
解析的概念
所谓“解析”:从事先规定好的格式中提取数据
解析的前提:提前约定好格式、数据提供⽅按照格式提供数据、 数据获取⽅则按照格式获取数据
iOS开发常⻅的解析:XML解析、JSON解析
以下以本地读取文件的方式对两者进行详细的介绍
XML解析
XML是一种可扩展标记语言. 在早期的网络中, XML大量存在, 而手机APP是一个从网络发展到手机的扩展功能, 可以说手机APP只是一个电脑网络的附属产品. 所以早期APP中的数据, 通常都是以XML语言的格式存放.
以下是一段简单不完整的XML内容部分
// Student.xml
<root>
<Student>
<number>1</number>
<name>张三</name>
<sex>男<sex>
</Student>
<Student>
<number>2</number>
<name>李四</name>
<sex>女</sex>
</Student>
<Student>
<number>3</number>
<name>王五</name>
<sex>男</sex>
</Student>
</root>除去根节点的属性, 我们需要解析的数据大体上就是这个样式的数据.
像<root></root> 这样用尖括号显示, 且成对存在的数据, 称之为一对标签. 或者一个节点.
不带’/’的是一个标签的开始 <root>, 带’/’的</root> 是一个标签的结束, 两者之间不用<>括起来的数据 就是我们需要获取的展示数据.
最外层的(也就是唯一的一对存放所有内容的节点)称之为根节点.
在以上数据中, 根节点是<root></root> 这对标签, 根节点下对应了三个子节点(<Student></Student>), 在每个子节点内又存放了三个子节点(<number></number>,<name></name>,<sex></sex>) <Student></Student> 相对于最内层的三个子节点而言, 是它们的父节点. 最内层的三个子节点中存放的数据就是我们需要获取的数据.
对于这段数据, 想要使用, 需要数据也就是最里层标签对夹着的内容放到一个容器里. 在OC中容器常用的就两种: 数组 字典
用OC语言的角度来解析这段数据就是一个大数组 包含了三个元素
而此时这三个元素可以看成又是三个数组, 或者是三个字典(将标签名当成key, 数据当成value), 这是根据各人的习惯, 从便于使用的角度来将数据转化到各自便于使用的容器里
怎么讲这个解析过程转化成代码呢?
解析XML格式的数据主要有以下两种方式
- SAX解析
- DOM解析
以下将详细介绍
SAX解析
SAX解析全称Simple API for XML。是基于事件驱动的解析⽅式,逐⾏解析数据。(采⽤协议回调机制)
也就是一行一行的读取数据, 在读取的同时, 会逐行解析, 驱动事件循环.
简单来说, 就是模拟人读书的过程, 从上至下, 从左往右 一行一行的读取数据. 然后对读取的数据进行判断, 判断当前读取的数据哪些是我们需要的, 哪些是不需要的.
这里需要用到一个系统类: NSXMLParser(解析人类)
NSXMLParser是苹果开发自带的XML数据解析类. 它采用的解析原理就是SAX.
解析过程由NSXMLParserDelegate协议⽅法回调
解析过程:开始标签->取值->结束标签->取值
主要用到的方法
- 根据网址接口解析数据
- (instancetype)initWithContentsOfURL:(NSURL *)url; - 根据本地数据解析
- (instancetype)initWithData:(NSData *)data; - 开始进行解析
- (BOOL)parse;
使用NSXMLParser类进行数据解析, 必须设置代理, 然后在代理人类中实现NSXMLParserDelegate协议中的方法
NSXMLParserDelegate的主要方法介绍
已经开始解析文档时触发
- (void)parserDidStartDocument:(NSXMLParser *)parser;已经结束解析时触发
- (void)parserDidEndDocument:(NSXMLParser *)parser;已经遇到节点时触发(判断标志是<>, 自动剔除<>, 并获得中间的标签名)
- (void)parser:(NSXMLParser *)parser didStartElement:(NSString *)elementName namespaceURI:(NSString *)namespaceURI qualifiedName:(NSString *)qName attributes:(NSDictionary *)attributeDict;结束节点时触发(判断标志是
</>, 自动剔除</>, 并获得中间的标签名)- (void)parser:(NSXMLParser *)parser didEndElement:(NSString *)elementName namespaceURI:(NSString *)namespaceURI qualifiedName:(NSString *)qName;发现词的时候触发 (读取开始节点标志<>后边的值)
- (void)parser:(NSXMLParser *)parser foundCharacters:(NSString *)string;
顺序按照我们正常看书时候的读取内容方法排序如下 :
- 开始解析文档
- 开始遇到节点
- 开始读词
- 结束节点
- 结束解析文档
其中 2 3 4步骤是重复不断的执行的
当读到的是根节点的时候 所读的词是一串空格 在这我们需要对所读到的词进行判断
设置Model, 根据以上的XML数据, 可以创建相应的Model类
// Model.h
@property (nonatomic, retain) NSString *number;
@property (nonatomic, retain) NSString *name;
@property (nonatomic, retain) NSString *sex;// 解析数据 (SAX解析)
- (void)xmlParserUpData {
// 利用的是系统的NSXMLParser(xml分析人)类 以驱动事件进行xml的解析(也就是利用不同情况下的触发的代理方法进行解析)
// 创建分析人 需要看分析的数据在哪 在本地, 需要先获得这个文件的二进制文件NSData, 获取二进制文件需要这个文件的路径
// 相对的 数据在网络上, 就需要先获得这个网络的地址的二进制字符串NSURL 获取二进制字符串的来源网址名
// 创建分析的data(二进制对象)
// 获取路径
NSString *path = [[NSBundle mainBundle] pathForResource:@"Student" ofType:@"xml"];
NSData *data = [NSData dataWithContentsOfFile:path];
NSXMLParser *parser = [[NSXMLParser alloc] initWithData:data];
// 驱动事件
parser.delegate = self;
// 开始分析
[parser parse];
NSLog(@"分析");
// 会自动触发代理方法
// 释放
[parser release];
}
// ControllView.m
// 定义三个属性如下, dataArray用于储存所有Model, model用于保存
@property (nonatomic, retain) NSMutableArray *dataArray;
@property (nonatomic, retain) Model *model;
@property (nonatomic, retain) NSString *string;#pragma mark 利用NSXMLParserDelegate触发方法解析数据
- (void)parserDidStartDocument:(NSXMLParser *)parser {
NSLog(@"已经开始解析文档");
// 一开始就初始化数组
self.dataArray = [NSMutableArray array];
}
- (void)parser:(NSXMLParser *)parser didStartElement:(NSString *)elementName namespaceURI:(NSString *)namespaceURI qualifiedName:(NSString *)qName attributes:(NSDictionary *)attributeDict {
// NSLog(@"已经开始遇到节点");
NSLog(@"<%@>", elementName);
// 如果节点名是Student, 就创建一个Model对象
if ([elementName isEqualToString:@"Student"]) {
// 当节点名是Student的时候 说明它后面的数据是一个Model
self.model = [[Model alloc] init];
}
}
- (void)parser:(NSXMLParser *)parser foundCharacters:(NSString *)string {
NSLog(@"%@", string);
// 保存字符串
self.string = string;
// NSLog(@"发现词");
}
- (void)parser:(NSXMLParser *)parser didEndElement:(NSString *)elementName namespaceURI:(NSString *)namespaceURI qualifiedName:(NSString *)qName {
// NSLog(@"节点结束");
NSLog(@"</%@>", elementName);
// 对Model赋值
// 如果当前结束的节点名是name, number, sex的时候, 之前的保存的字符串就是节点里的内容
if ([elementName isEqualToString:@"name"]) {
self.model.name = self.string;
}
if ([elementName isEqualToString:@“number"]) {
self.model.number = self.string;
}
if ([elementName isEqualToString:@“sex"]) {
self.model.sex = self.string;
}
if ([elementName isEqualToString:@"Student"]) {
[self.dataArray addObject:self.model];
[_model release];
}
}
/*
或者利用KVC赋值
- (void)parser:(NSXMLParser *)parser didEndElement:(NSString *)elementName namespaceURI:(NSString *)namespaceURI qualifiedName:(NSString *)qName {
// NSLog(@"节点结束");
NSLog(@"</%@>", elementName);
if ([elementName isEqualToString:@"Student"]) {
[self.dataArray addObject:self.model];
[_model release];
} else {
[self.model setValue:self.string forKey:elementName];
}
}
用本方法必须保证model中的属性名和标签名相同, 且必须重写了setValue forUndefinedKey方法
*/
- (void)parserDidEndDocument:(NSXMLParser *)parser {
// 这时装完所有的Model
NSLog(@"已经结束解析文档");
NSLog(@"%@", self.dataArray);
}DOM解析
DOM全称Document Object Model(⽂档对象模型)。
解析时需要 将XML⽂件整体读⼊,并且将XML结构化成树状,使⽤时再通过树状结构读取相关数据
简单来说, 可以根据节点名, 将数据从该节点名开始到结束中间的部分裁剪成一段连续数据. 若有多个名字相同的节点, 会同时剪裁出多多段数据. 但值得注意的是, 裁剪过程只能从最外层到最内层层层递进, 不能跳跃裁剪.
首先需要整体读取数据
// 创建文件对象, data是获取到的需要解析的XML数据
GDataXMLDocument *document = [[GDataXMLDocument alloc] initWithData:data options:0 error:nil];利用- (GDataXMLElement*)rootElement; 获得根节点. 此时根节点中的值就存放了从根节点开始到结束的所有数据(此时已经自动剔除根节点的标签了). 让后以此为基础, 层层裁剪
用到的方法为:
- (NSArray *)elementsForName:(NSString *)elementName;
若此时输入的节点名有多个, 则会放回多段数据, 存放在数组中放回.
直到剪裁到数据存放的节点时, 利用方法:
- (NSString *)getNSStringWithElementName:(NSString *)elementName;
获得最后的数据.
具体用法代码示例在后面有展示.
DOM解析用到的类是GDataXMLNode 这是Google提供的开源XML解析类, 并不是苹果官方自带的方法.
对libxml2.dylib进⾏了Objective-C的封装, 采⽤DOM⽅式解析数据.
iOS中包含一个C语言的动态链接库libxml2.dylib. GDataXMLNode是基于该库的一种解析方法. 它的解析速度比NSXMLParser快.
添加libxml2框架的方法.
第一步:

在工程设置General或者Build Phases选下下找到该选项.
添加libxml2.dylib或者libxml2.2.dylib(Xcode7.1后后缀名更为.tbd)
第二步:
在Build Settings中找到Header Search Paths
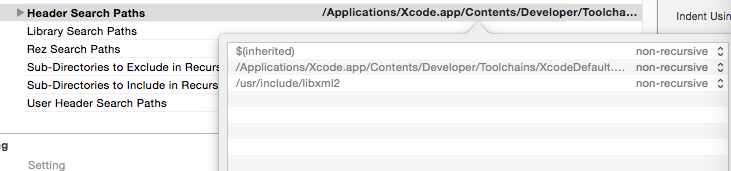
引入头文件后
// 用一个方法封装包装Model的过程
- (void)GDataXMLNodeUpData {
NSString *path = [[NSBundle mainBundle] pathForResource:@"Student" ofType:@"xml"];
NSData *data = [NSData dataWithContentsOfFile:path];
// options: 预留参数 随便填啥
// error应该是在有了错误以后才有值, 所以在一开始不应该给其赋值 或者直接填nil即可
GDataXMLDocument *document = [[GDataXMLDocument alloc] initWithData:data options:0 error:nil];
// 获取根节点
GDataXMLElement* rootElement = [document rootElement];
// 获取根节点下 Student节点
NSArray *elementArray = [rootElement elementsForName:@"Student"];
self.dataArray = [NSMutableArray array];
for (GDataXMLElement *element in elementArray) {
Model *model = [[Model alloc] init];
model.number = [self getNSStringWithElementName:@"number" inElement:element];
model.name = [self getNSStringWithElementName:@"name" inElement:element];
model.sex = [self getNSStringWithElementName:@"sex" inElement:element];
[self.dataArray addObject:model];
[model release];
}
NSLog(@"%@", self.dataArray);
}
// 返回值为Model属性的value
- (NSString *)getNSStringWithElementName:(NSString *)name inElement:(GDataXMLElement *)element {
NSArray *array = [element elementsForName:name];
GDataXMLElement *aElement = array[0];
return [aElement stringValue];
}SAX和DOM比较:
SAX优点:
- NSXMLParser是系统封装好的类, 在使用的时候比较快捷
- 赋值的时候可以使用KVC赋值, 节省代码, 不需要手动的一条一条属性的赋值
SAX缺点
- 效率低
- 解析过程比较复杂分布在5个触发方法中 在数据结构较为复杂的时候, 赋值就显得十分困难了.
DOM优点:
- 效率高
- 赋值过程逻辑清晰
DOM缺点:
- 使用的是第三方框架, 在使用前导入很麻烦.
- 没有办法快捷赋值, 只能一个属性一个属性的赋值.
通常XML都是使用DOM解析.
JSON解析
JSON是一种较为先进的数据交换语言. 现在市面上大多数都是用JSON格式作为数据传输的格式, 少部分由于数据比较陈旧的原因还在使用XML解析(iOS开发方面)
Javascript Object Notation,轻量级的数据交换格式,采⽤完全独⽴于语⾔的⽂本格式,被称为理想的数据交换语⾔
JSON⽂档有两种结构:对象、数据
对象:以“{”开始,以“}”结束,是“名称/值”对⼉的集合。名称和值中间⽤“:”隔开。多个“名称/值”对之间⽤“ , ”隔开。类似OC中的字典。
数组:以“[”开始,以“]”结束,中间是数据。数据以“ , ”分隔。
JSON中的数据类型:字符串、数值、BOOL、对象、数组。
之前XML的数据格式转化成JSON格式如下:
// Student.json
[
{
"number":"1",
"name":"张三",
"sex":"男"
},
{
"number":"2",
"name":"李四",
"sex":"女"
},
{
"number":"3",
"name":"王五",
"sex":"男"
}
]相较于XML, JSON格式的数据所占字节数要小上许多. 同是也清晰很多, 最关键的是 JSON最内层用于保存数据的字典便于利用KVC赋值. 无论是在解析还是在赋值的时候, JSON都比XML高效非常多.
自iOS5后, 系统提供了一个用于解析JSON数据的类NSJSONSerialization
主要用到的方法是:
+ (id)JSONObjectWithData:(NSData *)data options:(NSJSONReadingOptions)opt error:(NSError **)error;
// 其中NSJSONReadingOptions结构体定义如下
typedef NS_OPTIONS(NSUInteger, NSJSONReadingOptions) {
NSJSONReadingMutableContainers = (1UL << 0), // 返回的是可变的容器
NSJSONReadingMutableLeaves = (1UL << 1), // 返回的JSON对象中字符串的值为NSMutableString
NSJSONReadingAllowFragments = (1UL << 2) // 允许JSON字符串最外层不是[]和{}的数据
}
// 通常选择第一个, 返回值是一个可变的容器.利用解析数据
@property (nonatomic, retain) NSMutableArray *dataArray;
- (void)setUpJSONData {
NSString *path = [[NSBundle mainBundle] pathForResource:@"Student" ofType:@"json"];
NSData *data = [NSData dataWithContentsOfFile:path];
// 把一个JSON的二进制文件 转化成数组 或者字典
NSMutableArray *dataArray = [NSJSONSerialization JSONObjectWithData:data options:NSJSONReadingMutableContainers error:nil];
self.datas = [NSMutableArray array];
for (NSDictionary *dic in dataArray) {
Model *model = [[Model alloc] init];
[model setValuesForKeysWithDictionary:dic];
[self.datas addObject:model];
[model release];
}
}仅仅用这一个方法就完成了数据的解析已经model的封装, 相较于XML, 方便快捷了非常多.
JSON快捷的结果就是对程序开发人员的要求更高了一点点, 它需要我们非常准确的判断是用什么类型的容器(是字典还是数组)来接受JSON文件的数据. (其实就是判断最外层的数据是[]还是{})
还有就是根据JSON的数据, 准确有效的设置相应的Model类用于接受数据.















 418
418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









