







1.什么是正则表达式?
正则就是特定的规则对数据进行过滤,拿到我们想要的数据。在python中爬虫提取数据时re是万能的,所有的数据都可以使用re进行提取。
python正则表达式的使用要借助re模块,安装方法:pip install re
2.正则表达式语法规则
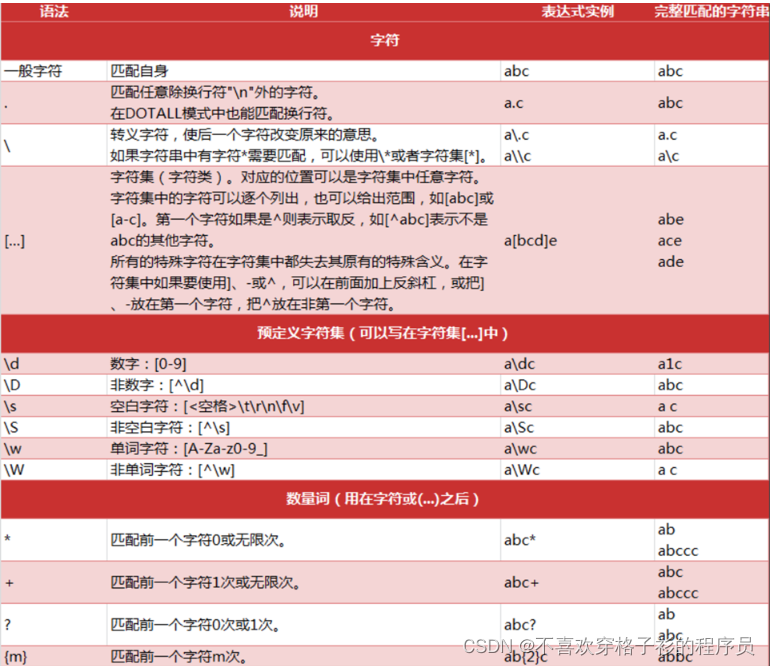
3.举例说明
# 取出字符串中的整数
str1 = "num12name2age15title666"
re.findall("\d",str1)
# print结果为["12","2","15","666"]
4.常见的使用方法
#从头找一个
re.match()
#找一个
re.search()
#找所有
re.findall()
#替换
re.sub()
#编译
re.compile()5.python中原始字符串r的用法
原始字符串定义(raw string):所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符,原始字符串往往针对特殊字符而言。例如"\n"的原始字符串就是"\\n",如果提取的数据中有"\"要在双引号前面加上r转译
6.匹配中文
在某些情况下,我们想匹配文本中的汉字,有一点需要注意的是,中文的 unicode 编码范围 主要在 [u4e00-u9fa5],这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。假设现在想把字符串 title = u'你好,hello,世界' 中的中文提取出来,可以这么做:
import re
# 注意点: 中文匹配 需要设置unicode字符才可以匹配
title = u'你好,hello,世界'
pattern = re.compile(ur'[\u4e00-\u9fa5]+')
result = pattern.findall(title)
print result
7.万能表达式:
爬虫中用到re的时候可以使用,适用百分之90以上的数据提取
例如:
data = "</div>
<h3 class="product-title">
<a href="//chaoshi.detail.tmall.com/item.htm?id=563432946975&rewcatid=51456012" target="_blank"
atpanel="40,563432946975,50012392,919380521,spu,1,spu,">
【<span class=H>进口</span>】荷兰荷高有机奶全脂<span class=H>纯</span><span class=H>牛奶</span>整箱1L*6盒装送礼礼盒
</a>
</h3>
<div class="item-summary">
<div class="item-sum">
<span>总销量:</span>
<strong>14233</strong>
</div>"
# 提取出总销量
"""
1.复制出需要的数据前后这里是总销量:</span><strong>14233</strong></div>"
2. 将需要的数据替换成(.*?)
"""
re.findall("<strong>(.*?)</strong>")8.遇到字符串中带()怎么办?
将圆括号放入中括号中,例如:
str1 = windoes__("data":['erte','ertert','ertet','uyty'])
# 提取出字符串中的列表
re.findall("windoes__[(]"data":"(.*?)[)])
















 7020
7020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











