







2.1 进程优先级
粗略分,实时进程和非实时进程。
实时进程:(1)硬实时进程,必须在可保证的时间范围内得到处理。
(2)软实时,仍然需要尽快处理,晚一点也可以接受。
普通进程,非实时的,根据重要性来划分,交互式的要尽快响应,冗长的编译或计算优先级可以低一点。
调度器的两次进化
(1) O(1)调度器,可以在常数时间内完成工作,不依赖系统运行的进程数目。
(2)完全公平调度器,试图尽可能模仿理想情况下的公平调度,还能处理更一般行的调度实体。
2.2 进程的生命周期
进程的状态:
(1)运行:该进程正在执行。
(2)等待:进程可运行,但没得到许可,当前cpu给了另外的进程,调度器下次可以选择当前进程。
(3)睡眠:进程正在睡眠,无法运行,等待外部事件,调度器下次切换任务时不可选该进程。
进程的状态切换
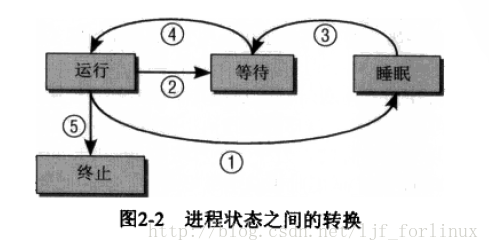
图 2-2的每个路径的描述
①进程必须等待事件,则从“运行”改变为“睡眠”。
②调度器从进程收回CPU资源,则从“运行”变为“等待”。
③“睡眠”状态,不能直接变为“运行”,在进程等待的时间发生后,先变回“等待”。
④在调度器授予CPU时间之前,进程一直保持“等待”,分配CPU时间后,状态才能改为“运行”。
⑤程序执行终止后,就从“运行”变为“终止”。
僵尸进程:进程已经终止了,但是进程表终仍然有对应的表项。
产生的原因:进程由另外的进程或者用户杀死,父进程,在子进程终止时,没有调用wait释放子进程保留的资源。
linux进程管理中的两种状态:用户状态和核心态。
用户态进程:权限受限,只能访问自身数据,不会干扰其他程序,如果要访问系统数据或者功能,必须切换到核心态。
核心态进程:有无限的权限。
从用户态切换到核心态的方法:
(1)系统调用,这个是由用户程序调用。
(2)中断,这个是自动触发的。
内核抢占是调度,抢占规则:
(1)普通进程总是可被抢占的,甚至是由其他进程抢占。
(2)系统处于核心态, 正在处理系统调用,其他进程是无法抢占CPU的,调度器必须等到系统调用结束。
(3)中断可以暂停处于用户态和核心态的进程,优先级最高。
2.3 进程表示
核心数据结构tack_struct,相当庞大,可以分为如下部分
(1)状态和执行信息,如待决信号,pid,父进程指针。
(2)已分配的虚拟内存信息。
(3)进程身份凭据,用户ID,组ID及权限。
(4)使用的文件,包括程代码的二进制文件。
(5)线程信息,记录该进程特定于CPU的运行时间数据。
(6)进程间通信相关的信息。
(7)信号处理程序。
linux资源限制机制,对进程使用系统资源施加某些限制,用rlim数组。
struct rlimit{
unsigned long rlim_cur;
unsigned long rlim_max;
}
rlim_cur,进程当前资源限制,也称软限制。
rlim_max,最大容许值,也称硬限制。
getrlimits和setrlimit分别用来读写,当前限制。可以查看进程的限制,cat /proc/pid/limits
2.3.1 进程类型
典型的unix进程包括:二进制代码组成的应用程序、单线程、分配给应用程序的一组资源。
进程的产生方式:
(1)fork,生成当前进程的一个相同副本,称子进程,原进程的所有资源都以适当的方式复制到子进程。
原来的进程有两个独立的实例,包括同一组打开文件、同样的工作目录、内存中的同样数据。
(2)exec,从一个可执行的二进制文件加载另外一个程序,来代替当前运行的进程。exec不创建新进程,所以
要先fork复制一个旧程序,在exec创建另外一个应用程序。
(3)clone,原理基本和fork相同,新进程不是独立于父进程的,而是可以与父进程共享某些制定需要的资源。
一般用于实现线程。
2.3.2 命名空间
传统的全局管理资源,例如系统所有进程,通过pid标识,所以内核管理一个全局的pid列表。
用户id的管理方式类似,全局id使得内核有选择允许货拒绝某些特权。如果想让某个用户为root,其他用户又不想受到干涉,那就太难了,这样他们每个都独立一个主机才行。这种做法存在局限性。
命名空间,可以简单理解为划分多个地区,在每个地区单独命名。
命名空间的作用:
(1)只使用一个内核,在一台计算机上运作,所有全局资源都通过命名空间抽象起来,这使得可以将一组进程放置到容器中,个容器彼此隔离。
(2)隔离使得容器的成员与其他容器毫无关系。
(3)可以通过允许容器进行一定的共享,来降低容器之间的分隔。
本质上,命名空间建立了系统的不同视图,每一项全局资源,都必须包含到容器的数据结构中,
只有资源和包涵资源的命名空间,构成的二元组才是全局唯一的。
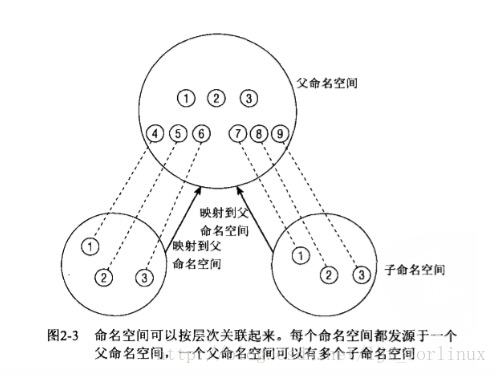
命名空间的创建方法:
(1)fork或clone创建进程时,有选项可以控制是与父进程共享命名空间,还是建立新的命名空间。
(2)unshare系统调用,将进程的某些部分从进程分离,其中包括命名空间。
子进程从父进程命名空间分离后,从子进程看,改变全局属性不会传播到父进程命名空间,而父进程的修改也不会传播到子进程,文件系统的另当别论。
命名空间如何实现?
(1)每个子系统的命名空间结构将此前所有的全局组件包装到命名空间中。
(2)将给定进程关联到所属命名空间的机制。
每个内核子系统的全局属性都封装到命名空间,用一个数据接口,将所有通过命名空间形式提供的对象集中起来,就是struct nsproxy。

从struct task_struct {
……
struct nsproxy *nsproxy;
……
}可知,多个进程可以共享一个命名空间。
2.3.3 进程ID号
在命名空间中用于唯一标识一个进程的,是进程ID,简称pid,fork货clone产生的每个进程都由内核分配一个新的pid值。
1、进程id有很多类型:
(1)进程里面的线程组id。
(2)进程组组长id。
(3)几个进程组合成一个会话,所以每个进程有个会话id。
全局ID和局部ID的区分:在建立一个新的命名空间时,该命名空间中的所有pid对父命名空间时可见的,但子命名空间无法看到父命名空间的皮带。这表示某些进程有多个pid,凡可以看到该进程的命名空间都会为其分配一个pid。
全局ID:对每个ID类型,都有一个给定的全局ID,保证在整个系统中的唯一性。
局部ID:对每个ID类型,它们在所属的命名空间内部有效,但类型相同、值也相同的ID可能出现在不同的命名空间中。
2、管理pid
pid分配器,用于加速新Id的分配。这里的id是广义上的,包括组id,组长id等。
先看看pid命名空间的表示方式
struct pid_namespace {
……
struct task_struck *child_reaper;
……
int level;
struct pid_namespace *parent;
};
这里有2个关键的地方:
(1)每个pid命名空间都有个进程,如上述的child_reaper就用于指向这个进程,该进程的作用相当于init进程,目的是对孤儿进程调用wait4,命名空间局部的init变体也需要完成该工作。
(2)parent指向父命名空间,层次表示当前命名空间在命名空间的层次结构中的深度。初始命名空间的深度为0。
pid管理围绕struct pid(内核对pid的内部表示)和struct upid(特定的命名空间中的可见信息)展开。
struct upid{
int nr;//id的数值
struct pid_namespace *ns;//该id所属的命名空间指针
struct hlist_node pid_chain;//将所有的upid链接在散列表的链表。
};
struct pid
{
atomic_t count;
struct hlist_head tasks[PIDTYPE_MAX];//每个项对应于一个id类型,作为一个散列表头。
int level;
};
对tasks中的每项,因为一个ID可能用于几个进程(如图2-5),所有共享同一给定ID的task_struct实例都吐过该
列表链接起来。
enum pid_type
{
PIDTYPE_PID,
PIDTYPE_PGID,
PIDTYPE_SID,
PIDTYPE_MAX
};
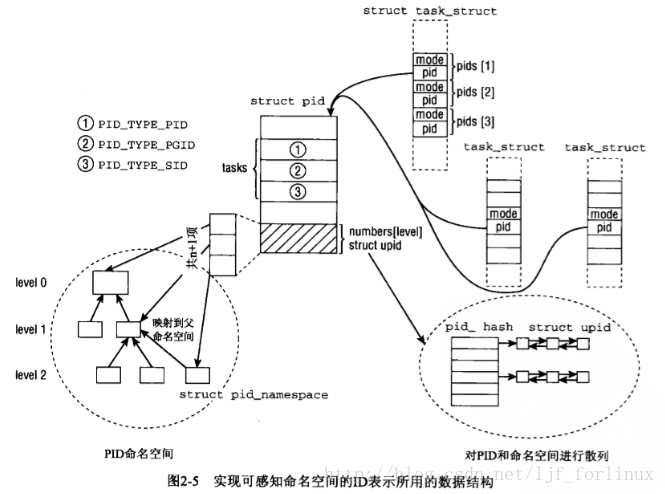
用函数可以操作和扫描上述复杂结构:
(1)给出局部数字id和对应的命名空间,查找此二元组的task_struct;
(2)给出task_struct、id类型、命名空间,取得命名空间局部的数字ID;
3、生成唯一的pid
具体做法:为跟踪已经分配和仍然可用的pid,内核使用一个大的位图,其中每个pid由一个比特标识,pid的值可以通过对应比特在位图的位置来计算。其他的id都可以派生于pid。
2.3.4 进程关系
一张图说明,父子关系,兄弟关系。
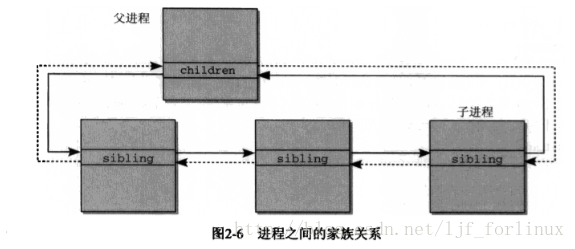
struct task_struct{
……
struct list_head children;
struct list_head sibling;
……
}
2.4 进程管理相关的系统调用
2.4.1 进程复制
进程复制有3个方法:
(1)fork,建立一个父进程的完整副本,然后作为子进程执行。linux使用写实复制。
(2)vfork,不创建父进程的副本,父子进程之间共享数据,一个进程修改,另外的会知道。
主要用于vfork后,调用execve加载新程序,子进程开始或退出前,父进程处于堵塞状态。
(3)clone产生线程,可以对父子进程之间的共享、复制进行精确控制。
1、写时复制
诞生的原因:复制父进程副本使用内存多,耗费时间长,很多情况下不需要复制。
作用是可以节省时间、内存空间。
在父、子进程确实要写入,会产生缺页异常,然后再由内核分配内存空间。
2、执行系统调用
fork —— sys_fork
vfork —— sys_vfork
clone — — sys_clone
几个系统调用对应的入口函数,最终这些入口函数,调用体系结构无关的do_fork,通过clone_flags这个标志集合区分不同入口。
3、do_fork的实现
do_fork
|—>copy_process
|—>确定pid
|—>初始化vfork的完成程序(在设置了CLONE_VFORK的情况下)和ptrace标志。
|—>wake_up_new_task
|—>是否设置了CLONE_VFORK标志?—>wait_for_completion
子进程生产成功后,需要执行一下操作:
(1)如果有CLONE_PID标志,fork操作先要创建新的pid命名空间。然后在新命名空间获取pid。否则直接获取局部pid。
(2)如果用了ptrace监控,创建进程后,就向它发送SIGSTOP信号,让调试器检查数据。
(3)子进程使用wake_up_new_task唤醒,也就是将它的task_struct添加到调度器队列,让她有机会执行。
(4)如果启用vfork机制,就要启用子进程的完成机制,子进程的task_struct的vfork_done成员即用于该墓地,父进程用wait_for_completion函数在该变量中进入睡眠,直至子进程退出。子进程终止时,内核调用complete(vfork_done)唤醒因该变量睡眠的进程。
4、复制进程
该过程主要受到标志的控制,来进行操作,内容较多,但比较简单。
5、创建线程时的特别问题
也是一些标志控制问题。
2.4.2 内核线程
内核线程的定义:直接由内核本身启动的进程,实际上是将内核函数委托给独立的进程,与系统其他进程并行执行,经常被称为内核守护进程。如,内存与块设备同步进程、系统事务日志进程。
内核线程,主要两类,要么就是启动后,一直等待内核让它执行某一些操作,要么就是周期性运行,检查特定资源,是否符合预设限制,然后根据检查结果执行操作。
内核线程的特别之处:
(1)它们在cpu管态执行,而不是用户态。
(2)它们只能访问内核部分的虚拟地址空间,不能访问用户空间。由于这个原因,内核上下文切换时,不需要倒换用户层的虚拟地址,等到下次执行的是与切换前不一样的进程才需要切换。
内核线程的实现:
(1)将一个函数传递给kernel_thread,内核调用daemonize,从内核释放父进程的所有资源。
(2)daemonize阻塞信号的接收。
(3)将init作为守护进程的父进程。
更简单的方法是kernel_create。
2.4.3 启动新程序
1、ececve的实现
该系统调用的入口点是体系结构相关的sys_execve,最后将工作委托给do_execve。
do_execve的主要工作:
(1)打开要执行的文件。
(2)bprm_init,申请进程空间并初始化。
(3)prepare_binprm,提供父进程相关的值,也是用于初始化。
(4)search_binary_handler,查找一种适当的二进制格式,用于所要执行的特定文件。
如释放原进程的所有资源,将应用程序映射到虚拟地址空间,参数和环境也映射到虚拟地址空间,
设置进程的指令指针和其他特定于体系结构的寄存器。
2、解释二进制格式
解释数据结构体 linux_binfmt,每种二进制格式,都要用register_binfmt向内核注册。
主要接口:
(1)load_binary加载程序。
(2)load_shlib价值普通程序。
(3)core_dump用于在程序错误的情况下输出内存转储,用于调试分析。
2.4.4 进程的退出
进程调用exit退出,内核能有机会讲资源释放回系统。
2.5 调度器的实现
2.5.1 概观
调度器的任务是在程序之间共享cpu时间,该任务分为调度策略和上下文切换两部分。
当前的调度器只考虑进程的等待时间,即进程在就绪队列中已经等待的时间,对cpu时间需求最严格的进程被调用,这样进程的不公平等待不会积累,不公平会均匀分布到系统的所有进程。
组成结构:所有可运行的进程都按等待时间在一个红黑树中排序,等待cpu时间最长的进程是在最左侧,调度器下次会考虑该进程,等待时间稍短的进程在该树上从左至右排序。时间复杂度时O(log n)。
虚拟时钟:该时钟的时间流逝速度慢于实际的时钟,精确的速度依赖于当前等待调度器挑选的进程数目。如4个进程,在就绪队列实际等待20秒,相当于虚拟时间5秒。
就绪队列的虚拟时间由fair_clock确定,进程的等待时间保存在wait_runtime,在红黑树排序时,食用
fair_clock-wait_runtime,当然是用绝对值了。另外,程序运行时,将从wait_runtime减去已经运行的时间,这样按时间排序时,它就会往右移动一点了。当前还会受到进程的优先级,和是否频繁切换因素影响。
2.5.2 数据结构
调度子系统的概观
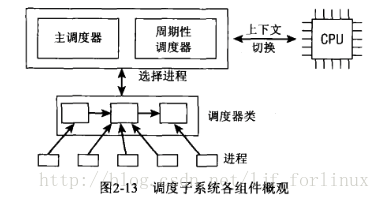
激活调度的方法:
(1)直接的,进程打算睡眠或其他因素放弃cpu。
(2)周期性的,以固定频率运行,检查是否有必要进行进程切换。
用这两种方法 ,分别是上面的通用调度器、核心调度器。
调度类:用于判断后面调用哪个进程,内核支持不同的调度策略(完全公平、实时调度、空闲时调度空闲进程),调度类能以模块化实现这些策略。调度器被调用时,它会查询调度器类,确定接下来运行哪个进程。也就是调度器类。
进程切换:在选中将运行的程序后,要执行底层任务切换。
注意:每个进程都属于某一调度类,每个调度类负责管理所属的进程,调度器本身不涉及进程管理,工作都委托给调度类。
1、task_struct的成员
struct task_struct{
……
int prio;
int normal_prio;
int static_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
unsigned int policy;
cpumask_t cpus_allowed;
unsigned int time_slice;
……
};
动态优先级:
(1)主要有两类prio和normal_prio。
(2)其中normal_prio表示基于进程的静态优先级和调度策略计算的优先级,因此即使普通进程和实时进程有相同静态优先级,其普通优先级也是不同的。
(3)调度器的优先级保存在prio。
注意,进程分支时,子进程会继承普通优先级。
rt_priority表示实时进程的优先级,该值不会代替前面prio、normal_prio等值,最低的优先级为0,最高为99。
sched_class表示进程所属的调度类。
调度器不限于调度进程,还可以调度更大的实体,如进程组调度,这里将cpu时间在进程组之间分配,接下来再在组内分配。这里调度器不直接操作进程,而是处理可调度实体,由sched_entity表示。
policy保存进程的调度策略,如完全公平的调度。
cpu_allowed是个位域,在多处理器时,用于限制进程可在哪个cpu运行。
run_list和time_slice时循环实时调度器所需要的,但不用于完全公平调度器。
2、调度器类
对每个调度类,都必须提供sched_class的一个实例,调度器请求的操作都有指针表示,调度器不要了解不同调度类的内部工作。
调度类之间的层次优先级:实时进程 > 完全公平调度 > 空闲进程,sched_class的next,就是按这个顺序链接起来的,这个层次结构在编译时已经建立,不能在运行时增加新调度类的机制。
3、就绪队列
就绪队列:核心调度器用于管理活动进程的主要数据结构,每个活动进程只出现在一个就绪队列。另外,进程不是就绪队列的成员直接管理的,进程由调度类管理,就绪队列潜入了特定于调度类的子就绪队列。
就绪队列的核心成员及解释:

nr_running,指定了队列上可运行的进程数目,不考虑优先级和调度类。
load 就绪队列当前负荷的度量。
cpu_load 用于跟踪此前的负荷状态。
cfs和rt是嵌入的子就绪队列,分别用于完全公平调度器和实时调度器。
curr 指向当前运行的进程的task_struct实例。
idle 指向空闲进程的task_struct实例。
clock和prev_raw_clock用于实现就绪队列自身的时钟,每次调用周期性调度器时,都会更新clock的值。
4、调度实体
load 指定了权重,决定了实体占队列总负荷的比例。
run_node 标准的树结点,实体可以在红黑树上排序。
on_rq 表示该实体当前是否在就绪队列上接受调度。
sum_exec_runtime用于记录进程运行时,消耗的cpu时间,用于完全公平调度。
在进程被撤销cpu时,当前sum_exec_runtime的值保存到prev_exec_runtime中。
2.5.3 处理优先级
1、优先级的内核表示
进程的nice值在-20和+19之间(包含),值越低优先级越高。
内核用0至139(包含),表示内部优先级,值越低优先级越高。0-99用于实时进程,nice值[-20,19]映射到范围[100,139],实时进程优先级总是比普通进程优先级高。
2、计算优先级
进程的优先级计算,要考虑static_prio、normal_prio、prio三种优先级。
调用相关函数计算结果,

3、计算负荷权重
进程的重要性由进程优先级和task_struct->se.load的负荷权重。进程每降低一个nice值,则多获得10%的cpu时间,每升高一个nice值,就放弃10%的cpu时间,也就是优先级加1,权重就减少。进程加入到就绪队列时,就绪队列的负荷权重也会增加。
2.5.4 核心调度器
1、周期性调度器
(1)在scheduler_tick中实现,系统活动时,内核以频率hz自动调用该函数。
(2)没进程等待时,供电不足情况下,可以关闭周期性调度器。
(3)主要任务是管理内核中与系统和每个进程的调度相关的统计量,另外就是激活负责当前进程的调度类的周期性调度方法。
__update_rq_clock 更新rq的时钟时间戳。
update_cup_load,更新rq->cup_load数组。
2、主调度器
将当前cpu分配给另一个进程,要调用主调度器函数schedule,从该系统调用返回后也要检查当前进程是否设置了重调度标志TIF_NEED_RESCHEDULE,如果有,内核会调用schedule。
__sched前缀的用处:有该前缀的函数,都是可能调用schedule的函数,包括schedule自身。该前缀目的是将相关代码的函数编译后,放到目标文件的特定段中,.sched.text中。该信息使内核在现实栈转储或类似信息时,忽略所有与调度有关的调用。由于调度器函数调用不是普通代码流程的部分,所以这种情况下是无意义的。
asmlinkage void __sched schedule( void );该函数的过程:
(1)将就绪队列的当前活动进程指针保存在prev中,prev = rq->curr;
(2)更新就绪队列的时钟,清除当前进程task_struct的重调度标志TIF_NEED_RESCHED。
(3)判断当前进程是否在可中断睡眠状态,而且现在接收到信号,那么它将再次提升为可运行。否则,用
deactivate_task讲进程停止。
(4)再用put_prev_task通知调度类,但前进程要被另一进程代替。pick_next_task,选择下一个要执行的进程。
(5)只有1个进程,是不要切换的,还让它留在cpu。要是能选择另外的进程,就用context_switch进行上下文切换。
(6)当前进程,被重新调度回来时,检测是否要重新调度,如果要,就又重复前面(1)至(5)的步骤了。
3、与fork的交互
用fork或其变体新建进程时,调度器用sched_fork函数挂钩到该进程。在用wake_up_new_task唤醒进程时,内核调用调度类的task_new将新进程加入相应类的就绪队列。
单处理器,sched_fork执行如下:
(1)初始化新进程与调度相关的字段。
(2)建立数据结构。
(3)确定进程的动态优先级。
4、上下文切换
context_switch要进行如下操作:
(1)prepare_task_switch,执行特定于体系结构的代码,为切换做准备。
(2)switch_mm更换task_struct->mm描述的内存管理上下文。
(3)switch_to切换处理器寄存器和内核栈。
(4)切换前,用户空间进程的寄存器进入和心态时保存在内核栈上,在上下文切换时,内核栈的值自动回复寄存器数据,再返回用户空间。















 2997
2997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









