







1.Window.onLoad 和 DOMContentLoaded事件的先后顺序?
顺序
一般情况下,DOMContentLoaded事件要在window.onload之前执行,当DOM树构建完成的时候就会执行 DOMContentLoaded事件,而window.onload是在页面载入完成的时候,才执行
区别
1、当 onload 事件触发时,页面上所有的DOM,样式表,脚本,图片,flash都已经加载完成了。
2、当 DOMContentLoaded 事件触发时,仅当DOM加载完成,不包括样式表,图片,flash。
2.怎么实现this对象的深拷⻉?
1)一行代码的深拷贝
//创建mock数据
function createData(deep, breadth) {
var data = {};
var temp = data;
for (var i = 0; i < deep; i++) {
temp = temp['data'] = {};
for (var j = 0; j < breadth; j++) {
temp[j] = j;
}
}
return data;
}
createData(1, 3);
// 1层深度,每层有3个数据 {data: {0: 0, 1: 1, 2: 2}}
//深拷贝对象
function cloneJSON(source) {
return JSON.parse(JSON.stringify(source));
}
其实我第一次简单这个方法的时候,由衷的表示佩服,其实利用工具,达到目的,是非常聪明的做法
下面来测试下cloneJSON有没有溢出的问题,看起来cloneJSON内部也是使用递归的方式
cloneJSON(createData(10000));
//出现错误
// Maximum call stack size exceeded
既然是用了递归,那循环引用呢?并没有因为死循环而导致栈溢出啊,原来是JSON.stringify内部做了循环引用的检测,正是我们上面提到破解循环引用的第一种方法:循环检测
var a = {};
a.a = a;
cloneJSON(a)
//出现错误
// Uncaught TypeError: Converting circular structure to JSON
普通简单版本
深拷贝的问题其实可以分解成两个问题,浅拷贝+递归,什么意思呢?假设我们有如下数据
var a1 = {b: {c: {d: 1}};
只需稍加改动上面浅拷贝的代码即可,注意区别
function clone(source) {
var target = {};
for(var i in source) {
if (source.hasOwnProperty(i)) {
if (typeof source[i] === 'object') {
target[i] = clone(source[i]); // 注意这里
} else {
target[i] = source[i];
}
}
}
return target;
}
其实上面的代码问题太多了,先来举几个例子吧
- 没有对参数做检验
- 判断是否对象的逻辑不够严谨
- 没有考虑数组的兼容
进阶版本
用循环遍历一棵树,需要借助一个栈,当栈为空时就遍历完了,栈里面存储下一个需要拷贝的节点
首先我们往栈里放入种子数据,key用来存储放哪一个父元素的那一个子元素拷贝对象
然后遍历当前节点下的子元素,如果是对象就放到栈里,否则直接拷贝
function cloneLoop(x) {
const root = {};
// 栈
const loopList = [{
parent: root,
key: undefined,
data: x,
}]
while (loopList.length) {
// 深度优先
const node = loopList.pop();
const parent = node.parent;
const key = node.key;
const data = node.data;
// 初始化赋值目标,key为undefined则拷贝到父元素,否则拷贝到子元素
let res = parent;
if (typeof key !== "undefined") {
res = parent[key] = {};
}
for (let k in data) {
if (data.hasOwnProperty(k)) {
if (typeof data[k] === "object") {
// 下一次循环
loopList.push({
parent: res,
key: k,
data: data[k],
});
} else {
res[k] = data[k];
}
}
}
}
return root;
}
3.var let const 的区别,以及变量提升,函数提升?
var
1.不存在块作用域
2.可以多次声明(覆盖)
3.存在变量提升:当var a = 1;时候,会先在作用域的最顶端,var a;然后在var a = 1;的位置给a赋值
let const
1.存在块作用域
经典例题:
for循环给多个dom添加时间,输出for循环的角标i,如果用var声明,因为没有块作用域,var会变量提升到外层作用域最顶端,而多次i赋值,最后只保存了最后一次的值,改成let可以解决这个问题(这就是强行解释,具体为什么let可以解决还需要好好看看let)
2.不可以多次声明
包括function a() {};存在后不能let const a
变量提升和函数提升排序的问题需要理解
4.node服务器优缺点?
1.优点:事件驱动,是的输入输出性能很高
2.缺点:cpu计算差,比如做很多计算操作,代码运行效率要求高,所以用底层的语言来做,比如C
3.io密集型:需要处理比较多的任务
5.WebSocket和socket的区别?
就像Java和JavaScript,并没有什么太大的关系,但又不能说完全没关系。可以这么说:
- 命名方面,Socket是一个深入人心的概念,WebSocket借用了这一概念;
- 使用方面,完全两个东西。
Socket
Socket可以有很多意思,和IT较相关的本意大致是指在端到端的一个连接中,这两个端叫做Socket。对于IT从业者来说,它往往指的是TCP/IP网络环境中的两个连接端,大多数的API提供者(如操作系统,JDK)往往会提供基于这种概念的接口,所以对于开发者来说也往往是在说一种编程概念。同时,操作系统中进程间通信也有Socket的概念,但这个Socket就不是基于网络传输层的协议了
WebSocket与HTTP的关系

相同点
都是一样基于TCP的,都是可靠性传输协议。
都是应用层协议。
不同点
WebSocket是双向通信协议,模拟Socket协议,可以双向发送或接受信息。HTTP是单向的。
WebSocket是需要浏览器和服务器握手进行建立连接的。而http是浏览器发起向服务器的连接,服务器预先并不知道这个连接。
联系
WebSocket在建立握手时,数据是通过HTTP传输的。但是建立之后,在真正传输时候是不需要HTTP协议的。
总结:
在WebSocket中,只需要服务器和浏览器通过HTTP协议进行一个握手的动作,然后单独建立一条TCP的通信通道进行数据的传送。
WebSocket连接的过程是:
首先,客户端发起http请求,经过3次握手后,建立起TCP连接;http请求里存放WebSocket支持的版本号等信息,如:Upgrade、Connection、WebSocket-Version等;
然后,服务器收到客户端的握手请求后,同样采用HTTP协议回馈数据;
最后,客户端收到连接成功的消息后,开始借助于TCP传输信道进行全双工通信
6.ES6新的数组去重方法?
es6里新添加了两个很好用的东西,set和Array.from。
set是一种新的数据结构,它可以接收一个数组或者是类数组对象,自动去重其中的重复项目。
set返回的是一个对象,可以通过Array.from来转化为数组。
7.不用for循环的情况下,打印出500个星号?
let num = 0;
while (num<500){
console.log("*")
num++;
}
8.storage和cookie的区别?
Web Storage的概念和cookie相似,区别是它是为了更大容量存储设计的。
Cookie的大小是受限的,并且每次你请求一个新的页面的时候Cookie都会被发送过去,这样无形中浪费了带宽,另外cookie还需要指定作用域,不可以跨域调用。
除此之外,Web Storage拥有setItem,getItem,removeItem,clear等方法,不像cookie需要前端开发者自己封装setCookie,getCookie。
但是Cookie也是不可以或缺的:
Cookie的作用是与服务器进行交互,作为HTTP规范的一部分而存在 ,而Web Storage仅仅是为了在本地“存储”数据而生
浏览器的支持除了IE7及以下不支持外,其他标准浏览器都完全支持(ie及FF需在web服务器里运行),值得一提的是IE总是办好事,例如IE7、IE6中的UserData其实就是javascript本地存储的解决方案。通过简单的代码封装可以统一到所有的浏览器都支持web storage。
localStorage和sessionStorage都具有相同的操作方法,例如setItem、getItem和removeItem等
9.介绍js有哪些内置对象?
Object 是 JavaScript 中所有对象的父对象
数据封装类对象:Object、Array、Boolean、Number和String其他对象:Function、Arguments、Math、Date、RegEx、Error`
10.如何区分数组和对象?
方法1
通过Object,prototype.toString.call方法来识别
var obj={};
var array=[];
1.Object.prototype.toString.call(obj);
"[Object Object]"
2.Object.prototype.toString.call(array);
"[Object Array]"
方法2
通过ES6中的Array.isArray来识别
Array.isArray([]) //true
Array.isArray({}) //false
方法3
通过intanceof
var o={};
var a=[];
o instanceof Array // false
a instanceof Array // true
11.什么是闭包?
闭包是指有权访问另外一个函数作用域中的变量的函数。可以理解为(能够读取另一个函数作用域的变量的函数)
function outer() {
var a = '变量1'
var inner = function () {
console.info(a)
}
return inner
// inner 就是一个闭包函数,因为他能够访问到outer函数的作用域
}
很多人会搞不懂匿名函数与闭包的关系,实际上,闭包是站在作用域的角度上来定义的。
因为inner访问到outer作用域的变量,所以inner就是一个闭包函数。
虽然定义很简单,但是有很多坑点,比如this指向、变量的作用域,稍微不注意可能就造成内存泄露。
12.说说几个闭包的使用场景?
1.很多js流行框架都是使用匿名自执行函数来避免变量污染
;(function(){
//todo
})()
2.缓存:闭包可以让变量的值始终保存在内存中,因此在使用时也要注意不要滥用闭包
function f1(){
var n=999;
nAdd = function(){n+=1}
function f2(){alert(n)}
return f2;
}
var result = f1(); //注意只有f1的返回值被外部引用,才不会被回收
result(); // 999
nAdd();
result(); //1000
3.封装
var person = function(){
var name = ‘default’
return {
getName:function(){ return name},
setName:function(newName){ name=newName}
}
}()
13.let const var 比较说明下?
理解js作用域
在ES5中,js只有两种形式的作用域:全局作用域和函数作用域。
全局作用域:变量在程序中任意地方都可以访问到
函数作用域:变量在函数内部可以访问到,在函数外部无法访问
for(var i=0;i<10;i++){
var a='a'
let b = 'b'
}
console.log(a) //'a'
console.log(b) //'b' is not defined
上述代码中,变量a为全局变量
function test(){
var a = 'a'
}
test()
console.log(a)
// 函数外部无法直接访问函数内部变量,报错
上述代码中,变量a为局部变量,控制台打印报错信息a is not defined
function test(){
a = 'a'
}
test()
console.log(a) //'a'
函数内部未使用var关键字定义变量,此时a为全局变量
小结
ES5中, js的作用域分为全局作用域和函数作用域
函数内部可以访问函数外部的全局变量,函数外部却无法直接访问函数内部的局部变量
未使用var关键字定义的变量是全局变量
现在我们知道函数内部可以访问函数外部的全局变量,函数外部却无法直接访问函数内部的局部变量
js中的变量提升
var定义变量存在变量提升:只提升声明语句,不提升赋值语句
var foo = {n:1};
(function(foo){
console.log(foo.n);
foo.n = 3;
var foo = {n:2};
console.log(foo.n);
})(foo)
console.log(foo.n);
执行上述代码,我们可以看到控制台中按顺序依次打印:1,2,3。这是因为Javascript先编译后执行。编译阶段,先声明变量,所以引擎会将上面的代码理解为以下格式
var foo = {n:1};
(function(foo){
var foo;
console.log(foo.n)
foo.n = 3;
foo = {n:2};
console.log(foo.n)
})(foo);
console.log(foo.n)
说明:
1.函数内部定义变量foo时,因为当前作用域中已经存在名为foo的变量,所以编译器忽略当前声明,继续进行编译,因此第一次打印的内容为外部变量foo的属性n值:1
2.foo.n=3 改变的是外部变量foo,foo={n:2}将foo指向了内部变量,并重新赋值为{n:2},所以第二次打印的内容为内部重新赋值的变量foo的属性n值:2
3.第三次打印内容是外部变量foo.n,因为函数内容已经更改了外部变量foo,所以打印结果为:3
js中先提升函数,后提升变量。
思考以下代码:
(function(){
console.log(a)
var a =1;
function a(){}
console.log(a)
})()
执行上述代码,我们可以看到控制台中按顺序依次打印:a(){},1。按照刚才的理解,js引擎将上面的代码会理解为下面的格式
(function(){
var a;
console.log(a)
a = 1;
function a(){}
console.log(a)
})()
那打印的结果应该为 undefined , f(){},这是因为我们忽略了一点,js先提升函数,后提升变量。所以正确的格式为
(function(){
function a(){}
var a;
console.log(a)
a = 1;
console.log(a)
})()
说明:
1.定义变量a时,因为已经存在命名为a的函数,所以第一次打印结果为a(){}
2.a=1,将变量a重新赋值,所以第二次打印结果为1
小结
ES5中,使用var定义变量,变量的作用域有两种:全局作用域、函数作用域
var定义变量存在变量提升,此外,先提升函数,后提升变量
但是开发过程中,变量提升往往会对开发造成困扰,幸好ES6中引入了let语法。
let
块级作用域
我们刚才提到,ES5中,js只用两种作用域:全局作用域与函数作用域。在ES6中,let关键字会隐式地创建一个块级作用域(通常是{}内部),变量只能在这个作用域中被访问。例如题目一中
for(var i=0;i<10;i++){
var a='a'
let b = ‘b'
}
console.log(a)
console.log(b)
我们在循环的内部,使用let创建了变量b,在循环外部访问时报错,b is not defined.就是这个原因。
块级作用域的引入大大改善了代码中由于全局变量而引发的错误,比如文章开头提出的第二题:
for(var i=0;i<3;i++){
setTimeout(function(){
console.log(i)
},1000)
}
上述代码由于变量i是用var声明的,所以全局范围有效 ,当循环体执行完时,i=2,所以定时器中console.log(i)中的i是指向全局变量i的,所以打印结果为2,2,2
如果我们将代码改为
for(let i=0;i<3;i++){
setTimeout(function(){
console.log(i)
},1000)
}
上述代码中,变量i使用let定义,所以只在本轮for循环中有效,所以打印结果为0,1,2。
let不存在变量提升,其所声明的变量一定要在声明语句之后使用。
例如:
console.log(bar);
let bar = 2;
打印结果报错:bar is not defined
此外,let 声明的变量不能重复声明,例如
let foo = {n:1};
(function(foo){
console.log(foo.n);
foo.n = 3;
let foo = {n:2};
console.log(foo.n);
})(foo)
console.log(foo.n);
函数内部定义变量foo时,因为当前作用域中已经存在命名为foo的变量,所以报错:’foo’ has already been declared.
const
ES6中新增了let关键字的同时,也新增了const关键字。
let与const有很多共同点:
- 都支持块级作用域
- 都不支持变量提升
- 都不支持重复声明
此外,我们知道var声明全局变量时,变量是挂在window上的。而let,const声明变量,却不是。这样子便避免了window对象的变量污染问题。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LPY8zWpy-1645064930533)(https://yangyunhaiimagesoss.oss-cn-shanghai.aliyuncs.com/2009181704_1600419895474.png “”)]
当然,const与let也有区别。const与let的区别在于:
let声明变量时无需赋值,const声明变量时必须赋值
let声明变量,变量可重新赋值,const声明变量,完成初始化后,值不得更改 (基本类型)
14.下面输出的结果为?
// interviewer: what will the following code output?
const arr = [10, 12, 15, 21];
for (var i = 0; i < arr.length; i++) {
setTimeout(function() {
console.log('Index: ' + i + ', element: ' + arr[i]);
}, 3000);
}
解析:
Index: 4,
element: undefined(打印4次)
setTimeout函数创建了一个可以访问其外部作用域的函数(闭包),该外部作用域是包含index的循环i。延时3秒,被执行的功能和它打印出的值i,这在环路的端部是在4,因为它循环通过0,1,2,3,4和环路最终停止在第4 arr[4]做不存在,这就是为什么你得到undefined。
15.以下代码将输出什么?
for (var i = 0; i < 3; i++) {
setTimeout(function() {
console.log(i);
}, 1000 + i);
}
上面代码的目标是分别在1、1.1和1.2秒后提醒数字0、1和2。
但是,问题是,如果您在控制台中运行上述代码,则在1、1.1 和1.2秒后实际上会收到3次3号警报。
这是因为JavaScript闭包有问题。JavaScript 闭包是指内部函数可以访问其外部封装函数的变量和属性。在上面的代码中,以下代码行:
使用在自身外部声明的变量i。
实际上,变量i是在for循环中声明的,内部函数可以访问它。
因此,当for循环完成运行时,每个内部函数都引用相同的变量i,该变量在循环末尾等于3。
我们的目标是使每个内部函数在不使用变量i的情况下保持其对变量i的引用。它的价值正在改变。我们将使用IIFE或立即调用的函数表达式来解决此问题。
for (var i = 0; i < 3; i++) {
setTimeout(function(i_local) {
return function() {
console.log(i_local);
}
}(i), 1000 + i);
}
我们将变量i作为名为i_local的局部变量传递到外部函数中,然后在该函数中返回将向我们发出i_local警报的函数。现在,这应该以正确的顺序正确警告数字0、1和2。
16.编写一个允许您执行此操作的函数!
var addSix = createBase(6);
addSix(10); // returns 16
addSix(21); // returns 27
解析:
您可以创建一个闭包,以保持将值传递给函数createBase,即使在返回内部函数之后也是如此。返回的内部函数是在外部函数内创建的,使其成为一个闭包,并且可以访问外部函数内的变量,在本例中为变量baseNumber。
function createBase(baseNumber) {
return function(N) {
return baseNumber + N;
}
}
var addSix = createBase(6);
addSix(10);
addSix(21);
17.让函数FirstReverse(str)接受传递的str参数,并以相反的顺序返回字符串。
//输入:
FirstReverse("Hello World and Coders");
//输出
sredoC dna dlroW olleH
function FirstReverse(string) {
return string.split('').reverse().join('');
}
FirstReverse("Hello World and Coders");
标签:字符串操作
18.使函数LongestWord(sen)接受传递的sen参数,并返回字符串中最大的单词。
如果有两个或更多个相同长度的单词,则从字符串中返回具有该长度的第一个单词。忽略标点符号,并假定sen不会为空。
输入:“ fun&!! time”
输出:time
输入:“I love dogs”
输出:love
function LongestWord(sen) {
sen = sen.trim();
sen = sen.replace(/[^a-zA-Z0-9 ]/g, '');
let longest = ""
var arr = sen.split(" ").forEach(word => {
if(word.length > longest.length) longest = word;
})
return longest;
}
LongestWord("fun&!! time");
// 输出:time
标签:最长字,字符串操作,查找
19.让函数FindIntersection(strArr)读取存储在strArr中的字符串数组,该数组将包含2个元素:
第一个元素将代表以逗号分隔的数字列表,以升序排列,第二个元素将代表第二个以逗号分隔的列表数字(也排序)。
您的目标是返回一个逗号分隔的字符串,其中包含按排序顺序出现在strArr元素中的数字。如果没有交集,则返回字符串false。
输入:["1, 3, 4, 7, 13", "1, 2, 4, 13, 15"]
输出:1,4,13
function FindIntersection (strArr) {
const inBothStrings = []
const arr1 = strArr[0].split(', ')
const arr2 = strArr[1].split(', ')
arr1.forEach(elementArr1 => {
const numArr1 = parseInt(elementArr1)
arr2.forEach(elementArr2 => {
const numArr2 = parseInt(elementArr2)
if (numArr1 === numArr2) {
inBothStrings.push(numArr1)
}
})
})
return inBothStrings.join(',')
}
FindIntersection(["1, 3, 4, 7, 13", "1, 2, 4, 13, 15"])
// 输出:"1,4,13"
20.有一个大数组:
var a = ['1', '2', '3', ...]
a 的长度是 100,内容填充随机整数的字符串.请先构造此数组 a,然后设计一个算法将其内容去重
/**
* 数组去重
**/
function normalize(arr) {
if (arr && Array.isArray(arr)) {
var i, len, map = {};
for (i = arr.length; i >= 0; --i) {
if (arr[i] in map) {
arr.splice(i, 1);
} else {
map[arr[i]] = true;
}
}
}
return arr;
}
/**
* 用100个随机整数对应的字符串填充数组。
**/
function fillArray(arr, start, end) {
start = start == undefined ? 1 : start;
end = end == undefined ? 100 : end;
if (end <= start) {
end = start + 100;
}
var width = end - start;
var i;
for (i = 100; i >= 1; --i) {
arr.push('' + (Math.floor(Math.random() * width) + start));
}
return arr;
}
var input = [];
fillArray(input, 1, 100);
input.sort(function (a, b) {
return a - b;
});
console.log(input);
normalize(input);
console.log(input);
21.JS延迟加载的方式有哪些?
1、 JS的延迟加载有助与提高页面的加载速度。
2、 defer和async、动态创建DOM方式(用得最多)、按需异步载入
3、 JSdefer:延迟脚本。立即下载,但延迟执行(延迟到整个页面都解析完毕后再运行),按照脚本出现的先后顺序执行。
4、 async:异步脚本。下载完立即执行,但不保证按照脚本出现的先后顺序执行。
22.new操作符具体干了什么呢?
-
创建一个空对象,并且
this变量引用该对象,同时还继承了该函数的原型。 -
属性和方法被加入到
this引用的对象中。 -
新创建的对象由
this所引用,并且最后隐式的返回this。
23.["1", "2", "3"].map(parseInt) 答案是多少?
答案
[1,NaN,NaN]
解析:
Array.prototype.map()
array.map(callback[, thisArg])
callback函数的执行规则参数:
自动传入三个参数:
- currentValue(当前被传递的元素);
- index(当前被传递的元素的索引);
- array(调用map方法的数组)
parseInt方法接收两个参数:
第三个参数["1", "2", "3"]将被忽略。
parseInt方法将会通过以下方式被调用
parseInt("1", 0)
parseInt("2", 1)
parseInt("3", 2)
parseInt的第二个参数radix为0时,ECMAScript5将string作为十进制数字的字符串解析;
parseInt的第二个参数radix为1时,解析结果���NaN;
parseInt的第二个参数radix在2—36之间时,如果string参数的第一个字符(除空白以外),不属于radix指定进制下的字符,解析结果为NaN。
parseInt(“3”, 2)执行时,由于"3"不属于二进制字符,解析结果���NaN。
24.谈谈this的理解
1、 this总是指向函数的直接调用者(而非间接调用者)
2、 如果有new关键字,this指向new出来的那个对象
3、在事件中,this指向目标元素,特殊的是IE的attachEvent中的this总是指向全局对象window。
25.介绍JavaScript的基本数据类型
- Number
- String
- Boolean
- Null
- Undefined
Object 是 JavaScript 中所有对象的父对象
数据封装类对象:
Object、Array、Boolean、Number 和 String
其他对象:
Function、Arguments、Math、Date、RegExp、Error
新类型:
Symbol、BigInt
26.什么是window对象? 什么是document对象?
window对象代表浏览器中打开的一个窗口。
document对象代表整个html文档。
实际上,document对象是window对象的一个属性。
27.通过什什么做到并发请求?
使用异步Prmosie All或者web worker
28.eval是做什么的?
它的功能是把对应的字符串解析成JS代码并运行;
应该避免使用eval,不安全,非常耗性能(2次,一次解析成js语句,一次执行)。
29.null,undefined的区别?
null表示一个"无"的对象,也就是该处不应该有值;而undefined表示未定义。
在转换为数字时结果不同,Number(null)为0,而undefined为NaN。
使用场景上:
null:
作为函数的参数,表示该函数的参数不是对象
作为对象原型链的终点
undefined:
- 变量被声明了,但没有赋值时,就等于undefined
- 调用函数时,应该提供的参数没有提供,该参数等于undefined
- 对象没有赋值属性,该属性的值为undefined
- 函数没有返回值时,默认返回undefined
null表示一个对象被定义了,但存放了空指针,转换为数值时为0。
undefined表示声明的变量未初始化,转换为数值时为NAN。
typeof(null)– object;
typeof(undefined)– undefined
30.解释 call/apply 原理,并手写 call/apply 实现
Function.prototype.call() call() 方法调用一个函数, 其具有一个指定的 this 值和多个参数(参数的列表)。
func.call(thisArg, arg1, arg2, …) 它运行 func,提供的第一个参数 thisArg 作为this,后面的作为参数。
看一个简单的例子:
function sayWord() {
var talk = [this.name, 'say',
this.word].join(' ');
console.log(talk);
}
var bottle = {
name: 'bottle',
word: 'hello'
};
//使用 call 将 bottle 传递为 sayWord 的 this
sayWord.call(bottle);
//bottle say hello
所以,call 主要实现了以下两个功能:
//call 改变了 this 的指向
//bottle 执行了 sayWord 函数
//模拟实现 call
//模拟实现 call 有三步:
//将函数设置为对象的属性
//执行函数
//删除对象的这个属性
Function.prototype.call = function (context) {
// 将函数设为对象的属性
// 注意:非严格模式下,
// 指定为 null 和 undefined 的 this 值会自动指向全局对象(浏览器中就是 window 对象)
// 值为原始值(数字,字符串,布尔值)的 this 会指向该原始值的自动包装对象(用 Object() 转换)
context = context ? Object(context) : window;
context.fn = this;
// 执行该函数
let args = [...arguments].slice(1);
let result = context.fn(...args);
// 删除该函数
delete context.fn
// 注意:函数是可以有返回值的
return result;
}
Function.prototype.apply() apply() 方法调用一个具有给定 this值的函数,以及作为一个数组(或[类似数组对象)提供的参数。
func.apply(thisArg, [argsArray]) 它运行 func 设置 this = context 并使用类数组对象 args 作为参数列表。
例如,这两个调用几乎相同:
func(1, 2, 3);
func.apply(context, [1, 2, 3]) 两个都运行 func 给定的参数是 1,2,3。但是 apply 也设置了 this = context。
call 和 apply 之间唯一的语法区别是 call 接受一个参数列表,而 apply 则接受带有一个类数组对象。
需要注意:Chrome 14 以及 Internet Explorer 9 仍然不接受类数组对象。如果传入类数组对象,它们会抛出异常。
模拟实现 apply
Function.prototype.apply = function (context, arr) {
context = context ? Object(context) : window;
context.fn = this;
let result;
if (!arr) {
result = context.fn();
} else {
result = context.fn(...arr);
}
delete context.fn
return result;
}
31.如何判断一个对象是否属于某个类?
使用instanceof 即
if(a instanceof Person){
alert('yes');
}
32.##### 同步和异步的区别?
同步的概念在操作系统中:
不同进程协同完成某项工作而先后次序调整(通过阻塞、唤醒等方式),同步强调的是顺序性,谁先谁后。异步不存在顺序性。
同步:
浏览器访问服务器,用户看到页面刷新,重新发请求,等请求完,页面刷新,新内容出现,用户看到新内容之后进行下一步操作。
异步:
浏览器访问服务器请求,用户正常操作,浏览器在后端进行请求。等请求完,页面不刷新,新内容也会出现,用户看到新内容。
33.一秒理解HTTP 状态码及其含义
1XX:信息状态码
100 Continue:客户端应当继续发送请求。这个临时相应是用来通知客户端它的部分请求已经被服务器接收,且仍未被拒绝。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。服务器必须在请求完成后向客户端发送一个最终响应
101 Switching Protocols:服务器已经理解 le 客户端的请求,并将通过 Upgrade 消息头通知客户端采用不同的协议来完成这个请求。在发送完这个响应最后的空行后,服务器将会切换到 Upgrade 消息头中定义的那些协议。
2XX:成功状态码
- 200 OK:请求成功,请求所希望的响应头或数据体将随此响应返回
- 201 Created:
- 202 Accepted:
- 203 Non-Authoritative Information:
- 204 No Content:
- 205 Reset Content:
- 206 Partial Content:
3XX:重定向
- 300 Multiple Choices:
- 301 Moved Permanently:
- 302 Found:
- 303 See Other:
- 304 Not Modified:
- 305 Use Proxy:
- 306 (unused):
- 307 Temporary Redirect:
4XX:客户端错误
- 400 Bad Request:
- 401 Unauthorized:
- 402 Payment Required:
- 403 Forbidden:
- 404 Not Found:
- 405 Method Not Allowed:
- 406 Not Acceptable:
- 407 Proxy Authentication Required:
- 408 Request Timeout:
- 409 Conflict:
- 410 Gone:
- 411 Length Required:
- 412 Precondition Failed:
- 413 Request Entity Too Large:
- 414 Request-URI Too Long:
- 415 Unsupported Media Type:
- 416 Requested Range Not Satisfiable:
- 417 Expectation Failed:
5XX: 服务器错误
- 500 Internal Server Error:
- 501 Not Implemented:
- 502 Bad Gateway:
- 503 Service Unavailable:
- 504 Gateway Timeout:
- 505 HTTP Version Not Supported:
1、创建一个新对象,继承自func.prototype
2、执行构造函数,this会指向新创建的对象
3、如果构造函数返回一个对象,则该对象便是new出来的结果,如果构造函数没有返回对象,那么new出来的结果为步骤1创建的对象。
34.JS单例模式
闭包的写法:
class Singleton {
constructor() {}
}
Singleton.getInstance = (function() {
let instance
return function() {
if (!instance) {
instance = new Singleton()
}
return instance
}
})()
let s1 = Singleton.getInstance()
let s2 = Singleton.getInstance()
console.log(s1 === s2) // true
非闭包的写法:
function Universe() {
// 判断是否存在实例
if (typeof Universe.instance === 'object') {
return Universe.instance;
}
// 其它内容
this.start_time = 0;
this.bang = "Big";
// 缓存
Universe.instance = this;
// 隐式返回this
}
// 测试
var uni = new Universe();
var uni2 = new Universe();
console.log(uni === uni2); // true
35.JS垃圾回收机制?
1、 标记清除:
当变量进入执行环境时标记为“进入环境”,当变量离开执行环境时则标记为“离开环境”,被标记为“进入环境”的变量是不能被回收的,因为它们正在被使用,而标记为“离开环境”的变量则可以被回收
2、 引用计数:
统计引用类型变量声明后被引用的次数,当次数为 0 时,该变量将被回收。
但是引用计数的方式,有一个相对明显的缺点——循环引用
在现代浏览器中,Javascript 使用的方式是标记清除,所以我们无需担心循环引用的问题
3、 内存泄露
本质上讲, 内存泄露就是不再被需要的内存, 由于某种原因, 无法被释放.
常见的内存泄露案例
- 全局变量照成内存泄露
- 未销毁的定时器和回调函数造成内存泄露
- 闭包造成内存泄露
36.数组对象有哪些原生方法,列举一下
- concat、
- copyWithin、
- fill、
- find、
- findIndex、
- lastIndexOf、
- pop、
- push、
- reverse、
- shift、
- unshift、
- slice、
- sort、
- splice、
- includes、
- indexOf、
- join、
- keys、
- entries、
- values、
- forEach、
- filter、
- flat、
- flatMap、
- map、
- every、
- some、
- reduce、
- reduceRight
37.call、apply、bind三者的用法和区别
我们知道,
call、apply、bind这三兄弟都是可以改变this指向的,那具体如何使用呢?
我们先定义两个对象
var obj={
name:'Li lei',
age:18,
intr:function(){
console.log(`我叫${this.name},我${this.age}岁`);
}
}
var obj2={
name:'Han meimei',
age:20,
intr:function(){
console.log(`I'm ${this.name},I'm ${this.age} years old`);
}
}
obj.intr();
//我叫Li lei,我18岁
obj2.intr();
//I'm Han meimei,I'm 20 years old
当我们调用obj和obj2中的intr方法时,输出的是各自对象中的name和age,如果我们需要使用obj中的参数执行obj2的intr方法,就可以使用call、apply、bind实现
1)先看一下call
obj.intr.call(obj2);
//我叫Han meimei,我20岁
obj2.intr.call(obj);
//I'm Li lei,I'm 18 years old
由上可知,当执行第一句时,obj.intr中的this指向发生了改变,指向了obj2
同理,当执行第二句时,obj2.intr中的this指向了obj
2)再来看看apply和bind
obj.intr.apply(obj2);
//我叫Han meimei,我20岁
obj.intr.bind(obj2)();
//我叫Han meimei,我20岁
可以看到这里apply和call是一样的,但是bind返回的是一个函数,所以需要调用后才执行intr方法
三者传参的区别
var obj={
name:'Li lei',
intr:function( age, city ){
console.log(`我叫${this.name},我${age}岁,我来自${city}`);
}
}
var obj2={
name:'Han meimei',
intr:function( age, city ){
console.log(`I'm ${this.name},I'm ${age} years old,I'm from ${city}`);
}
}
obj.intr.call( obj2, 20, '中国' );
//我叫Han meimei,我20岁,我来自中国
obj.intr.apply( obj2, [ 20, '中国' ] );
//我叫Han meimei,我20岁,我来自中国
obj.intr.bind( obj2, 20, '中国' );
//我叫Han meimei,我20岁,我来自中国
可以看到call和bind都是独立传递,而apply是以数组传递参数的,参数也可以是方法或对象
总结
call、apply、bind可以将某个函数的this指向修改为传入这三个方法中的第一个参数,其中call、apply会立即执行,bind返回的是一个函数,需调用后执行。
第二个参数是传入要执行的方法中的参数,call、bind是独立传递参数,apply是以数组传递参数的
使用场景:
1、需要改变某个函数的this指向时
2、当参数较少时可以使用call,参数较多可以使用apply以数组的方式传递
3、当需要重复调用时,可以使用bind新定义一个方法
38.requireJS的核心原理是什么?(如何动态加载的?如何避免多次加载的?如何缓存的?)
核心是js的加载模块,通过正则匹配模块以及模块的依赖关系,保证文件加载的先后顺序,根据文件的路径对加载过的文件做了缓存。
39.AMD,CMD规范区别?
1.AMD 是 RequireJS 在推广过程中对模块定义的规范化产出。
2.CMD 是 SeaJS 在推广过程中对模块定义的规范化产出。
区别:
1、 对于依赖的模块,AMD 是提前执行,CMD 是延迟执行。不过 RequireJS 从 2.0 开始,也改成可以延迟执行(根据写法不同,处理方式不同)。
2、 CMD 推崇依赖就近,AMD 推崇依赖前置。
3、 AMD 的 API 默认是一个当多个用,CMD 的 API 严格区分,推崇职责单一。
// CMD
define(function(require, exports, module) {
var a = require('./a')
a.doSomething()
// 此处略去 100 行
var b = require('./b')
// 依赖可以就近书写
b.doSomething()
})
// AMD 默认推荐
define(['./a', './b'], function(a, b) {
// 依赖必须一开始就写好
a.doSomething();
// 此处略去 100 行
b.doSomething();
})
40.请你谈谈Cookie的弊端?
cookie
1.IE6或更低版本最多20个cookie
2.IE7和之后的版本最后可以有50个cookie。
3.Firefox最多50个cookie
4.chrome和Safari没有做硬性限制 Opera 会清理近期最少使用的Firefox会随机清理 4096字节,为了兼容性,一般不能超过 IE 提供了一种存储可以持久化用户数据,叫做IE5.0就开始支持。每个数据最多128K,每个域名下最多1M。这个持久化数据放在缓存中,如果缓存没有清理,那么会一直存在。
优点:
极高的扩展性和可用性
1.通过良好的编程,控制保存在cookie中的session对象的大小。
2.通过加密和安全传输技术(SSL),减少cookie被破解的可能性。
3.只在cookie中存放不敏感数据,即使被盗也不会有重大损失。
4.控制cookie的生命期,使之不会永远有效。偷盗者很可能拿到一个过期的cookie。
缺点:
1.Cookie数量和长度的限制。每个domain最多只能有20条cookie,每个cookie长度不能超过4KB,否则会被截掉。
2.安全性问题。如果cookie被人拦截了,那人就可以取得所有的session信息。即使加密也与事无补,因为拦截者并不需要知道cookie的意义,他只要原样转发cookie就可以达到目的了。
3.有些状态不可能保存在客户端。例如,为了防止重复提交表单,我们需要在服务器端保存一个计数器。如果我们把这个计数器保存在客户端,那么它起不到任何作用。
41. 介绍路由的history
history对象保存着用户的上网记录,从浏览器窗口打开的那一刻算起。
出于安全的考虑,开发人员无法得知用户浏览过的URL。
不过,借由用户访问过的页面列表,同样可以在不知道实际URL的情况下实现后退与前进
一、history对象的方法
go(Stirng|number)
使用go方法可以在用户的历史记录中任意跳转,可以向后也可以向前。这个方法接受一个参数,表示向后或向前跳转的页面数的一个整数值。负数表示向后跳转(类似浏览器的后退按钮),正数表示向前跳转(类似浏览器的前进按钮)。来看下例子
//后退一页
history.go(-1)
//前进一页
history.go(1)
//前进两页
history.go(2)
也可以给go()方法船体一个字符串参数,此时浏览器会跳转到历史记录中包含改字符串的第一个位置,可能后退也可能前进,具体要看哪一个位置最近。如果历史记录中不包含该字符串,则什么都不做。例如:
//跳转到最近的wrox.com页面
history.go("wrox.com")
//跳转到最近的douban.cn页面
history.go("douban.cn")
back()和forward
这两个方法可以来代替go(),模仿浏览器的后退和前进功能
back()相当于 go(-1) 后退一个页面
forward相当于go(1) 前进一个页面
注:接下来几个方法是html5新增的方法
二、html5中history新增的方法
pushState(state,title,url)
该方法的作用是 在历史记录中新增一条记录,改变浏览器地址栏的url,但是,不刷新页面。
pushState对象接受三个参数,
• state:一个与添加的记录相关联的状态对象,主要用于popstate事件。该事件触发时,该对象会传入回调函数。也就是说,浏览器会将这个对象序列化以后保留在本地,重新载入这个页面的时候,可以拿到这个对象。如果不需要这个对象,此处可以填null。
• title:新页面的标题。但是,现在所有浏览器都忽视这个参数,所以这里可以填空字符串。
• url:新的网址,必须与当前页面处在同一个域。浏览器的地址栏将显示这个网址。
举个例子,假设当前网址是hello.com/1.html,使用puchState()方法在浏览记录中添加一个新纪录
var stateObj={foo:'bar'}
history.pushState(starteObj,'','2.html')
添加新纪录后,浏览器的地址栏立刻显示`hello.com/2.html,但不会跳转到2.html,也不会检查2.html是否存在,它只是成为浏览历史中的最新记录。
总之,pushState()方法不会触发页面刷新,只是导致history对象发生变化,地址栏会有反应,使用该方法后,就可以使用history.state属性读出状态对象
var stateObj={foo:'bar'}
history.pushState(starteObj,'','2.html')
history.state //=> {foo:"bar"}
注意:如果pushState的URL参数设置了一个新的hash值,并不会触发hashchange事件。
replaceState(state,title,url)
replaceState方法的作用是替换当前的历史记录,其他的都与pushState()方法一模一样。
假定当前网页是example.com/example.html。
history.pushState({page: 1}, 'title 1', '?page=1')
// URL 显示为 http://example.com/example.html?page=1
history.pushState({page: 2}, 'title 2', '?page=2');
// URL 显示为 http://example.com/example.html?page=2
history.replaceState({page: 3}, 'title 3', '?page=3');
// URL 显示为 http://example.com/example.html?page=3
history.back()
// URL 显示为 http://example.com/example.html?page=1
history.back()
// URL 显示为 http://example.com/example.html
history.go(2)
// URL 显示为 http://example.com/example.html?page=3
三、popstate事件
popstate事件是window对象上的事件,配合pushState()和replaceState()方法使用。当同一个文档(可以理解为同一个网页,不能跳转,跳转了就不是同一个网页了)的浏览历史出现变化时,就会触发popstate事件。
上面我们说过,调用pushState()或者replaceState()方法都会改变当前的历史记录,仅仅调用pushState()方法或replaceState()方法 ,并不会触发该事件,另外一个条件是用户必须点击浏览器的倒退按钮或者前进按钮,或者使用js调用history.back()或者history.forward()等方法。
所以,记住popstate事件触发的条件
- 处在同一个文档(同一个html页面)
- 文档的浏览历史(即history对象)发生改变
只要符合这两个条件,popstate事件就会触发
具体例子
//index.html
<head>
<script>
window.onpopstate=function(){
alert('location '+document.location+',state '+jsON.stringify(event.state))
}
</script>
</head>
<body>
<!--第二步 -->
<button onclick="window.history.back()">后退</button>
<button onclick="window.history.forward()">前进</button>
<!--第一步 -->
<button onclick="window.history.pushState(null,'','1.html')">pushState</button>
</body>
先点击pushState按钮,在点击后退按钮,就会触发popstate事件
再来一个例子
//index.html
<head>
<script>
window.onpopstate=function(){
alert('location '+document.location+',state '+jsON.stringify(event.state))
}
</script>
</head>
<body>
<a href="#one">#one</a>
</body>
直接点击a标签,也可以触发popstate事件
42.如何解决跨域的问题
- jsonp:只支持 GET,不支持 POST 请求,不安全 XSS
- cors:需要后台配合进行相关的设置
- postMessage:配合使用 iframe,需要兼容 IE6、7、8、9
- document.domain:仅限于同一域名下的子域
- websocket:需要后台配合修改协议,不兼容,需要使用 http://socket.io
- proxy:使用代理去避开跨域请求,需要修改 nginx、apache 等的配置(最常用)
43.常见Http请求头
- Host (主机和端口号)
- Connection (链接类型)
- Upgrade-Insecure-Requests (升级为 HTTPS 请求)
- User-Agent (浏览器名称)
- Accept (传输文件类型)
- Referer (页面跳转处)
- Accept-Encoding(文件编解码格式)
- Cookie (Cookie)
- x-requested-with :XMLHttpRequest (是 Ajax 异步请求)
44. 使用过webpack⾥面哪些plugin和loader
loader:
- file-loader:把文件输出到一个文件夹中,在代码中通过相对URL引用输入的文件。
- url-loader:和file类似,但能在文件很小的情况下以base64方式把文件内容注入到代码中。
- image-loader:加载并压缩图片文件。
- babel-loader:把ES6转换为ES5。
- css-loader:加载CSS,支持模块化、压缩、文件导入等特性。
- style-loader:把CSS代码注入到JavaScript中,通过DOM操作去加载CSS。
- eslint-loader:通过ESlint检查JavaScript代码。
plugin:
- define-plugin:定义环境变量。
- commons-chunk-plugin:提取公共代码。
- uglifyjs-webpack-plugin:缩小(压缩优化)js文件
45. webpack⾥面的插件是怎么实现的
大部分时候,webpack 对我来说就是个黑盒。
且让我们抛开所有让人畏惧的细节,设想一下,webpack 在构建时会发生什么:
读取入口文件
一步一步处理
输出各种 assets 文件
显然,期间的每一步,应该都是设定好的,而非天马行空。
那么,我们用 webpack 插件扩展的,究竟是什么?
勾子
勾子用于拦截组件间传递的函数、事件、或消息。
在 webpack 构建过程中,文件从上一环节传递到下一环节,这期间,就有拦截的机会
Tapable
Tapable 是 webpack 内置各种勾子的实际提供者。
比如,我们调用 SyncHook 来创建一个同步的 hook:
import { SyncHook } from 'tapable';
const hook = new SyncHook();
创建完 hook 后,我们可以 tap(窃听)该 hook:
hook.tap('MyPlugin', () => {
// 窃听成功
});
这样在该 hook 执行时,我们的窃听函数就会执行 - 这正是 webpack 插件的原理,通过 tapable,webpack 主动开放各种 hook。我们只需要 tap 回调到 hook 上,就能保证它们在某个时间点被执行:
hook.call(); // 某个时间点执行该 hook,所有窃听的回调都会被执行
除了 SyncHook 外,tapable 还提供了其它类型的勾子,具体可查询文档。
当然,在 webpack 下我们并不直接调用 tapable,因此这里仅就它的原理稍作了解。
webpack 插件写法
在 webpack 下,它推荐的插件写法是这样:
class MyWebpackPlugin {
apply(compiler) {
// 定义一个 class,其中有一个 apply 方法,
// apply 方法接收 webpack 的 compiler 对象
}
}
在插件完成后,我们就可以在配置文件中调用插件:
{
plugins: [
new MyWebpackPlugin()
]
}
webpack 在运行时,会调用我们的插件定义的 apply 方法:
if (Array.isArray(options.plugins)) {
for (const plugin of options.plugins) {
if (typeof plugin === 'function') {
plugin.call(compiler, compiler);
} else {
plugin.apply(compiler);
}
}
}
于是,我们的勾子们就顺利插入到 webpack 生命周期中。
webpack 勾子
在知道 webpack 插件的运转原理及 webpack 插件写法之后,我们只要梳理清楚 webpack 所有勾子及勾子触发的时序即可对症下药,在需要的勾子上挂上“窃听器”。
webpack 的勾子分三类:
- Compiler hooks
- Compilation hooks
- JavascriptParser hooks
总共加起来,大约有百来个。一一掌握这百来个勾子并不现实;针对需求,然后查找文档、定位可用的勾子可能更切实际。
原文地址:https://blog.zfanw.com/how-webpack-plugin-works/
46. dev-server是怎么跑起来?
1.安装了webpack以及自己需要使用的loader和plugins,由于webpack-dev-server是个独立的npm包,所以我们需要在npm下安装它
2.在webpack.config.js中进行配置:
devServer中常用的配置对象属性如下:
- contentBase:”./”
本地服务器在哪个目录搭建页面,一般我们在当前目录即可; - historyApiFallback:true
当我们搭建spa应用时非常有用,它使用的是HTML5 History Api,任意的跳转或404响应可以指向 index.html 页面; - inline:true
用来支持dev-server自动刷新的配置,webpack有两种模式支持自动刷新,一种是iframe模式,一种是inline模式;使用iframe模式是不需要在devServer进行配置的,只需使用特定的URL格式访问即可;不过我们一般还是常用inline模式,在devServer中对inline设置为true后,当我们启动webpack-dev-server时仍要需要配置inline才能生效,这一点我们之后再说; - hot:true
启动webpack热模块替换特性,这里也是坑最多的地方,不少博客都将hot设置了true,我们姑且也设置为true,之后再看; - port:端口号(默认8080)
在devServer中设置inline:true后这里也要设置一下!
47.常见项目优化方法
常见优化方法
从资源请求数量+代码执行效率两个角度来考虑
DOM结构
- 样式表放在头部,防止白屏和闪屏
- JS脚本放在底部或异步获取,防止阻塞资源加载
- 使用语义化标签,优化精简DOM结构
- 减少DOM操作频率
- 减少重绘与回流
JS脚本
- 优化脚本结构,移除重复的脚本
- 模块就近加载(CMD)
- 按需加载加载组件和路由
- 图片懒加载,列表分页
- 使用节流与防抖减少事件触发频率
- 尽量使用CSS动画代替js动画,开启硬件加速
- 资源打包上线
- 使用打包构建工具(webpack)清除注释,压缩页面资源,js、css、html、图片、字体等等
- 混淆js代码
- 分离非业务逻辑相关vendor依赖,使用长缓存缓存和CDN分发网络
服务器优化
- 减少Http请求,合并页面资源,js,css单一入口。js特殊可以分为两个文件,一个业务逻辑,一个非业务逻辑
- 把小图标合成雪碧图,不太适用经常更新的移动端开发
- 把小的图片,字体等资源base64化
- 开启GZip压缩,减少资源传输大小
- 使用强缓存和协商缓存,减少资源重复请求
Vue中可以优化的点
- Vue库dist里面的Runtime-only比Runtime+Compiler小30%
- Vue的计算属性会根据依赖的data进行缓存
- keep-alive可以缓存常用组件
- Vuex中的getter也会根据依赖的state进行缓存
- v-for中唯一key的使用
- Vue全局错误处理errorHandle
- Vue路由懒加载
- Vue组件动态加载
React中可以优化的点
- 在constructor改变this指向代替箭头函数和render内绑定this,避免函数作为props带来不必要的rerender
- shouldComponentUpdate,减少不不必要的rerender
- PureComponent高性能组件只响应引用数据的深拷贝
- 使用唯一key优化list diff
- 合并setState操作,减少虚拟dom对比频率
- React路由动态加载react-loadable
48. 抽取公共文件是怎么配置的
在不明白CommonsChunkPlugin的使用情况下,直接上手webpack4的splitChunks,实在是难上加难。为了能更好的理解splitChunks的使用,必须出个题目,练练手,才能从中有所收获(下面的题目不考虑实际应用场景):
从指定入口文件中提取公共文件
CommonsChunkPlugin的实现:
entry: {
index:'./src/index.js',
index1:'./src/index1.js',
index2:'./src/index2.js'
},
plugins: [
new CommonsChunkPlugin({
name:"common1",
chunks:['index','index1','index2']
})
]
其中index和index1以及index2都是打包的入口文件。
49. 项目中如何处理安全问题
随着大前端的快速发展,各种技术不断更新,前端的安全问题也值得我们重视。
今天我们来聊一聊前端常见的7个安全方面问题:
- iframe
- opener
- CSRF(跨站请求伪造)
- XSS(跨站脚本攻击)
- ClickJacking(点击劫持)
- HSTS(HTTP严格传输安全)
- CND劫持
1)、iframe
a、如何让自己的网站不被其他网站的 iframe 引用?
// 检测当前网站是否被第三方iframe引用
// 若相等证明没有被第三方引用,若不等证明被第三方引用。当发现被引用时强制跳转百度。
if(top.location != self.location){
top.location.href = ‘http://www.baidu.com’
}
b、如何禁用,被使用的 iframe 对当前网站某些操作?
sandbox是html5的新属性,主要是提高iframe安全系数。iframe因安全问题而臭名昭著,这主要是因为iframe常被用于嵌入到第三方中,然后执行某些恶意操作。
现在有一场景:我的网站需要 iframe 引用某网站,但是不想被该网站操作DOM、不想加载某些js(广告、弹框等)、当前窗口被强行跳转链接等,我们可以设置 sandbox 属性。如使用多项用空格分隔。
- allow-same-origin:允许被视为同源,即可操作父级DOM或cookie等
- allow-top-navigation:允许当前iframe的引用网页通过url跳转链接或加载
- allow-forms:允许表单提交
- allow-scripts:允许执行脚本文件
- allow-popups:允许浏览器打开新窗口进行跳转
- “”:设置为空时上面所有允许全部禁止
2)、opener
如果在项目中需要 打开新标签 进行跳转一般会有两种方式
参考地址:https://paper.seebug.org/538/
1) HTML -> <a target='_blank' href='http://www.baidu.com'>
2) JS -> window.open('http://www.baidu.com')
- 这两种方式看起来没有问题,但是存在漏洞。
- 通过这两种方式打开的页面可以使用 window.opener 来访问源页面的 window 对象。
- 场景:A 页面通过 或 window.open 方式,打开 B 页面。但是 B 页面存在恶意代码如下:
- window.opener.location.replace(‘https://www.baidu.com’) 【此代码仅针对打开新标签有效】
- 此时,用户正在浏览新标签页,但是原来网站的标签页已经被导航到了百度页面。
- 恶意网站可以伪造一个足以欺骗用户的页面,使得进行恶意破坏。
- 即使在跨域状态下 opener 仍可以调用 location.replace 方法。
<a target="_blank" href="">
<a target="_blank" href="" rel="noopener noreferrer nofollow">a标签跳转url</a>
通过 rel 属性进行控制:
noopener:会将 window.opener 置空,从而源标签页不会进行跳转(存在浏览器兼容问题)
noreferrer:兼容老浏览器/火狐。禁用HTTP头部Referer属性(后端方式)。
nofollow:SEO权重优化
b、window.open()
<button onclick='openurl("http://www.baidu.com")'>click跳转</button>
function openurl(url) {
var newTab = window.open();
newTab.opener = null;
newTab.location = url;
}
3)、CSRF / XSRF(跨站请求伪造)
你可以这么理解 CSRF 攻击:攻击者盗用了你的身份,以你的名义进行恶意请求。它能做的事情有很多包括:以你的名义发送邮件、发信息、盗取账号、购买商品、虚拟货币转账等。
总结起来就是:个人隐私暴露及财产安全问题。
- 阐述 CSRF 攻击思想:(核心2和3)
- 1、浏览并登录信任网站(举例:淘宝)
- 2、登录成功后在浏览器产生信息存储(举例:cookie)
- 3、用户在没有登出淘宝的情况下,访问危险网站
- 4、危险网站中存在恶意代码,代码为发送一个恶意请求(举例:购买商品/余额转账)
- 5、携带刚刚在浏览器产生的信息进行恶意请求
- 6、淘宝验证请求为合法请求(区分不出是否是该用户发送)
- 7、达到了恶意目标
防御措施(推荐添加token / HTTP头自定义属性)
- 涉及到数据修改操作严格使用 post 请求而不是 get 请求
- HTTP 协议中使用 Referer 属性来确定请求来源进行过滤(禁止外域)
- 请求地址添加 token ,使黑客无法伪造用户请求
- HTTP 头自定义属性验证(类似上一条)
- 显示验证方式:添加验证码、密码等
4)、XSS/CSS(跨站脚本攻击)
XSS又叫CSS(Cross Site Script),跨站脚本攻击:攻击者在目标网站植入恶意脚本(js / html),用户在浏览器上运行时可以获取用户敏感信息(cookie / session)、修改web页面以欺骗用户、与其他漏洞相结合形成蠕虫等。
浏览器遇到 html 中的 script 标签时,会解析并执行其中的js代码。举例:
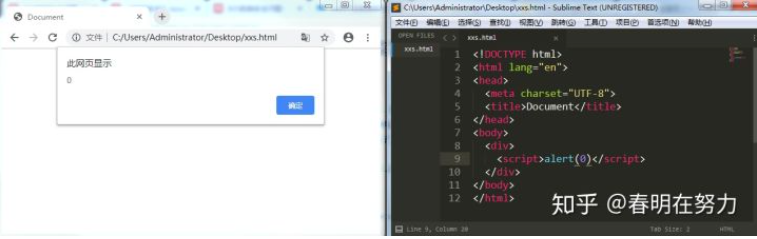
针对这种情况,我们对特殊字符进行转译就好了(vue/react等主流框架已经避免类似问题,vue举例:不能在template中写script标签,无法在js中通过ref或append等方式动态改变或添加script标签)
XSS类型:
- 持久型XSS:将脚本植入到服务器上,从而导致每个访问的用户都会执行
- 非持久型XSS:对个体用户某url的参数进行攻击
防御措施(对用户输入内容和服务端返回内容进行过滤和转译)
- 现代大部分浏览器都自带 XSS 筛选器,vue / react 等成熟框架也对 XSS 进行一些防护
- 即便如此,我们在开发时也要注意和小心
- 对用户输入内容和服务端返回内容进行过滤和转译
- 重要内容加密传输
- 合理使用get/post等请求方式
- 对于URL携带参数谨慎使用
- 我们无法做到彻底阻止,但是能增加黑客攻击成本,当成本与利益不符时自然会降低风险
5)、ClickJacking(点击劫持)
ClickJacking 翻译过来被称为点击劫持。一般会利用透明 iframe 覆盖原网页诱导用户进行某些操作达成目的。
防御措施
在HTTP投中加入 X-FRAME-OPTIONS 属性,此属性控制页面是否可被嵌入 iframe 中【DENY:不能被所有网站嵌套或加载;SAMEORIGIN:只能被同域网站嵌套或加载;ALLOW-FROM URL:可以被指定网站嵌套或加载。】
判断当前网页是否被 iframe 嵌套(详情在第一条 firame 中)
6)、HSTS(HTTP Strict Transport Security:HTTP严格传输安全)
网站接受从 HTTP 请求跳转到 HTTPS 请求的做法,例如我们输入“http://www.baidu.com”或“www.baidu.com”最终都会被302重定向到“https://www.baidu.com”。这就存在安全风险,当我们第一次通过 HTTP 或域名进行访问时,302重定向有可能会被劫持,篡改成一个恶意或钓鱼网站。
HSTS:通知浏览器此网站禁止使用 HTTP 方式加载,浏览器应该自动把所有尝试使用 HTTP 的请求自动替换为 HTTPS 进行请求。用户首次访问时并不受 HSTS 保护,因为第一次还未形成链接。我们可以通过 浏览器预置HSTS域名列表 或 将HSTS信息加入到域名系统记录中,来解决第一次访问的问题。
7)、CDN劫持
出于性能考虑,前端应用通常会把一些静态资源存放到CDN(Content Delivery Networks)上面,例如 js 脚本和 style 文件。这么做可以显著提高前端应用的访问速度,但与此同时却也隐含了一个新的安全风险。如果攻击者劫持了CDN,或者对CDN中的资源进行了污染,攻击者可以肆意篡改我们的前端页面,对用户实施攻击。
现在的CDN以支持SRI为荣,script 和 link 标签有了新的属性 integrity,这个属性是为了防止校验资源完整性来判断是否被篡改。它通过 验证获取文件的哈希值是否和你提供的哈希值一样来判断资源是否被篡改。
使用 SRI 需要两个条件:一是要保证 资源同域 或开启跨域,二是在<script>中 提供签名 以供校验。

integrity 属性分为两个部分,第一部分是指定哈希值的生成算法(例:sha384),第二部分是经过编码的实际哈希值,两者之前用一个短横(-)来分隔
这个属性也存在兼容问题

50、为什么要语义化?
为了在没有CSS的情况下,页面也能呈现出很好地内容结构、代码结构
用户体验:例如title、alt用于解释名词或解释图片信息、label标签的活用;
有利于SEO :和搜索引擎建立良好沟通,有助于爬虫抓取更多的有效信息:
爬虫依赖于标签来确定上下文和各个关键字的权重;
方便其他设备解析(如屏幕阅读器、盲人阅读器、移动设备)以意义的方式来渲染网页;
便于团队开发和维护,语义化更具可读性,是下一步吧网页的重要动向,遵循W3C标准的团队都遵循这个标准,可以减少差异化
51.文件上传如何做断点续传?
前端
前端大文件上传网上的大部分文章已经给出了解决方案
核心是利用 Blob.prototype.slice 方法,和数组的 slice 方法相似,调用的 slice 方法可以返回原文件的某个切片
这样我们就可以根据预先设置好的切片最大数量将文件切分为一个个切片,然后借助 http 的可并发性,同时上传多个切片,这样从原本传一个大文件,变成了同时传多个小的文件切片,可以大大减少上传时间
另外由于是并发,传输到服务端的顺序可能会发生变化,所以我们还需要给每个切片记录顺序
服务端
服务端需要负责接受这些切片,并在接收到所有切片后合并切片
这里又引伸出两个问题
何时合并切片,即切片什么时候传输完成 如何合并切片
第一个问题需要前端进行配合,前端在每个切片中都携带切片最大数量的信息,当服务端接受到这个数量的切片时自动合并,也可以额外发一个请求主动通知服务端进行切片的合并
第二个问题,具体如何合并切片呢?这里可以使用 nodejs 的 api fs.appendFileSync,它可以同步地将数据追加到指定文件,也就是说,当服务端接受到所有切片后,先创建一个最终的文件,然后将所有切片逐步合并到这个文件中
52.new运算符的实现机制?
var new2 = function (func) {
var o = Object.create(func.prototype);
var k = func.call(o);
if (typeof k === 'object') {
return k;
} else {
return o;
}
}
53.描述一下EventLoop的执行过程
- 一开始整个脚本作为一个宏任务执行
- 执行过程中同步代码直接执行,宏任务进入宏任务队列,微任务进入微任务队列
- 当前宏任务执行完出队,检查微任务列表,有则依次执行,直到全部执行完
- 执行浏览器UI线程的渲染工作
- 检查是否有Web Worker任务,有则执行
- 执行完本轮的宏任务,回到2,依此循环,直到宏任务和微任务队列都为空
54.Promise和Callback有什么区别?
相比于callback,Promise 具有更易读的代码组织形式(链式结构调用),更好的异常处理方式(在调用 Promise 的末尾添加上一个catch方法捕获异常即可),以及异步操作并行处理的能力(Promise.all() Promise.race()等)。
callback最大的问题就是我们通常说的回调地狱,一旦业务逻辑复杂了,我们不得不使用大量的嵌套回调代码,可维护性很低.
55.用js写一个数组扁平化函数
// reduce
function flatten(arr = []) {
return arr.reduce((result, item) => {
return result.concat(Array.isArray(item) ? flatten(item) : item)
}, [])
}
// (toString | join) & split(利用数组的toString或者join,将数组转化为字符串)
function flatten(arr = []) {
return arr.toString().split(',').map(item => Number(item))
}
56.csrf跨站攻击怎么解决
CSRF, 跨站请求伪造,它可以在用户毫不知情的情况下以用户名义伪造请求发送给受攻击站点,从而对用户或者网站造成攻击. 预防措施如下:
服务器端验证HTTP Referer字段, Referer记录了该HTTP请求的来源地址•在请求地址中添加token并验证•在HTTP头中自定义属性并验证
57.用js实现数组随机取数,每次返回的值都不一样
function getUniqueItems(arr, num) {
let temp = [];
for (let index in arr) {
temp.push(arr[index]);
}
let res = [];
for (let i = 0; i<num; i++) {
if (temp.length>0) {
let arrIndex = Math.floor(Math.random()*temp.length);
res[i] = temp[arrIndex];
temp.splice(arrIndex, 1);
} else {
break;
}
}
return res;
}
58.Promise的基础题
const promise1 = new Promise((resolve, reject) => {
console.log('promise1')
})
console.log('1', promise1);
过程分析:
从上至下,先遇到new Promise,执行该构造函数中的代码promise1
然后执行同步代码1,此时promise1没有被resolve或者reject,因此状态还是pending
结果:
'promise1'
'1' Promise{<pending>}
59.Promise的基础题
const promise = new Promise((resolve, reject) => {
console.log(1);
resolve('success')
console.log(2);
});
promise.then(() => {
console.log(3);
});
console.log(4);
过程分析:
- 从上至下,先遇到new Promise,执行其中的同步代码1
- 再遇到resolve(‘success’), 将promise的状态改为了resolved并且将值保存下来
- 继续执行同步代码2
- 跳出promise,往下执行,碰到promise.then这个微任务,将其加入微任务队列
- 执行同步代码4
- 本轮宏任务全部执行完毕,检查微任务队列,发现promise.then这个微任务且状态为1. resolved,执行它。
结果:
1 2 4 3
60.Promise的基础题
const promise = new Promise((resolve, reject) => {
console.log(1);
console.log(2);
});
promise.then(() => {
console.log(3);
});
console.log(4);
过程分析:
- 和题目二相似,只不过在promise中并没有resolve或者reject
- 因此promise.then并不会执行,它只有在被改变了状态之后才会执行
结果:
1 2 4
61.Promise的基础题
const fn = () => (new Promise((resolve, reject) => {
console.log(1);
resolve('success')
}))
fn().then(res => {
console.log(res)
})
console.log('start')
过程分析:
- 这道题里最先执行的是’start’吗 ?
- 请仔细看看哦,fn函数它是直接返回了一个new Promise的,而且fn函数的调用是在start之前,所以它里面的内容应该会先执行。
结果:
1
'start'
'success'
62.Promise的基础题
const fn = () =>
new Promise((resolve, reject) => {
console.log(1);
resolve("success");
});
console.log("start");
fn().then(res => {
console.log(res);
});
过程分析:
- 是的,现在start就在1之前打印出来了,因为fn函数是之后执行的。
- 注意⚠️:之前我们很容易就以为看到new Promise()就执行它的第一个参数函数了,其实这是不对的,就像这两道题中,我们得注意它是不是被包裹在函数当中,如果是的话,只有在函数调用的时候才会执行。
结果:
"start"
1
"success"
63.Promise结合setTimeout
console.log('start')
setTimeout(() => {
console.log('time')
})
Promise.resolve().then(() => {
console.log('resolve')
})
console.log('end')
过程分析:
- 刚开始整个脚本作为一个宏任务来执行,对于同步代码直接压入执行栈进行执行,因此先打印出start和end。
- setTimout作为一个宏任务被放入宏任务队列(下一个)
- Promise.then作为一个微任务被放入微任务队列
- 本次宏任务执行完,检查微任务,发现Promise.then,执行它
接下来进入下一个宏任务,发现setTimeout,执行。
结果:
'start'
'end'
'resolve'
'time'
64.Promise结合setTimeout
const promise = new Promise((resolve, reject) => {
console.log(1);
setTimeout(() => {
console.log("timerStart");
resolve("success");
console.log("timerEnd");
}, 0);
console.log(2);
});
promise.then((res) => {
console.log(res);
});
console.log(4);
过程分析:
- 从上至下,先遇到new Promise,执行该构造函数中的代码1
- 然后碰到了定时器,将这个定时器中的函数放到下一个宏任务的延迟队列中等待执行
- 执行同步代码2
- 跳出promise函数,遇到promise.then,但其状态还是为pending,这里理解为先不执行
- 执行同步代码4
- 一轮循环过后,进入第二次宏任务,发现延迟队列中有setTimeout定时器,执行它
- 首先执行timerStart,然后遇到了resolve,将promise的状态改为resolved且保存结果并将1. 之前的promise.then推入微任务队列
- 继续执行同步代码timerEnd
- 宏任务全部执行完毕,查找微任务队列,发现promise.then这个微任务,执行它。
结果:
1
2
4
"timerStart"
"timerEnd"
"success"
65.Promise结合setTimeout
Promise.resolve().then(() => {
console.log('promise1');
const timer2 = setTimeout(() => {
console.log('timer2')
}, 0)
});
const timer1 = setTimeout(() => {
console.log('timer1')
Promise.resolve().then(() => {
console.log('promise2')
})
}, 0)
console.log('start');
过程分析:
这道题稍微的难一些,在promise中执行定时器,又在定时器中执行promise;
并且要注意的是,这里的Promise是直接resolve的,而之前的new Promise不一样。
(偷偷告诉你,这道题往下一点有流程图)
因此过程分析为:
- 刚开始整个脚本作为第一次宏任务来执行,我们将它标记为宏1,从上至下执行
- 遇到Promise.resolve().then这个微任务,将then中的内容加入第一次的微任务队列标记为微1
- 遇到定时器timer1,将它加入下一次宏任务的延迟列表,标记为宏2,等待执行(先不管里面是什么内容)
- 执行宏1中的同步代码start
- 第一次宏任务(宏1)执行完毕,检查第一次的微任务队列(微1),发现有一个promise.then这个微任务需要执行
- 执行打印出微1中同步代码promise1,然后发现定时器timer2,将它加入宏2的后面,标记为宏3
- 第一次微任务队列(微1)执行完毕,执行第二次宏任务(宏2),首先执行同步代码timer1
- 然后遇到了promise2这个微任务,将它加入此次循环的微任务队列,标记为微2
- 宏2中没有同步代码可执行了,查找本次循环的微任务队列(微2),发现了promise2,执行它
- 第二轮执行完毕,执行宏3,打印出timer2
结果:
'start'
'promise1'
'timer1'
'promise2'
'timer2'
66.Promise结合setTimeout
const promise1 = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('success')
}, 1000)
})
const promise2 = promise1.then(() => {
throw new Error('error!!!')
})
console.log('promise1', promise1)
console.log('promise2', promise2)
setTimeout(() => {
console.log('promise1', promise1)
console.log('promise2', promise2)
}, 2000)
过程分析:
- 从上至下,先执行第一个new Promise中的函数,碰到setTimeout将它加入下一个宏任务列表
- 跳出new Promise,碰到promise1.then这个微任务,但其状态还是为pending,这里理解为先不执行
- promise2是一个新的状态为pending的Promise
- 执行同步代码console.log(‘promise1’),且打印出的promise1的状态为pending
- 执行同步代码console.log(‘promise2’),且打印出的promise2的状态为pending
- 碰到第二个定时器,将其放入下一个宏任务列表
- 第一轮宏任务执行结束,并且没有微任务需要执行,因此执行第二轮宏任务
- 先执行第一个定时器里的内容,将promise1的状态改为resolved且保存结果并将之前的promise1.then推入微任务队列
- 该定时器中没有其它的同步代码可执行,因此执行本轮的微任务队列,也就是promise1.then,它抛出了一个错误,且将promise2的状态设置为了rejected
- 第一个定时器执行完毕,开始执行第二个定时器中的内容
- 打印出’promise1’,且此时promise1的状态为resolved
- 打印出’promise2’,且此时promise2的状态为rejected
结果:
'promise1' Promise{<pending>}
'promise2' Promise{<pending>}
test5.html:102 Uncaught (in promise) Error: error!!! at test.html:102
'promise1' Promise{<resolved>: "success"}
'promise2' Promise{<rejected>: Error: error!!!}
67.async/await的几道题
async function async1() {
console.log("async1 start");
await async2();
console.log("async1 end");
}
async function async2() {
console.log("async2");
}
async1();
console.log('start')
过程分析:
- 首先一进来是创建了两个函数的,我们先不看函数的创建位置,而是看它的调用位置
发现async1函数被调用了,然后去看看调用的内容 - 执行函数中的同步代码async1 start,之后碰到了await,它会阻塞async1后面代码的执行,1. 因此会先去执行async2中的同步代码async2,然后跳出async1
- 跳出async1函数后,执行同步代码start
- 在一轮宏任务全部执行完之后,再来执行刚刚await后面的内容async1 end。
在这里,你可以理解为「紧跟着await后面的语句相当于放到了new Promise中,下一行及之后的语句相当于放在Promise.then中」。
结果:
'async1 start'
'async2'
'start'
'async1 end'
68.async/await的几道题
现在将async结合定时器看看。
给题目一中的 async2函数中加上一个定时器:
async function async1() {
console.log("async1 start");
await async2();
console.log("async1 end");
}
async function async2() {
setTimeout(() => {
console.log('timer')
}, 0)
console.log("async2");
}
async1();
console.log("start")
过程分析:
没错,定时器始终还是最后执行的,它被放到下一条宏任务的延迟队列中。
结果:
'async1 start'
'async2'
'start'
'async1 end'
'timer'
69.async/await的几道题
来吧,小伙伴们,让我们多加几个定时器看看。😁
async function async1() {
console.log("async1 start");
await async2();
console.log("async1 end");
setTimeout(() => {
console.log('timer1')
}, 0)
}
async function async2() {
setTimeout(() => {
console.log('timer2')
}, 0)
console.log("async2");
}
async1();
setTimeout(() => {
console.log('timer3')
}, 0)
console.log("start")
过程分析:
思考一下🤔,执行结果会是什么?
其实如果你能做到这里了,说明你前面的那些知识点也都掌握了,我就不需要太过详细的步骤分析了。
结果:
'async1 start'
'async2'
'start'
'async1 end'
'timer2'
'timer3'
'timer1'
定时器谁先执行,你只需要关注谁先被调用的以及延迟时间是多少,这道题中延迟时间都是0,所以只要关注谁先被调用的。。
70.async/await的几道题
来吧,小伙伴们,让我们多加几个定时器看看。😁
async function async1 () {
console.log('async1 start');
await new Promise(resolve => {
console.log('promise1')
})
console.log('async1 success');
return 'async1 end'
}
console.log('srcipt start')
async1().then(res => console.log(res))
console.log('srcipt end')
过程分析:
这道题目比较有意思,大家要注意了。
在async1中await后面的Promise是没有返回值的,也就是它的状态始终是pending状态,因此相当于一直在await,await,await却始终没有响应…
所以在await之后的内容是不会执行的,也包括async1后面的 .then。
结果:
'script start'
'async1 start'
'promise1'
'script end'
71.async/await的几道题
让我们给上一题中的Promise加上resolve:
async function async1 () {
console.log('async1 start');
await new Promise(resolve => {
console.log('promise1')
resolve('promise1 resolve')
}).then(res => console.log(res))
console.log('async1 success');
return 'async1 end'
}
console.log('srcipt start')
async1().then(res => console.log(res))
console.log('srcipt end')
过程分析:
现在Promise有了返回值了,因此await后面的内容将会被执行:
结果:
'script start'
'async1 start'
'promise1'
'script end'
'promise1 resolve'
'async1 success'
'async1 end'
72.async/await的几道题
让我们给上一题中的Promise加上resolve:
async function async1 () {
console.log('async1 start');
await new Promise(resolve => {
console.log('promise1')
resolve('promise resolve')
})
console.log('async1 success');
return 'async1 end'
}
console.log('srcipt start')
async1().then(res => {
console.log(res)
})
new Promise(resolve => {
console.log('promise2')
setTimeout(() => {
console.log('timer')
})
})
过程分析:
这道题应该也不难,不过有一点需要注意的,在async1中的new Promise它的resovle的值和async1().then()里的值是没有关系的,很多小伙伴可能看到resovle(‘promise resolve’)就会误以为是async1().then()中的返回值。
结果:
'script start'
'async1 start'
'promise1'
'promise2'
'async1 success'
'async1 end'
'timer'
73.async/await的几道题
让我们给上一题中的Promise加上resolve:
async function async1() {
console.log("async1 start");
await async2();
console.log("async1 end");
}
async function async2() {
console.log("async2");
}
console.log("script start");
setTimeout(function() {
console.log("setTimeout");
}, 0);
async1();
new Promise(function(resolve) {
console.log("promise1");
resolve();
}).then(function() {
console.log("promise2");
});
console.log('script end')
过程分析:
有了上面👆几题做基础,相信你很快也能答上来了。
(这道题最后async1 end和promise2的顺序其实在网上饱受争议,我这里使用浏览器Chrome V80,Node v12.16.1的执行结果都是上面这个答案)
结果:
'script start'
'async1 start'
'async2'
'promise1'
'script end'
'async1 end'
'promise2'
'setTimeout'
74.综合题
上面👆的题目都是被我拆分着说一些功能点,现在让我们来做一些比较难的综合题吧。
const first = () => (new Promise((resolve, reject) => {
console.log(3);
let p = new Promise((resolve, reject) => {
console.log(7);
setTimeout(() => {
console.log(5);
resolve(6);
console.log(p)
}, 0)
resolve(1);
});
resolve(2);
p.then((arg) => {
console.log(arg);
});
}));
first().then((arg) => {
console.log(arg);
});
console.log(4);
过程分析:
- 第一段代码定义的是一个函数,所以我们得看看它是在哪执行的,发现它在4之前,所以可以来看看first函数里面的内容了。(这一步有点类似于题目1.5)
- 函数first返回的是一个new Promise(),因此先执行里面的同步代码3
- 接着又遇到了一个new Promise(),直接执行里面的同步代码7
- 执行完7之后,在p中,遇到了一个定时器,先将它放到下一个宏任务队列里不管它,接着向下走
- 碰到了resolve(1),这里就把p的状态改为了resolved,且返回值为1,不过这里也先不执行
- 跳出p,碰到了resolve(2),这里的resolve(2),表示的是把first函数返回的那个Promise的状态改了,也先不管它。
- 然后碰到了p.then,将它加入本次循环的微任务列表,等待执行
- 跳出first函数,遇到了first().then(),将它加入本次循环的微任务列表(p.then的后面执行)
然后执行同步代码4 - 本轮的同步代码全部执行完毕,查找微任务列表,发现p.then和first().then(),依次执行,打印出1和2
- 本轮任务执行完毕了,发现还有一个定时器没有跑完,接着执行这个定时器里的内容,执行同步代码5
- 然后又遇到了一个resolve(6),它是放在p里的,但是p的状态在之前已经发生过改变了,因此这里就不会再改变,也就是说resolve(6)相当于没任何用处,因此打印出来的p为
Promise{<resolved>: 1}。
结果:
3
7
4
1
2
5
Promise{<resolved>: 1}
刷题,刷到这的小伙伴,一定要给自己一朵花,我录题的时候都吐了。。。。。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5W4G4WE0-1645064930550)(https://user-gold-cdn.xitu.io/2020/2/28/1708bb1c9abe9b51?imageView2/0/w/1280/h/960/format/webp/ignore-error/1)]
75.使用Promise实现每隔1秒输出1,2,3
这道题比较简单的一种做法是可以用Promise配合着reduce不停的在promise后面叠加.then,请看下面的代码:
const arr = [1, 2, 3]
arr.reduce((p, x) => {
return p.then(() => {
return new Promise(r => {
setTimeout(() => r(console.log(x)), 1000)
})
})
}, Promise.resolve())
或者你可以更简单一点写:
const arr = [1, 2, 3]
arr.reduce((p, x) => p.then(() => new Promise(r => setTimeout(() => r(console.log(x)), 1000))), Promise.resolve())
76.使用Promise实现红绿灯交替重复亮
红灯3秒亮一次,黄灯2秒亮一次,绿灯1秒亮一次;如何让三个灯不断交替重复亮灯?(用Promise实现)三个亮灯函数已经存在:
function red() {
console.log('red');
}
function green() {
console.log('green');
}
function yellow() {
console.log('yellow');
}
答案:
function red() {
console.log("red");
}
function green() {
console.log("green");
}
function yellow() {
console.log("yellow");
}
const light = function (timer, cb) {
return new Promise(resolve => {
setTimeout(() => {
cb()
resolve()
}, timer)
})
}
const step = function () {
Promise.resolve().then(() => {
return light(3000, red)
}).then(() => {
return light(2000, green)
}).then(() => {
return light(1000, yellow)
}).then(() => {
return step()
})
}
step();
77.封装一个异步加载图片的方法
这个相对简单一些,只需要在图片的onload函数中,使用resolve返回一下就可以了。
来看看具体代码:
function loadImg(url) {
return new Promise((resolve, reject) => {
const img = new Image();
img.onload = function() {
console.log("一张图片加载完成");
resolve(img);
};
img.onerror = function() {
reject(new Error('Could not load image at' + url));
};
img.src = url;
});
78.pc、h5一套代码和两套代码的优劣?
优势
1.降低了开发人员成本
2.提升了维护成本
缺点
1.如果页面过于复杂的话,会造成css文件过大
2.需要兼容更多的应用端
3.因为pc端需要考虑seo,而h5对seo要求较低,所以会造成技术选型不是很匹配。
79.[] == 0等于什么?为什么?
这道题考察的知识点为:javascript隐式转换
JavaScript中的ToPrimitive规则:
当对象类型和原始类型做相等比较时,对象类型会依照ToPrimitive规则转换为原始类型
ToPrimitive指对象类型类型(如:对象、数组)转换为原始类型的操作。
当对象类型需要被转为原始类型时,它会先查找对象的valueOf方法,如果valueOf方法返回原始类型的值,则ToPrimitive的结果就是这个值
如果valueOf不存在或者valueOf方法返回的不是原始类型的值,就会尝试调用对象的toString方法,也就是会遵循对象的ToString规则,然后使用toString的返回值作为ToPrimitive的结果。如果valueOf和toString都没有返回原始类型的值,则会抛出异常。
字符串和数字比较时,会先转为数字类型,空字符为0
所以:
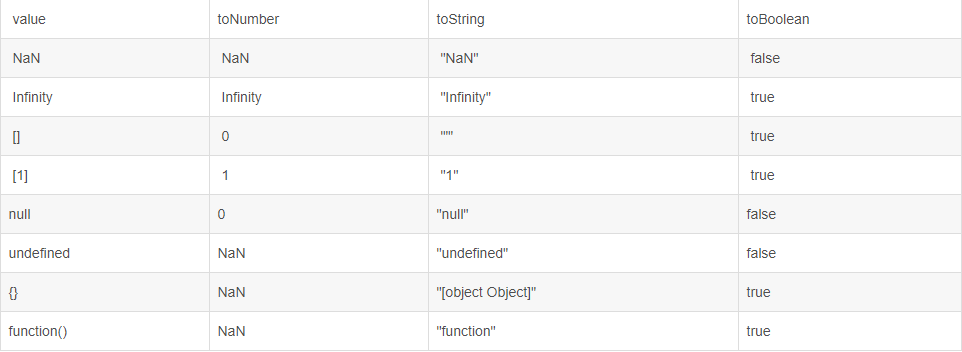
[].valueOf()== 0
↓
[].toString()== 0
↓
Number("") == 0
↓
""==0
80.点击一个input依次触发的事件?
const text = document.getElementById('text');
text.onclick = function (e) {
console.log('onclick')
}
text.onfocus = function (e) {
console.log('onfocus')
}
text.onmousedown = function (e) {
console.log('onmousedown')
}
text.onmouseenter = function (e) {
console.log('onmouseenter')
}
答案:
'onmouseenter'
'onmousedown'
'onfocus'
'onclick'
81.什么是微前端?
微前端(Micro-Frontends)是一种类似于微服务的架构,它将微服务的理念应用于浏览器端,即将 Web 应用由单一的单体应用转变为多个小型前端应用聚合为一的应用。各个前端应用还可以独立运行、独立开发、独立部署。微前端不是单纯的前端框架或者工具,而是一套架构体系
为什么会有微前端
任何新技术的产生都是为了解决现有场景和需求下的技术痛点,微前端也不例外:
拆分和细化:
当下前端领域,单页面应用(SPA)是非常流行的项目形态之一,而随着时间的推移以及应用功能的丰富,单页应用变得不再单一而是越来越庞大也越来越难以维护,往往是改一处而动全身,由此带来的发版成本也越来越高。微前端的意义就是将这些庞大应用进行拆分,并随之解耦,每个部分可以单独进行维护和部署,提升效率。
整合历史系统:
在不少的业务中,或多或少会存在一些历史项目,这些项目大多以采用老框架类似(Backbone.js,Angular.js 1)的B端管理系统为主,介于日常运营,这些系统需要结合到新框架中来使用还不能抛弃,对此我们也没有理由浪费时间和精力重写旧的逻辑。而微前端可以将这些系统进行整合,在基本不修改来逻辑的同时来同时兼容新老两套系统并行运行。
实现微前端有哪些方案
- Mooa:基于Angular的微前端服务框架
- Single-Spa:最早的微前端框架,兼容多种前端技术栈。
- Qiankun:基于Single-Spa,阿里系开源微前端框架。
- Icestark:阿里飞冰微前端框架,兼容多种前端技术栈。
- Ara Framework:由服务端渲染延伸出的微前端框架。
注意事项
1.iconffont 字体在子应用无法加载
原因:
shadow dom 是不支持@font-face 的,所以当引入 iconfont 的时候,尽管可以引入样式,但由于字体文件是不存在的,所以相对应的图标也无法展示。
方案:
- 把字体文件放在主应用加载
- 使用通用的字体文件
2.dom的查询方法找不到指定的元素
原因:
shadow dom 内的元素是被隔离的元素,故 document下查询的方法例如,querySelector、getElementsById 等是获取不到 shadow dom 内元素的。
方案:
代理 document 下各个查询元素的方法,使用子应用传入的容器,即外面的 shadow dom一层查询。具体使用可以参考乾坤的这个方法 initGlobalState。
3.组件库动态创建的元素无法使用自己的样式
原因:
有些对话框或提示窗是通过document.body.appendChild添加的,所以 shadow dom 内引入的 CSS 是无法作用到外面元素的。
方案:
代理document.body.appendChild方法,即把新加的元素添加到 shadow dom容器下,而不是最外面的 body节点下。
补充:
类似的问题都可以往这个方向靠,看是不是shadow dom节点或者dom方法的问题。
4.第三方引入的 JS 不生效
原因:
有些 JS 文件本身是个立即执行函数,或者会动态的创建 scipt 标签,但是所有获取资源的请求是被乾坤劫持处理,所以都不会正常执行,也不会在 window 下面挂载相应的变量,自然在取值调用的时候也不存在这个变量。
方案:
参考乾坤的 issue,子应用向body添加script标签失败
5.webpack-dev-server 代理访问的接口 cookie 丢失
原因:
在主应用的端口下请求子应用的端口,存在跨域,axios 默认情况下跨域是不携带 cookie 的,假如把 axios 的 withCredential设置为 true(表示跨域携带 cookie),那么子应用需要设置跨域访问头Access-Control-Allow-Origin(在 devServer 下配置 header)为指定的域名,但不能设置为*,这时候同时存在主应用和子应用端口发出的请求,而跨域访问头只能设置一个地址,就导致无法代理指定服务器接口。
方案:
子应用接口请求的端口使用主应用接口请求的端口,使用主应用的配置代理请求
// 主应用
devServer: {
...
port: 9600
proxy: {
// 代理配置
}
}
// 子应用
devServer: {
...
port: 9600, // 使用主应用的页面访问端口
}
82.两个请求并行发送,如果其中一个请求出错,就用默认值代替,怎么实现?
// 方法1(类似这种)
import awaitTo from "await-to-js";
const p1=new Promise(()=>{});
const p2=new Promise(()=>{});
const [errors,results]=awaitTo(Promise.all([p1,p2]));
// 如果出错给errors赋默认值就可以了
// 方法2(类似这种)+ ajax-hook 最完美
const apiDefaultValues={
"/getLit":1
}
const httpGet=(options)=>{
return new Promise((resolve, reject) => {
axios.get().then(res => {
if (res) {
resolve(1);
} else {
reject(2);
}
})
.catch(error => {
resolve(apiDefaultValues[options.url])
});
})
}
83.页面有两个相同的请求怎么复用?
Vuex+localStorage
84.跨域通信有哪些?
- postMessage
- document.domain
- WebSocket
- JSONP
- window.name
- location.hash
- http-proxy
85.什么是懒加载?
懒加载是一种在页面加载时延迟加载一些非关键资源的技术,换句话说就是按需加载。
- 图片懒加载:scroll 滚动懒加载
- 元素懒加载IntersectionObserver()
- 路由懒加载:import()
86.commonjs 和 es module区别?
- commonJs是被加载的时候运行,esModule是编译的时候运行
- commonJs输出的是值的浅拷贝,esModule输出值的引用
- commentJs具有缓存。在第一次被加载时,会完整运行整个文件并输出一个对象,拷贝(浅拷贝)在内存中。下次加载文件时,直接从内存中取值
87.tree sharking原理?
原理
利用ES6模块的特点:
- 只能作为模块顶层的语句出现
- import的模块名只能是字符串常量,不能动态引入模块
- import binding 是immutable的,引入的模块不能再进行修改
虽然tree shaking的概念在1990就提出了,但直到ES6的ES6-style模块出现后才真正被利用起来。这是因为treeshaking只能在静态modules下工作。ECMAScript6模块加载是静态的,因此整个依赖树可以被静态地推导出解析语法树。所以在ES6中使用tree shaking是非常容易的。而且, tree shaking不仅支持import/export级别,而且也支持statement(声明)级别。
在ES6以前,我们可以使用CommonJS引入模块:require(),这种引入是动态的,也意味着我们可以基于条件来导入需要的代码:
let dynamicModule;
// 动态导入
if(condition) {
myDynamicModule = require("foo");
} else {
myDynamicModule = require("bar");
}
CommonJS的动态特性模块意味着tree shaking不适用。因为它是不可能确定哪些模块实际运行之前是需要的或者是不需要的。在ES6中,进入了完全静态的导入语法:import。这也意味着下面的导入是不可行的:
// 不可行,ES6 的import是完全静态的
if(condition) {
myDynamicModule = require("foo");
} else {
myDynamicModule = require("bar");
}
只能通过导入所有的包后再进行条件获取
import foo from "foo";
import bar from "bar";
if(condition) {
// foo.xxxx
} else {
// bar.xxx
}
ES6的import语法完美可以使用tree shaking,因为可以在代码不运行的情况下就能分析出不需要的代码。
如何使用
从webpack 2开始支持实现了Tree shaking特性,webpack 2正式版本内置支持ES2015模块(也叫做harmony模块)和未引用模块检测能力。新的webpack 4正式版本,扩展了这个检测能力,通过package.json的sideEffects属性作为标记,向compiler提供提示,表明项目中的哪些文件是“pure(纯的 ES2015模块)”,由此可以安全地删除文件中未使用的部分。
如果使用的是webpack4,只需要将mode设置为production即可开启tree shaking
entry: './src/index.js',
mode: 'production', // 设置为production模式
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'bundle.js'
}
如果是使用webpack2,可能你会发现tree shaking不起作用。因为babel会将代码编译成CommonJs模块,而treeshaking不支持CommonJs。所以需要配置不转义:
options: {
presets: [ [
'es2015', {
modules: false
}
] ]
}
关于side effects(副作用)
side effects是指那些当import的时候会执行一些动作,但是不一定会有任何export。比如ployfill,ployfills不对外暴露方法给主程序使用。
tree shaking不能自动的识别哪些代码属于side effects ,因此手动指定这些代码显得非常重要,如果不指定可能会出现一些意想不到的问题。
在webapck中,是通过package.json的sideEffects属性来实现的。
{
"name": "tree-shaking",
"sideEffects": false
}
如果所有代码都不包含副作用,我们就可以简单地将该属性标记为false,来告知webpack,它可以安全地删除未用到的export导出。
如果你的代码确实有一些副作用,那么可以改为提供一个数组:
{
"name": "tree-shaking",
"sideEffects": [
"./src/common/polyfill.js"
]
}
总结
tree shaking不支持动态导入(如CommonJS的require()语法),只支持纯静态的导入(ES6的import/export)
webpack中可以在项目package.json文件中,添加一个“sideEffects”属性,手动指定由副作用的脚本
88.loader 会 plugins区别?
两者都是为了扩展webpack的功能。
loader它只专注于转化文件(transform)这一个领域,完成压缩,打包,语言翻译;
而plugin不仅只局限在打包,资源的加载上,还可以打包优化和压缩,重新定义环境变量等
loader运行在打包文件之前(loader为在模块加载时的预处理文件);plugins在整个编译周期都起作用
一个loader的职责是单一的,只需要完成一种转换。
一个loader其实就是一个Node.js模块。当需要调用多个loader去转换一个文件时,每个loader会链式的顺序执行
在webpack运行的生命周期中会广播出许多事件,plugin会监听这些事件,在合适的时机通过webpack提供的API改变输出结果
89.防抖和节流的区别及实现方式?
概念
- 防抖(debounce):
触发高频事件后n秒内函数只会执行一次,如果n秒内高频事件再次被触发,则重新计算时间。 - 节流(throttle):
高频事件触发,但在n秒内只会执行一次,所以节流会稀释函数的执行频率。 - 目的:
节流(throttle)与 防抖(debounce)都是为了限制函数的执行频次,以优化函数触发频率过高导致的响应速度跟不上触发频率,出现延迟,假死或卡顿的现象。
使用场景
- window对象的resize、scroll事件
- 拖拽时的mousemove事件
- 文字输入、自动完成的keyup事件
- 射击游戏中的mousedown、keydown事件
- 实际上对于window的resize事件,实际需求大多为停止改变大小n毫秒后执行后续处理;而其他事件大多的需求是以一定的频率执行后续处理。
实现
防抖(debounce)
实现方式:
每次触发事件时设置一个延迟调用方法,并且取消之前的延时调用方法
缺点:
如果事件在规定的时间间隔内被不断的触发,则调用方法会被不断的延迟
//防抖debounce代码:
function debounce(fn,delay) {
var timeout = null; // 创建一个标记用来存放定时器的返回值
return function (e) {
// 每当用户输入的时候把前一个 setTimeout clear 掉
clearTimeout(timeout);
// 然后又创建一个新的 setTimeout, 这样就能保证interval 间隔内如果时间持续触发,就不会执行 fn 函数
timeout = setTimeout(() => {
fn.apply(this, arguments);
}, delay);
};
}
// 处理函数
function handle() {
console.log('防抖:', Math.random());
}
//滚动事件
window.addEventListener('scroll', debounce(handle,500));
节流(throttle)
实现方式:每次触发事件时,如果当前有等待执行的延时函数,则直接return
//节流throttle代码:
function throttle(fn,delay) {
let canRun = true; // 通过闭包保存一个标记
return function () {
// 在函数开头判断标记是否为true,不为true则return
if (!canRun) return;
// 立即设置为false
canRun = false;
// 将外部传入的函数的执行放在setTimeout中
setTimeout(() => {
// 最后在setTimeout执行完毕后再把标记设置为true(关键)表示可以执行下一次循环了。
// 当定时器没有执行的时候标记永远是false,在开头被return掉
fn.apply(this, arguments);
canRun = true;
}, delay);
};
}
function sayHi(e) {
console.log('节流:', e.target.innerWidth, e.target.innerHeight);
}
window.addEventListener('resize', throttle(sayHi,500));
区别:
函数节流不管事件触发有多频繁,都会保证在规定时间内一定会执行一次真正的事件处理函数,而函数防抖只是在最后一次事件后才触发一次函数。
比如在页面的无限加载场景下,我们需要用户在滚动页面时,每隔一段时间发一次 Ajax 请求,而不是在用户停下滚动页面操作时才去请求数据。
这样的场景,就适合用节流技术来实现。
90.了解哪些新技术?
- Vue3
- TypeScript
- Webgl
- VR
- AR
- Ai
- python
91.控制台会报错么如果报错是什么类型的错误?
if(a == 1) {
console.log(a);
}
a is not defined
92.以下代码
var a=?;
if(a==1&&a==2&&a==3){
console.log('小样儿!');
}
问:当a等于什么的时候,if条件成立,并打印?
答案
var a={
num:1,
toString:function(){
return a.num++;
}
}
if(a==1&&a==2&&a==3){
console.log("恭喜答对啦!");
}else{
console.log("还是错了小子!");
}
原理:
a1&&a2&&a3,这是一个短路逻辑与运算符,表示左边条件为真时才会继续往右判断,否则立即整个判断像短路一样,所以 a 的第一个值必须是 a1 为真才会继续向右判断 a2,由此可以推断出 a 的值或者说是转换类型后的值是可以自增长的,JavaScript中当遇到不同类型的值进行比较时,会根据类型转换规则试图将它们转为同一个类型再比较。比如 Object 类型与 Number 类型进行比较时,Object 类型会转换为 Number 类型。转换为时会尝试调用 Object.valueOf 和 Object.toString 来获取对应的数字基本类型。
在上面代码中,逻辑转换先调用了valueOf方法,如果返回的还是对象,再接着调用toString()方法。每次比较都会先执行重写后的对象方法toString(),这个方法里先返回属性num的值再自增。执行a1判断时,对象a调用toString()方法返回了属性num的值1,此时比较两个当然是相等的。与此类似,a2和a3一样成立。怎么样是不是很巧妙?
93.说说原型和原型链?
原型:
把所有的对象共用的属性全部放在堆内存的一个对象中(共用属性组成的对象),然后让每一个对象的
__proto__存储这个(共用属性组成的对象)的地址。而这个共用属性就是原型。原型出现的目的就是
为了减少不必要的内存消耗。
原型链:
而原型链就是对象通过__proto__向当前实例所属类的原型上查找属性或方法的机制,如果找到Object
的原型上还是没有找到想要的属性或者是方法则查找结束,最终会返回undefined,终点是null。
















 838
838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











