







刚刚学数据挖掘,在看数据预处理时,看到熵是最常用于确定划分点的度量。最开始理解以为熵就是作为一个分类的依据,维基后发现熵最开始于物理的热力学,是指能量的均匀。熵越大越均匀,后发展用于信息,统计学。那么熵怎么用于分类决策树划分呢?首先有公式如下:
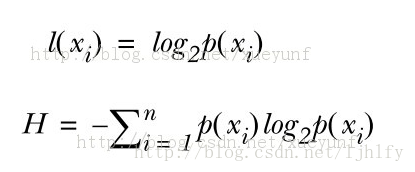
下面是计算信息熵的方法,以及测试代码:
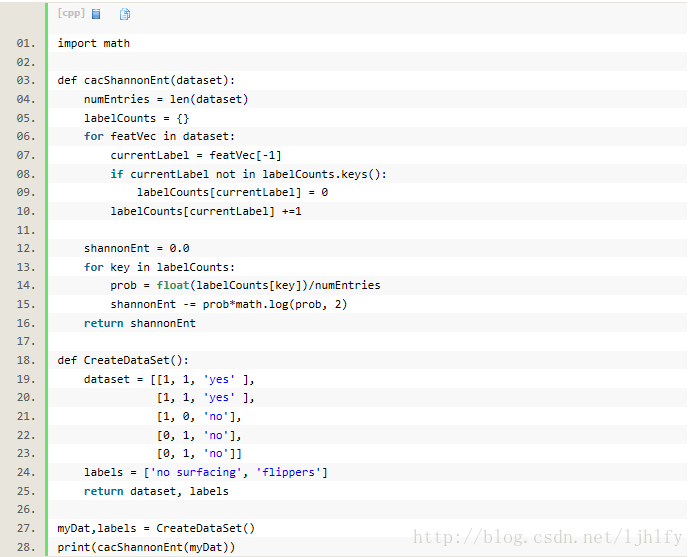
第一个函数试计算信息熵,第二个函数创建数据
刚刚学数据挖掘,在看数据预处理时,看到熵是最常用于确定划分点的度量。最开始理解以为熵就是作为一个分类的依据,维基后发现熵最开始于物理的热力学,是指能量的均匀。熵越大越均匀,后发展用于信息,统计学。那么熵怎么用于分类决策树划分呢?首先有公式如下:
下面是计算信息熵的方法,以及测试代码:
第一个函数试计算信息熵,第二个函数创建数据

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



















 4699
4699





