






糗事百科爬虫用户统计
以前爬了糗事百科,一些数据还是挺有意思的:
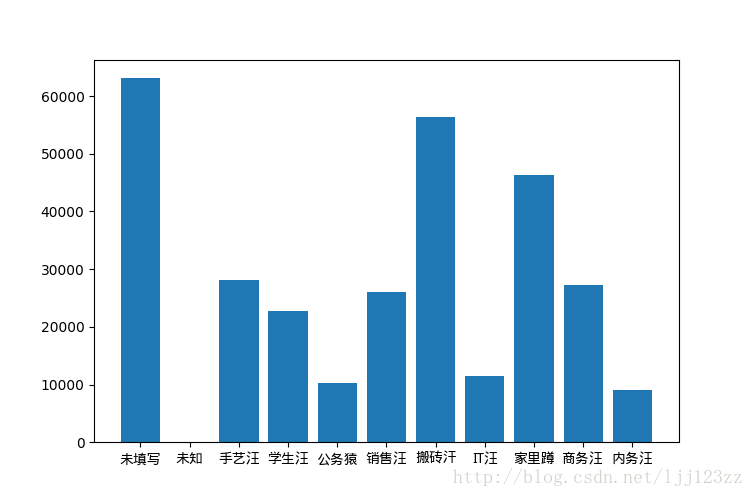
- 工作
搬砖汉应该是调侃自己的,不过人数比较多的手艺汪,学生汪,家里蹲应该有一些共同点,那就是时间比较自由 - 故乡
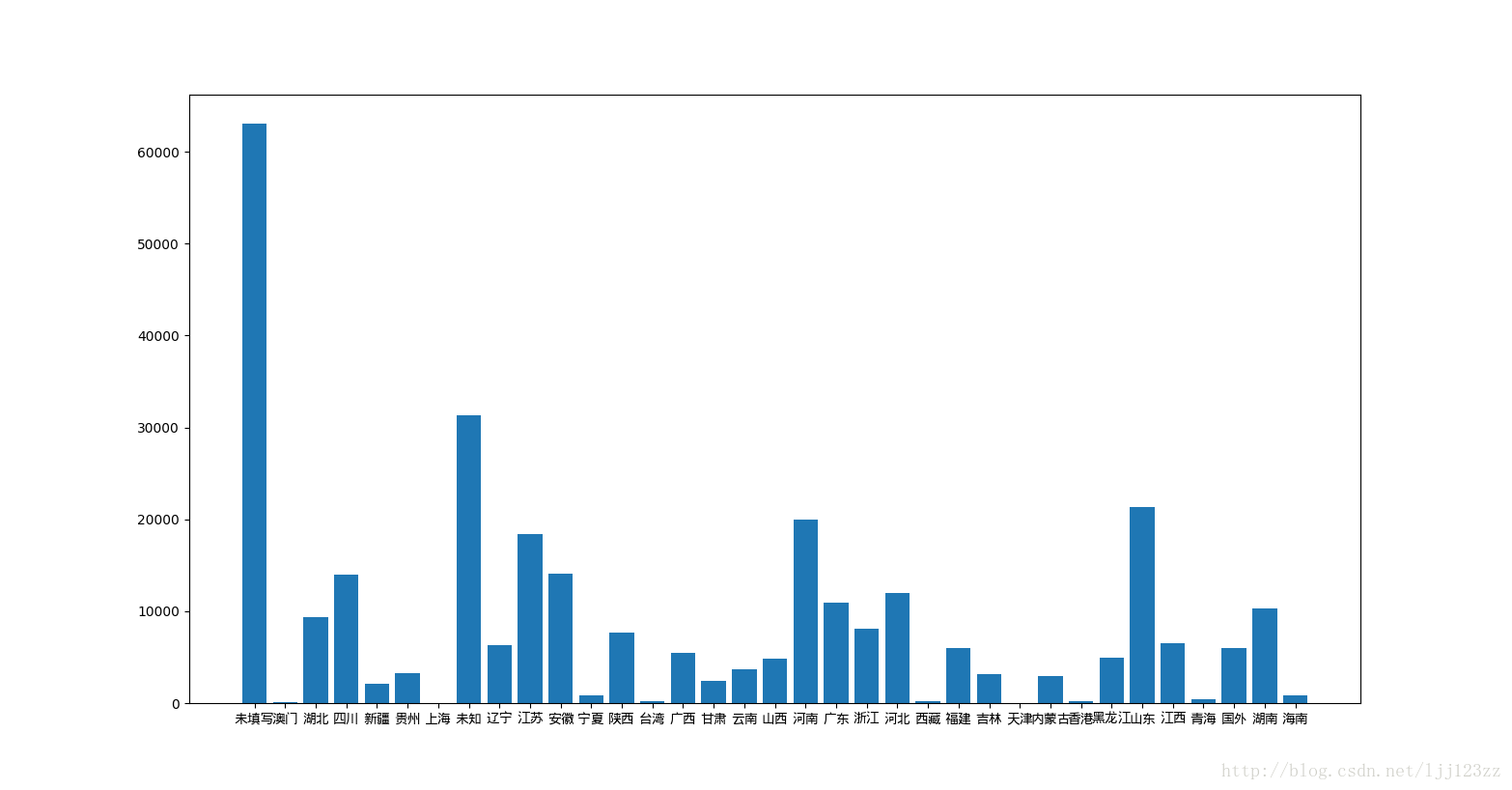
基本上人口基数大的地方用户也多,比如河南、山东、四川等 - 婚姻状况
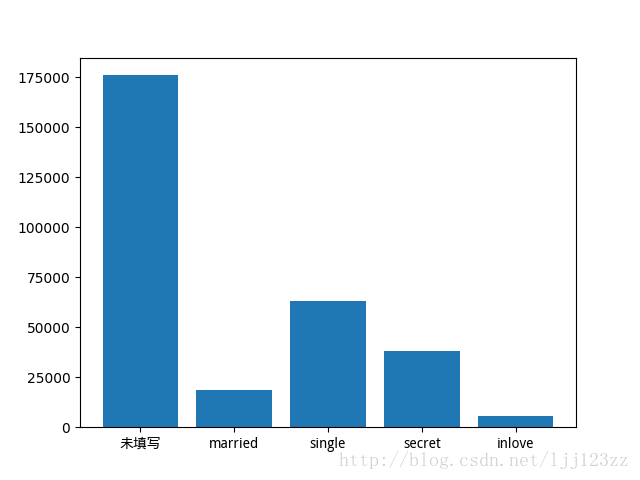
估计单身狗会比较多☺ - 星座
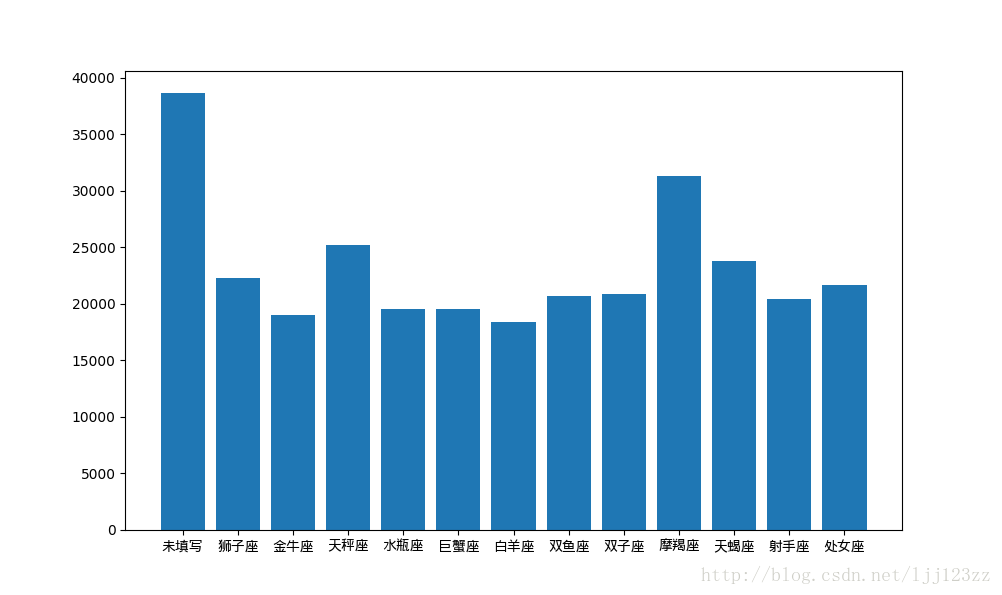
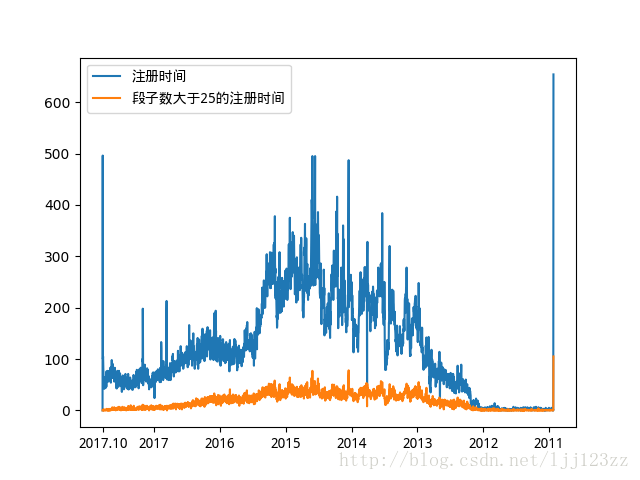
- 注册时间
很多用户都是在04、05年左右注册的,看来那时候风头挺火,现在似乎不如以前了 - 一堆时间自由的单身狗在这上面看笑话
下面是程序:
# -*- coding: utf-8 -*-
import pymongo as mo
import jieba
import re
import matplotlib.pyplot as plt
import matplotlib as mpl
import os
zhfont = mpl.font_manager.FontProperties(fname='wqy-microhei.ttc')
# 从列表中删除停用词
def del_stopwords(indata):
filename = 'stopwords.txt' # 读取停用词词典
f = open(filename, 'r+')
file_list = f.read()
f.close()
stopwords = tuple(file_list.split('\n'))
outlwords = []
for d in indata:
if d[0] not in stopwords:
outlwords.append(d)
return outlwords
# 结巴分词并保存
def fenci():
filename = 'qs.txt'
f = open(filename, 'r+')
file_list = f.read()
f.close()
seg_list = jieba.cut(file_list, cut_all=True)
tf = {}
for seg in seg_list:
# print seg
seg = ''.join(seg.split())
if (seg != '' and seg != "\n" and seg != "\n\n"):
if seg in tf:
tf[seg] += 1
else:
tf[seg] = 1
bb = sorted(tf.items(), key=lambda item: item[1], reverse=True)
outdata = del_stopwords(bb)
f = open("result.txt", "w+")
for item in outdata:
# print item
f.write(item + " " + str(tf[item]) + "\n")
f.close()
# 批量删除字典中的key,输入分别为字典和需要删除key的集合
def deldic(indic, delset):
for i in delset:
try:
del indic[i]
except:
pass
# 定义函数,检测输入的数据是否在字典中,如果在就在字典数值位加1,如果不在就在字典中新建key
def coun_dic(newkey, indic={}):
try:
indic[newkey] = indic[newkey] + 1
except:
indic[newkey] = 1
return indic
def coun_list(indata, datalist):
# print(indata)
lengthdata = len(datalist)
if indata < 0:
indata = 0
elif indata > lengthdata - 1:
indata = lengthdata - 1
datalist[indata][1] = datalist[indata][1] + 1
return datalist
# 字典转化为列表,顺序不管
def dic2list(indic):
aa = list(indic.keys())
bb = []
for a in aa:
bb.append(indic[a])
return aa, bb
def plotdic(indic):
a, b = dic2list(indic)
a[a.index('')] = '未填写'
plt.bar(left=(range(len(indic))), height=(b))
plt.xticks(range(len(indic)), a, fontproperties=zhfont)
plt.show()
def gendata(db, people_att):
work_type = {} # 工作
gender = {} # 性别
constellation = {} # 星座
marriage = {}
hometown = {}
peopname = {}
# 统计所有人在线时间
totaltime_count = [[x, 0] for x in range(2500)]
# 统计段子数大于10的在线时间
totaltime_count1 = [[x, 0] for x in range(2500)]
# 所有人段子量统计
qiushi_count = [[x, 0] for x in range(3000)]
kk = 1
joke = set()
# kmeandata = []
for d in db.find():
try:
totaltime_count = coun_list(int(re.sub("\D", "", d['total_time'])), totaltime_count)
if len(d) > 25:
totaltime_count1 = coun_list(int(re.sub("\D", "", d['total_time'])), totaltime_count1)
# print(len(d))
peopname = coun_dic(d['name'], peopname)
qiushi_count = coun_list(len(d) - 15, qiushi_count)
work_type = coun_dic(d['job'], work_type)
constellation = coun_dic(d['horoscope'], constellation)
marriage = coun_dic(d['marri'], marriage)
if d['hometown'] == '':
hometown = coun_dic('', hometown)
elif d['hometown'] == '未知':
hometown = coun_dic('未知', hometown)
elif len(d['hometown'].split(' · ')) == 1:
hometown = coun_dic(d['hometown'], hometown)
else:
hometown = coun_dic(d['hometown'].split(' · ')[0], hometown)
# 保存笑话
deldic(d, people_att)
for i in d:
if len(d[i]['body']) > 10:
joke.add(d[i]['body'])
# kmeandata.append(
# [int(re.sub("\D", "", d['total_time'])), int(d['comment_num']), int(d['face_num']), int(d['qiushi_num'])])
except Exception as e:
print(str(e))
print(d)
aa = d
os._exit()
kk = kk + 1
peopatt = {'work_type': work_type, 'marriage': marriage, 'constellation': constellation, 'hometown': hometown,
'totaltime_count': totaltime_count, 'totaltime_count1': totaltime_count1, 'peopname': peopname}
return joke, peopatt
if __name__ == '__main__':
people_att = {'_id', 'name', 'pic', 'funs_num', 'atten_num', 'qiushi_num',
'comment_num', 'face_num', 'choice_num', 'marri',
'horoscope', 'job', 'hometown', 'total_time', 'face_num', 'flag'}
client = mo.MongoClient('localhost', 27017)
databases_name = 'qsbk2'
tablename = 'qsbk2'
db = client[databases_name][tablename]
joke, peopatt = gendata(db, people_att)
# 出图工作
plotdic(peopatt['work_type'])
# 出图婚姻
plotdic(peopatt['marriage'])
# 出图星座
plotdic(peopatt['constellation'])
# 出图家乡
plotdic(peopatt['hometown'])
# 在线时间
plt.plot([x[1] for x in peopatt['totaltime_count']], label=u'注册时间', )
xtic = [x * 365 + 285 for x in range(7)] # 截止10月初
xtic.insert(0, 1)
plt.xticks(xtic, ['2017.10', 2017, 2016, 2015, 2014, 2013, 2012, 2011], fontproperties=zhfont)
plt.plot([x[1] for x in peopatt['totaltime_count1']], label=u'段子数大于25的注册时间')
xtic = [x * 365 + 285 for x in range(7)] # 截止10月初
xtic.insert(0, 1)
plt.xticks(xtic, ['2017.10', 2017, 2016, 2015, 2014, 2013, 2012, 2011])
plt.legend(prop=zhfont)
plt.show()
print('总共段子个数', len(joke))
client.close()
print('finish')














 249
249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









