






PfAAM是最近刚提出的一种无参注意力机制,结合通道注意力和空间注意力,一起学习一下
论文地址:https://arxiv.org/abs/2210.07828
代码地址:https://github.com/nkoerb/pfaam
原理
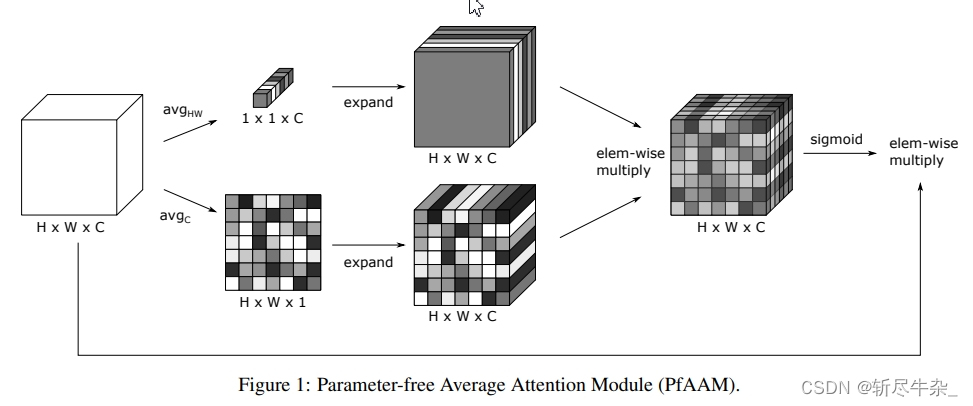
原理很简单,就是将原特征图分两次进行平均池化,一种相当于通道注意力,另一种是空间注意力。然后将它们拉伸成原特征图的大小,最后,两特征图相乘并作用于原特征图
代码
官方给的github上的pytorch源码运行有一点问题,我稍微修改了一下,亲测可以运行
class PfAAMLayer(nn.Module):
def __init__(self, c1, c2, ratio=16):
super(PfAAMLayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c, 1, 1).expand_as(x)
z = torch.mean(x, dim=1, keepdim=True).expand_as(x)
return x * self.sigmoid(y*z)
在YOLOv5中的使用
首先,将上面的代码添加到common.py文件中
其次,在yolo.py中注册PfAAMlayer类,具体做法是在perse_model函数中加入PfAAMlayer,如下图
最后,在网络结构中添加注意力层,下面是一种改进方法,我把注意力机制放在最后一层
(PS:注意力机制作为一种即插即用的模块,理论上可以放在任何位置,要注意层数和通道数)
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1,1, PfAAMLayer,[1024]], #<<<---注意力机制
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









