







背景:
在将一个文件从excel另存为txt的时候,以UTF-8的方式进行保存为a.txt。在C++中通过getline的方式逐行读取发现第一行的数据出现读取错误的情况。
分析:
将该文件另存为UTF-8的无BOM格式,再读取的时候,则可以正常读取。
在UCS 编码(即 Unicode编码)中有一个叫做”ZERO WIDTH NO-BREAK SPACE”的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输 字符”ZERO WIDTH NO-BREAK SPACE”。这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little- Endian的。因此字符”ZERO WIDTH NO-BREAK SPACE”又被称作BOM。UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符”ZERO WIDTH NO-BREAK SPACE”的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
UTF- 8编码的文件中,BOM占三个字节。如果用记事本把一个文本文件另存为UTF-8编码方式的话,用UE打开这个文件,切换到十六进制编辑状态就可以看到开 头的FFFE了,如下图所示。这是个标识UTF-8编码文件的好办法,软件通过BOM来识别这个文件是否是UTF-8编码,很多软件还要求读入的文件必须带BOM。可 是,还是有很多软件不能识别BOM。
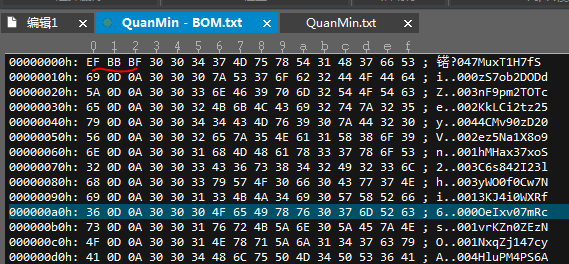
从上图可以看出EF BB BF开头的字符,该行的字符出现显示编码异常。而采用UTF-8无BOM存储方式如下,可以看出,第一行的数据正常显示。
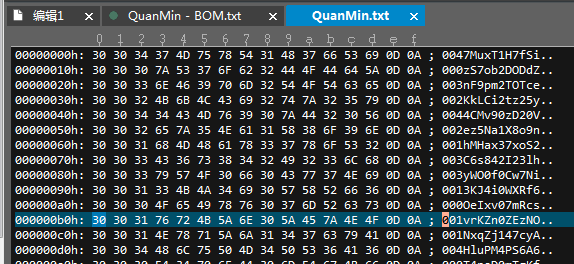
带有BOM的正常读取方案
最简单的方法就是直接另存为无BOM的UTF-8格式。如果是带有BOM的UTF-8,则先要去除其BOM头。
判断是否存在BOM:
bool HasBom(const char* decKrc, uint32_t decKrcLen)
{
if (decKrcLen >= 3
&& (unsigned char)decKrc[0] == 0xef
&& (unsigned char)decKrc[1] == 0xbb
&& (unsigned char)decKrc[2] == 0xbf)
{
return true;
}
return false;
}正式代码:
ifstream Inputread("a.txt");
string str;
while(getline(Inputread,str))
{
bool hasBom1 = HasBom(str.c_str(), str.size());
if (hasBom1)
str= str.substr(3);
//对该行内容的处理操作
}即可实现该行数据的正常读取。在去掉BOM之后,保留的文本如下:
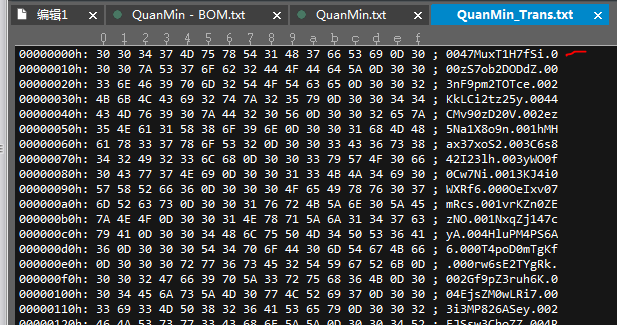


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









