







背景
对日志获取记录数据的文本进行分析
后,就反馈信息。
使用例子
1:分析文本文件中某一个中的值域和对应出现的次数。
文本结构:
列1 列2
key1 N
key2 Y
key3 Y1
代码:
cat mark_2016-08-08.log |awk '{a[$2]++}END{for(i in a){print i,a[i] | "sort -k 1"}}'输出结果:

2:指定某个列,统计该列出现某个关键字的次数
代码:
cat mark_2016-08-07.log |awk '{if($2 =="Y") sum+=1} END {print "Sum = ", sum}'结果如下:

该结果和上述结果,是一致的。
3:排序
按照升序获取降序的方式,统计某个关键字出现次数。
测试数据如下,第一列表示关键字(此处的关键字不存在重复),第二列表示value,即该key出现的次数。
| k1 1 k2 2 k3 1 k4 3 k4 4 k5 5 k6 3 k7 6 k8 3 |
代码:
cat mytest.log | awk '{a[$2]++}END{for(i in a){print i,a[i]} }'运行结果:
| 4 1 5 1 6 1 1 2 2 1 3 3 |
该结果的第一列表示测试数据中的value(测试数据的第二列),第二列表示该value值出现的次数,即是对value值进行一次出现次数的统计。
按照value值出现次数进行升序或者降序排序:
这里sort的参数k2表示对第二列结果进行操作,-r表示降序。
代码:
cat mytest.log | awk '{a[$2]++}END{for(i in a){print i,a[i] | "sort -r -k2"} }'运行结果如下,从中可以看出,value=3的记录,出现了3次,value=1的记录,出现了2次:
| 3 3 1 2 6 1 5 1 4 1 2 1 |
按照value值进行升序获取降序排序:
代码:
cat mytest.log | awk '{a[$2]++}END{for(i in a){print i,a[i] | "sort -r -k1"} }'运行结果如下:
| 6 1 5 1 4 1 3 3 2 1 1 2 |
4:求某一列最大值和该列的数据
用linecontent来存储最大值所在行的内容,max存储最大值,linecout存储的是该文件所有的行数,linenum存储的是该最大值所在的行数。
awk 'BEGIN {max=0;linecout=0} {linecout++;if($2>max) {max=$2;linecontent=$0;linenum=linecout} fi} END {print "linecontent=",linecontent;print "linecout=",linecout;print "linenum=",linenum}' hashbyscid1.txt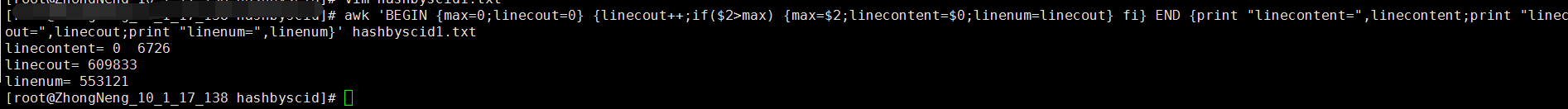
5:当key出现重复,而需要进行进行统计
未完,待续
6:对数据按照列方向进行条件筛选:
筛选出第2列或者第3列出现0的行信息
cat krc_lrc_upload_status.txt |awk '$2==0 || $3==0{print $0}'















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









