







背景:
需要根据给定的关键字对给定的一序列的文本文件进行查找。
方案设计:
ES+python
采用ES建立全文的文本搜索,根据给定的查找关键字直接进行查找
ES服务搭建
下载elasticsearch
直接解压,运行bin目录下的./bin/elasticsearch -d 在后端中启动该服务。
如果提示是java版本不是最新,需要更新。
Elasticsearch requires at least Java 8 but your Java version from /usr/bin/java does not meet this requirement
更新java版本:
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get install oracle-java8-installer安装完之后java版本:

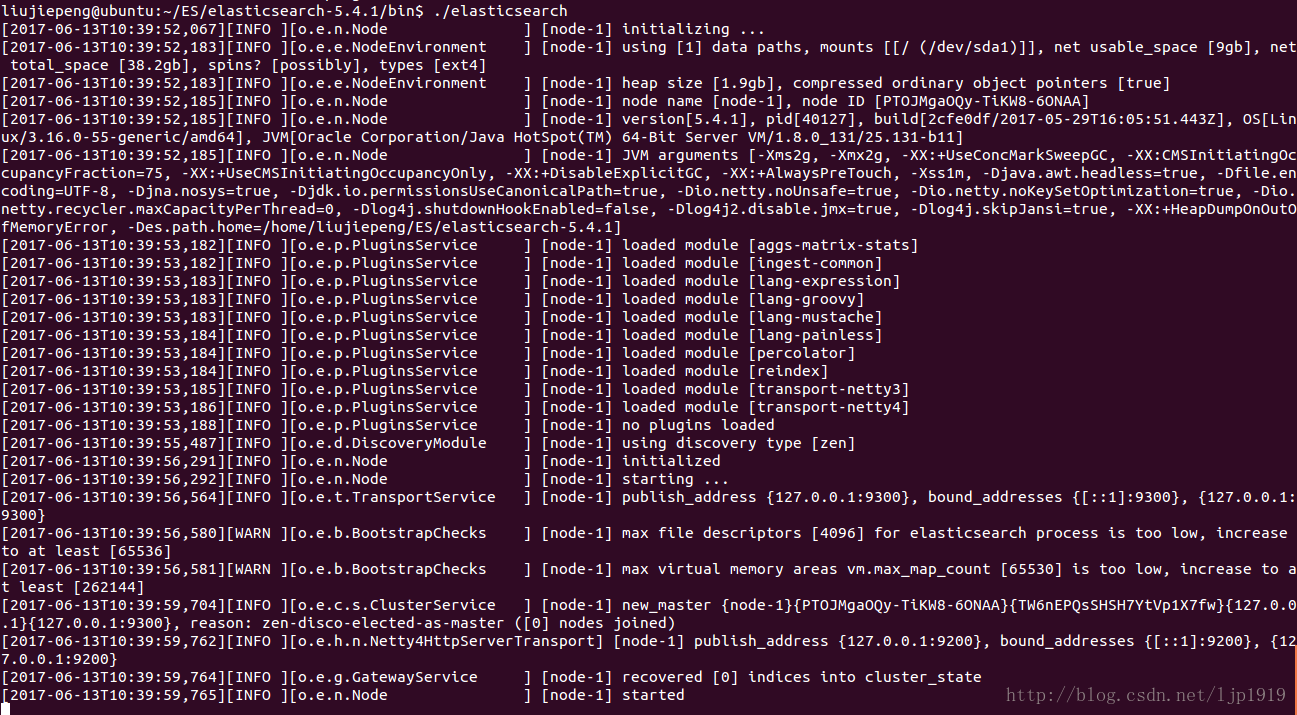
直接在bin目录下用./elasticsearch启动
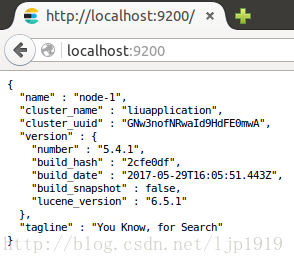
9200端口的访问结果:

基本概念:
index:
es里的index相当于一个数据库。
作为动词,它指的是把一个文档“保存”到 ES 中的过程,索引一个文档后,我们就可以使用 ES 搜索到这个文档
作为名词,它是指保存文档的地方,相当于一个数据库概念中的“库”。
type:
相当于数据库里的一个表。
id: 唯一,相当于主键,是用于标识文档的,一个文档的索引 / 类型 /id 必须是唯一的。文档 id 是自动生成的(如果不指定)
document 文档:
一个文档就是一个保存在 es 中的 JSON 文本,可以把它理解为关系型数据库表中的一行。每个文档都是保存在索引中的,拥有一种类型和 id。一个文档是一个 JSON 对象(一些语言中的 hash / hashmap / associative array)包含了 0 或多个字段(键值对)。原始的 JSON 文本在索引后将被保存在 _source 字段里,搜索完成后返回值中默认是包含该字段的。
node:
节点是es实例,一台机器可以运行多个实例,但是同一台机器上的实例在配置文件中要确保http和tcp端口不同。
cluster:
代表一个集群,集群中有多个节点,其中有一个会被选为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。
shards:
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上,构成分布式搜索。它保存索引时会选择适合的“主分片”(Primary Shard),把索引保存到其中(我们可以把分片理解为一块物理存储区域)。分片的分法是固定的,而且是安装时候就必须要决定好的(默认是 5),索引创建后不能更改。
既然有主分片,那肯定是有“从”分片的,在 ES 里称之为“副本分片”(Replica Shard),es可以设置多个索引的副本。副本分片主要有两个作用:
1) 高可用:某分片节点挂了的话可走其他副本分片节点,节点恢复后上面的分片数据可通过其他节点恢复,提高系统的容错性
2) 负载均衡:ES 会自动根据负载情况控制搜索路由,副本分片可以将负载均摊
基于python&ES的全文索引建立
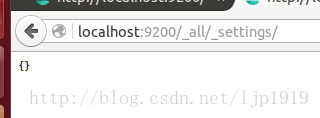
对于刚启动的ES服务,可以先查询所有索引的配置信息,由于此时没有索引信息,所以是空的:
调用ES接口的方式建立索引:
# -*- coding: utf-8 -*-
__author__ = 'jasonliu'
import datetime
import urllib2
import json
import time
import httplib
import socket
id = "7"
url = "http://获取数据的ip或者域名:8071/getext?nohead=1&id=" + str(id)
try:
s = urllib2.urlopen(url, timeout = 10).read().replace("\r\n", " ")
if len(s) > 0 :
d = json.dumps({"krcid" : id, "content" : s})
url = "http://127.0.0.1:9200/lyrics/fulltext/" + str(id) + "/_create"#创建一个文档,如果该文件已经存在,则返回失败
urllib2.urlopen(url, d, timeout = 10)
print("add success :" + str(id))
except socket.timeout, e:
print("timeout : " + str(id))
raise e
except:
print("add error : " + str(id))上述代码即实现了往index=lyrics,type=fulltext,id=krcid,document是包含歌词信息的一个json文本。全文的文本无法是在外层添加一个循环而已。
可以通下述方式来简单查找该id:
http://127.0.0.1:9200/lyrics/fulltext/7
查询结果:

关键字查询
对于指定的关键字(全文查找)的全文查找:
# -*- coding: utf-8 -*-
__author__ = 'jasonliu'
import datetime
import urllib2
import json
import time
import httplib
import socket
id = "7"
try:
url = "http://127.0.0.1:9200/lyrics/fulltext/_search?"#创建一个文档,如果该文件已经存在,则返回失败
queryParams = "pretty&size=1000"
url = url + queryParams
QUERY_TEMPLATE = "{\"_source\": [\"krcid\"],\"query\" : { \"match\" : { \"content\" : \
{\"query\" : \"我爱ES\", \"type\" : \"phrase\",\"slop\" : 20}}},\"highlight\" : {\"pre_tags\" : [\"<kw>\"],\"post_tags\" : [\"</kw>\"],\"fields\" : {\"content\" : {}}}}"
#修改其中的keyword
tempjason = json.loads(QUERY_TEMPLATE)
tempjason["query"]["match"]["content"]["query"] = "天空的雾来的漫不经心"
data = json.dumps(tempjason)
print 'data=', data
cnx = urllib2.urlopen(url, data, timeout=60)
tempcnx = cnx.read()
print tempcnx
# kg_song_info = json.loads(tempcnx)
# print("add success :" + str(id))
except socket.timeout, e:
print("timeout : " + str(id))
raise e
except:
print("add error : " + str(id))
至此,可以简单实现文本的索引建立和使用的功能。















 1301
1301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









