










0.背景
机构:Facebook
作者:Guillaume Lample、 Alexis Conneau
发布地方:arxiv
面向任务:Language Understanding
论文地址:https://arxiv.org/abs/1901.07291
论文代码:https://github.com/facebookresearch/XLM
0-1 摘要
最近的研究已经证明了生成预训练对于英语自然语言理解的有效性。在本文的工作中,我们将这种方法扩展到多种语言并展示跨语言预训练的有效性。本文提出了两种学习跨语言语言模型(XLM)的方法:一种是无监督方式,只依赖于单语言数据;另一种是监督,在平行语料数据上利用一个新的跨语言语言模型目标函数。我们获得了关于跨语言分类(cross-lingual classification),无监督机器翻译和监督机器翻译的最优结果。在XNLI数据集上,本文的方法将准确性的最优性能指标提升了4.9个百分点。在无监督机器翻译任务上,本文方法在WMT’16German-English数据集上的BLEU=34.3,比此前的最优值高出9个BLEU。在监督机器翻译任务中,本文方法在WMT’16 Romanian-English数据集上的BLEU=38.5,比此前最优结果高出4个BLEU。
1.介绍
句子编码器的生成式预训练(Generative pretraining)已经使许多自然语言理解的 benchmark 取得了显著的进步。在此背景下,Transformer 语言模型在大型无监督文本语料库上学习后,再针对具体的自然语言理解 (NLU) 任务进行微调,如分类或自然语言推理。尽管目前研究人员对学习通用句子表示的兴趣激增,但该领域的研究基本上都是集中在英语 Benchmark上。学习和评估多语言的跨语言句子表示的最新进展,旨在减轻以英语为中心的偏见,并提出可以构建通用的跨语言编码器,将任何句子编码到共享嵌入空间中。在本文的工作中,证明了跨语言模型预训练在多个跨语言理解(XLU)benchmark 上的有效性。具体来说,本文工作有以下贡献:
-
提出了一种新的无监督方法。使用跨语言语言建模来学习跨语言表示,并研究了两种单语预训练的目标函数。
-
提出一个新的监督学习目标。当有平行语料时,该目标可以改进跨语言的预训练。
-
本文的模型在跨语言分类、无监督机器翻译和有监督机器翻译方面都显著优于以往的最优结果。
-
本文实验表明跨语言模型对于low-resource 语种数据集,也能够显著改善其他语种的困惑度(perplexity)。
2. 相关工作
略
3. 跨语言模型
本文提出3个语言模型目标函数,其中2个仅仅需要单语种数据集(无监督方式),另一个需要平行语料(有监督方式)。假设有个 N N N个语种,对应的语料记为 { C i } i = 1 … N \left\{C_{i}\right\}_{i=1 \ldots N} {Ci}i=1…N, n i n_{i} ni表示 C i C_{i} Ci中的句子数量。
3-1. 共享sub-word字典
在本文的所有实验中,所有语种共用一个字典,该字典是通过Byte Pair Encoding (BPE)构建的。共享的内容包括相同的字母、符号token如数字符号、专有名词。这种共享字典能够显著的提升不同语种在嵌入空间的对齐效果。本文在单语料库中从随机多项式分布中采样句子进行BPE学习。为了保证平衡语料,句子的采样服从多项式分布:
q
i
=
p
i
α
∑
j
=
1
N
p
j
α
with
p
i
=
n
i
∑
k
=
1
N
n
k
q_{i}=\frac{p_{i}^{\alpha}}{\sum_{j=1}^{N} p_{j}^{\alpha}} \quad \text { with } \quad p_{i}=\frac{n_{i}}{\sum_{k=1}^{N} n_{k}}
qi=∑j=1Npjαpiα with pi=∑k=1Nnkni
其中
α
=
0.5
\alpha=0.5
α=0.5。使用这种分布抽样,可以增加分配给low-resource 语种的token数量,并减轻对high-resource 语种的偏见。这可以防止low-resource 语种数据集的单词在字符级被分割。
3-2. 因果语言模型(CLM)
使用Transformer在给定前序词语的情况下预测下一个词的概率。
本文的因果语言建模 (CLM) 任务其实是一个Transformer语言模型,该模型被训练来对给定句子预测后一个单词的概率, P ( w t ∣ w 1 , … , w t − 1 , θ ) P\left(w_{t} | w_{1}, \ldots, w_{t-1}, \theta\right) P(wt∣w1,…,wt−1,θ)。虽然 CNN 在语言建模基准(benchmarks)测试中是性能最好的, 但Transformer 模型也很有竞争力。
在 LSTM 语言模型的情况下,通过向 LSTM 提供上一个迭代的最后隐藏状态来执行时间反向传播 (backpropagation through time, BPTT)。对于 Transformer,可以将之前的隐藏状态传递给当前的batch,为当前batch中的第一个单词提供上下文信息。但是,这种技术不能扩展到跨语言,因此为了简单起见,我们只保留每个 batch 中的第一个单词,而不考虑上下文。
3-3. 掩模语言模型(MLM)
本文也采用Devlin et al. (2018) 论文中提出的掩模语言模型(MLM),也称为完形填空任务。与Devlin等人一样,我们从文本流中随机抽取 15% 的 BPE token,使用的时候,80%的时间用 [MASK] token 替换,10%时间的用随机 token 替换,10%时候保持不变。与其不同的是,本文使用由任意数量的句子(每个句子截断为256个token)组成的文本流代替成对的句子。为了均衡稀有tokens和高频tokens(比如标点符号和停止词),本文采用类似于Mikolov et al. (2013b)的方法对高频词汇进行二次采样:文本流中的tokens都是以多项式分布进行采样的,其权重与它们的逆文本频率的平方根成正比。本文的MLM目标如图1所示:
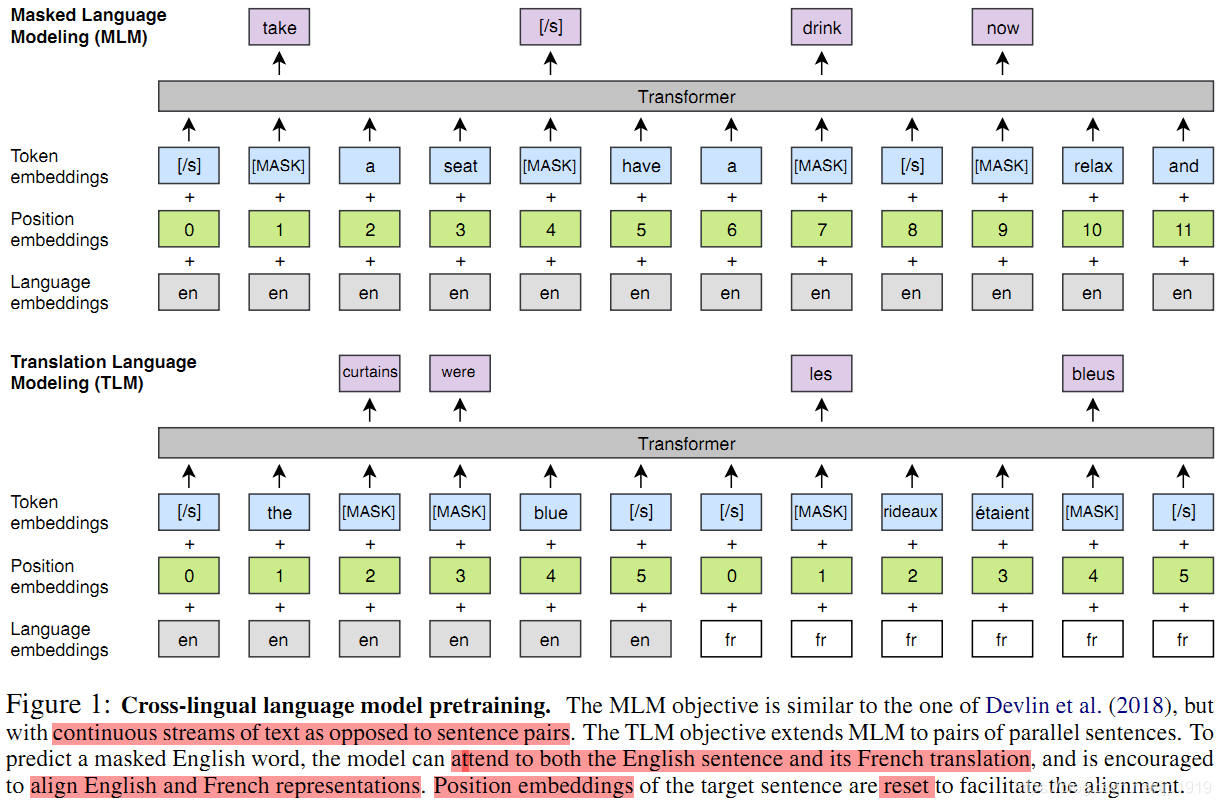
图 1: 跨语言模型预训练。 MLM 目标类似于 Devlin et al. (2018) 里的,但不是句子对,是连续的文本流。TLM 目标将 MLM 扩展到并行的句子对。为了预测一个被遮挡的英语单词,该模型可以同时考虑英语句子及其法语翻译,并鼓励将英语和法语表进行示对齐。目标句子的位置嵌入被重置以方便对齐。
3-4. 翻译语言模型(TLM)
CLM 和 MLM都是无监督的,只需要单语数据。但是,当存在平行语料数据时,上述两者都无法使用。为此本文提出一种新的翻译语言建模方法 (TLM) 来提高跨语言训练的效果。TLM的目标是MLM的扩展,TLM不考虑单语种的文本流, 而是将并行的翻译句子拼接起来,如图 1 所示。之后,在source 句子和 target 句子中都随机mask掉words。当要预测英文句子中被masked的word时,该模型不仅能够注意到英文words还能够注意到法语的翻译内容。这就引导模型将英语和法语的表征进行对齐。特别地,该模型在英文句子不足以推断出被masked的英文单词时,能够利用法语上下文信息。为了方便对齐,在target句子部分,位置编码需要重置。
3-5. 跨语言模型
本文的跨语言预训练模型由于 CLM、MLM,或MLM与TLM结合的模型组成。对于CLM和MLM的目标,本文训练模型过程使用的每个batch由64个句子流组成,每个句子流由256 个 token 组成。每次的迭代,一个batch来自同一个语种中的句子,句子则是按照此前介绍的多项式分布采样得到 { q i } i = 1 … N \left\{q_{i}\right\}_{i=1 \ldots N} {qi}i=1…N,其中 α = 0.7 \alpha=0.7 α=0.7。当TLM联合MLM使用时,需要在这两个目标之间交替,并使用类似的方法对翻译对进行采样。
4. 跨语言模型的预训练
本章节主要介绍如何训练得到跨语言模型:
-
得到一个能够处理zero-shot跨语言分类任务的初始化更好的句子编码器
-
初始化更好的有监督和无监督的神经机器翻译系统
-
低资源(low-resource)语言的语言模型
-
无监督的跨语言词汇嵌入
4-1. 跨语言分类器
本文预训练的XLM模型提供通用的跨语言文本表示。在英文文本分类任务上,本文的XLM与单语种语言模型下的微调类似,在一个跨语言分类benchmark上进行微调。本文这里使用cross-lingual natural language inference (XNLI)数据集。准确地讲,本文在预训练的Transformer的第一个隐藏状态之上加入一个线性分类器,再在英文NLI训练集上进行微调所有参数。之后,在15个XNIL 语种数据集上评估模型。此外,本文还在训练集和测试集上以机器翻译任务做了性能对比。具体结果在Table 1中。
4-2. 无监督机器翻译
预训练是无监督神经机器翻译的重要部分,Lample et al.(2018b)的研究表明用于初始化查找表的预训练跨语言单词嵌入, 对无监督机器翻译模型的性能有重要影响。本文进一步提出用跨语言模型对整个encoder和decoder进行预训练,以提升无监督神经机器翻译的性能。本文探索了多种不同的初始化策略,并评估了各种策略在标准机器翻译任务(包括WMT’14 English-French,
WMT’16 English-German and WMT’16 English-Romanian)中的表现。详细结果请见Table 2。
4-3. 有监督机器翻译
本文同时研究跨语言预训练对于有监督机器翻译的影响。并将Ramachandran et al. (2016)的方法进一步拓展到多语种神经机器翻译中。本文在WMT’16 Romanian-English中评估了CLM和MLM预训练的影响, 其结果见于Table 3。
4-4. low-resource语言建模
对于资源较少的语言,可以使用数据较相似的资源较多的语言进行预训练,特别是它们的词汇表很大部分相同时。比如,在维基上有100k个尼泊尔语的句子,其数量是印地语的6倍。这两种语言在共享的BPE字典(100k subword单元)中有80%tokens是相同的。Table 4展示了尼泊尔语语言模型和在尼泊尔语上训练的跨语言模型在perplexity上对比。这个跨语言模型还用不同的印地语和英文的组合数据进行了数据扩充。
4-5. 无监督跨语言词嵌入
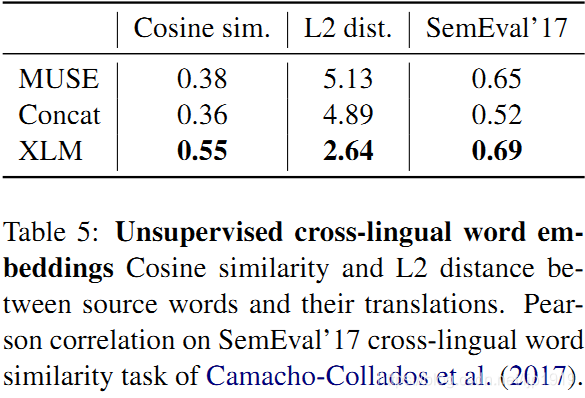
Conneau et al. (2018a) 介绍过如何通过对抗训练(MUSE)对齐单语种词嵌入空间,来实施无监督的单词翻译。Lample et al. (2018a)则采用2个语种的共享字典,再将单语种语料进行拼接后输入到fastText,也能够提供高质量的跨语言词嵌入(Concat),同时共享一份字母表。本文的词嵌入是通过提出的XLM模型获得,从余弦相似度、L2距离和跨语言词语相似度几个维度评估嵌入质量,在SemEval’17 cross-lingual word similarity task进行评估测试。
5. 实验和结果
本章节从几个benchmarks的实验证明跨语言模型的预训练的有效性,且效果显著。
5-1. 训练细节
这部分具体看原文就好了。
5-2. 数据预处理
采用WikiExtractor来从Wikipedia dumps中抽取原始句子,并将其作为CLM和MLM的单语种数据集。至于TLM,只使用涉及到英文的平行语料,与Conneau et al. (2018b)类似。准确地说,本文对于French, Spanish, Russian, Arabic and Chinese采用的是MultilUN数据集,至于印度语则采用IIT Bombay corpus。在获取low resource语料上则是通过OPUS website Tiedemann (2012)抽取到的,其中包括EUbookshop corpus for German, Greek and Bulgarian, OpenSubtitles 2018 for Turkish, Vietnamese and Thai, Tanzil for both Urdu and Swahili and GlobalVoices for Swahili。对于中文、日语和泰语,则分别采用Chang et al. (2008)分词器、Kytea分词器和PyThaiNLP分词器。其他语种的分词器则统一采用Moses (Koehn et al., 2007)的分词器,如有必要时采用默认的英语tokenizer。BPE的学习是借助于fastBPE。
5-3. 结果与分析
主要从跨语言分类、无监督机器翻译和有监督机器翻译来证明文本方法的有效性。
跨语言分类任务:
Table 1中展示了2类预训练的跨语言encoders:
(1)在单语种语料上采用MLM作为目标的无监督跨语言预训练
(2)在平行语料上联合使用MLM和TLM作为目标的有监督跨语言模型
同时本文这里介绍2个机器翻译的baseline:
(1)TRANSLATE-TRAIN:其中English MultiNLI作为训练集,它被翻译到每一个XNLI语言。
(2)TRANSLATE-TEST:其中XNLI的每个dev set和 test set都被翻译为英语。
![[外链图片转存失败(img-5waCj6ww-1563876074615)(leanote://file/getImage?fileId=5d312463c4664c50f1000002)]](https://img-blog.csdnimg.cn/20190723180504839.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2xqcDE5MTk=,size_16,color_FFFFFF,t_70)
表 1:跨语言分类准确率的结果。测试了 15 种 XNLI 语言的准确性。报告了机器翻译 baselines 和 基于跨语言句子编码器 的 zero-shot 分类方法的结果。XLM (MLM) 对应于只在单语语料库上训练的无监督方法,XLM (MLM+TLM) 对应于通过 TLM 目标利用单语和双语平行语料数据的监督方法。其中
Δ
\Delta
Δ表示平均准确率。
本文的无监督MLM方法刷新了zero-shot 跨语言分类的记录,且明显超出此前Artetxe and Schwenk (2018)的监督方法,该方法使用了223 million的平行语料。准确地讲,MLM的平均准确率为71.5%,而Artetxe and Schwenk (2018)的监督方法的平均准确率为70.2%。
在使用平行语料的TLM(即MLM+TLM)中,也取得了3.6%的准确率提升,并以75.1%的准确率刷新了记录,在Swahili 和 Urdu low-resource languages上,分别高出此前最优6.2%和6.3%的准确率。在MLM中使用TLM也能够将英语的准确率从83.2%提升到85%。这在准确率上分别高出Artetxe and Schwenk (2018) 和 Devlin et al. (2018)的方法11.1%和3.6%。
在每个XNLI语种的训练集(TRANSLATE-TRAIN)上进行微调,本文的监督模型在准确率上超出本文的zero-shot方法(即上述的zero-shot cross-lingual classification)1.6个百分点,平均准确率达到76.7%。本文的方法在TRANSLATE-TRAIN上平均准确率为76.7%,在TRANSLATE-TEST上的平均准确率为74.2%,显然TRANSLATE-TRAIN高出TRANSLATE-TEST2.5%的平均准确率。此外,本文的zero-shot方法的准确率为75.1%,高出TRANSLATE-TEST的平均准确率(74.2%)0.9个百分点。
无监督机器翻译:
对于无监督机器翻译任务,本文考虑以下3个语种的翻译:English-French, English-German和English-Romanian。本文的设置与Lample et al. (2018b)相同,唯一不同的是初始化步骤,本文使用跨语言语言模型来预训练完整的模型,而不是只训练查找表。
对于encoder和decoder,采用不同的初始化:CLM预训练,MLM预训练,或者随机初始化。这一共有9种组合方式。本文采用Lample et al. (2018b) 中的方法采用降噪自编码DAE损失和在线回译损失训练模型。对比结果见于Table 2,对比了本文方法和Lample et al. (2018b)的方法,可以看出每个语种翻译对上,本文的方法都能够显著优于先前的最优结果。使用Lample et al.(2018b)的NMT方法 (EMB),发现结果指标比其初始论文还高,归其原因是实验过程采用的多GPU可以使用更大的batch。
在German-English中,本文的方法高出先前最优无监督方法9.1个BLEU;如果仅考虑神经网络无监督方法,则本文方法是高出神经无监督方法13.3个BLEU。对比仅仅预训练查找表lookup table的EMB方法,本文在encoder和decoder上都采用MLM的预训练方式在German-English上提升了7个BLEU。另外,我们还观察到MLM作为目标的预训练结果总是优于以CLM作为目标,在English-French上,前者为30.4(见于Table 2中的倒数第5行),后者可以达到33.4(见于Table 2中的倒数第1行);在Romanian-English上,前者为28.0(但是我看,好像是27.8??),后者为31.8。这些结果与Devlin et al. (2018)的结论一致,在NLU任务上,MLM作为目标的预训练要优于CLM。此外,本文还发现encoder是预训练中最重要的部分:对比在encoder和decoder上的预训练,仅仅在decoder上预训练在性能指标会降低,但是仅仅在encoder上预训练在最后的BLEU得分上几乎没有影响。
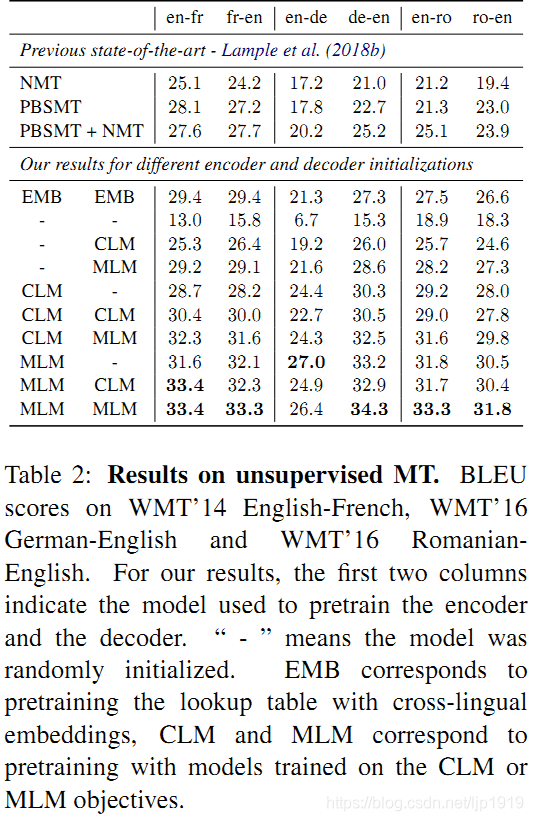
表 2:WMT’14 英语 - 法语, WMT’16 德语 - 英语 以及 WMT’16 罗马尼亚语 - 英语的无监督机器翻译 BLEU 分数结果。前两列表示用于预训练编码器和解码器的模型。“-” 表示模型被随机初始化,CLM 和 MLM 对应于针对 CLM 或 MLM 目标的模型的预训练。
有监督机器翻译:
在Table 3中展示了不同监督训练配置在Romanian-English WMT’16 上的结果,包括单向(ro->en), 双向(ro<->en,即基于en->ro和ro->en 训练一个multi-NMT model) 和 带回译的双向(ro<->en + BT)。带回译模型是用相同的单语种数据进行预训练的。带有回译的模型在语料数量上虽然能够与预训练模型中使用的单语种语料一样,但是无法在dev set上获得良好的泛化性能。本文带有回译的双向模型可以获取最佳的性能指标:38.5BLEU,超出此前Sen
nrich et al. (2016) 最优的结果4个BLEU。Sennrich et al. (2016) 的模型是基于回译和集成学习模型的。
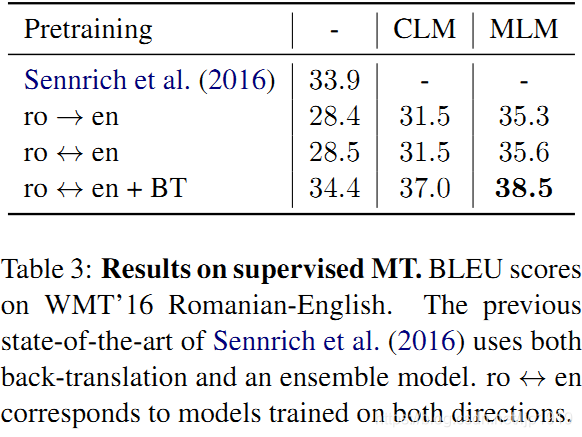
表 3:WMT’16 罗马尼亚语 - 英语的有监督机器翻译 BLEU 评分结果。Sennrich et al.(2016)是此前最先进的技术,使用了反向翻译和集成模型。roen 对应于模型训练的两个方向。
low-resource 语言建模:
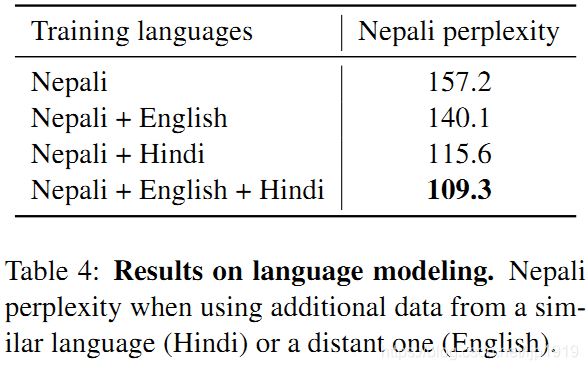
在Table 4,研究跨语言模型在提升low-resource的Nepali语言模型的影响(主要的性能指标是perplexity)。为此,本文基于Wikipedia训练了一个Nepali语言模型,额外的数量来自于English 或者 Hindi。同时Nepali 和 English 是相去较远的语言,而Nepali 和 Hindi是近似的语种(二者共享梵文字母且源于同一梵文祖先)。当采用英语语种时,Nepali的语言模型perplexity下降了17.1个点(Nepali-only的语言模型其perplexity是157.2,基于English的Nepali语言模型其perplexity是140.1)。如果在Nepali语料基础上再使用额外的Hindi语料,则perplexity可以从157.2下降到115.6,即下降41.6个点。最后,在Nepali语料基础上同时联合使用英语和Hindi语料,则Nepali语言模型的perplexity可以下降到109.3。跨语言模型带来的perplexity的下降,可以部分归结于跨语言的n-grams锚点(n-grams anchor points that are shared across languages),比如Wikipedia文章。跨语言模型因此能够利用Hindi或者英文语料所提供的额外上下文信息,进而提升Nepali的语言模型。
无监督跨语言词嵌入:
MUSE、Concat和XLM(MLM)方法都提供了无监督跨语言的词嵌入空间。在Table 5中,研究了上述3种方法采用同一个词典,计算MUSE字典中word 翻译对的余弦相似度、L2距离结果。同时也用SemEval’17跨语言的词相似度任务评估余弦相似度结果。从中,可以看出XLM在跨语言词相似度上同时超出MUSE和Concat,其皮尔逊相关系数达到0.69。有趣的是,在XLM跨语言词嵌入空间中,词的翻译对也比MUSE或Concat 要近得多。特别地,MUSE的余弦相似度和L2距离分别是0.38、5.13,而XLM对应的结果则是0.55和2.64。这意味着XLM的词嵌入已经通过一个能够强制拉近的sentence encoder特别训练过,而MUSE和Concat只是基于fastText的词嵌入。
6. 总结
本文首次验证了跨语言模型(XLM)的预训练所带来的巨大收益。研究了2个仅需要单语种语料的无监督目标:CLM和MLM,并证实了二者都能够提供用于预训练的有效跨语言特征。同时本文也证明了跨语种语言模型能够用以提升low-resource的Nepali语言模型,此外也提供了无监跨语言词嵌入。在无需使用任何的平行句子语料,跨语言模型在XNLI的跨语言分类任务上,平均准确率能够超出此前最优的有监督模型1.3个百分点。本文的核心贡献在于TLM目标的提出,该目标使用了平行语料提升了跨语言模型的预训练。TLM天然地扩展了BERT的MLM方法,使用平行语料的batches而不是连续的句子。在MLM上使用TLM能够进一步提升结果指标。该有监督方法以高出平均准确率4.9%的优势刷新了此前XNLI的记录。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









