







1. 范畴的概念
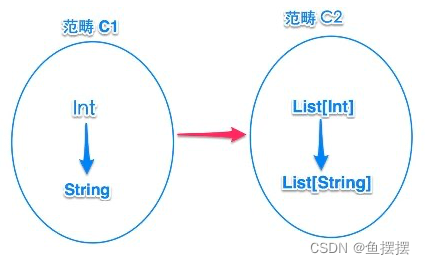
范畴:可以简单理解为高阶类型,如List[T+],即范畴是一组类型的集合
- 范畴C1里面有类型String和类型Int,范畴C2里面有类型List[String]和List[Int]
- 对于范畴C2,它的所有类型都是List[T]的特定类型,这个范畴可以抽象为List高阶类型
- 对于范畴C1,它的抽象类型可以看做是一个identity类型构造器,它与任何参数类型(case class)构造出的类型就是参数类型:type Id[T] = T
2. 函子Functor
1) 与函数的区别:
- 函数function表达的映射关系在类型上体现在特定类型(proper type)之间的映射
- 函子functor是高阶类型(范畴)之间的映射
2) 代码实现:
//函数function,Int => String
def foo(i: Int): String = i.toString
// 函子functor,List[T] => Set[T]
def baz[T](l: List[T]):Set[T] = l.toSet
3. 自函子Endofunctor
3.1 与自函数的区别
- 自函数是把一个类型映射到自身类型的函数,如:
Int => Int, String => String等- 自函子是把一个范畴映射到自身范畴的函子,如:
(List[T]=>Set[T]) => List[T] =>Set[T],- 测试一下:
type test[T] = (List[T]=>Set[T]) => List[T] =>Set[T]
3.2 flatMap就是一个自函子
// 观察Monad[T+]中的flatMap定义
def flatMap[U](f: (T) => Monad[U]): Monad[U]
// Monad[T+]中的flatMap,是将Monad[T+]范畴映射到Monad[U]
// 根据trait定义Monad[T+],Monad[U]即Monad[T+],因此flatMap是一个自函子
4. 可应用函子Applicative
4.1 Applicative函子的实现,借助之前的Functor
// 使用map2和unit实现一个Applicative函子
trait Applicative[F[_]] extends Functor[F]{
// 原始操作
def map2[A,B,C](fa: F[A], fb:F[B])(f: (A,B) => C): F[C]
def unit[A](a: => A): F[A]
// 衍生操作
def map[B](fa: F[A])(f: A => B): F[B] = map2(fa, unit(()))((a, _) => f(a)) // ()是类型Unit的唯一值,unit(())是使用()调用unit,等同于unit()
def traverse[A,B](as: List[A])(f: A => F[B]): F[List[B]]: F[List[B]] = as.foldRight(unit(List[B]()))((a, fbs) => map2(f(a), fbs)(_ :: _))
}
- 所有的Applicative都是函子functor
- 这里用map2和unit实现了map
- map2完成了值的加工,但是不改变类型
- unit完成了值的封装
- map根据map2和unit实现,在对值进行封装后,对值进行了处理,保持数据结构不变
使用apply和unit实现一个Applicative函子如下所示:
// 使用apply和unit实现一个Applicative函子
trait Applicative[F[_]] extends Functor[F]{
// 原始操作
def apply[A,B](fab: F[A => B])(fa: F[A]): F[B]
def unit[A](a: => A): F[A]
// 衍生操作
def map[A,B](fa: F[A])(f: A => B): F[B] = apply(unit(f))(fa)
def map2[A,B,C](fa: F[A], fb:F[B])(f: (A,B) => C): F[A] = apply(uni(f))(f(apply(unit(f)(fa), apply(unit(f)(fb)))))
}
4.2 让Monad成为Applicative的子类型,这样所有的monad都是可应用函子
// 使用flatMap实现map2,这样可以使用Applicative可应用函子实现Monad,而无需使用类型组合的方式为monad提供Applicative实例
trait Monad[F[_]] extends Applicative[F]{
def flatMap[A,B](fa: F[A])(f: A => B): F[B] = join(map(fa)(f))
def join[A](ffa: F[F[A]]): F[A] = flatMap(ffa)(fa => fa)
def compose[A,B,C](f: A => F[B], g: B => F[C]): A => F[C] = a => flatMap(f(a))(g)
def map[B](fa: F[A])(f: A => B): F[B] = flatMap(fa)((a: A) => unit(f(a)))
def map2[A,B,C](fa: F[A], fb: F[B])(f: (A,B) => C): F[C] = flatMap(fa)(a => map(fb)(b => f(a,b)))
}
5. 单子Monad和可应用函子Applicative的区别
5.1 Monad可以定义为不同的最小操作集合
- unit和flatMap:unit对值进行封装,flatMap对多个封装的值进行解包->计算->封装
- unit和compose
- unit、map和join
5.2 Applicative可以定义为不同的最小操作集合
unit和map2
5.3 Monad和Applicative最小操作的区别:
- Monad中的flatMapA,B(f: A => F[B]):F[B]相当于对F打开封装,应用一个函数,返回一个封装的值;
Applicative的unit是增加一层F,map2是F中应用一个函数,无法对输入的F[A]打开封装- Monad中的joinA:F[A]相当于去掉了一层F;
Applicative中的unit是增加一层F,map2是F中应用一个函数,无法完成Monad的join操作
5.4 对比Option applicative和Option Monad
- Applicative的map2可以使用Option组合两个独立的结果
val F: Applicative[Option] = ...
val depts: Map[String, String] = ...
val salaries: Map[String, Double] = ...
val o: Option[String] = F.map2(depts.get("Alice"), salaries.get("Alice"))((dept, salary) => s"Alice in ${dept} makes ${salary} per year")
// depts和salaries的查找相互独立,Option中组合了两个查找的结果
- Monad的flatMap结合前一个查询的结果,进一步查询
val idsByName: Map[String, Int]
val depts: Map[Int, String] = ...
val salaries: Map[Int, Double] = ...
val o: Option[String] = idsByName.get("Bob").flatMap(id => F.map2(deps.get(id), salaries.get(id))(dept, salary) => s"Bob in ${dept} makes ${salary} per year")
// 首先根据idsByName获得id,然后进一步使用这个id在depts和salaries中查找
5.5 对比Parser Applicative和Parser Monad
# Date, Temperature
1/1/2010, 25
2/1/2010, 28
3/1/2010, 42
4/1/2010, 53
// 解析文件,假设我们知道文件结构:第一列日期,第二列温度
case class Row(date: Date, temperature: Double)
val F: Applicative[Parser] = ...
val d: Parser[Date] = ...
val temp: Parser[Double] = ...
val row: Parser[Row] = F.map2(d, temp)(Row(_,_))
val rows: Parser[List[Row]] = row.sep("\n")
// Date, Temperature
25, 1/1/2010
28, 2/1/2010
42, 3/1/2010
53, 4/1/2010
// 解析文件,假设我们不知道文件结构,需要flatMap根据header动态解析随后的行
case class Row(date: Date, temperature: Double)
val F: Monad[Parser] = ...
val d: Parser[Date] = ...
val temp: Parser[Double] = ...
val header: Parser[Parser[Row]] = ...
val rows: Parser[List[Row]] = F.flatMap(header){row => row.sep("\n")}
- Applicative计算有固定的结构和简单的顺序,而Monad计算可以基于之前的计算结果动态的选择结构
- Applicative构建了上下文自由的计算,而Monad允许上下文敏感的计算
- Monad将类型构造器case class变成一等公民,可以在编译阶段动态生成,而不是程序提前选择。在当前的例子中,Parser[Row]作为解析行为的一部分被生成,被后续的解析程序使用
5.6 可应用函子的优势
- 比Monad相对灵活,解析器可以有更多的信息直到将要做什么,可以自由的做出一些假设和实现取执行之后的代码
- 可应用函子可组合,但是Monad不可以
5.7 不是所有的可应用函子都是Monad
可应用Stream:为Stream定义unit和map2,但不是flatMap
val streamApplicative = new Applicative[Stream]{
// 无限的常量流
def unit[A](a: => A): Stream[A] = Stream.continually(a)
// 逐个组合相应的元素
def map2[A,B,C](a: Stream[A], b: Stream[B])(f: (A,B) => C):Stream[C] = a zip b map f.tupled
}
5.8 可应用法则
5.8.1 左幺元:使用unit时保持fa的结构不变
// map(id)(v) == v
def map[B](fa: F[A])(f: A=>B):F[B] = map2(fa, unit(()))((a,_) => f(a))
map2(unit(()), fa)((_,a) => a) == fa
5.8.2 右幺元:同上
// map(v)(id) == v
def map[B](fa: F[A])(f: A=>B):F[B] = map2(unit(()), fa)((_,a) => f(a))
map2(fa, unit(()))((a,_) => a) == fa
5.8.3 结合律
map(map(v)(g))(f) == map(v)(f compose g)
5.8.4 Naturality of product
val F: Applicative[Option] = ...
case class Employee(name: String, id: Int)
case class Pay(rate: Double, hoursPerYear: Double)
def format(e: Option[Employee], pay: Option[Pay]): Option[String] = F.map2(e, pay){(e, pay) => s"${e.name} makes ${pay.rate * pay.hoursPerYear}"}
val e: Option[Employee] = ...
val pay: Option[Pay] = ...
format(e, pay)
// 重构format,将调用属性的过程放在各自的map方法中完成
val F: Applicative[Option] = ...
val format(name: Option[String], pay: Option[Double]): Option[String] = F.map2(e,pay){(e, pay) => s"$e makes $pay"}
val e: Option[Employee] = ...
val pay: Option[Pay] = ...
format(
F.map(e)(_.name)
F.map(pay)(pay => pay.rate * pay.hoursPerYear)
)
// 重构format,将两个重复的map函数合成一个函数,根据product(map(a)(f), map(b)(g)) == map2(a,b)(productF(f,g))
def productF[I,O,I2,O2](f: I => O, g: I2 => O2):(I,I2) => (O,O2) = (i, i2) => (f(i), g(i2))
6. 可遍历函子
traverse和sequence函数
def traverse[F[_], A, B](as: List[A])(f: A => F[B]): F[List[B]] // as负责提供f中指定的类型A,f负责更改类型,f对as进行处理后返回一个新的类型,这个类型首先应为F[_],其次要求元素必需是List[B],最终返回F[List[B]]
def sequence[F[_], A](fas: List[F[A]]): F[List[A]] // fas是一个List,元素为F[A],根据结合律,有List[F[A]]
举例:对Map实现traverse和sequence函数
trait Traverse[F[_]]{
// traverse接受F[A],进行封装,返回G[F[A]]
def traverse[G[_]:Applicative, A, B](fa: F[A])(f: A => G[B]): G[F[B]] = sequence(map(fa)(f))
// sequence接受G[F[A]],进行重新封装,返回F[G[A]]
def sequence[G[_]:Applicative, A](fga: F[G[A]]): G[F[A]] = traverse(fag)(ga => ga)
}
List[Option[A]] => Option[List[A]]
// 使用Option作为Applicative,当调用Traverse[List].sequence,如果元素是None,则返回None,否则返回Some封装的List列表
Tree[Option[A]] => Option[Tree[A]]
// 使用Option作为Applicative, 当调用Traverse[Tree].sequence,如果元素为None,则返回None,否则返回Some封装的Tree
7. 使用之前例子中的Traverse特质
7.1 traverse方法
之前Traverse使用traverse方法实现了Map,说明Traverse是一个函子的扩展,traverse方法是一个map操作的泛化
7.2 举例:使用traverse方法替代map
trait Traverse[F[_]] extends Functor[F]{
def traverse[G[_], A, B](fa: F[A])(f: A => G[B])(implicit G: Applicative[G]): G[F[B]] = sequence(map(fa)(f))
def sequence[G[_], A](fga: F[G[A]])(implicit G: Applicative[G]):G[F[A]] = traverse(fga)(ga => ga)
// uncheck
def map[A,B](fa: F[A])(f: A => B): F[B] = traverse(fa)(f)
}
7.3 举例:traverse方法替代foldMap、foldLeft、foldRight
// def traverse[G[_]: Applicative, A, B](fa: F[A])(f: A => G[B]): G[F[B]]
// 假如G是一个类型构造器ConseInt,用于将所有类型A转变为Int,这样ConstInt[A]则丢弃类型A变为类型Int
// 这样原有traverse函数签名则改变为:
// def traverse[A,B](fa: F[A])(f: A => Int): Int
type Const[M,B] = M // 值类型B被泛化为任何类型的M,而不仅仅是Int
// 将Monoid转变为Applicative
implicit def monoidApplicative[M](M: Monoid[M]) =
new Applicative[({type f[x] = Const[M, x]})#f]{ // 这里的#是什么意思???
def unit[A](a: => A): M = M.zero
def map2[A, B, C](m1: M, m2: M)(f: (A, B) => C) : M = M.op(m1, m2))
}
trait Traverse[F[_]] extends Functor[F] with Foldable[F]{
def foldMap[A,M](as: F[A])(f: A => M)(mb: Monoid[M]): M = traverse[(type f[x] = Const[M,x])#f, A, Nothing](as)(f)(monoidApplicative(mb))
}
8. 带状态的遍历
State可应用函子:可以对集合实现复杂的遍历,并保持内部状态
9. 组合可遍历结构
Traversal的一个特性是保持它参数的类型
举例:组合两个不同的结构类型
def zip[A,B](fa: F[A], fb: F[B]): F[(A, B)] =
(mapAccum(fa ,toList(fb)){
case(a, Nil) => sys.error("zip: Incompatible shapes")
case(a, b :: bs) => ((a, b), bs)
})._1
举例:另一种组合方式
def zipL[A,B](fa: F[A], fb: F[B]): F[(A, Option[B])] =
(mapAccum(fa, toList(fb)){
case (a, Nil) => ((a,None), Nil)
case (a, b::bs) => ((a, Some(b)), bs)
})._1
def zipR[A,B](fa: F[A], fb:F[B]):F[(Option[A], B)] =
(mapAccum(fb, toList(fa)){
case (b, Nil) => ((None, b), Nil)
case (b, a :: as) => ((Some(a), b), as)
})._1
10. 遍历融合
product可应用函子可以实现两个遍历的融合,有两个函数f和g,只要遍历fa一次,收集两个函数的结果
def fuse[G[_], H[_], A, B](fa: F[A])(f: A => G[B], g: A => H[B])(G: Applicative[G], H: Applicative[H]): (G[F[B]], H[F[B]])
















 1464
1464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











