







转载请注明出处:http://blog.csdn.net/lonelytrooper/article/details/17042391
很早就知道bulk load这个东西,也大致都清楚怎么回事,居然直到前几天才第一次实践... 
这篇文章大致分为三个部分:
1. 使用Hbase自带的importtsv工具
2. 自己实现写mr生成hfile并加载
3. bulk load本身及对依赖的第三方包的一些总结
第一部分:
导入的文件是data.txt,符合tsv格式,如下:

做一些准备工作:
a. 在hdfs上穿件/test目录,并将data.txt传至该目录下
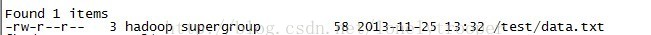
b. 创建hbase表bl_tmp

c. 将依赖的jar加到$HADOOP_HOME/conf/Hadoop-env.sh (每个人的不一定一样,加你需要的)
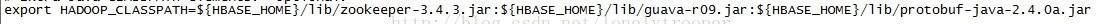
运行hbase自带的imprttsv工具,这里输出路径是output,列的定义由-Dimporttsv.columns指定:
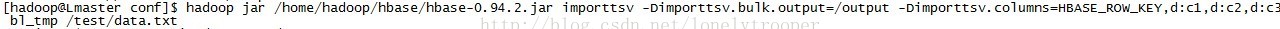
程序正常运行,运行成功后,查看/output目录,output目录下会根据列族名生成一个自录,这里是d,d目录下为具体的hfile文件:

运行completebulkload工具将hfile装载到表bl_tmp中:
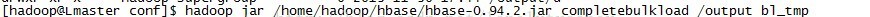
装载完之后,d目录下的hfile不存在了,这时查询bl_tmp表,如下:
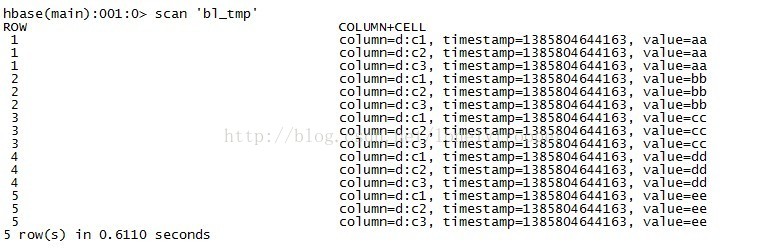
第二部分:
源码直接贴了,简明扼要,没什么好说的... 关键的点详见前边两篇简要介绍相关源码的博文...
- import java.io.IOException;
- import java.util.Date;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.conf.Configured;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.hbase.HBaseConfiguration;
- import org.apache.hadoop.hbase.client.HTable;
- import org.apache.hadoop.hbase.client.Put;
- import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
- import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat;
- import org.apache.hadoop.hbase.mapreduce.PutSortReducer;
- import org.apache.hadoop.hbase.util.Bytes;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- import org.apache.hadoop.util.Tool;
- import org.apache.hadoop.util.ToolRunner;
- public final class HBaseBulkLoadDemo extends Configured implements Tool {
- public static class BulkLoadDemoMapper extends
- Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
- private static final byte[] FAMILY_NAME = "d".getBytes();
- private static final byte[] COLUMN_A = "colA".getBytes();
- private static final byte[] COLUMN_B = "colB".getBytes();
- private static final byte[] COLUMN_C = "colC".getBytes();
- protected void map(LongWritable key, Text value, Context context) throws IOException,
- InterruptedException {
- String line = value.toString();
- String[] fields = line.split("\t");
- byte[] rowkeybytes = Bytes.toBytes(fields[0]);
- ImmutableBytesWritable rowkey = new ImmutableBytesWritable(rowkeybytes);
- Put put = new Put(rowkeybytes);
- put.add(FAMILY_NAME, COLUMN_A, fields[1].getBytes());
- put.add(FAMILY_NAME, COLUMN_B, fields[2].getBytes());
- put.add(FAMILY_NAME, COLUMN_C, fields[3].getBytes());
- context.write(rowkey, put);
- }
- }
- /**
- * @param args
- * @throws Exception
- */
- public static void main(String[] args) throws Exception {
- System.exit(ToolRunner.run(new HBaseBulkLoadDemo(), args));
- }
- public int run(String[] args) throws Exception {
- Configuration conf = HBaseConfiguration.create();
- String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
- if (otherArgs.length != 3) {
- System.err.println("Usage: <tableName> <inputDir> <outputDir>");
- System.exit(2);
- }
- HTable table = new HTable(conf, otherArgs[0]);
- Job job = new Job(conf);
- job.setJarByClass(HBaseBulkLoadDemo.class);
- job.setJobName("HBaseBulkLoadDemo " + new Date());
- job.setMapperClass(BulkLoadDemoMapper.class);
- job.setReducerClass(PutSortReducer.class);
- job.setMapOutputKeyClass(ImmutableBytesWritable.class);
- job.setMapOutputValueClass(Put.class);
- FileInputFormat.addInputPath(job, new Path(otherArgs[1]));
- FileOutputFormat.setOutputPath(job, new Path(otherArgs[2]));
- HFileOutputFormat.configureIncrementalLoad(job, table);
- return job.waitForCompletion(true) ? 0 : 1;
- }
- }
程序用打包后,扔到集群上运行,为验证结果,注意先truncate掉bl_tmp表并删掉/output目录。
另外一点,这里运行自己打的包,如果你没有打依赖包的话,因为你用到hbase-version.jar,所以你需要把它加到HADOOP_CLASSPATH上:
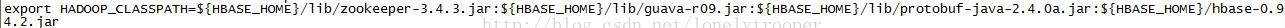
运行自己打的jar包:
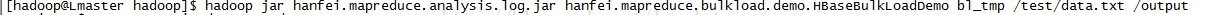
程序正确运行,查看/output下的输出:
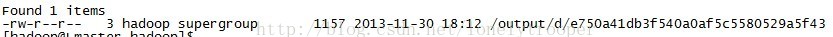
将数据装在进bl_tmp仍然可以用completebulkload工具,或者你可以自己写一个工具,非常简单,就是构造一个LoadIncrementalHFile对象,并调用它的doBulkLoad方法就好了。 然后查看这时的bl_tmp(注意列名,与importtsv时不一样...):
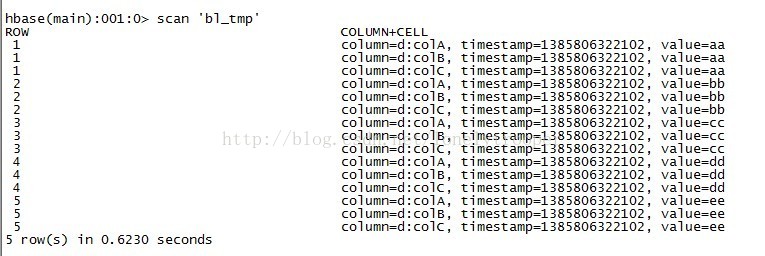
第三部分:
关于bulkload本身:
1.这种方式适合初次导入,对于大数据量,效率非常可观,并且不需要表offline
2.目前貌似只适合每次对一个单列族导入..
3.数据量很大时,因为reduce个数与region个数对应,所以导数前记得对表进行预分区。
4.自己实现时,map阶段的输出只能是<ImmutableBytesWritable,KeyValue>或者<ImmutableBytesWritable,Put>,对应的reducer分别是KeyValueSortReducer和PutSortReducer。
关于hadoop对jar的加载方式及bulk load时第三方jar的一些说明,自己在实践的时候起初迷惑了很久,所以特意总结了下:
1.hadoop jar在运行时一定会将HADOOP_CLASSPATH加到CLASSPATH上(感兴趣可以cat hadoop看下),并且将hadoop jar运行的目标jar拷贝到子节点。
2.依赖的第三方jar,一般三种方式处理,要么-libjars,要么加到HADOOP_HOME/lib下(所有子节点),要么打包进目标jar。
3.运行hadop jar hbase-version.jar importtsv时,由于将依赖的jar加到了HADOOP_CLASSPATH,并且在主节点本地可以找到,所以依托TableMapReduceUtil.addDependencyJars方法的作用,依赖的第三方jar在运行时被作为分布式缓存拷贝到了子节点,程序得以正确运行。
完... 















 2534
2534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









