






类创建
- 创建类成员变量—属性
封装:再创建get、set方法改变和获取被封装的变量
- 构造方法
- 创建无参构造
- 创建含参构造:创建对象+给对象的所有属性赋值
- 成员方法—普通方法
- 根据本类业务提供一些方法
- 提供一个方法,用于展现本类的类名以及本类所有属性和属性值
- 创建对象进行测试
4.1使用无参构造创建对象,然后调用setXxx()给对象的所有属性赋值
4.2 使用全参构造创建对象,对象的属性同时也有值
一基础
- 安装和环境变量配置
1.1安装路径最好不要有中文
1.2新建系统变量JAVA_HOME:安装的JDK根目录
修改系统变量Path:安装的JDK根目录下的bin目录
1.3新建系统变量CLASS_PATH:是JDK安装的lib目录
1.4 JDK安装配置测试: 想查看JDK是否安装配置成功.”win+r”键,弹出运行窗口输入“cmd“,在弹出的窗口输入”java -version”,显示版本号即配置成功。
2.JDK、JRE、JVM
JDK:最小开发工具包
JRE:最小运行环境
JVM:虚拟机,加载字节码文件
源代码:.java
字节码:.class(由源代码翻译成字节码供JVM运行)
虚拟机:jvm(分windows os liunx)
(一)、数据类型:
- 基础类型:
整数型:
- byte: 字节空间1 -2的7次方到2的7次方减1
- short: 字节空间2 -2的15次方到2的15次方减1
- int: 字节空间4 -2的31次方到2的31次方减1
- long: 字节空间8 -2的63次方到2的63次方减1
浮点型:
- float: 字节空间4 单精度
- double: 字节空间8 双精度
字符型:
- char: 字节空间2 0——65535
布尔型:
- blooean: 字节空间1 只有真(true)或假(false)
- 引用类型:
Byte:
Short:
Integer:
Long:
Double:
Float:
Character:
String:
(二)、数据类型五个规则(字面值类型):
- 整数默认int类型
- 浮点数默认double类型
- byte short char 可用范围内的值直接赋值
- long double float字面值后缀分别为L \D\ F
- 字面值加前缀改进制
二进制前缀0b
八进制前缀 0
十六进制前缀0x
(三)、类型转换规则:(包含数小的可以转成包含数大的不用加后缀, float需要加后缀)
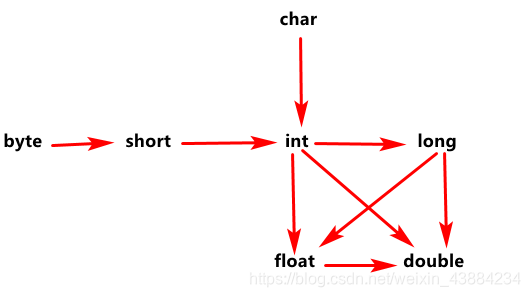
- 布尔类型不参与类型转换
- 基本类型之间能否转换,不取决于字节数,字节数为参考,主要取决于类型取值范围
- 基本类型之间转换,小类型转大类型自动转
- 大类型转小类型显示转换
- 整数运算会溢出,包含数大的可以转成包含数小的前面加强转标志(超出int的加后缀L)
- 浮变整,小数没 – 浮点型通过运算变整形是直接舍弃所有的小数部分的,不会四舍五入
(四)、类型运算规则:
1、运算结果的数据类型与最大类型保持一致
2、3种比int小的类型,运算时会自动提升成int再运算
3、整数运算溢出的问题,一旦溢出,数据就错误了
4、浮点数运算不精确
5、浮点数的特殊值 Infinity NaN
二、运算符
1概念:运算符 用于连接 表达式 的 操作数,并对操作数执行运算。

2算数运算符
1: 取余运算符

2: 自增自减运算符
前缀:++a先自增再使用(输出) --a先自减在使用(输出)
后缀:a++先使用(输出)再自增 a--先使用(输出)再自减

3.比较运算符
- 符号: < 、 <=、 > 、>= 、==、!=
- 特点:所有比较运算符结果都为boolean类型 返回true 和false
4.逻辑运算符
- 符号:&、&&、|、||、+、!
- &(与):1(true) 0(false)
1&1为 1(true) //全真才真
0&1、1&0 、0&0为0(false) //有假就假
- &&(双与):0&&1 时先判断前者为0(false)直接跳过后面判断
- |(或): 1(true) 0(false)
1|1、1|0 、0|1为1(true)//有真就行
0|0 为0(false) //全假才假
- ||(双或):1 ||0 时先判断前者为1(true)直接跳过后面判断
- + :拼接符号
- !: 取反的符号意思为不
- ^(亦或):不同为1 相同为0
- ~(非):非0为1,非1为0
5.三目运算符
1. 符号: ? :
2. 特点:a = 1 ? c : d 定义一个a而 1为判断条件,为真选c否则选择d
6.复合运算符
- d+=c; //d=d+c
- d-=c; //d=d-c
7.运算符优先级
小括号优先级最高
三、流程控制
1.顺序结构
2.分支结构
1.概念:顺序结构的程序虽然能解决计算、输出等问题但不能做判断再选择。对于要先做判断再选择的问题就要使用分支结构
2.形式:
单分支:if( 条件){ 代码 }
多分支1: if(条件){ 满足条件执行代码1 } else{ 不满足条件执行代码2 }
嵌套分支1:if( 条件1 ){ 代码1 } else if(条件2 ){ 代码2 } else if(条件3 ){ 代码3} else { 代码4}
嵌套分支2:if( 条件1 ){ if( 条件2 ){ 代码2 }代码1 }
3. switch选择结构
1.概念:switch case 语句用来判断一个变量与一系列值中某个值是否相等,每个值称为一个分支,当一个case成立,从这个case向后穿透所有case,包括default,直到程序结束或者遇到break程序才结束。
2.形式:


- switch结构的注意事项
1.switch 语句中的变量类型可以是: byte、short、int 、char、String(jdk1.7以后支持)
2.switch 语句可以拥有多个 case 语句
3.每个 case 后面跟一个要比较的值和冒号,且此值的数据类型必须与变量的数据类型一致
4.当变量值与 case 语句值相等时,开始执行此case 语句的内容,执行完会判断此行代码是否有break,如果有,结束执行,如果没有,会继续向后执行穿透所有case,包括default
5.switch 语句可以包含一个 default 分支,该分支一般是写在switch 语句的最后
6.如果在default之前的case有break,则default不会执行
4. for循环、while循环、do while循环
4.1概念
循环结构是指在程序中需要反复执行某个功能而设置的一种程序结构。
4.2for形式:
for(开始条件;循环条件;更改条件){
循环体
}

4.3嵌套 for形式
for(开始条件;循环条件;更改条件){
for(开始条件;循环条件;更改条件){
循环体
}
}
- 外层循环控制的是执行的轮数,内层循环控制的是这一轮中执行的次数
- 外层循环控制的是图形的行数,内层循环控制的是这一行的列数
- 开始条件只执行一次,循环次数取决于能取到几个数。
4.4 while循环形式
while( 判断条件true继续 false不再循环){ 循环体 }
4.5 do while循环形式
do{ 循环体 }while( 判断条件true继续 false不再循环)
do表示先执行一次
4.6 break 和 continue:
Break: for循环内使用时,跳过本循环,继续循环体外的代码
Continue: for循环内使用时,提高程序效率,跳过后续代码,再次开启下一轮循环,for循环内使用时,continue后不可加代码,因为代码不可达。
4.7特性
1. 循环的开始条 件只会在第一轮开始的时候执行一次,后续均不再执行
- 循环结构适合我们在程序中需要反复执行某一件事时使用
- 循环能够执行几次,取决于循环变量能够取到几个值,而不是循环变量的取值范围
五 变量
1.概念
可以改变的数,称为变量。在Java语言中,所有的变量在使用前必须声明。
一般通过“变量类型 变量名 = 变量值 ;”这三部分来描述一个变量。如:int a = 3 ;
变量的使用原则:就近原则,即尽量控制变量的使用范围到最小
2.成员变量
位置:定义在类里方法外
注意:不用初始化,也会自动被初始化成默认值
作用:整个类中,类消失了,变量才会释放
指定本类已有变量:用this.指定本类成员变量;用super.指定父类成员变量。

3.局部变量
位置:定义在方法里或者局部代码块中
注意:必须手动初始化来分配内存.如:int i = 5;或者int i; i = 5;
赋值:先声明再赋值,或声明同时赋值
作用域:也就是方法里或者局部代码块中,方法运行完内存就释放了
六 方法
1 概述
被命名的代码块,方法包括含参数和不参数,可以提高代码的复用性。
2 方法定义的格式

3 方法调用顺序图
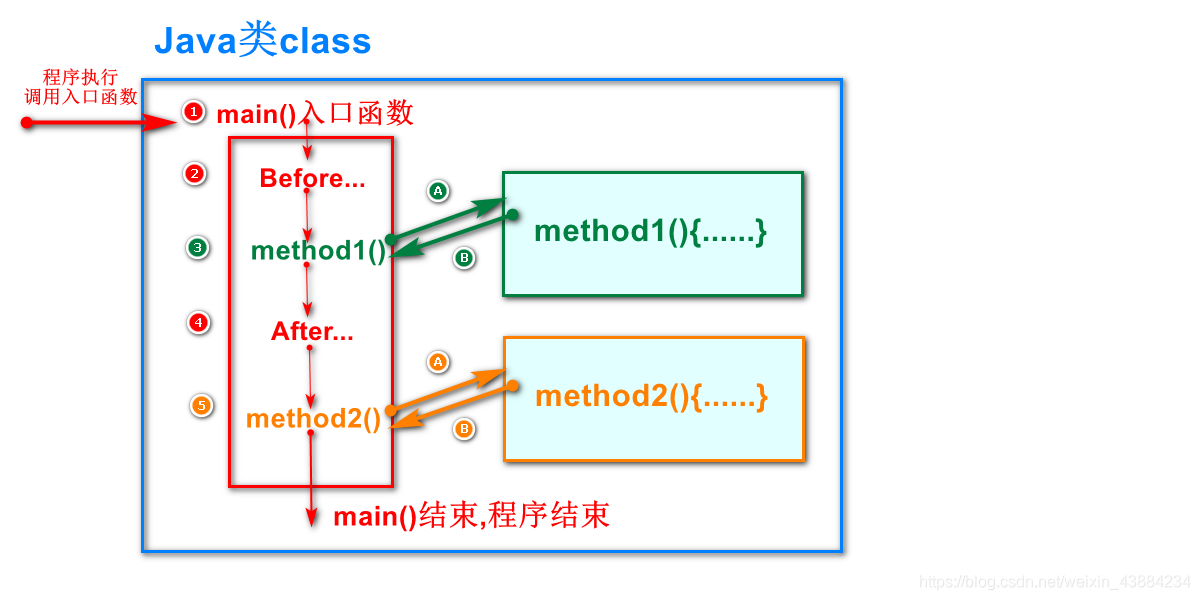
4 方法的重载(需要与重写区分)
1.定义:如果在同一类中,存在多个同名方法,但是参数列表不同的现象(也就是指参数的个数和类型不同或类型顺序不同)
2.,程序在调用方法时,可以通过传递给他们的不同个数和类型的参数来决定具体调用哪个方法.
3.作用:重载使我们的代码更灵活,传入不同的参数,都可以有对应的方法被调用。
==方法是否构成重载,与方法的类型有关,与方法参数名无关。
七 数组
1.概述
数组Array,标志是[ ] ,用于储存多个相同类型数据的集合想要获取数组中的元素值,可以通过脚标(下标)来获取数组下标是从0开始的,下标的最大值是数组的长度减1。
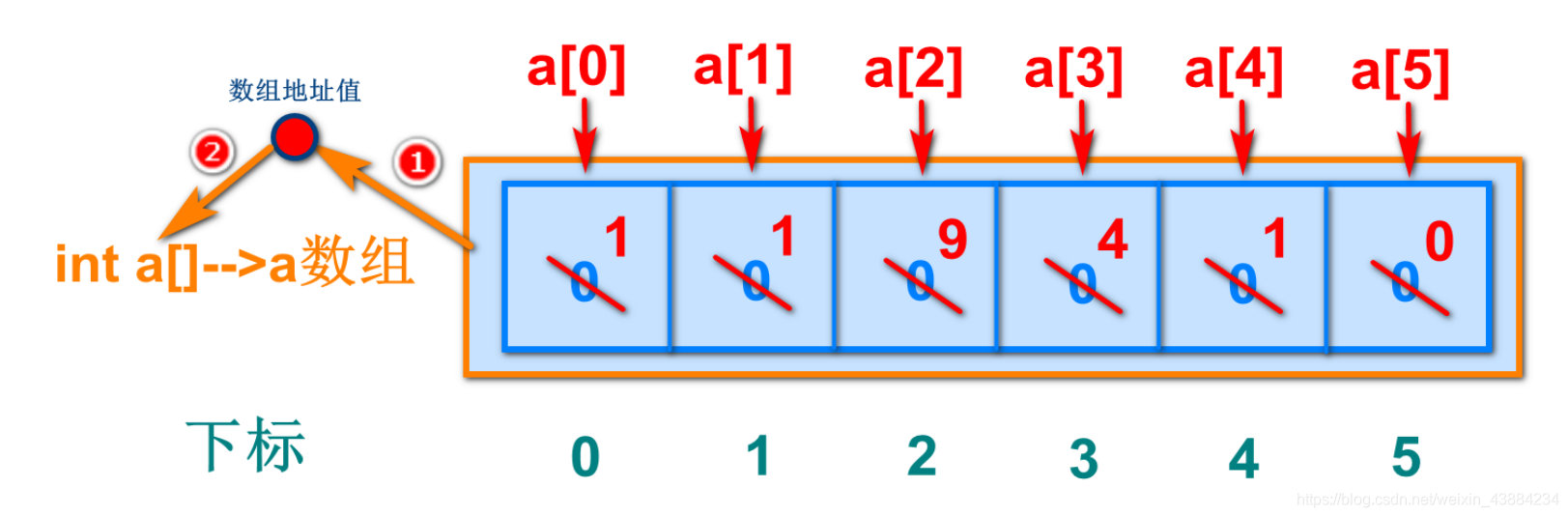
2.创建数组
(1)动态初始化
int [ ] a=new int[5]
(2)静态初始化
int [ ] a={1,2,3,4,5}
char[] c2 = new char[] {'h','e','l','l','o'};
无论什么样创建方式都需要制定数组类型与长度,长度可以为0。
3. 打印数组
char类型数组中底层做了处理,可以直接打印数组中的具体元素
除了char类型 其他类型查看数组中的具体元素,需要使用数组的工具类Arrays
否则打印的是地址值。
方式: Arrays.toString(数组名); //Arrays 需要导包
System.out.println(Arrays.toString(s1));//使用Arrays 工具类的toString 方法
4. 查看数组的长度
System.out.println(s3.length); / /数组中存放的元素的个数
5. 数组的扩容和缩容
copyof()用于完成数组的复制()内需要两个参数(原数组,新数组长度)
扩容:给数组扩大容量,新数组的长度大于原有数组长度
扩容思路:先创建对应长度的新数组,每个位置上都是声明变量的默认值
然后从原来数组中将元素复制到新的数组,没有被覆盖的还是默认值
缩容:给数组减小容量,新数组的长度小于原有数组长度
缩容思路:先创建对应长度的新数组,每个位置上都是声明变量的默认值
然后从原来数组中将元素复制到新的数组,超出长度的从后往前去除
6. 从指定范围截取数组中的元素
copyofRange()用于截取数组,需要3个参数,copyofRange(需要截取的数组名字,开始,结尾) ———————— 截取数组位置含头不含尾 [开始,结尾)
7. 注意事项
数组一旦创建长度不可改变,如果要增减数组元素,只能创建一个新长度的数组,将原来的数据复制到新的数组中
8. 数组工具类Arrays
(1)Arrays.toString(数组) 数组中的数据组成一个字符串
(2)Arrays.sort(数组) 底层优化后的快速排序方法
(3)Arrays.copyOf(数组,新的长度) 从原来数组中将元素复制到新长度的新数组
(4)Arrays.copyofRange(需要截取的数组名字,开始,结尾) 截取指定范围的元素
9.数组排序(冒泡排序)

八.面向对象
1.概念
面向过程是一种思想,意思是我们要做任何事,都需要亲力亲为,强调的是过程。
面向对象也是一种编程思想,相对于面向过程,我们可以由原来问题的执行者变为指挥者,进而把生活中很多复杂的问题变得简单化。
java 初始化顺序:
静态成员变量>静态初始化块>普通成员变量>普通的初始化块>普通的初始化块>构造方法(自动初始化时机在调用任何方法之前(构造方法,成员方法))
2.三大特征
- 封装: 把相关的数据封装成一个“类”组件
- 继承: 是子类自动共享父类属性和方法,这是类之间的一种关系
- 多态: 增强软件的灵活性和重用性
3 类和对象
3.1 类(包含方法(行为)和变量(属性))
- Java语言最基本单位就是类,类似于类型。
- 类是一类事物的抽象。
- 可以理解为模板或者设计图纸。
- 多个方法共用的变量(属性)为成员变量,方法内(块内)的为局部变量
- 类为未实现某方面功能时的称呼。
3.2 对象
1.每个对象具有三个特点:对象的状态,对象的行为和对象的标识。
2.对象的状态用来描述对象的基本特征。
3.对象的行为用来描述对象的功能。
4.对象的标识是指对象在内存中都有一个唯一的地址值用来和其他对象区分开来。
5.类是一类事物的抽象,对象是具体的实现。
6.对象是类实现的状态,根据类创建出的一个一个的实例,标志为“new”。
3.3 类和对象的关系
计算机语言来怎么描述现实世界中的事物的? 属性 + 行为
我们可以通过类来描述一类事物,用成员变量描述事物的属性,用方法描述事物的行为
3.4 对象创建过程
Person p = new Person();//短短这行代码发生了很多事情
1.把Person.class文件加载进内存
2.在栈内存中,开辟空间,存放引用变量p
3.在堆内存中,开辟空间,存放Person对象
4.对成员变量进行默认的初始化
5.对成员变量进行显示初始化
6.执行构造方法(如果有构造代码块,就先执行构造代码块再执行构造方法)
7.堆内存完成
8.把堆内存的地址值赋值给变量p ,p就是一个引用变量,引用了Person对象的地址值
3.5匿名对象(不重要)
正常创建对象是Demo d = new Demo();
匿名创建对象 new Demo().show(); 每个匿名对象生成一个独立地址值
new Demo().show(); 另一个独立的对象
4.封装
4.1 概述
隐藏对象的属性和实现细节,仅仅对外提供公共的访问方式,比如类和方法
可提高安全性
可提高重用性
4.2 private关键字
权限修饰符 ,可以用来修饰成员变量和成员方法.被私有化的成员只能在本类中访问,按提供的方式来调用,私有化的成员变量需要根据属性生成公共的getXxx()与setXxx()方法
4.3 方法的封装
方法的封装也是使用private来修饰方法
如果想要调用私有方法的功能,就需要在该类的其他公共方法里调用这个私有方法
5.访问控制符
 Public:Public修饰的可被同类、同包、子类、不同包使用
Public:Public修饰的可被同类、同包、子类、不同包使用
Protected:Protected修饰的可被同类、同包、子类使用
默认(default):默认修饰的可被同类、同包使用
注:default是表示不写修饰符,默认,如果写default单词来修饰会报错
private:private修饰的只可被同类使用,权限修饰符。 可以用来修饰成员变量和成员方法.被私有化的成员只能在本类中访问,按提供的方式来调用,私有化的成员变量需要根据属性生成公共的getXxx()与setXxx()方法
6.构造方法
6.1.概念
构造方法是一种特殊的方法,它是一个与类同名且没有返回值类型的方法构造方法的主要功能就是完成对象创建或者初始化当类创建对象(实例化)时,就会自动调用构造方法,构造方法与普通方法一样也可以重载.
6.2 形式
修饰符 与类同名的方法名 参数列表(含参或无参或全参){ 方法体 }
6.3 注意事项
1.每次new(实例化)一个对象时,都会触发对应的构造方法
2.每一个类都会默认存在一个没有参数的构造方法
3.构造方法的格式:没有返回值类型并且与类名同名的方法
4.每次创建对象时都会创建构造方法::::构造方法作用:创建对象。
5.创建全参构造(可以给成员变量赋值,构造方法内需要有赋值语句):Generate——constructor——参数全选
6.如果创建了含参构造 则无参构造被覆盖,除非手动创建无参构造。
7.构造代码块与局部代码块
当创建对象时会触发构造函数,也会触发构造代码块,而且构造代码块优于构造方法执行,我们通过创建好的对象来调用普通方法,如果调用普通方法里有局部代码块,对应的局部代码才会执行。
7.1执行顺序
执行顺序(0)静态代码块(如果有)、(1)构造代码块 、(2)构造方法 、(3)对象创建成功、(4)普通方法、(5)局部代码块
7.2静态代码块
- 位置: 在类的内部,在方法的外部
- 作用: 常用于优先加载只加载一次的内容,用于项目的初始化。
- 执行时机: 每次调用构造方法前都会调用构造代码块
7.3构造代码块
- 位置: 在类的内部,在方法的外部
- 作用: 用于抽取构造方法中的共性代码
- 执行时机: 每次调用构造方法前都会调用构造代码块
- 注意事项: 构造代码块优先于构造方法加载
7.4局部代码块
- 位置: 在方法里面的代码块
- 作用: 通常用于控制变量的作用范围, (出了局部代码块,本方法其他区域也不可用),出了花括号就失效
- 注意事项: 变量的作用范围越小越好,成员变量会存在线程安全的问题
8. 继承
9.1概念
1. 继承是面向对象最显著的一个特征
2. 继承是从已有的类中派生出新的类,新的类能吸收已有类的数据属性和行为,并扩展新的能力.
3. Java继承是会用已存在的类的定义作为基础建立新类的技术
4.新类的定义可以增加新的数据或者新的功能,也可以使用父类的功能,但不能选择性的继承父类(超类/基类)
5.这种继承使得复用以前的代码非常容易,能够大大的缩短开发的周期,降低开发费用.
9.2继承的特性
1.继承的关键字extends 格式: 子类 extends 父类
2.继承相当于子类把父类的功能复制了一份,包括私有资源
3.Java只支持单继承:一个子类只能有一个父类,一个父类可以有多个子类
4.继承具有传递性:爷爷的功能会传给爸爸,爸爸的功能会传给孙子
5.子类只可以使用父类的非私有资源,私有资源不可用的原因是不可见
6.子类可以拥有自己的特有功能
7.继承是is a 强耦合的关系,依赖性非常强,比如我们看到”熊孩子”,就知道他有一个”熊父母”
9.3继承中的构造方法
1.子类在创建对象时,默认先调用父类无参构造
2.原因是子类的构造函数中第一行默认存在super() 表示调用父类的无参构造
3.当父类没有无参构造时可以通过super(参数) 调用父类的含参构造,但是不能不调用父类的任何构造函数
4.(1)构造方法不可被继承,语法要求
(2)构造方法名是本类的类名,所以子类方法名写父类类名否则就不叫构造方法,————所以子类不能重写父类的构造方法。
9.4重写
9.4.1重写概念
子类对父类的方法不满意时,可以重写父类的方法,对其功能做修改
(1)方法名、参数列表不能改.(2)修饰符、返回值可改但需要符合一定规则
9.4.2重写意义
在不修改源码的情况下,进行功能的修改与拓展(ocp原则:面向修改关闭,面向拓展开放)
9.4.3重写规则:两同 两小 一大
一大:子类方法的修饰符权限 >=父类方法的修饰符权限
两同:方法名相同,参数列表相同
两小:子类方法的返回值类型<=父类方法的返回值类型
子类抛出的异常类型<=父类的抛出异常类型
9.4.4注意事项:
如果父类方法返回值类型为void,则子类的返回值类型也是void
此处返回值类型大小不是值的大小,而是继承关系(返回值的范围要小于等于父类)
9.5 this
9.5.1概念
this代表的是本类,this代表本类对象的一个引用对象
9.5.2形式用法
1. 当本类成员变量与局部变量同名的时候作为指定成员变量使用,this.name = name
2. 调用本类的构造方法(1)调用无参构造this()(2)调用含参构造this(参数)
3. this调用构造方法的语句不能同时在无参含参中间来回调用,会出现死循环,所以只能单方面调用
4. this调用构造方法的语句 必须在构造方法的第一行
9.6.final关键字
1.final 可以用于修饰类,但被final修饰的类是最终类,不允许被继承.
2.final 可以用于修饰方法,但被final修饰的是最终方法,不允许被重写,重载。
3.final 可以用于修饰变量,但被final修饰的变量必须被赋值而且成为了常量,不允许被重新赋值。
(可以把被final修饰的类看成树结构中的叶子节点。)
9.7.super和this对比
1.this代表的是本类对象的引用,我们可以把this看作是Cat this = new Cat();
2.super代表的是父类对象的引用,我们可以把super看作是Father super = new Father();
3.当本类的成员变量与局部变量同名时,需要使用this.变量名指定本类的成员变量
4.当本类的成员变量与父类的成员变量同名时,需要使用super.变量名指定父类的成员变量
5.this可以实现调用本类构造方法的功能,不能互相调用,需要写在构造方法首行
6.this();表示调用本类的无参构造 this(参数);表示调用本类的对应参数的构造
7.super也可以实现调用父类构造方法的功能
8.super();表示调用父类的无参构造 super(参数);表示调用父类的对应参数的构造
9. 注意:super的使用前提是继承,没有父子类关系,就没有super
10.注意:this调用构造方法或者super调用构造方法,都必须出现在构造方法的第一行
11.注意:如果父类没有无参构造,需要手动在子类构造方法的第一行调用其他的含参构造
12.拓展:如果子类重写了父类的方法以后,可以使用super.方法名(参数列表)来调用
9.静态
10.1概述
Static是关键字,用于修饰成员(成员变量和成员方法),被static修饰的资源被称为静态资源,静态资源是随着类加载到内存中的,比对象优先进入内存所以********静态资源可以通过类名直接调用,即使没有创建对象也可以被调用*********
10.2特点
1.可以修饰成员属性变量与成员方法
2.随着类的加载而加载,优先于对象加载
3.只加载一次,就会一直存在,不再开辟新空间, 直到类消失才一起消失
4. static修饰后的静态资源在内存中只有一份,全局共享,通过任意方式修改静态变量的值,其他任何方式查看到的都是修改后的值。
5.可以直接被类名调用
6. static静态只能调用static静态,非静态可以随意调用
7.static不能和this或者super共用,因为有static时可能还没有对象
10.3对比静态代码块、构造代码块、局部代码块
1.静态代码块:在类加载时就加载,并且只被加载一次,一般用于项目的初始化 样子:static{ }
2.构造代码块:在创建对象时会自动调用,每次创建对象都会被调用,提取构造共性
3.局部代码块:方法里的代码块,限制局部变量的范围
4.一个项目各个部分在内存中加载顺序:
JVM——public——main方法——各类——各类中的静态资源——创建的对象——对象中的构造代码块——对象中的构造方法——对象创建完成——普通方法——普通方法中的局部代码块
10.多态
11.1.概念
多态是面向对象程序设计(OOP)的一个重要特征,指同一个实体同时具有多种形式,即同一个对象,在不同时刻,代表的对象不一样,指的是对象的多种形态。
可以把不同的子类对象都当作父类来看,进而隔离不同子类对象之间的差异,写出通用的代码,做出通用的编程,统一调用标准。
11.2.特点
1.多态的前提1:是继承
2.多态的前提2:要有方法的重写
3.父类应用指向子类对象:如 Animal a=new cat()
4.多态中,编译看左边,运行看右边(Animal a=new cat(),左边编译时父类中必须定义过方法(1),运行看右边是指右边运行的必须在子类中重写过父类方法(1),运行时方法体内使用的是子类重写后的功能)
11.3三种创建对象
1、Animal a=new Animal ()
父类创建父类对象,不能调用子类功能(无论是重写的还是特有的)
2、Animal a=new Cat()————————————————————————此种为多态
父类引用指向子类,调用重写的父类对象,或者未重写的父类普通方法,不能调用子类特有功能
3、Cat a=new Cat()
子类引用子类对象,能调用子类特有对象和子类重写的父类对象,或者未重写的父类普通方法
4、无论父类子类,如果为抽象类,则不可以创建对象。
11.4多态成员的使用情况
1.多态中,成员变量使用的是父类的
2.多态中,方法的声明使用的是父类的,方法的实现使用的是子类的
3.多态中,如果父子类都有同名的静态方法,使用的是父类的,因为多态对象把自己看作是父类型,直接使用父类静态对象
11.抽象类
12.1概述
1.抽象类结构 abstract class 类名{ }
2.抽象方法结构 方法名();—————————小括号后面无大括号,抽象方法没有方法体
3.如果一个类包含了抽象方法,则这个类必须为抽象类
4.抽象类里可以有普通方法,而且可以全为普通方法,可以全为抽象方法
5.当子类继承抽象父类后 (1)要么继续变成抽象类 (2)要么将父类所有抽象方法功能实现成为普通子类
6.抽象类不可以创建对象。
7.抽象类存在构造方法,是为了子类创建对象时候可以使用super();
8. 抽象类中可以声明变量
9. 抽象类中可以声明常量
12.异常
1 概述
异常是一些用来封装错误信息的对象它由异常的类型、提示信息、报错的行号提示三部分组成
2.异常的继承结构

3. 异常的暴露
1.不要害怕BUG,真正的勇士敢于直面自己写的BUG
2.学会看报错的提示信息,确定错误的方向,不管第一行有多长,都要看完
3.学会看报错的行号信息(从下往上看),确定自己报错的位置,哪里不对点哪里
注意:源码应该不会错,应该看自己的代码*/
4.解决方案
4.1捕获
1.捕获处理的格式: try{可能发生异常的代码}catch(异常类型和异常名){捕获到了预先推测的异常,就执行此处设置的解决方案}
2.忽略所有子异常,catch内统一使用父类异常类型,catch(exception e) ————————这是多态最为经典的一种用法
4.2向上抛出
1.向上抛出:谁调用谁解决
2.异常抛出的格式:方法()throws 异常类型1,异常类型2...{}
3.注意:我们一般不把异常抛给main方法,因为没有人解决了,再往后就是JVM虚拟机运行了,所以我们一般会在main()调用之前就解决异常
4.main方法之前创建method方法,处理抛出的异常,method包含解决方案,解决方案包括捕获或者继续向上级方法抛出。
(即,如果method方法调用了会抛出异常的方法(如f3()),有两个解决方案:捕获和抛出)
5.方法上直接抛出异常时,异常类型要<=RunTimeException
13.接口(区别于普通类和抽象类)
1 接口的概念
接口( Interface )在Java中是一种抽象类型,接口中的内容是抽象形成的需要实现的功能,接口更像是一种规则和一套标准.
作用:接口是先天设计结果,最先写,并且要制定好规则
2 接口的实现过程
2.1创建接口
2.2创建接口实现类
2.3主类中使用实现了的接口方法
3 接口的特性
3.1 构造方法:
接口interface不算类。接口本身没有构造方法(也没有构造代码块),所以实现类的super()调用的默认存在的总父类object的无参构造。
3.2 成员变量:
接口中的变量实际上是静态常量,静态:可以被接口名直接调用 常量:值不可以被修改,并且定义时必须赋值
所以:接口会默认给每个变量自动拼接 public static final
3.3 创建对象:
接口里全是抽象方法,与抽象类一样无法创建抽象对象
3.4 实现类:
实现类实现了接口,则其要么变成抽象类(方法不实现或部分实现),要么变成一个普通子类(方法全部实现)。
4. 接口的意义
接口是用来指定规则的(包括有哪些方法,方法有哪些参数,是否有返回值类型),并不做具体的实现。
接口可以对上多继承(一个接口可以继承多个接口) 对下多实现(一个类可以实现多个接口)
5.面试题
5.1.类与类的关系:
1.1继承关系,只支持单继承
1.2子类不能使用父类的私有资源,原因是私有不可见
1.3继承相当于子类把父类的功能复制了一遍,但是构造方法不可继承
1.4子类如果要修改原有功能,需要重写(方法签名与父类一致 + 权限修饰符>=父类修饰符)
5.2.接口和接口的关系:
2.1继承关系,接口既可以继承一个接口,也可以继承多个接口
如:interface A extends Inter1()
interface A extends Inter1, Inter1()
5.3.类和接口的关系:
3.1 实现关系:可以单实现,也可以多实现
class A implements Inter1{}
class B implements Inter1, Inter2{}
B需要实现Inter1, Inter2所有抽象方法,否则就是一个抽象子类,任何一个抽象方法没有实现它就是一个抽象子类。
3.2 一般创建引自接口实现类的对象,我们不创建接口多态对象。
3.3 类只能继承一个接口,但可以实现多个接口。
5.4.抽象类与接口的比较
4.1抽象类是特殊的类,这个类被abstract修饰,并且可以存在抽象方法。
接口不是类,接口由interface声明,主要只存在抽象方法,接口可以存在带方法体的方法,但是必须被default修饰 ,称为默认方法。
4.2抽象类可以没有抽象方法,接口所有的方法都是抽象方法,除了被default修饰的方法。
4.3抽象类是class,接口不是class,接口是interface。
4.4抽象类中有构造方法,但接口中没有构造方法
4.5抽象类与接口均不可创建对象
4.6抽象类只能单继承,接口可以多继承。
4.7抽象类中可以定义普通成员变量,接口中只能存在静态常量
4.8抽象类是后天重构的结果,接口是先天设计的结果。
九.API
1. API概述:
1.1定义:
API(Application Programming Interface,应用程序接口)是一些预先定义的函数,基本单位是类(class)。
1.2目的作用:
提供应用程序与开发人员基于某软件可以访问的功能集,但又无需访问源码或理解内部工作机制的细节。
API作为其公共开放系统,也就是公司制定自己的系统接口标准,当需要进行系统整合,自定义和程序应用等操作时,公司所有成员都可以通过该接口标准调用源代码.
2. API应用:
2.1顶级父类Object
Object类是所有Java类的祖先,也就是说我们所说的”顶级父类”, 在不明确给出父类的情况下,Java会自动把Object类作为要定义类的超类。
2.2常用包lang包、util包
java.lang包是java的核心,包含了java基础类,包括基本Object类/Class类/String类/基本数学类等最基本的类,这个包无需导入,默认会自动导入。
Java.util包是java中的工具包,包含各种实用工具类/集合类/日期时间工具等各种常用工具包。
2.3常用方法
2.3.1 toString():
Object中toString()默认实现,对象名@十六进制的哈希码值
1.如果子类没有重写toString则println默认打印的对象.tostring()是
getClass().getName() + "@" + Integer.toHexString(hashCode())
2.如果子类重写了toString()以后println打印的对象.tostring()是重写后的
类型+属性+属性值
2.3.2 hashCode()
作用是返回对应对象的int类型哈希码值力求不同对象返回的哈希码不同这样可以根据不同哈希码值区分不同对象。
2.3.3 equals()
object中equals的默认实现,用的是==比较
==比较的是左右两边的地址值,1.如果两边是基本类型则比较的是字面值。2.如果是引用类型则比较的是引用对象的地址值。
2.3.4 equals和hashcode要一致,要重写都重写 要不重写都不重写
如果不重写:hashcode()的哈希码值根据地址值生成
equals底层使用==比较两个对象的地址值
如果重写了:hashcode()的哈希码值根据重写传入的属性值生成,属性一致哈希码值就是一样
equals底层使用==比较的是重写后的类型+所有属性与属性值
2.4 String类
String底层是一个封装char[]数组的对象,字符串固定不可变
2.4.1创建String对象的方式:
方法一:String str = “abc”
本方法如果是第一次使用字符串,java会在字符串堆中常量池创建一个对象。后续创建该字符串时,堆内存只需重复使用该常量池中的“abc”字符串地址值,节省内存空间。
方法二:char[] c={'a','b','c'};
String s1=new String(c);
堆栈创建新内存,下次创建字符串为“abc”的S2对象时,需要重新开辟堆内存存储相同字符串生成不同地址值。
方法一、方法二哈希码值一样,因为String类默认重写了hashcode(),是根据字符串的内容生成哈希码值,而不是根据地址值生成所以S1S2 一个在堆的常量池中,一个在堆中,他俩的哈希码值一样。
2.4.2string的常用方法
hashCode():底层重写了hashCode()根据字符串的内容生成哈希码值,内容相同哈希码值相同。
length() : 通过.length()方法获取字符串长度。
toLowerCase(): 字符串中的字母转小写。
toUpperCase(): 字符串中的字母转大写。
startsWith("a"): 判断是否以a开始。
endsWith("a") : 判断是否以a结尾。
charAt(0): 根据下标获取元素。
lastIndexOf("j"): j最后第一次出现的下标。
indexOf("j") : j第一次出现的下标。
concat(s1) : 将指点字符串拼接到本字符串结尾———临时拼接(可声明新的变量成为新拼接后的字符串)
split("b") : 以指定字符串中的b字符作为分隔符,分割字符串成为数组,如无b则不分割。
trim() : 去除首尾两端的空格。
getBytes() :把字符串存储到一个新的 byte 数组中
substring(3) : 从指定下标开始截取[下标3,结束]。
substring(3,6) : 从指定下标开始到指定下标结束(不含结束下标)截取[下标3,下标6)。
valueOf(1.1) : 将括号中其他类型转为String类型。
2.5 StringBuilder/StringBuffer
相同点:这两个方法都是拼接字符串的方法,拼接速度都很快。
不同点:StringBuilder,拼接速度更快,线程不安全
StringBuffer,拼接速度慢,线程安全
3.正则表达式
1 概述
建立正确的字符串格式规则。
2 常见语法
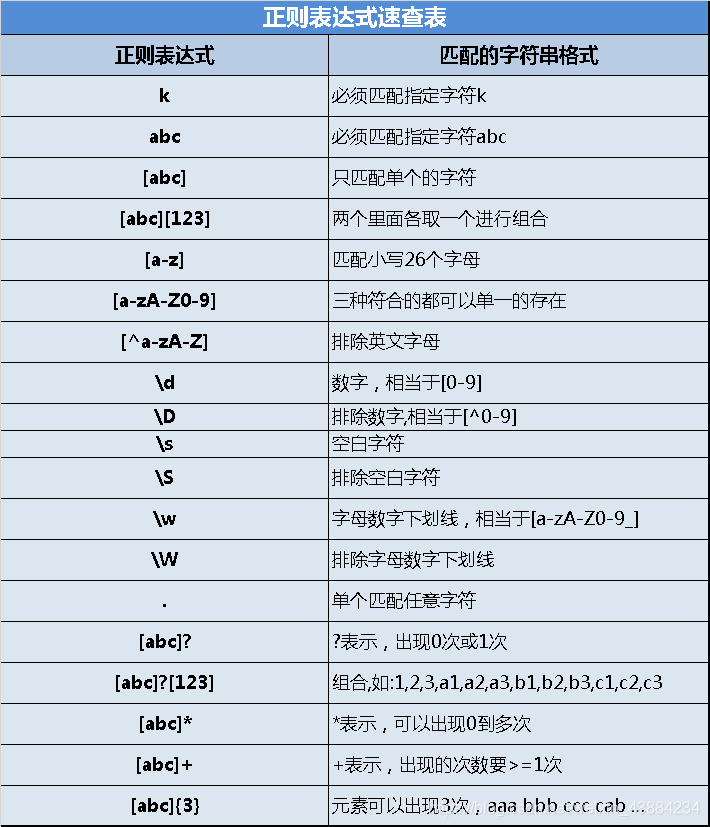
单个\在Java中有特殊含义,表示转义符号,不认为是一个斜杠,\\才表示斜杠,前面的斜杠转义告诉你后面的斜杆不是转义符号,否则单个斜杆代表转义符号后面的内容意思会变。
3.regex
String regex=输入规则;
目标数据.matches(regex):
4.包装类
4.1定义:
对基本类型进行包装,提供更加完善的功能。
4.2意义:
基本类型是没有任何功能的,只是一个变量,记录值,而包装类可以有更加丰富的功能。
4.3包装类与基本类型的对应关系
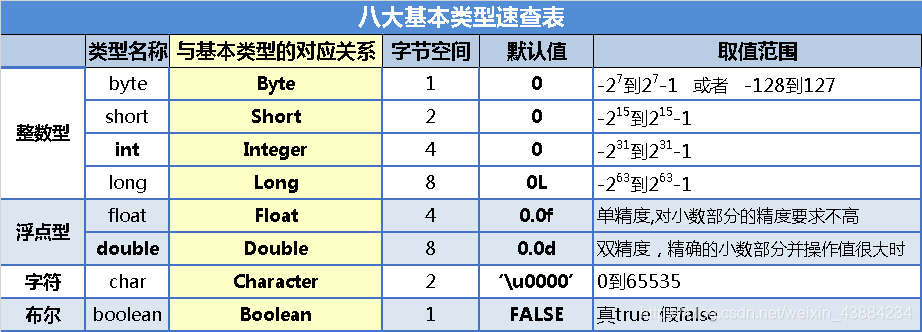
4.3.1例:Integer包装类
可以高效存储数据(快速且节省内存),但需要3个条件,1.是Integer类型。2.使用valueof()创建方法。3.数据在-128-127范围内(因为Integer底层保存了-128-127的常数和'0'-'9','a'-'z'的字符),满足以上条件,相同数据只会存一次,后续在使用的都是刚刚保存过的数据。只有Integer才有高效的效果,其他包装类是没有的。
4.4自动装箱自动拆箱
自动装箱:把基本类型包装成对应的包装类型的过程
Integer i1=new Integer(5);
Integer i2=Integer.valueOf(5);
Integer i3=5;
编译器会把基本类型int 5,包装成对应的包装类型Integer,然后交给对象名i3来保存
自动装箱底层的代码:Integer.valueof(5);
valueof()的方向:int——>Integer
自动拆箱:从包装类型的值,自动变成基本类型的值
int i4=i3;
编译器会把包装类型的i3拆掉箱子,变回基本类型数据5,然后交给基本类型int类型的变量i4来保存
底层发生的代码:i3.intvalue()
valueof()的方向:Integer——>int
5. BigDecimal类
5.1作用:
本类用于解决浮点运算不精确的问题
将数据转为BigDecimal类型:BigDecimal b = new BigDecimal( 原始数据 );
使用转化后的数据再进行运算
5.2 特殊情况
5.2.1 double类型转为BigDecimal本身就存在不精确:
最好不要用double作为构造函数的参数类型。
所以最好使用String类型参数的构造方法,这样就可以精确计算了,如果使用double类型预算可将double转String,转的快速方法 拼接一个""就可以了。
5.2.2 String类型转为BigDecimal使用除法divide()依旧除不尽(算数本身数不尽如:1/3):
使用divide(o,m,n),
o:除数
m:指的是如果除不尽,结果保留几位小数
n: 指的是保留是采取的舍入方式,BigDecimal.ROUND_HALF_UP为四舍五入。
十.IO流
1.概念:
Io流创建过程:
1.创建流对象
2.使用流对象
3.关闭流对象
Io流通用创建结构及解决异常的通用结构
1.声明流对象
2.try{ io流创建 }catch( IOException e){ e.printStackTrace(); }finally { try{ 关闭流对象 } catch (IOException e) { e.printStackTrace(); } }
1.1. 流(Stream)的概念:
数据的读写操作抽象成数据在"管道"中流动
1.流只能单方向流动
2.输入流用来读取 → in
3.输出流用来写出 → out
4.数据只能从头到尾顺序的读写一次
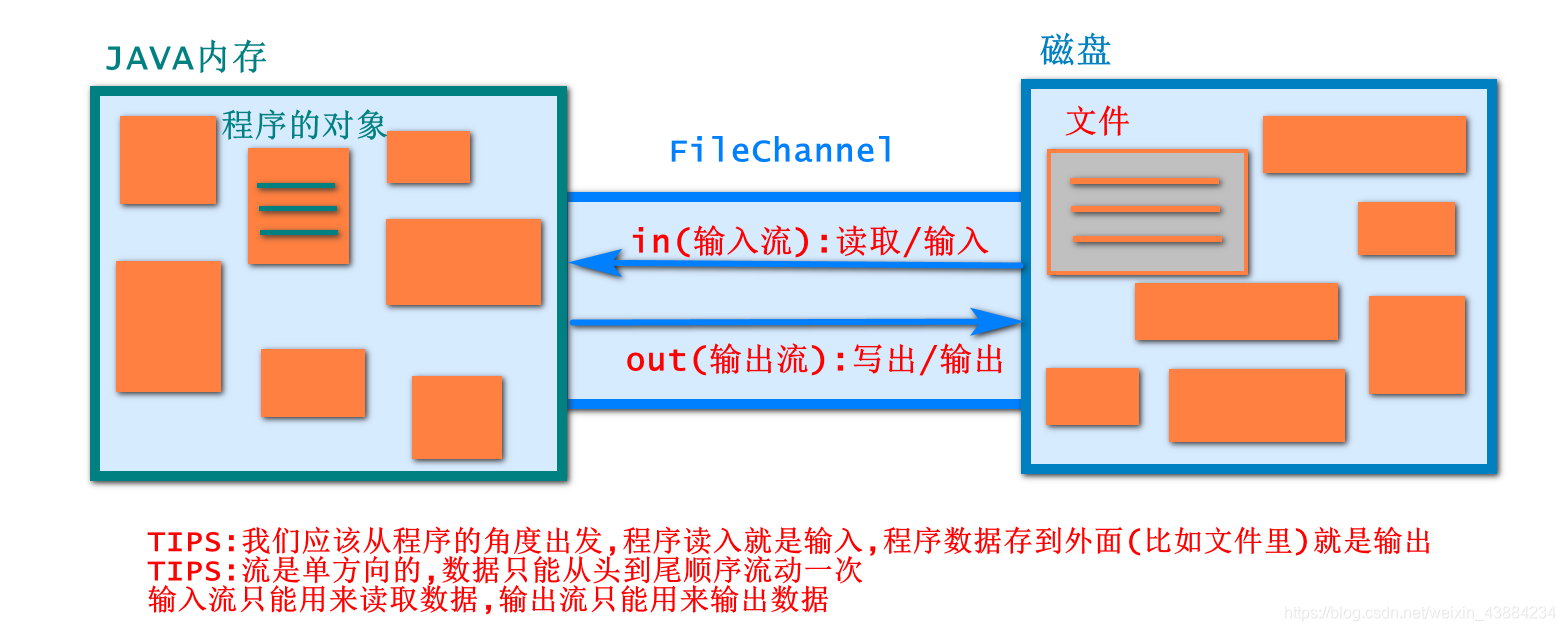
-
- 流的分类
按流的方向:
输入流:数据从磁盘到程序(内存)
输出流 数据从内存(程序)到磁盘
按操作数据单位
字节流:什么类型的东西都可以处理,包括文档音频 视频等
字符流:只能处理与字符相关的内容
-
- 常用IO流类的继承结构
Object:
字节流
InputStream 字节输入流父类
——FileInputStream 普通字节输入流
——FilterInputStream
——BufferedInputStream 高效字节输入流
OutputStream
——FileOutputStream 普通字节输出流
——FilterOutputStream
——BufferedOutputStream 高效字节输出流
字符流
Reader
——InputStreamReader
——File Reader 普通字符输入流
——Buffered Reader 高效字符输入流
Writer
——OutputStreamWriter
——File Writer 普通字符输出流
——Buffered Writer 高效字符输出流
- 常用类
2.1 InputStream
父类InputStream是抽象类无法创建对象,字节输入流
2.1.1子实现类FileInputStream
操作文件的字节输入流
FileInputStream构造函数有两个 一个需要File对象 一个需要String路径(使用此种简洁)。
创建时代码会抛出异常(找不到文件异常),使用try-catch解决异常。解决办法:f.printStackTrace(); 报错之后在控制台给程序员打印错误信息来调试。
2.1.2子实现类BufferedInputStream
高效的操作文件的字节输入流
BufferedInputStream构造函数有两个 分别需要(InputStream in)和(InputStream in, int size)参数。InputStream为抽象类无法创建对象所以创建其子实类new FileInputStream(路径)
2.2 OutputStream
父类OutputStream是抽象类无法创建对象,字节输出流
2.2.1 子实现类File OutputStream
操作文件的字节输出流
FileOutStream(File file,boolean append)—如果第二个参数为true,表示追加,不覆盖
2.2.2 子实现类BufferedOutputStream
高效的操作文件的字节输出流
2.3 Reader
父类Reader是抽象类无法创建对象,
2.3.1 子实现类FileReader
操作文件的字符输入流
2.3.2 子实现类BufferedReader
高效的操作文件的字符输入流
2. 4 Writer
2.4.1 子实现类FileWriter
操作文件的字符输出流
2.4.2 子实现类Buffered Writer
高效操作文件的字符输出流
- finally:
finally{ }部分的代码是无论是否发生异常一定执行
我们常在finally中添加一些必须执行的操作,比如关流。关流有顺序的,如果有多个流需要关闭,最后创建的流是最先关闭的,输入流、输出流关流操作不可以在一块,如果前面的关流失败则后面的将不会执行关流,所以多条关流语句需要各自try-catch。
- IO流常用通用的方法:
1. read(): 读取代码,输入流的常用通用方法,一次只能读取一个字节,并且这个返回值类型是int,会到Acsii码表中读取对应编码,比如读到字符a,控制台会打印97,如果没有数据了会返回-1,如果要优化读取代码可使用循环结构,每次运行都是读取下一个,需定义变量来保存读到的数据。
2. write():写入代码,输出流的常用通用方法。
3. close():关闭此输出流并释放与此流有关的所有系统资源。配合关键字finally来关流,通常为finally { try{ 对象.close() } catch (IOException e) { e.printStackTrace(); } },此过程必定执行,无论前面使用流是否发生异常。
- 使用IO流复制文件
本案例为字符类型文件复制,字节型输入输出流与此结构相同,字符型输入输出流常用于处理纯文本数据,读写容易出现乱码的现象,在读写时,最好指定编码集为UTF-8,只能复制字符内容,不可复制图片、音频等;字节型输入输出流比较常用的,可以可以处理多种不同种类的文件,比如文本文档/音频/视频等等。
- 序列化与反序列化
特点: 可以传输对象。
6.1 序列化objectoutputstream
将对象从堆内存写入到磁盘
概念:指的是把程序中的java对象通过序列化流oos输出到磁盘的文件中,相当于数据写出的过程。
方向是Out 使用的流是objectoutputstream
使用方法是out.writeObject(目标对象)
注意:如果一个类的对象想要被序列化,那么这个类必须实现Serializable接口
6.2 反序列化objectinputstream
将对象从磁盘读取到堆内存
概念:指的是吧之前已经保存到文件中的对象的相关数据,通过反序列化Ois流读取到内存的程序中,相当于数据的读取的过程。
方向是in,使用的流是objectinputstream
使用的方法是in.readObject();
注意:反序列化指定的文件路径必须与序列化的路径一致
注意:一次序列化操作对应一次反序列化,或者UID必须保持一致,如果不一致,会报错。
6.3序列化与反序列化的条件:
1.如果本类想要被序列化,必须实现一个可序列化的接口Serializable(Serializable是一个空接口),否则报错,实现这个接口相当于给Student一个标记,标记这个类的对象可以序列化。
2.反序列化UID必须与序列化时保存到文件中的UID保持一致,如果不一致,反序列化会失败,所以一般情况下,每次反序列化之前进行一次序列化,这样就不会错了
3.注意:如果一次序列化后,Student类未做更改,则多次反序列化也可以,只要Student发生改动(不包括注释),UID的值就会改变。
4.如果想让UID固定不变,则我们可以把它设置成固定值: private static final long serialVersionUID=1L;
5.序列化与反序列化成对出现:文件路径一致,UID一致。
- 编码转换流
7.1作用:这个流可以设置输入输出数据的编码类型,通过设置编码准确读取,存储文件内容。
输入流编码如果跟源文件内容编码不一致会乱码
7.2编码输出流:OutputStreamWriter o=null;
o = new OutputStreamWrite(new FileOutputStream (文件路径),文件编码类型)
7.3编码输入流:InputStreamReader I = null;
I = new InputStreamReader(new FileInputStream(文件路径),文件编码类型)
7.4将编码输入流以汉字打印到控制台:
int a = i.read(c); //将读取到的内容存到C数组中。
System.out.println( new String(声明的数组C, 数组偏移量0,数组读取的长度a));
十一.file类:
1.1 file类常用方法
1.1.1 创建新对象:
File file = new File("E:\\自有文件夹\\ready\\1.txt"); 参数为String类型路径名,创建file新对象在内存中保存参数列表文件。
System.out.println(file.length()); //输出内存中保存的对象的字节长度。
System.out.println(file.canExecute());//判断文件是否可执行
System.out.println(file.exists());//判断文件是否存在
System.out.println(file.isDirectory());//判断是否为文件夹
System.out.println(file.getName());//获取文件名
System.out.println(file.getParent());//获取父级路径
System.out.println(file.getAbsolutePath());//获取带盘符的完整路径,绝对路径
System.out.println(file.getAbsoluteFile());//获取带盘符的完整文件名
1.1.2创建新对象再新建文件:
1、file=new File("E:\\自有文件夹\\ready\\2.txt");
//只会在Java内存中创建一个File类型对象,不会创建真实的文件。
2、System.out.println(file.createNewFile());
//file对象的createNewFile()方法调用内存可以创建文件。
3、 file=new File("E:\\自有文件夹\\ready\\m");
//1.新建对象到内存
4、 System.out.println(file.mkdir());//file对象的mkdir()可以创建单层文件的文件夹路径 //2.该方法让内存中的新建对象输出执行
5、 file=new File("E:\\自有文件夹\\ready\\m\\a\\b\\c");
System.out.println(file.mkdirs());
//file对象的mkdirs()可以创建多层文件夹的文件夹路径
6、 System.out.println(file.delete());
//可删除最后一层的文件或者空文件夹,不能删除含文件或者含文件夹的文件夹。
7、 file=new File("E:\\自有文件夹\\ready") ; //测试展示文件列表
String[] list=file.list();
//新建list 用来装file.list()提供的数组
8、 System.out.println(Arrays.toString(list));
// System.out.println(list[0].isDirectory());
//判断是否为文件夹时出错,因为String类型没有isDirectory()方法
9、 File[] fs=file.listFiles();
System.out.println(fs[0].isDirectory());
//判断是否为文件夹,File[]有isDirectory()方法
十二.泛型
1.作用:
1.1模拟数组的数据类型检查,把报错的时机提前,只要元素的类型不匹配,在编译期就报错,而不是运行代码时才报错,向集合中添加元素时,也会自动执行类型检查。
1.2在集合中引入泛型的概念,泛型通常与集合一起使用,利用泛型约束集合中元素的类型。
1.3泛型可以实现更加通用高级的代码,使用E表示元素类型是Element类型,可以把这个理解成神似多态,不管传入什么类型,都可以匹配的上。
1.4 泛型只在编译时生效,编译通过以后,说明符合语法,泛型就会被抛弃,字节码文件中没有泛型。
2.泛型使用要求:
2.1 在方法上使用泛型,必须在两处同时出现:一个是方法的参数列表中的参数类型,一个是返回值前的泛型类型<E>表示这是一个泛型方法。
2.2 <E>泛型中E需要根据集合中存入的元素类型做决定,但是E必须是引用类型,不能是基本类型,所以8大基本类型的泛型,应该使用其对应的包装类型。
3.泛型在foreach方法中的应用:
public <E> void print( E[ ] a ){
for ( E e : a ){
System.out.print( e );
}
}
Foreach循环的结构解释:
for(1 2 : 3){ 循环体 }
* 3:要遍历的数据 1:本轮循环的数据类型 2:遍历到的数据名随便起
* 好处:语法简单,效率高
* 坏处:不能按下标遍历,只能从头到尾遍历
十三.集合
1.集合关系:

2.常用集合关系
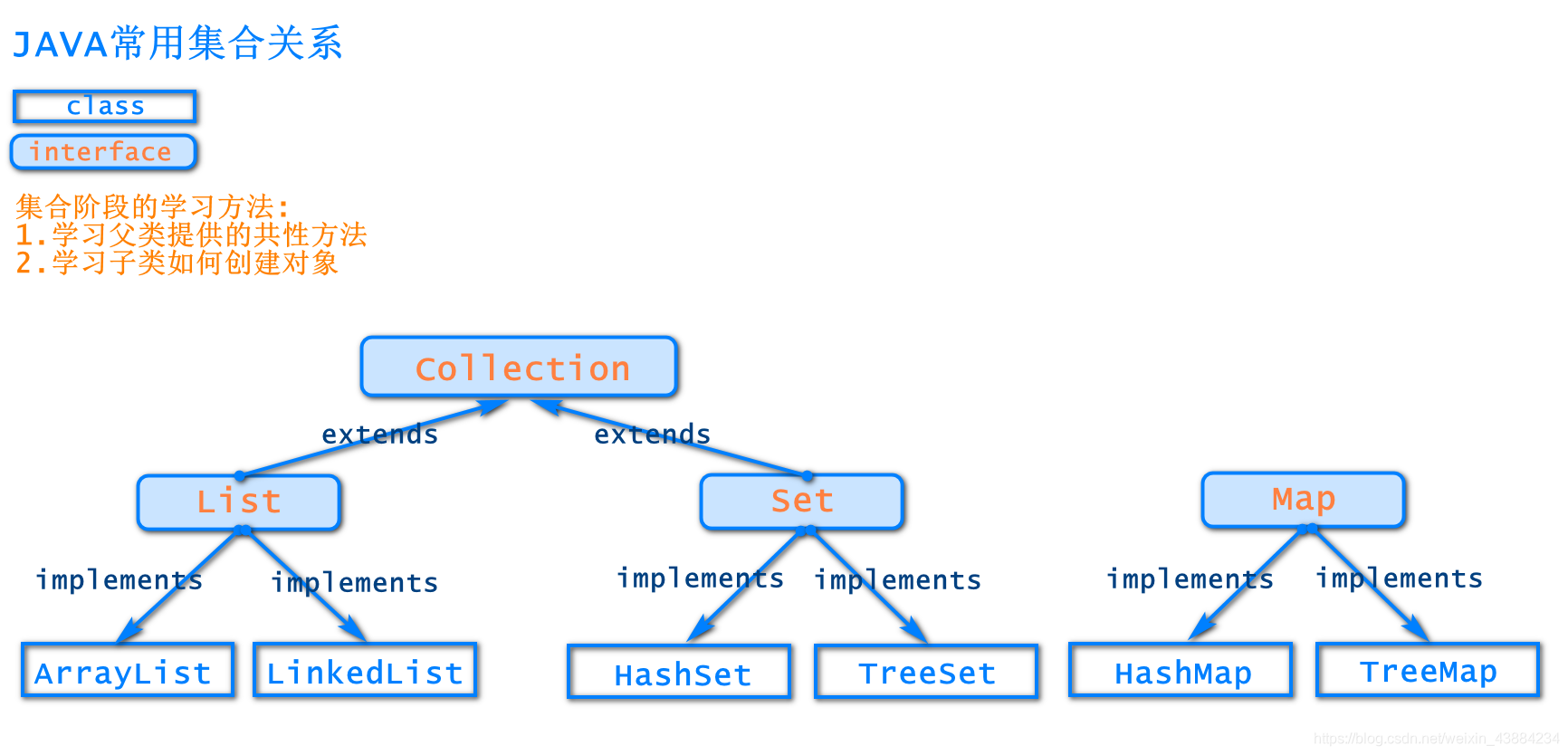
3.Collection接口
3.1概念
集合的英文名称是Collection,是用来存放对象的数据结构,而且长度可变,可以存放不同类型的对象,并且还提供了一组操作成批对象的方法.Collection接口层次结构 中的根接口,接口不能直接使用,但是该接口提供了添加元素/删除元素/管理元素的父接口公共方法.
由于List接口与Set接口都继承了Collection接口,因此这些方法对于List集合和Set集合是通用的.
3.2集合的创建:
创建引用collection的相关对象:
Collection<Integer> c=new ArrayList<Integer>();//如果要加泛型引用类型后面必须加,新建对象类型后面可加可不加。
3.4常用方法:
System.out.println(c.hashCode());//输出哈希码值
System.out.println(c.toString());//集合输出数组
System.out.println(c.equals(200));//不能哪集合对象和某个对象对比
System.out.println(c.isEmpty());//集合是否为空
System.out.println(c.contains(200));//判断集合是否有200
System.out.println(c.remove(400));//移除集合中的指定元素
System.out.println(c.size());//获取集合的长度或者说是元素个数
Object[] array=c.toArray();//将集合转为数组
(测试集合间的操作)
c.addAll(c2);//将c2集合中的所有元素添加到c中,c2集合不受影响
System.out.println(c);
System.out.println(c.contains(c2));//无法判断c2是否被包含于c,不同于c.containsAll(c2)
System.out.println(c.containsAll(c2));//判断c2中所有元素是否都被包含在C中
// System.out.println(c.removeAll(c2));//删除c集合中所有c2的元素
System.out.println(c.remove(c2));//无法删除c2中的元素不同于c.removeAll(c2)
System.out.println(c.retainAll(c2));//保留C、C2的公共元素,只要有就保留
3.2子接口List :数据有下标,有序,可重复
3.2. 1 List接口实现类ArrayList:底层数据结构为数组,内存空间是连续的。
1.元素有下标、有序。
2.允许存放重复的元素。
3.在数据量较大的情况下,增删慢,查询快。
3.2. 2 List接口实现类LinkedList:底层结构为链表,内存空间是不连续的
1.元素有下标、有序
2.允许存放重复的元素。
3.在数据量较大的情况下,增删快,查询慢。
3.3子接口set: 数据无下标,无序,不可重复
3.3.1 set概述
1.数据无序且数据不允许重复
2.HashSet : 底层是哈希表,包装了HashMap,相当于向HashSet中存入数据时,会把数据作为K,存入内部的HashMap中。当然K仍然不许重复。
3.TreeSet : 底层是TreeMap,也是红黑树的形式,便于查找数据
3.3. 2 set接口实现类HashSet:底层结构为Map
底层是哈希表,包装了HashMap,相当于向HashSet中存入数据时,会把数据作为K存入内部的HashMap中,其中K不允许重复,允许使用null.
4.Map 接口【键值对的方式存数据】
将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。
4.1HashMap子类
前言:HashMap的键用来同时重写hashCode()和equlas()
hashCode()用来判定二者的hash值是否相同,重写后根据属性生成。
equlas()用来判断属性的值是否相同,重写后,根据属性判断
–equlas()判断KEY数据如果相等,hashCode()必须相同
–equlas()判断KEY数据如果不等,hashCode()尽量不同
概述:1.此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
2. HashMap底层为Entry[K,V ]数组,是数组加链表的结构,通过哈希码值计算(hash(key)%n n为数组的长度) 获取余数,根据余数在数组上排位,余数一样的在链上延伸,当链超过8时转换成红黑树,但只有当红黑树数据减少到6以内才会重新变成成链。
3.原数组长度16,余数在数组上排位超过默认加载因子(0.75),则进行扩容,扩容标准为原来两倍

十四. 进程
1.概念:
正在运行的程序集合(软件或者项目),是系统进行资源分配和调用的独立单位,每个进程都有他的内存空间和系统资源。
一个进程可以包含多个线程,但是一个进程也可以包含一个线程,称为单线程程序。
在宏观上,一个CPU看似可以同时处理多件事。
在微观上,一个CPU同一时刻只能处理一件事。
结论:线程的执行具有随机性,除了系统开发人员,其他人无法控制,是由OS底层的算法决定的。
名词解释:
进程:运行中的程序是动态的。
线程:是OS能够运行调度的最小单位。
CPU:电脑核心处理器,类似于人的大脑。
2.特征:
2.1 独立性:
进程是系统中独立存在的实体,它可以拥有自己独立的资源,每个进程都拥有自己私有的地址空间,在没有经过进程本身允许的情况下,一个用户进程不可以直接访问其他进程的地址空间
2.2动态性:
进程与程序的区别在于,程序只是一个静态的指令集合,而进程是一个正在系统中活动的指令集合,程序加入了时间的概念以后,称为进程,具有自己的生命周期和各种不同的状态,这些概念都是程序所不具备的.
2.3并发性:
多个进程可以在单个处理器CPU上并发执行,多个进程之间不会互相影响,区别于并行性(多个进程在多个CPU上并行执行),和串行(一个CPU同一时刻只能处理一个进程).
3.线程
一个操作系统中可以有多个进程,一个进程中可以包含一个线程(单线程程序),也可以包含多个线程(多线程程序)
每个线程在共享同一个进程中的内存的同时,又有自己独立的内存空间,所以想使用线程技术,得先有进程,进程的创建是OS操作系统来创建的,一般都是C或者C++完成
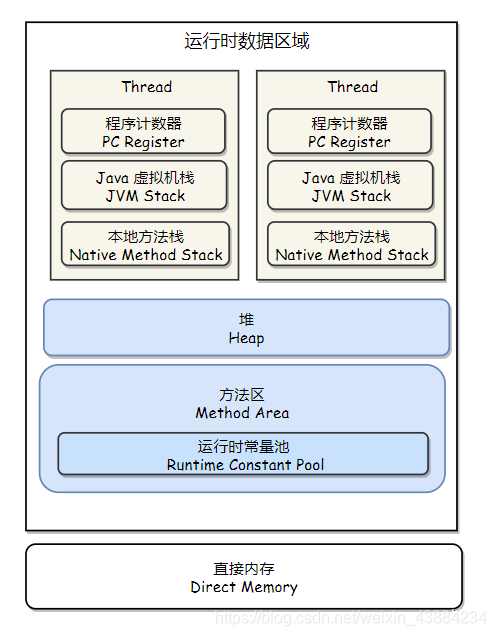 线程的内存空间
线程的内存空间
关键字:
父类Thread: Thread类本质上是实现了Runnable接口的一个实例,
Thread实现了Runnable的run()方法,自带start()、getname()、
currentThread()、sleep()、stop()、yield()、toString()等方法
start(): 使该线程开始执行;然后Java 虚拟机调用该线程的 run 方法。
run(): Runnable的抽象方法,需要实现或继承Thread类后重写。
currentThread():Thread类的静态方法,使用Runnable创建线程时可在实现类内使用Thread类名调用,并通过它使用getname()。
父接口Runnable:包含一个抽象的run()方法。用于创建多线程。
3.1 多线程:
3.1.1CPU分时调度
时间片,即CPU分配给各个线程的一个时间段,称作它的时间片,即该线程被允许运行的时间,如果在时间片用完时线程还在执行,那CPU将被剥夺并分配给另一个线程,将当前线程挂起,如果线程在时间片用完之前阻塞或结束,则CPU当即进行切换,从而避免CPU资源浪费,当再次切换到之前挂起的线程,恢复现场,继续执行。
注意:我们无法控制OS选择执行哪些线程,OS底层有自己规则,如:
FCFS(First Come First Service 先来先服务算法)
SJS(Short Job Service短服务算法)
3.1.2线程的状态
三态模型:
1.就绪(可运行)状态:线程已经准备好运行,只要获得CPU,就可立即执行
2.执行(运行)状态:线程已经获得CPU,其程序正在运行的状态
3.阻塞状态:正在运行的线程由于某些事件(I/O请求等)暂时无法执行的状态,即线程执行阻塞
五态模型:
除了就绪,执行,阻塞再加上:
4.创建状态:线程的创建比较复杂,需要先申请PCB,然后为该线程运行分配必须的资源,并将该线程转为就绪状态插入到就绪队列中
5.终止状态:等待OS进行善后处理,最后将PCB清零,并将PCB返回给系统
(PCB(Process Control Block):为了保证参与并发执行的每个线程都能独立运行,OS配置了特有的数据结构PCB来描述线程的基本情况和活动过程,进而控制和管理线程)
3.1.3线程状态与代码对照(七态模型)
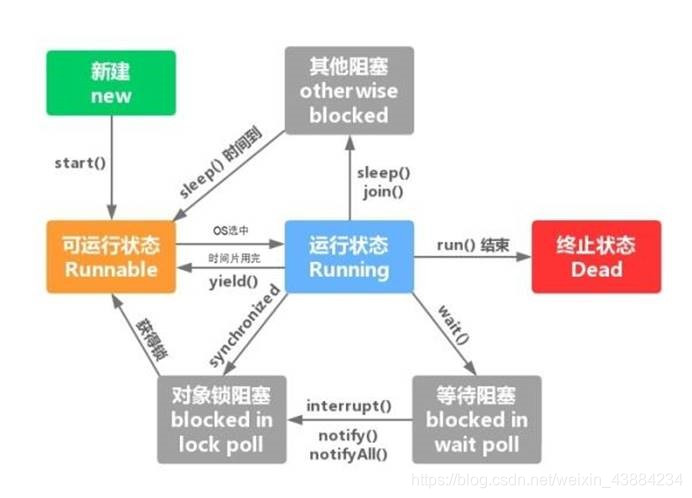
1.新建状态(New) : 当线程对象创建后就进入了新建状态.如:Thread t = new MyThread();
2.就绪状态(Runnable):当调用线程对象的start()方法,线程即为进入就绪状态.,就绪状态是进入运行状态的唯一入口。
处于就绪(可运行)状态的线程,只是说明线程已经做好准备,随时等待CPU调度执行,并不是执行了t.start()此线程立即就会执行
3.运行状态(Running): 操作系统执行run()。
4.阻塞状态(Blocked):处于运状态中的线程由于某种原因,暂时放弃对CPU的使用权,停止执行,此时进入阻塞状态,直到其进入就绪状态才有机会被CPU选中再次执行.
阻塞状态分三种:
等待阻塞:运行状态中的线程执行wait()方法,本线程进入到等待阻塞状态
同步阻塞:线程在获取synchronized同步锁失败(因为锁被其他线程占用)
其他阻塞:调用线程的sleep()或者join()或发出了I/O请求时,线程会进入到阻塞状态.当sleep()状态超时.join()等待线程终止或者超时或者I/O处理完毕时线程重新转入就绪状态
5.死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期
3.2创建方法一:继承Thread
1.自定义多线程类继承Thread:
2.重写run()方法:方法内是我们的业务(.super.run();表示的是调用的父类的业务,我们需要创建自己的业务所以需要注释掉)
3.创建多个线程对象:
new一个对象想当于线程的新建状态,要模拟多线程要启动至少一个,如果只有一个相当于单线程,
4.线程对象调用start()以多线程的方式启动:
1.start()对应的就是就绪状态,会吧刚刚新建号的线程加入到就绪队列中,至于什么时候执行,就是多线程执行的效果,需要等待OS选中分配CPU(抢占CPU)
2.run()如果直接调用,是没有多线程抢占执行效果的,只是把这两句话当做
普通方法的调用,谁先写谁先执行。
3. 执行的时候start()底层会自动调用我们重写的run()方法中的业务。
4. 线程的执行具有随机性,也就是说各个Start()具体怎么执行取决于CPU的调度时间片的分配,我们是决定不了的。
5继承Thread创建多线程的缺点
继承Thread的创建多线程的方法涉及到继承只能单继承,继承了Thread,就
不能再继承其他类。
3.3创建方法二:实现Runnable接口
1.自定义多线程类实现Runnable接口:
2.实现run()方法:创建线程运行入口。
3.创建实现了Runnable接口的对象:将对象作为参数创建新Thread对象,调用start(),
启动 多个启动入口。
4. 优点: 自定义的线程类只是实现了Runnable接口或Callable接口,后续还可以继承其他类,在这种方式下,多个线程可以共享同一个业务(运行任务)
缺点: 编程稍微复杂,如想访问当前线程,则需使用Thread.currentThread()方法
3.4创建方法三:实现Callable接口
重写call()方法,然后包装成java.util.concurrent.FutureTask, 再然后包装成Thread
-
- 创建方法四:线程池(Executors)
3.5.1关键字:Executors:用来辅助创建线程池的工具类
3.5.2常用的方法是newFixedThreadPool(int):
这个方法可以帮我们创建不超过指定数目线程的线程池ExecutorService pool=Executors.newFixedThreadPool(50);
3.5.3使用循环启动线程for (int i = 0; i <50 ; i++) { pool.execute(tickets) ; }
execute():让线程池中的线程来执行业务,每次调用这个方法,都会将一个线程加到就绪队列中,类似于start()
这个方法的参数,就是我们要执行的具体业务,也就是目标业务对象target(我的是tickets) //新建业务对象TicketRunnable2 tickets=new TicketRunnable2();
要给池中分配同一个目标业务对象,所以多线程业务类使用Runnable 不使用Thread,因为Thread每个线程需要创建新的业务对象
3.6线程安全:
3.6.1关键字:同步、异步、synchronized(同步锁)
同步:体现了排队的效果,同一时刻只能有一个线程独占资源,其他没有权利的线程排队。效率低,安全性高。
异步:体现了多线程抢占资源的效果,线程间互相不等待,互相抢占资源。
效率高,安全性低。
Synchronized:同步锁,当多个对象操作共享数据时,可以使用同步锁解决线程安全问题,被锁住的代码就是同步的。
synchronized (锁对象){需要同步的代码(也就是可能出现问题的操作共享数据的多条语句);}
3.6.2 判断:
判断程序有无可能出现线程安全问题三个判断条件:
1.在多线程程序中
2.有共享数据
3.多条语句操作共享数据
3.6.3 解决:使用同步锁Synchronized
同步需要两个或者两个以上的线程(单线程无需考虑多线程安全问题)
多个线程间必须使用同一个锁,为了提高安全性最好再使用其他方法进行校验。
3.6.4 同步锁Synchronized特点:
1.可以用来修饰代码块,称为同步代码块,使用的锁对象类型任意,但注意:必须唯一!
2. 可以用来修饰方法,称为同步方法。
3. 缺点:降低程序。
4. 为了性能,加锁范围需要控制。
十五. 注解
1.JDK自带注解:
@Override:重写的方法
@Deprecated:标记就表明这个方法已经过时了,但我就要用,别提示我过期
@SuppressWarnings(“deprecation”): 忽略警告
@SafeVarargs : jdk1.7出现,堆污染,不常用
@FunctionallInterface : jdk1.8出现,配合函数式编程拉姆达表达式,不常用
2.元注解:用来描述注解的注解
@Target : 规定注解用在哪里:类上、方法上、属性上等等
@Retention :规定注解的生命周期:源文件中、字节码文件中、运行中
3.自定义注解:
3.1创建注解的格式: @interface 注解名{ 可添加属性:赋值普通属性或未赋值属性,赋值的特殊属性或未赋值的特殊属性 }
3.2注解中的普通属性:
未赋值的普通属性:int age();使用注解时必须给属性赋值如@Rice(age=10)
赋值的普通属性:int age() default 7; 创建注解赋值后,使用时可不用再赋值
3.3注解中的特殊属性:
特殊属性名必须叫value,
未赋值的特殊属性:String value();使用时必须赋值如@Rice("Apple")
赋值的特殊属性 String value( ) default "Apple1"; 使用时可不用再赋值
如果需要给注释所有属性赋值,则即使是特殊属性也不能简写@Rice(age =10,value="APPLE")
3.4创建注解的步骤:
1. 创建注解主体@interface注解名{ }
2. 在主体上方加@Target(ElementType.静态常量):规定注解用在哪里:类上、方法上、属性上等等
ElementType.TYPE 应用于类的元素
ElementType.METHOD 应用于方法级
ElementType.FIELD 应用于字段或属性(成员变量)
ElementType.ANNOTATION_TYPE 应用于注解类型
ElementType.CONSTRUCTOR 应用于构造函数
ElementType.LOCAL_VARIABLE 应用于局部变量
ElementType.PACKAGE 应用于包声明
ElementType.PARAMETER 应用于方法的参数
3. 在主体上方加@Retention(RetentionPolicy.静态常量):规定注解的生命周期:
源文件中、字节码文件中、运行中
RetentionPolicy.SOURCE 在源文件中有效(即源文件保留)
RetentionPolicy.CLASS 在class文件中有效(即class保留)
RetentionPolicy.RUNTIME 在运行时有效(即运行时保留)
4. 在主体代码块内加属性参数:普通属性或特殊属性
十六. 设计模式
1.概念
代表了最佳的实践,通常被有经验的面向对象的软件开发人员所采用。
JAVA一共有23种设计模式。
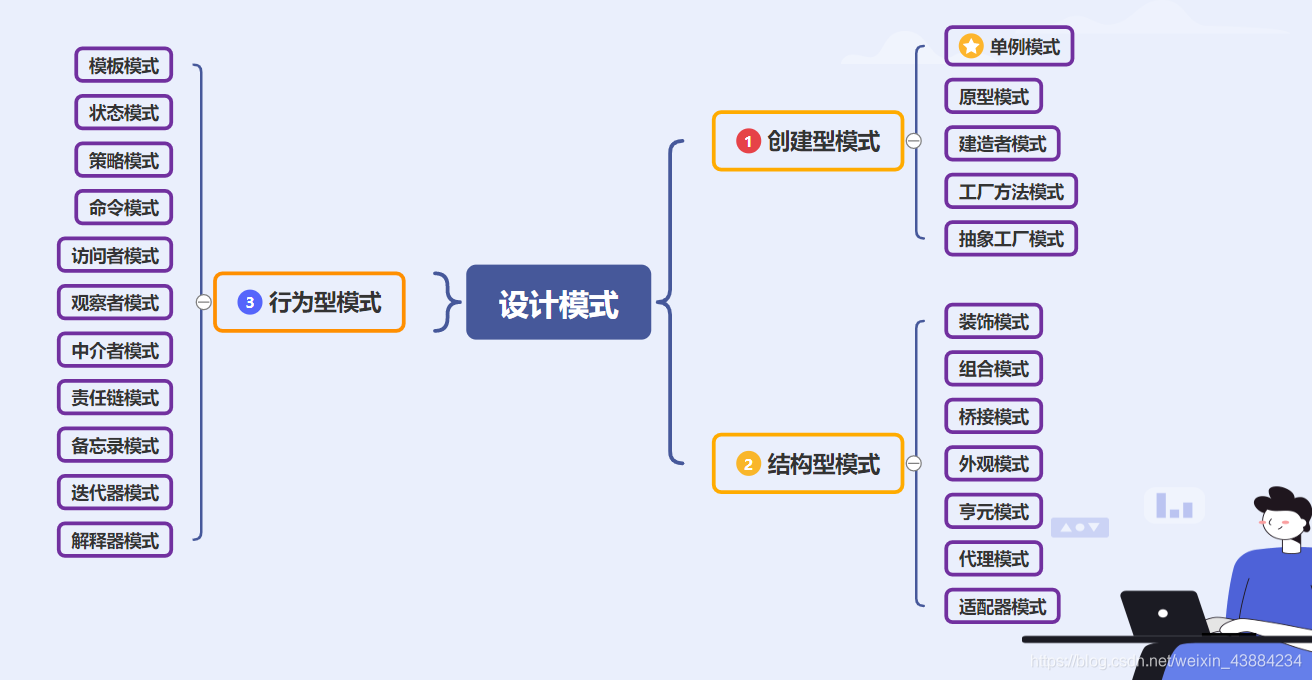
2. 例:单例模式
2.1方法一.饿汉氏:不管你用不用这个类的对象,都会直接先创建一个
1.创建自己的单例程序 (创建类)
2.构造方法私有化 (私有化构造方法是为了防止外界随意创建本类对象)
3.创建本类对象并私有化 (private static MySingle Single=new MySingle();)
4.提供公共的访问方式,返回创建好的对象(为了能直接调用本方法,需要将本方法设置为静态) (public static MySingle getSingle( ){ return Single; })
5.因为方法静态初始化,所以可以通过类名直接调用
6.有共享数据和多条语句操作数据,所以尽量提前处理,避免多线程数据安全隐患
2.2方法二.懒汉氏:先不给创建这个类的对象,等你需要的时候在在创建--延迟加载的思想
1.创建自己的单例程序
2.构造方法私有化
3.创建本类对象并私有化
4.判断之前是否创建过对象,之前创建过就直接走return
5.之前如果没有创建过,才走if,创建对象并返回
if (single2 == null) { single2 = new MySingle2();
System.out.println("第一次") ;
}else {System.out.println("有了");} return single2;
6.有共享数据和多条语句操作数据,所以尽量提前处理,避免多线程数据安全隐患
6的解决方案1:加同步代码块
6的解决方案2:将本方法getSingle2()设置为同步方法,因为本方法里所有语句都需要同步
十七. 单元测试
*使用单元测试方法:是JAVA中最小的测试单位,使用灵活,各测试单元相互不影响
* 语法要求:在方法上加@Test。方法固定格式public+void+方法名+(没有参数){ }
* 注意:使用时需要导包,ADD JUnit 4 library to the build path
* 导包后的效果:import org.junit.Test
测试单元中不同注解作用。
@Test测试主体
@befor 描述方法,方法固定格式public+void+方法名+(没有参数){ },不能是static
在@Test执行之前执行
@after public+void+方法名+(没有参数){ } 在@Test执行之后执行。
十八. 反射(Reflection)
1.是什么:
是 Java 程序开发语言的特征之一,反射非常强大,它甚至能直接操作程序的私有属性,private封装的资源只能类内部访问,外部是不行的,但这个规定被反射打破了。它可以在运行时获取一个类的所有信息,可以获取到任何定义的信息(包括成员变量,成员方法,构造器等),并且可以操纵类的字段、方法、构造器等部分。
2.为什么:
有一个框架Spring就是一个非常专业且功能强大的产品,它可以帮我们创建对象,管理对象。以后我无需手动new对象,直接从Spring提供的容器中的Beans获取即可。Beans底层其实就是一个Map<String,Object>,最终通过getBean(“user”)来获取。而这其中最核心的实现就是利用反射技术。
类不是你创建的,是你同事或者直接是第三方公司,此时你要或得这个类的底层功能调用,就需要反射技术实现。
3.怎么做:
3.1反射的前提:
获取字节码对象,引文字节码对象中有这个类所有的关键信息
3.2反射所用API:
获取字节码对象方法:
1、Class.forName(“类的全路径”)
2、类名.class
3、对象.getClass();
3.3常用方法
获取包名类名
clazz.getPackage().getName()//包名
clazz.getSimpleName()//类名
clazz.getName()//完整类名
获取成员变量定义信息
getFields()//获取所有公开的成员变量,包括继承变量
getDeclaredFields()//获取本类定义的成员变量,包括私有,但不包括继承的变量
getField(变量名)
getDeclaredField(变量名)
获取构造方法定义信息
getConstructor(参数类型列表)//获取公开的构造方法
getConstructors()//获取所有的公开的构造方法
getDeclaredConstructors()//获取所有的构造方法,包括私有
getDeclaredConstructor(int.class,String.class)
获取方法定义信息
getMethods()//获取所有可见的方法,包括继承的方法
getMethod(方法名,参数类型列表)
getDeclaredMethods()//获取本类定义的的方法,包括私有,不包括继承的方法
getDeclaredMethod(方法名,int.class,String.class)
反射新建实例
clazz.newInstance();//执行无参构造创建对象
clazz.newInstance(666,”海绵宝宝”);//执行含参构造创建对象
clazz.getConstructor(int.class,String.class)//获取构造方法
反射调用成员变量
clazz.getDeclaredField(变量名);//获取变量
clazz.setAccessible(true);//使私有成员允许访问
f.set(实例,值);//为指定实例的变量赋值,静态变量,第一参数给null
f.get(实例);//访问指定实例变量的值,静态变量,第一参数给null
反射调用成员方法
Method m = Clazz.getDeclaredMethod(方法名,参数类型列表);
m.setAccessible(true);//使私有方法允许被调用
m.invoke(实例,参数数据);//让指定实例来执行该方法
3.4暴力反射:获取私有的属性或者方法
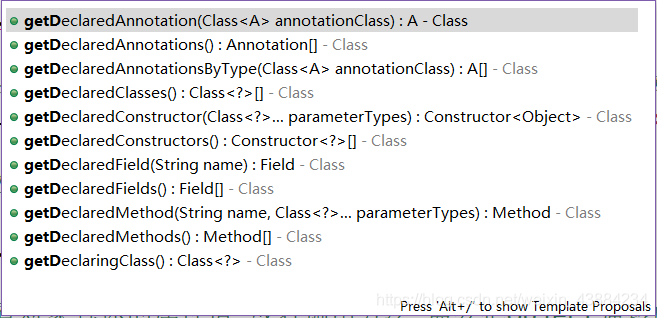
3.4.1.获取
clazz.getDeclaredField("name") 通过创建clazz字节码对象暴力获取属性,属性名叫name
clazz.getDeclaredField("age") 通过创建clazz字节码对象暴力获取属性,属性名叫age
3.4.2*修改反射对象的私有属性:
1. 使用反射获取Student对应的字节码对象Class<?> clazz = Student.class;
2. Object o = clazz.newInstance();//通过字节码对象利用反射创建新的物料类对象实例触发无参构造。
3. Field f1 = clazz.getDeclaredField("age");//暴力获取私有属性属性age
4.f1.setAccessible(true);//值为 true 则指示反射的对象f1在使用时应该取消 Java 语言访问检查。
5. f1.set(o,7); //改值:新的物料类o中的age属性值设置为7。
3.4.3*修改反射对象的私有方法:
1.获取字节码对象
2.创建新物料类对象实例
3.暴力获取私有方法:clazz.getDeclaredMethod(指定的方法, int.class方法的参数对象1, String.class方法的参数对象2);//获取某个指定的私有方法。
4. mt.setAccessible(true);取消方法mt的 Java 语言访问检查。
5. mt.invoke(物料类对象实例, 参数1, 参数2);//给方法对象传参用.invoke方法
十九.内部类
1.成员内部类
1.1成员内部类位置: 类里方法外, Class{ class{ } 外部类方法 }
1.2成员内部类相关权限:
1.外部类不能直接使用内部类资源,需要创建内部类对象,通过对象使用。
2. 内部类可以使用外部类的方法、普通属性、私有属性。
3. 无关类想要使用内部类需要创建外部类对象,通过外部类对象再创建内
部类对象:Outer.inner oi = new Outer().new inner();
通过创建好的内部类对象,使用内部类的资源。
4. 如果成员内部类被private修饰 无关类则不能再直接访问或者创建内部类对象。需要在外部类提供一个公共的方法,在方法内部创建内部类的对象,调用内部类的功能。
5. 当内部类被static修饰以后,可以通过外部类类名直接调用,不用额外创建外部类对象(创建了会报错),
6.当内部类的方法被static修饰以后,Out3.inner3.show2();//不创建任何对象,使用外部类名和内部类名调用内部类的静态方法:(链式加载)推荐。
2.局部内部类
2.1局部内部类位置:类里方法内, Class{ 外部类方法( ) { class{ } } }
2.2局部内部类相关权限:
1. 需要在外部类中创建内部类的对象,并且调用内部类的方法,才会触发内部类的功能
2. 外部类方法内,局部内部类后面才能创建局部内部类对象,调用局部内部类的功能。Class{ 外部类方法( ) { class{ } new class } }。
其他方式使用局部内部类的资源都不可行。
3.匿名内部类
3.1匿名内部类位置: 创建匿名对象:new 类名或接口名( ){ } { }为匿名内部类。
3.2匿名内部类优点:
new 接口名(){ 实现接口内的抽象方法 }.方法;
new 抽象类名(){ 实现抽象类内的抽象方法 }.方法;
匿名内部类其实就充当了实现类的角色,去实现未实现的抽象方法,只是没有名字而已,省去创建实现类的过程。
3.3匿名内部类缺点:
如果要想多次使用实现后的功能,还是要创建普通对象,匿名对象只能使用一次,一次只能调用一个功能。
二十.日期类Date
1. Date日期类
类 Date 表示一个特定的瞬间,精确到毫秒
1.1 Date的构造函数
Date() 分配一个 Date 对象,以表示分配它的时间(精确到毫秒)
Date(long date) 分配一个 Date 对象,表示自从标准基准时间起指定时间的毫秒数
标准基准时间:称为“历元(epoch)”,即 1970 年 1 月 1 日 00:00:00
1.2 Date的构造函数练习
Date d2=new Date(t);//从标准基础时间往后加传入的t毫秒的时间
Date d1=new Date();
System.out.println(d1);//获取当下时间Fri Sep 24 17:03:39 CST 2021
1.3 Date的常用方法练习
getTime() 返回自 1970 年 1 月 1 日 00:00:00 GMT 以来此 Date 对象表示的毫秒值
setTime(long time) 设置时间,表示 1970 年 1 月 1 日 00:00:00 GMT 后的毫秒值
1.4日期转换类simpleDateFormat
1. SimpleDateFormat sdf=new SimpleDateFormat();
String f = sdf.format(d1);//转换日期格式为字符串类型的默认格式输出
2. Date转String
SimpleDateFormat sdf2=new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");//设置时间显示格式。
String f1=sdf2.format(d1);//输出为设置后的
3. String转Date
String s="2021-09-20 05:31:17";
SimpleDateFormat sdf3=new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");//解析String类型日期格式要和之前设置的时间显示格式一致,否则使用之前设置的String格式输出的时间再转为Date容易解析错误。
Date p = sdf3.parse(s);
二十一. Linux系统介绍 参见Linux笔记
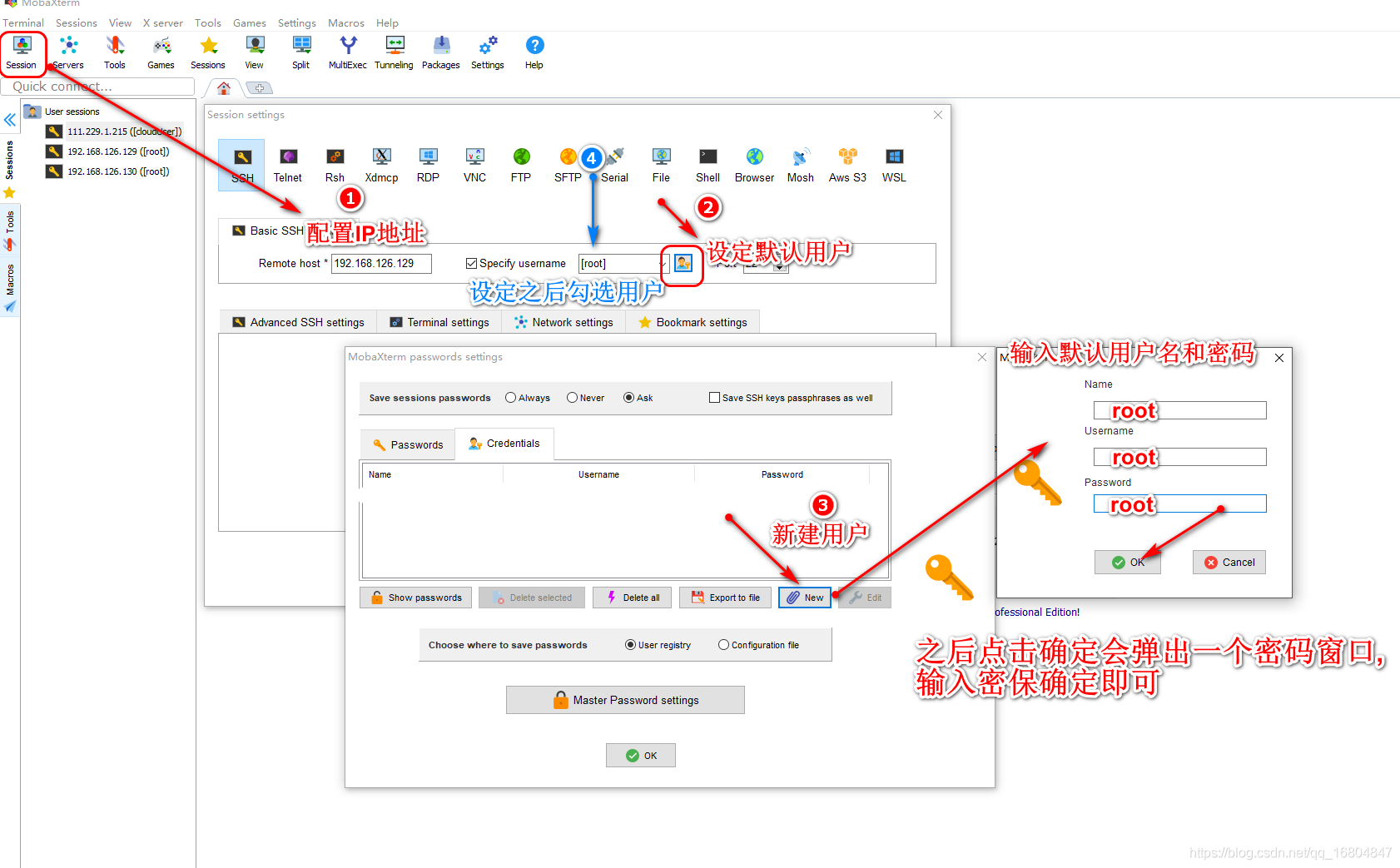
二十二.远程连接
1 远程链接工具下载
1.1 网址
URL: https://mobaxterm.mobatek.net/download.html
二十三.Nginx
1.概念:
是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务。
2特点:
2.1 占用内存少:不超过2M,而tomacat为200M
2.2 并发能力强:理论5万每秒,而tomacat为220-260个每秒,调优后最多1000个每秒。
2.3 nginx由C语言开发,tomacat为java语言开发
3 代理机制
3.1 用户通过网络地址访问服务器
3.2 通过某种机制(Nginx和tomcat)转为本地磁盘地址http://image.lin.com>E:/third/pictures
3.3 根据磁盘地址信息找到图片,回传给用户。
4 反向代理
4.1
反向代理服务器位于用户与目标服务器之间,但是对于用户而言,反向代理服务器就相当于目标服务器,即用户直接访问反向代理服务器就可以获得目标服务器的资源。同时,用户不需要知道目标服务器的地址,也无须在用户端作任何设定。反向代理服务器通常可用来作为Web加速,即使用反向代理作为Web服务器的前置机来降低网络和服务器的负载,提高访问效率。我不知道目标资源IP地址,但是代理知道,由代理去访问
特点:
1. 反向代理服务器介于用户和目标服务器之间
2. 用户的资源从反向代理服务器中获取.
3. 用户不清楚真实的服务器到底是谁. 保护了服务器的信息. 称之为服务器端代理.
5 正向代理
5.1
正向代理,意思是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端才能使用正向代理。
我知道目标资源IP地址,但是无法直接访问,由代理去访问,或由代理去访问他的代理
特点:
1. 反向代理服务器介于用户和目标服务器之间
2. 用户的资源从正向代理服务器中获取.
3. 客户端通过正向代理服务器,指向目标服务器.(用户非常清楚的了解目标服务器的存在.) 服务器端不清楚到底是谁访问的服务器.以为只是代理服务器访问.
6 Nginx安装和使用
6.1安装:下载后免安装,解压后直接使用
6.2 解压位置:
1. 路径不能有中文路径
2. 占用80端口,故80端口不能被其他应用占用
3. 程序不能存放于C盘路径下。
6.3 测试:http://localhost:80 80可省略因为http协议默认为80,https默认为443
6.4 进程说明:主进程内存大,主要提供反向代理服务,守护进程小,主要防止主进程意外关闭
6.5 使用:DOS指令
启动nginx: start nginx
重启nginx: nginx -s reload
关闭nginx: nginx -s stop
7 Nginx反向代理案例
7.1关键字:
envent:配置工作环境
worker_connections 1024; //最大同时处理容量,可手动设置,每次倍增。
http: 请求协议(不可使用TCP/IPV4/IPV6 ; 而https需要手动开启)
可接受http请求的规则,有且只有一份。
server: 每个反向代理服务都是一个server
listen: nginx中一般监听的是80端口
server_name: nginx拦截url中哪个请求
location: 进行拦截服务后,开始反向代理配置的核心关键字。
/ :斜杠代表需要拦截的斜杠后面的请求的路径,可以有多个location/{ }请求
root: 代表反向代理的是一个文件夹。
index:反向代理时默认加载的页面。
7.2 nginx.conf配置文件解释:
server { #反向代理开始
listen 80; #监听端口
server_name localhost; #拦截的域名
location / { #{拦截所有的{}中的请求路径(目标硬盘路径) } /后面为根目录
root html; #表明代理的是一个目录,这里添硬盘路径
index index.html index.htm; #默认访问的页面是。。。。
}
}
7.3 hosts作用
Hosts是一个没有扩展名的系统文件,可以用记事本等工具打开,其作用就是将一些常用的网址域名与其对应的IP地址建立一个关联“数据库”,当用户在浏览器中输入一个需要登录的网址时,系统会首先自动从Hosts文件中寻找对应的IP地址,一旦找到,系统会立即打开对应网页,如果没有找到,则系统会再将网址提交DNS域名解析服务器进行IP地址的解析。通过hosts文件访问对应IP地址,则不用再通过DNS域名解析服务器访问。
7.4 进行C:\Windows\System32\drivers\etc \hosts文件配置
127.0.0.1 localhost #服务器
127.0.0.1 image.lin.com #图片服务器
127.0.0.1 manage.lin.com #后台服务器
127.0.0.1 www.lin.com #前端服务器
7.5 hosts文件配置失败说明
1. 如果属性为只读,需要去掉
2. 开放所有用户的权限,权限配置勾选所有允许权限
7.6 nginx.conf域名实现后端访问
server {
listen 80;
server_name manage.lin.com;
location / {
proxy_pass http://localhost:8091;
}
}
7.7 nginx.conf域名实现图像库访问
server {
listen 80;
server_name image.lin.com;
location / {
root E:/third/pictures;
}
}
7.8 nginx.conf域名实现前端访问//当项目打包后,成为静态资源文件,不再使用8080端口
server {
listen 80;
server_name www.lin.com;
location / {
proxy_pass http://localhost:8080;
}
}
8.负载均衡:反向代理将域名访问均衡分发至多个服务器。
8.1动态获取当前服务器端口号
@RestController //扫描本类获取YML配置文件信息
@CrossOrigin
public class PortController {
@Value("${server.port}") //插值表达式插入端口号
private Integer port;
public String getPort(){
return "当前端口号:"+port;
}
}
8.2开启多台tomcat服务器,提供多个端口(不能开启热部署)
8.3负载均衡配置
8.3.1轮询机制:
配置nginx.conf文件,将代理的目标地址替换成动态的服务器集群。
8.3.2轮询机制+权重机制:
配置nginx.conf文件
#nginx本地访问服务器可直接使用127.0.0.1 或localhost
#nginx远程访问服务器需要使用具体IP地址
8.3.3 IPHASH策略(用户和tomcat服务器绑定)
作用:解决负载均衡时,用户每次访问不同服务器,获取的服务和数据不同的问题。
机理:用户访问服务器时,Nginx对其进行(Iphash%服务器数)计算,计算结果唯一。
配置:配置nginx.conf文件,集群中加入ip_hash代码,此时轮询机制+权重机制对来自同一个IP地址的用户失效,相同IP地址的用户只能访问同一台服务器。
优点:用户下次访问服务时,数据不会丢失。如在线考试掉线后,下次登录可继续作答。
缺点:首先如果服务器宕机,用户则不可再使用服务,其次因为hash计算自身正态分布的特质,某些服务器会被分配过多用户。
8.3.4 如果后端服务器宕机,nginx依然会访问故障机如何解决
配置nginx.conf文件:
down关键字:端口号后加down ,标识该服务器(端口)下线不提供服务。
backup关键字:端口号后加backup ,标识该服务器(端口)下线不主动提供服务,除非其他主机全部下线或负载过大。
8.3.5 在线部署:
步骤:
1.将涉及部署的策略
2.通过DOWN属性标识服务器下线
3.部署新的项目,启动测试
4.重复执行上述步骤操作其他服务器
5.上述步骤一般可通过脚本文件执行。
8.3.6 tomcat高可用
配置nginx.conf文件:
设置max_fails=1: 最大失败次数
设置fail_timeout=60s:达到最大失败次数后60秒内不再访问
9. nginx的前端项目发布
9.1修改前端JS
9.1.1修改前端AJAX默认请求URL
当前前端访问模式为AJAX的:axios.defaults.baseURL = 'http://localhost:8091/'
修改当前前端AJAX的访问模式:axios.defaults.baseURL = 'http://manage.lin.com/'
修改后manage.lin.com可通过nginx访问多个端口对应的多个服务器,实现负载均衡。
9.1.2修改前端文件上传的路径
9.2前端项目部署
9.2.1前端发布说明
前端包含文件 html/css/js 是静态资源. 将前端项目按照静态资源的方式打成文件目录. 之后通过nginx实现反向代理.实现前端项目的发布.
9.2.2前端项目打包:生成dist文件
vue 脚手架可视化客户端中以built(编译并压缩(用于生产环境))方式运行。
效果: 如果编译成功,则会在jtadmin的目录下,生成dist目录信息. dist就是编译之后的前端项目.
9.2.3前端项目发布
1.导入前端文件:将打包的文件导入到nginx文件夹下(部署在nginx内部).
2.配置nginx.conf文件实现反向代理:
server {
listen 80;
server_name www.lin.com;
location / {
root dist;
index index.html;
}
}
















 4468
4468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









