







背景介绍
设计初衷
作为用户推荐系统的支撑系统之一:用户实时特征系统有着举足轻重的重要,甚至说它是一起推荐行为触发的必要条件。而实时特征系统价值除了为实时推荐获取用户特征提供基础能力,对离线数据训练模型也起到关键支撑。
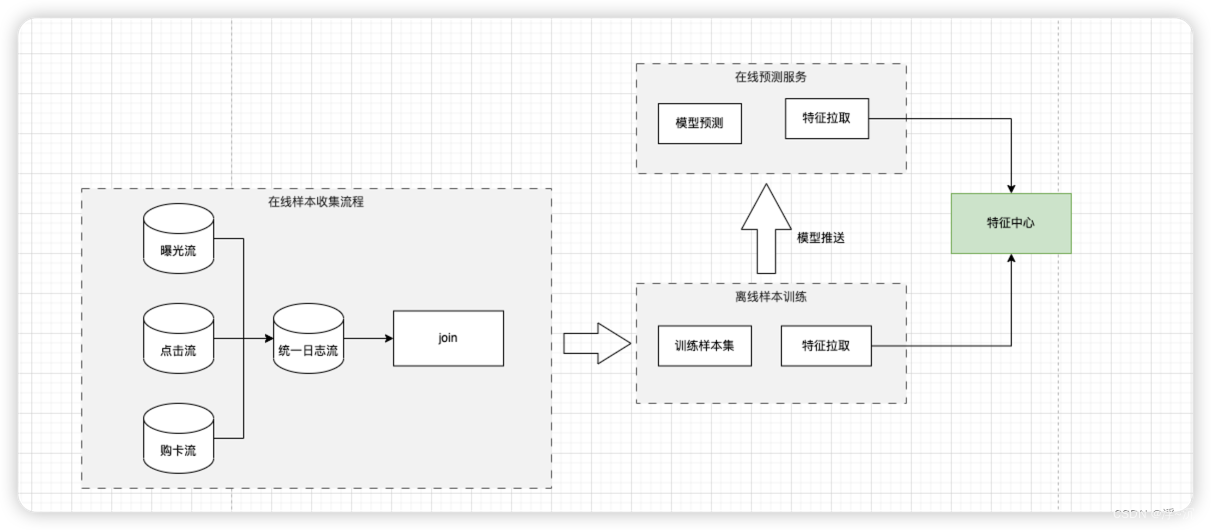
离线训练流程
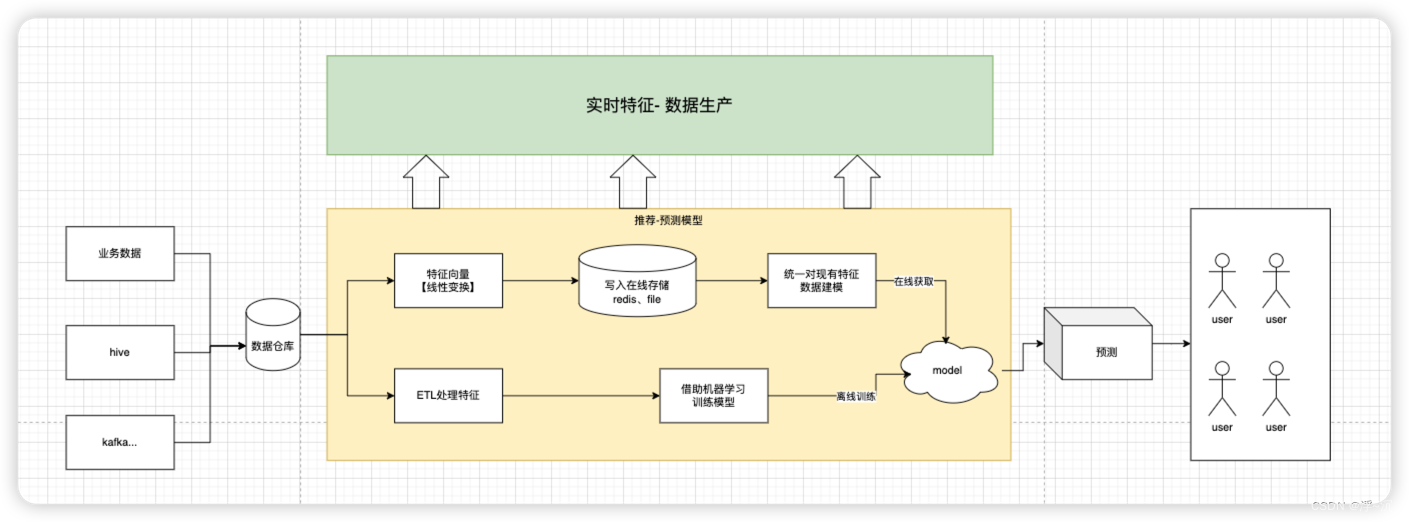
由于我主要负责实时系统, 离线训练细节逻辑由专门算法同学负责,通过经验分享和沟通也得到了算法同学认可如上图所示
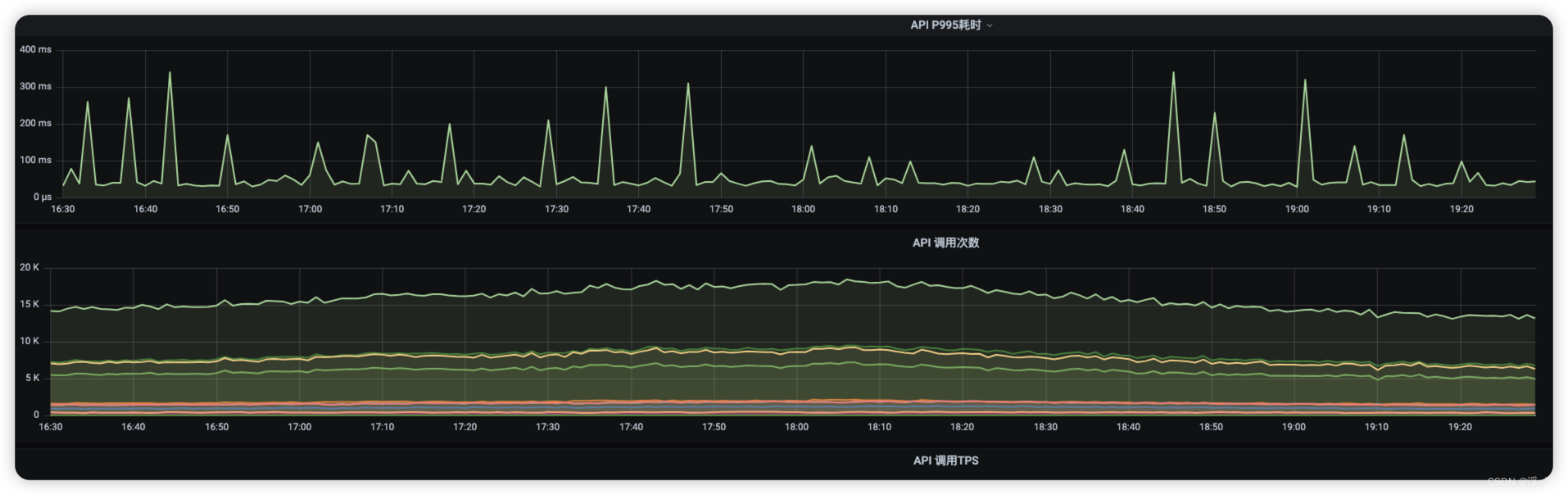
看起来实时特征的生产和离线训练生产特征 逻辑大体相同,但是实时特征对数据一致性,及时性以及对接口的响应RT是要求极高的, 我们业务中就要在峰值5000+QPS的背景下 要求P995 在500ms 以内返回,那么如何做到这一点,请听我娓娓道来…
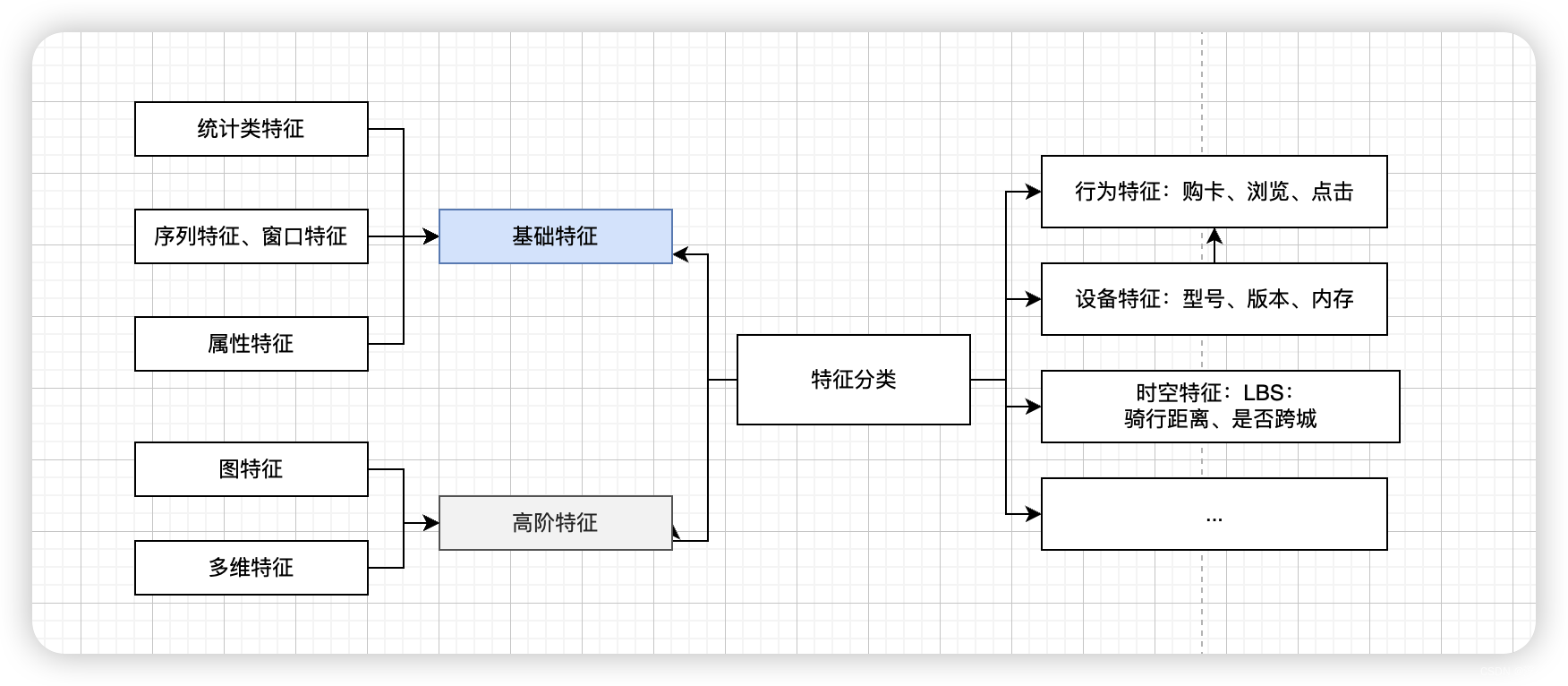
基本概念
考虑有些同学可能还未接触过,这里把一些本文涉及到核心概念做了总结,让大家有个整体感受
| 关键词 | 描述 | 备注 |
|---|---|---|
| 用户画像 | 用户画像的本质是通过对用户的行为分析和统计,挖掘用户的需求、兴趣和习惯 | 购买行为,支付方式,浏览习惯 |
| 客群 | 特定的、拥有共同特性(可能是年龄、收入、性别、购买行为等)的消费者群体 | 例如:喜欢购买骑行卡的用户骑车在xx岁的用户 |
| 特征 | 通常是描述用户特定行为或属性,也可以是城市、车辆某些行为 | 如:购卡用户、多少日内骑行用户免押金城市、订单量大于xx的城市等 |
| 标签 | 进一步具体刻画特征,或者说在业务实践中的常用术语 | 技术层面对特征具象化 |
| 物料 | 用户的原始特征,如身份、年龄、职业等 | 技术层面理解就是未进入到特征系统的业务数据 |
| Point-in time | 时间点准确预测 | 可直接影响离线训练模型结果,也就是常说的特征穿越问题 |
| 用户活跃度 | 活跃期、沉默期、沉睡期 | |
| 召回 | 根据原始特征快速分析用户的泛化兴趣,即粗略的共同爱好进行参与排序计算 | 实时推荐第一步 |
其他概念都比较好理解,特征穿越可能会有点疑惑,本文重点不在这,但是文末有进一步解释
技术架构
“四高”
在这么一个在推荐业务及其重要的环节,怎么保证实时特征生产和查询的及时性,准确性,以及服务的高可用性、高并发、高性能,同时为了兼容后续业务迭代如何让特征生产具备高扩展性,几经打磨如下技术体系:
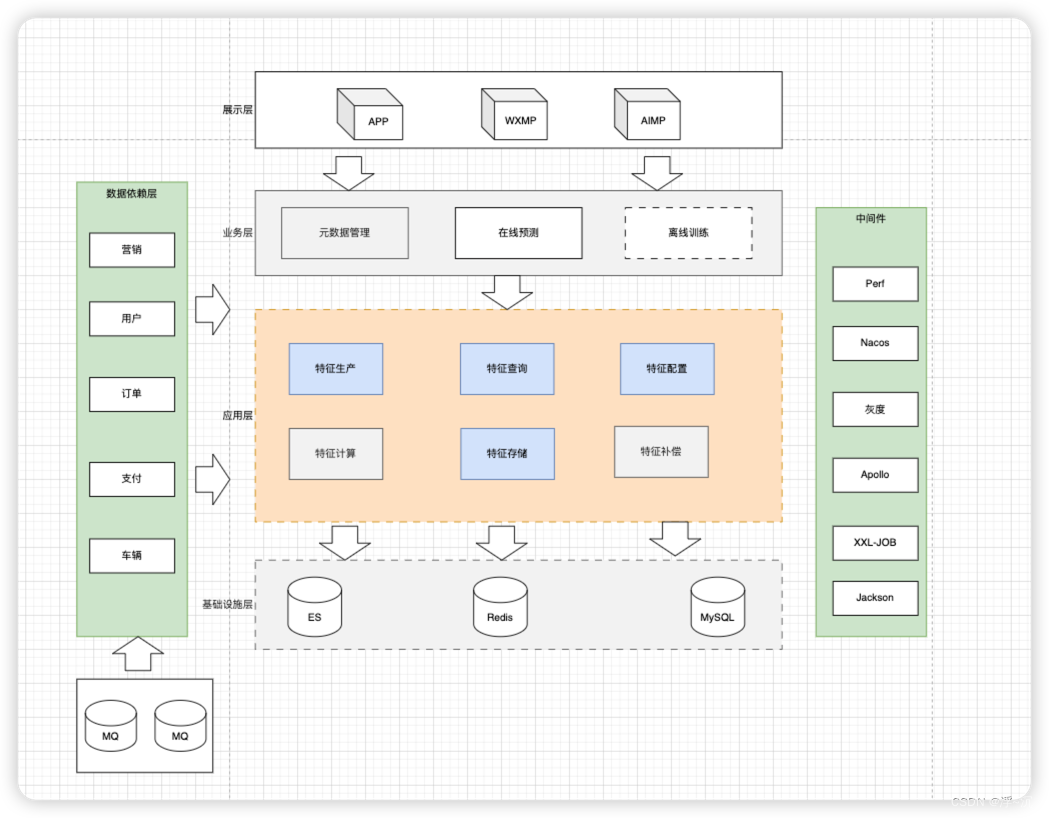
下面我们分析每一个业务模块
特征存储
如果说实时特征系统是用户推荐的关键一环,那么特征存储选择决定了"三高"的上限,这里我们采用ES 集群 + Redis 主从架构,
为什么选择ES?
众所周知,本身ES集群本身基于Raft协议在数据一致性可以得到很好的保障,加上本身基于lucence引擎在搜索领域早已崭露头角,高性能查询当之无愧,此外ES集群采用1主2从,多副本分片机制加之运维人员合理配置,承载高并发、高可用性也是可以轻松做到。
至于Redis,考虑的即便是实时特征也有进一步对特征时效性的区分即高时效性和一般时效性,例如对某些用户特征要求1秒级返回,有的可以允许几分钟时延,因此Redis主要是做这部分时效性一般特征的抗压组件再合适不过。
特征计算
和离线采集一样,实时特征采集也是需要经过ETL标准流程,通过承接不同业务事件,做一般时效性特征采集,转化到最终匹配到统一特征模型配置中,而针对于时效性很高的特征,分两步,有的直接通过业务接口同步更新,对于链路较长的业务特征采集,则是通过直接加载业务数据源方式构建。
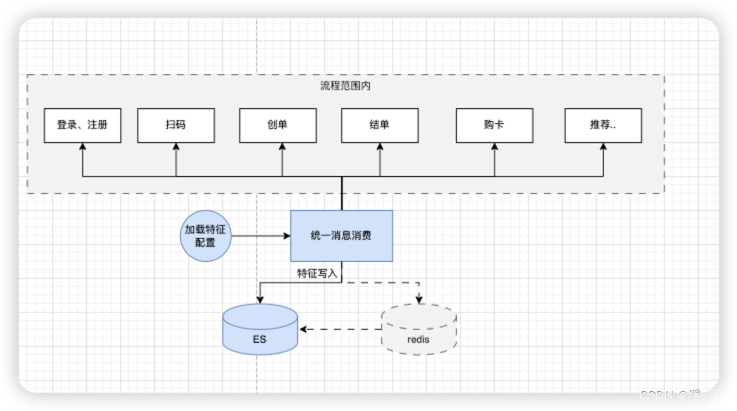
然而,随着用户行为累积,特征的表现形式也多种多样,如何灵活特征的衍生和快速配置方式让特征生效
在设计之初就考虑到了这一典故,我对特征进行元数据管理,对特征来源,特征计算逻辑也进行单独管理,事实上背后最关键的技术也是来自ES本身支持场景基本单一【这是选择ES另一个考虑】,其中内置很多计算函数:如sum,max,min,avg等,基于此可以灵活衍生多个不同维度复杂算子。
同时我们还有专门的管理后台对特征进行状态上下线,以及通用计算逻辑界面化配置[可以参考下],这样可以极大减少开发周期,几乎无需写代码即可实现新特征注册上线及使用。
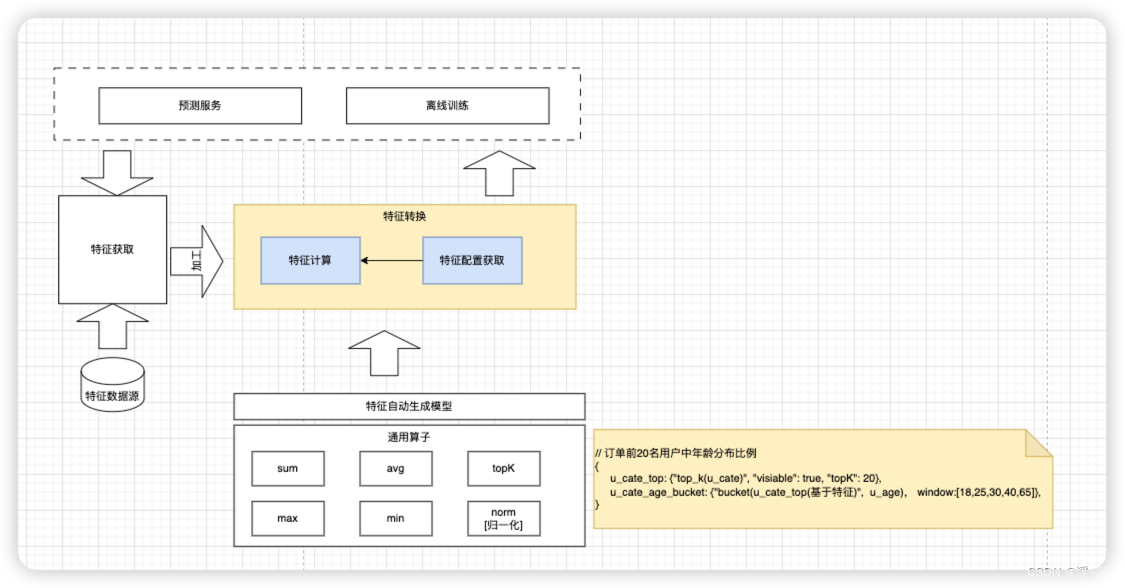
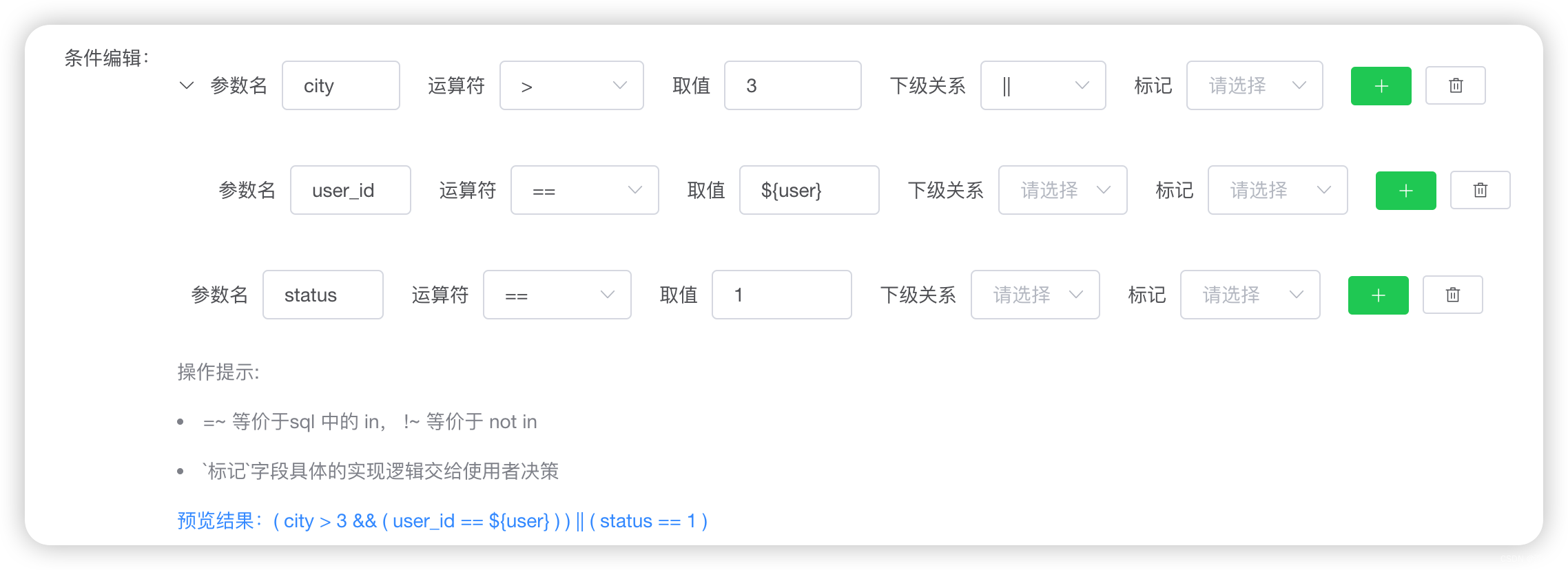
特征计算配置得益于我们在初始化阶段就构造了20多个算子, 可以支持一般性特征扩展。
特征查询
查询其实在特征计算也提到过,对推荐系统来说,查询RT越低,在用户侧推荐效果就越好。因此我们对特征进行时效性划分, 当需要时效性一般的数据,直接走缓存,如果缓存未命中则直接从ES全量集合中获取,对于时效性较高的走ES查询,而对于时效性极高的特征,则是优先从业务数据源直接查询
可能会有疑问:这么高的并发业务库能承载的了这样的查询吗?
A:首先特征系统在接入业务数据源的时候,业务方基本都做了读写分离,加上一主多从的机制可以充分分担查询压力,同时对于这种时效极高的数据特征case是比较少的,基本只存在特定页面过来。为了防止突发流量,我们也做了相应的限流和熔断机制
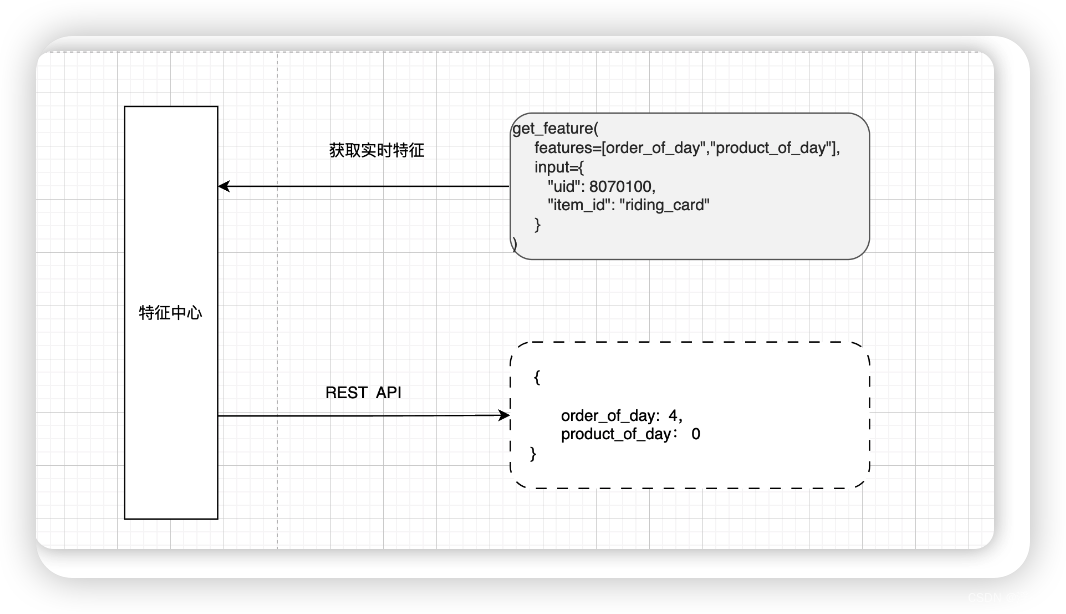
特征补偿
特征补偿,主要发生在监听业务事件消费逻辑上,也就是非实时性较高的特征场,而且生产环境很难完全规避中间件抖动带来的影响,所以对于这部分特征我们采用异步任务,对消费异常过程的特征进行打点,然后在业务低峰期进行对应特征事件数据补偿:比如在监听用户购卡、结单消息出现问题时,通过user_id和异常消费时间线是一定可以从业务数据找到对应特征元数据并补充到ES中。
技术难点Q&A
1. 数据一致性保障?
这里存在三处不一致需要解决
- 不可重复读:当查询请求介于更新相同特征之间时容易引发不可重复读的问题,那么常见的思路就是需要考虑加版本号控制,ES也提供了这样的机制
- 增量更新:对于实时特征来说,基本都是基于用户当天的行为特征, 比如是否注册用户,复活用户等应该保障一天只更新1次,而不是出现特征覆盖的情况造成推荐系统紊乱
- 数据加工一致:作为特征生产的集中站,我们从业务那里无论是异步还是同步加载特征源信息,都应该在解析,转换以及使用都应该和业务保持一致,比如数据脱敏,例如我们从用户系统获取用户信息,我们也需要保持同样的加密和解密算法逻辑,还有类似对状态,枚举的定义甚至文字说明也要保持一致,避免数据误差。
2. 数据幂等
这个最容易忽略,业务方在产生这些数据特征, 尤其是状态相关的一般也是随着业务规模才逐渐加上了幂等逻辑,而对于特征消费场景来说,幂等也是应考虑的重点,以避免对特征数据源产生较高写操作,是系统压力集中站,必须要谨慎设计
3. 如何尽最大努力保障业务数据源的稳定性
前面提到,我们会有兜底逻辑查询业务数据源,尤其是实效性极高的特征,虽然早期并发不高,但是如果业务扩展,高并发查询进来势必会对系统带来查询瓶颈,那么改如何优化?
- 做到同一个用户只查询1次, 这取决特征元数据抽取和特征配置表的设计思路,如下图所示

这就是看技术经理怎么设计了,一般来说从理解上看特征与数据源关系是多对多:一个数据源可以生成多个特征,一个特征可能需要来自多个数据源特征共同组成,因此如果只从技术考虑那么这个实现复杂度是N*M,因此为了降低复杂度在设计的时候我们采用了数据库第二范式冗余字段,进行优化对一个数据源一次性抽取所有特征, 即便并不关心是否一定需要最终使用,也避免多次占用网络带宽造成的性能损耗。
4. 复杂特征计算通用性
简单特征只需要经过1次预处理就可以完成写入,但是对于复杂的特征分为2类:
- 特征消费时可以确定的逻辑:即便如此,也需要组合多个特征输入甚至还要对某些特征加工, 然后作为最终特征构建的输入,这里我们统一借助特征算子配置,
以预定义函数算子 + Stream表达式方式去编排拼接得到最终的复杂特征,这个过程可以通过管理页面进行控制,而无需手动编码,可以快速响应产品需求变化 - 对于特征生产无法确定的逻辑,比如甚至需要依靠实时推荐系统查询提供输入才能最终确定逻辑:对于这部分特征只能硬编码去根据推荐输入参数实时处理并得到期望的特征值。
还有更多的细节问题,有过一定开发经验童鞋通过网络也能顺腾摸瓜思考得以解决,千篇一律,这里就不一一举例了
彩蛋
什么是特征穿越【Point In Time】?
我也是盲人摸象,慢慢熟悉之后整个流程才了解,这个情况倒不会发生咋实时系统,而是多在离线训练发生,但是起点仍然在实时特征中心
简单来说,通过营销推荐策略推给用户导致的购买行为,本应该在T1时刻关联的对应的特征,但是因为系统时效性或者逻辑漏洞造成关联的T0 时刻特征,这就会对模型训练造成极大干扰,导致最终生产的模型不佳,举例如下:

采用ChatGPT举例生成,以此说明
如上图所示, 用户在9点时刻行为,只能使用9点之前用户的特征【过去购买、点击的商品】,如果使用了9点之后的信息来构建就会产生特征穿越,因为包含了未来的信息导致模型训练和预测结果存在显著差异,从而反应模型表现很差
写在最后, 深耕不易,如需转载和复制,请备注出处!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









