







3.2.1 什么是事物
事务就是用户定义的一系列数据库操作,这些操作可以视为一个完成的逻辑处理工作单元,要么全部执行成功,要么全部执行失败,是不可分割的工作单元
3.2.2 说一说事务的ACID特性 ?
原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
3.2.3 不考虑事务会引发什么问题 ?
赃读:一个事务读到另外一个事务还没有提交的数据。
不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。
幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了 "幻影"。
3.2.4 事务的隔离级别有哪些
read uncommitted : 读取尚未提交的数据 :哪个问题都不能解决
read committed:读取已经提交的数据 :可以解决脏读 ---- oracle、sql server、postgresql 默认的
repeatable read:重读读取:可以解决脏读 和 不可重复读 ---mysql默认的
serializable:串行化:可以解决 脏读 不可重复读 和 虚读 ---相当于锁表
3.2.5 事务隔离级别是怎么实现的
隔离级别的实现主要有读写锁和MVCC( Multi-Version Concurrency Control )多版本并发处理方式。
- 读未提交,它是性能最好,也可以说它是最野蛮的方式,因为它压根儿就不加锁,所以根本谈不上什么隔离效果,可以理解为没有隔离。
- 串行化。读的时候加共享锁,也就是其他事务可以并发读,但是不能写。写的时候加排它锁,其他事务不能并发写也不能并发读。
- 读已提交在读已提交隔离级别下,在事务中每一次执行快照读时生成ReadView。多个事物有多个ReadView , 事务没有结束之前只能读取自己的ReadView , 实现了读已提交 , 不能读取到其他事物未提交的数据
- 可重复读在可重复读隔离级别下,仅在事务中第一次执行快照读时生成ReadView,后续复用该ReadView。 而Repeatable Read 是可重复读,在一个事务中,执行两次相同的select语句,查询到的结果是一样的
3.2.6 说一说数据库表锁和行锁 ?
表级锁 : 每次操作锁住整张表。锁定粒度大,发生锁冲突的概率最高,并发度最低。应用在MyISAM、InnoDB等存储引擎中
表级锁又分 : 表锁 , 元数据锁 , 意向锁
- 表锁 : 表共享读锁, 表独占写锁
-
- 加锁语法 :
lock tables 表名... read/write, 读读共享, 读写互斥 , 写写互斥 - 释放锁:
unlock tables
- 加锁语法 :
- 元数据锁 : 元数据锁锁主要作用是维护表元数据的数据一致性,在表上有活动事务的时候,不可以对元数据进行写入操作 , 在访问一张表的时候会自动加上。
- 意向锁 : 在获取到一张表中某一条数据的行锁的时候, 会自动为该表加上意向锁
行级锁 : 每次操作锁住对应的行数据。锁定粒度最小,发生锁冲突的概率最低,并发度最高 , 行锁是对索引加锁
行级锁主要有三类 : 行锁 , 间隙锁, 临键锁
- 行锁(Record Lock):锁定单个行记录的锁,防止其他事务对此行进行update和delete , 在RC、RR隔离级别下都支持行锁 , 防止出现脏读

加锁语法 :
-
- 读锁 :
SELECT ... LOCK IN SHARE MODE - 写锁 :
SELECT ... FOR UPDATE
- 读锁 :
- 间隙锁(Gap Lock):锁定索引记录间隙(不含该记录),确保索引记录间隙不变,在RR隔离级下支持间隙锁 , 防止其他事务在这个间隙进行insert,产生幻读

- 临键锁(Next-Key Lock):行锁和间隙锁组合,同时锁住数据,并锁住数据前面的间隙Gap ,在RR隔离级下支持间隙锁 , 防止其他事务在这个间隙进行insert,产生幻读

查询加锁情况 :
select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;3.2.7 什么是死锁 , 如何避免死锁
死锁是指两个或两个以上的线程在执行过程中,因争夺资源而造成的一种互相等待的现象这就是死锁
例如 : MYSQL中 事物A获取了一部分数据的锁(10-20) , 事物B也获取一部分数据的锁(20-30)
这个时候事物A想获取id=25这条数据的锁 , 因为这条数据的锁被事物B持有就会阻塞程序
事物B这个时候想获取id=15这条数据的锁 , 因为这条数据的锁被事物A持久, 也会进行等待
这个时候事物A等事物B , 事物B等事物A , 就产生了死锁 , 出现死锁之后MYSQL会报一个异常
CREATE TABLE `emp` (
`id` int NOT NULL AUTO_INCREMENT COMMENT 'ID',
`name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '姓名',
`age` int NULL DEFAULT NULL COMMENT '年龄',
`job` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '职位',
`salary` int NULL DEFAULT NULL COMMENT '薪资',
`entrydate` date NULL DEFAULT NULL COMMENT '入职时间',
`managerid` int NULL DEFAULT NULL COMMENT '直属领导ID',
`dept_id` int NULL DEFAULT NULL COMMENT '部门ID',
`gender` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '性别',
`workaddress` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '工作城市',
PRIMARY KEY (`id`) USING BTREE,
INDEX `index_age`(`age` ASC) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 39 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '员工表' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of emp
-- ----------------------------
INSERT INTO `emp` VALUES (1, '金庸', 66, '总裁', 20000, '2000-01-01', NULL, 5, '男', '北京');
INSERT INTO `emp` VALUES (2, '郭靖', 20, '项目经理', 12500, '2005-12-05', 1, 1, '男', '上海');
INSERT INTO `emp` VALUES (3, '杨逍', 33, '开发', 8400, '2000-11-03', 2, 1, '男', '长沙');
INSERT INTO `emp` VALUES (4, '韦一笑', 48, '开发', 11000, '2002-02-05', 2, 1, '男', '北京');
INSERT INTO `emp` VALUES (5, '常遇春', 43, '开发', 10500, '2004-09-07', 3, 1, '男', '长沙');
INSERT INTO `emp` VALUES (6, '小昭', 19, '程序员鼓励师', 6600, '2004-10-12', 2, 1, '女', '武汉');
INSERT INTO `emp` VALUES (8, '周芷若', 19, '会计', 48000, '2006-06-02', 7, 3, '女', '北京');
INSERT INTO `emp` VALUES (9, '丁敏君', 23, '出纳', 3000, '2009-05-13', 7, 3, '女', '北京');
INSERT INTO `emp` VALUES (10, '郭靖', 20, '市场部总监', 12500, '2004-10-12', 1, 2, '女', '武汉');
INSERT INTO `emp` VALUES (12, '杨过', 16, '职员', 6000, '2023-04-02', 0, 1, '男', '湖北武汉');
INSERT INTO `emp` VALUES (13, '方东白', 19, '职员', 5500, '2009-02-12', 10, 2, '男', '上海');
INSERT INTO `emp` VALUES (14, '张三丰', 88, '销售总监', 14000, '2004-10-12', 1, 4, '男', '杭州');
INSERT INTO `emp` VALUES (16, '宋远桥', 40, '销售', 4600, '2004-10-12', 14, 4, '男', '上海');
INSERT INTO `emp` VALUES (17, '陈友谅', 42, NULL, 2000, '2011-10-12', 1, NULL, '男', '杭州');
INSERT INTO `emp` VALUES (23, '俞莲舟', 38, '销售', 4600, '2004-10-12', 14, 4, '男', '杭州');
INSERT INTO `emp` VALUES (25, '鹤笔翁', 19, '职员', 3750, '2007-05-09', 10, 2, '男', '武汉');
INSERT INTO `emp` VALUES (28, '鹿杖客', 56, '职员', 3750, '2006-10-03', 10, 2, '男', '武汉');
INSERT INTO `emp` VALUES (30, '杨康', 16, '职员', 6500, '2023-04-03', 1, 1, '男', '湖北武汉');死锁演示 :
- 事物A :
start transaction ; - 事物B :
start transaction ; - 事物A执行语句 :
update emp set salary = 3000 where age= 23; - 事物B执行语句 :
update emp set salary = 7000 where age= 30; - 事物A执行语句 :
insert into emp value (35,'小龙女',25,'职员',6500,'2023-04-03',1,1,'女','湖北武汉');
- 事物B执行语句 :
insert into emp value (38,'小红',21,'职员',6500,'2023-04-03',1,1,'女','湖北武汉');
这个时候就出现了死锁 , 控制台报异常
Deadlock found when trying to get lock; try restarting transaction
数据库的死锁的发生通常由以下原因导致:
- 多个事务同时请求相同的资源,但是它们请求资源的顺序不同,导致互相等待。
- 事务在操作过程中,没有按照相同的顺序获取锁,导致互相等待。
- 操作的数据量过大,在持有锁的同时,又请求获取更多的锁,导致互相等待。
解决死锁的方法有:
- 减少锁的数量:比如使用RC来代替RR来避免因为gap锁和next-key锁而带来的死锁情况。
- 减少锁的时长:加快事务的执行速度,降低执行时间,也能减少死锁发生的概率。
- 固定顺序访问数据:事务在访问同一张表时,应该以相同的顺序获取锁,这样可以避免死锁的发生。
- 减少操作的数据量:尽量减少事务操作的数据量,尽量减少事务的持有时间,这样可以降低死锁的发生几率。
3.2.8 什么是redolog , 有什么用 ?
redolog就是重做日志,记录的是事务提交时数据页的物理修改,是用来实现事务的持久性
该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log file),前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都存到该日志文件中, 用于在刷新脏页到磁盘,发生错误时, 进行数据恢复使用
在InnoDB引擎中的内存结构中,主要的内存区域就是缓冲池,在缓冲池中缓存了很多的数据页。
当我们在一个事务中,执行多个增删改的操作时,InnoDB引擎会先操作缓冲池中的数据,如果缓冲区没有对应的数据,会通过后台线程将磁盘中的数据加载出来,存放在缓冲区中,然后将缓冲池中的数据修改,修改后的数据页我们称为脏页。
而脏页则会在一定的时机,通过后台线程刷新到磁盘中,从而保证缓冲区与磁盘的数据一致。 而缓冲区的脏页数据并不是实时刷新的,而是一段时间之后将缓冲区的数据刷新到磁盘中,假如刷新到磁盘的过程出错了,而提示给用户事务提交成功,而数据却没有持久化下来,这就出现问题了,没有保证事务的持久性。
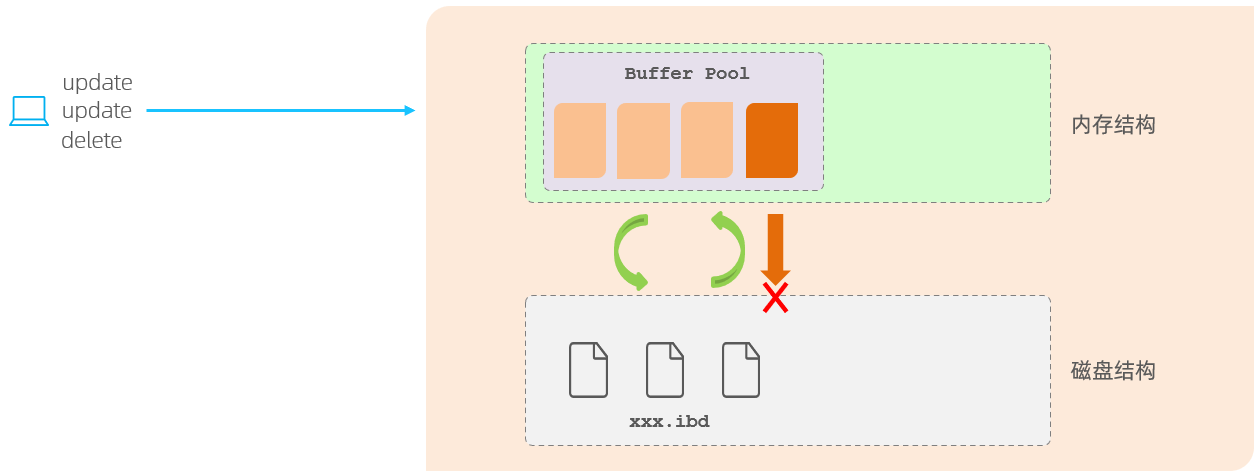
redolog的存在就是为了解决这个问题
当对缓冲区的数据进行增删改之后,会首先将操作的数据页的变化,记录在redo log buffer中。
在事务提交时,会将redo log buffer中的数据刷新到redo log磁盘文件中。
过一段时间之后,如果刷新缓冲区的脏页到磁盘时,发生错误,此时就可以借助于redo log进行数据恢复,这样就保证了事务的持久性。
而如果脏页成功刷新到磁盘 或 或者涉及到的数据已经落盘,此时redolog就没有作用了,就可以删除了,所以存在的两个redolog文件是循环写的
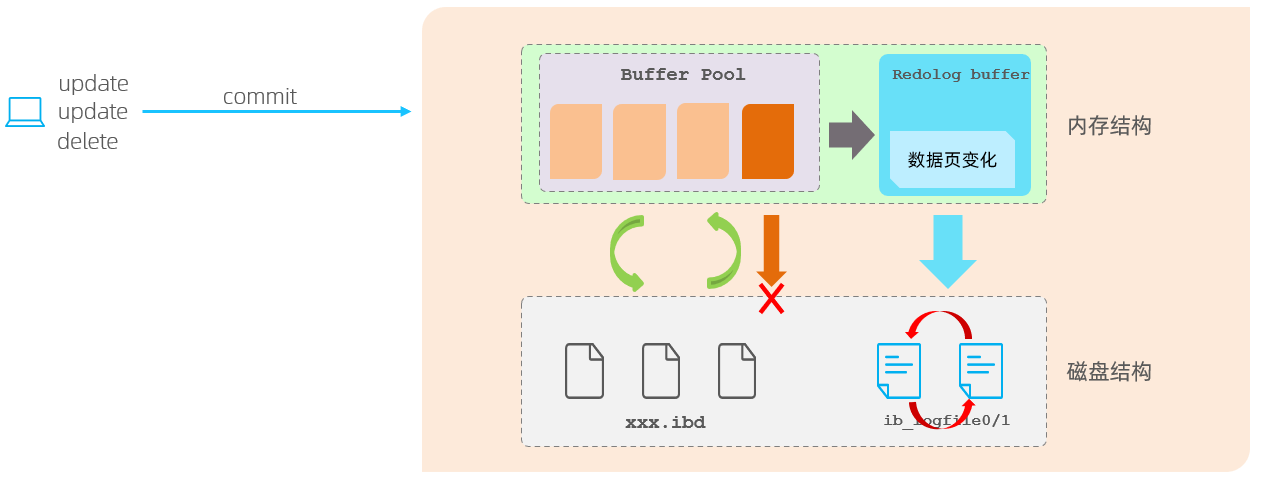
问题 : 为什么每一次提交事务,要刷新redo log 到磁盘中呢,而不直接将buffer pool中的脏页刷新到磁盘呢 ?
因为在业务操作中,我们操作数据一般都是随机读写磁盘的,而不是顺序读写磁盘。 而redo log在往磁盘文件中写入数据,由于是日志文件,所以都是顺序写的。顺序写的效率,要远大于随机写
3.2.9 什么是undo log, 有什么用 ?
undo log就是回滚日志,用于记录数据被修改前的信息 , 顾名思义他的作用主要是用来回滚事物的 , 保证事物一致性 , 同时也可以提供多版本并发控制下的读(MVCC)
在事务没提交之前,MySQL会先记录更新前的数据到 undo log日志文件里面,当事务回滚时或者数据库崩溃时,可以利用 undo log来进行回退
在MySQL数据库InnoDB存储引擎中,还用undo Log来实现多版本并发控制(MVCC)。当读取的某一行被其他事务锁定时,它可以从undo log中分析出该行记录以前的数据版本是怎样的,从而让用户能够读取到当前事务操作之前的数据
3.2.10 什么是binlobg, 有什么用 ?
binlog是一个二进制格式的文件,用于记录用户对数据库更新的SQL语句信息,例如更改数据库表和更改内容的SQL语句都会记录到binlog里,但是对库表等内容的查询不会记录。
默认情况下,binlog日志是二进制格式的,不能使用查看文本工具的命令(比如,cat,vi等)查看,可以使用mysqlbinlog解析查看
所以他的主要作用就是是用于数据库的主从复制及数据的增量恢复
3.2.11 有没有了解过MVCC , 说一说你的理解
MVCC也叫多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突
通俗的讲就是MVCC通过保存数据的历史版本,根据比较数据的版本号来决定数据的是否显示,在不需要加读锁的情况就能达到事务的隔离效果,最终可以在读取数据的时候可以同时进行修改,修改数据时候可以同时读取,极大的提升了事务的并发性能
假如我们创建一张表 :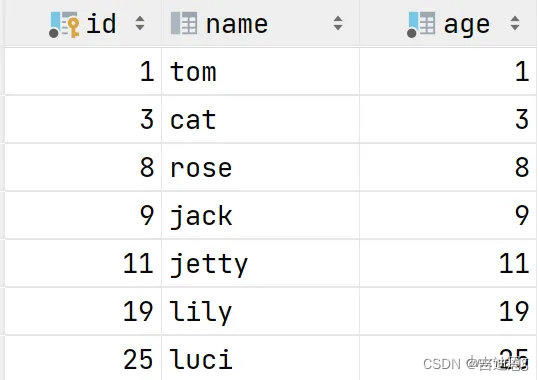
们创建了上面的这张表,我们在查看表结构的时候,就可以显式的看到这三个字段。 实际上除了这三个字段以外,InnoDB还会自动的给我们添加三个隐藏字段及其含义分别是
- DB_TRX_ID : 最近修改事务ID , 记录插入这条记录或最后一次修改该记录的事务ID
- DB_ROLL_PTR : 回滚指针,指向这条记录的上一个版本,用于配合undo log,指向上一个版本
- DB_ROW_ID : 隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段
当有多个事务同时对这个表的数据进行修改 , 这个时候就会形成版本链
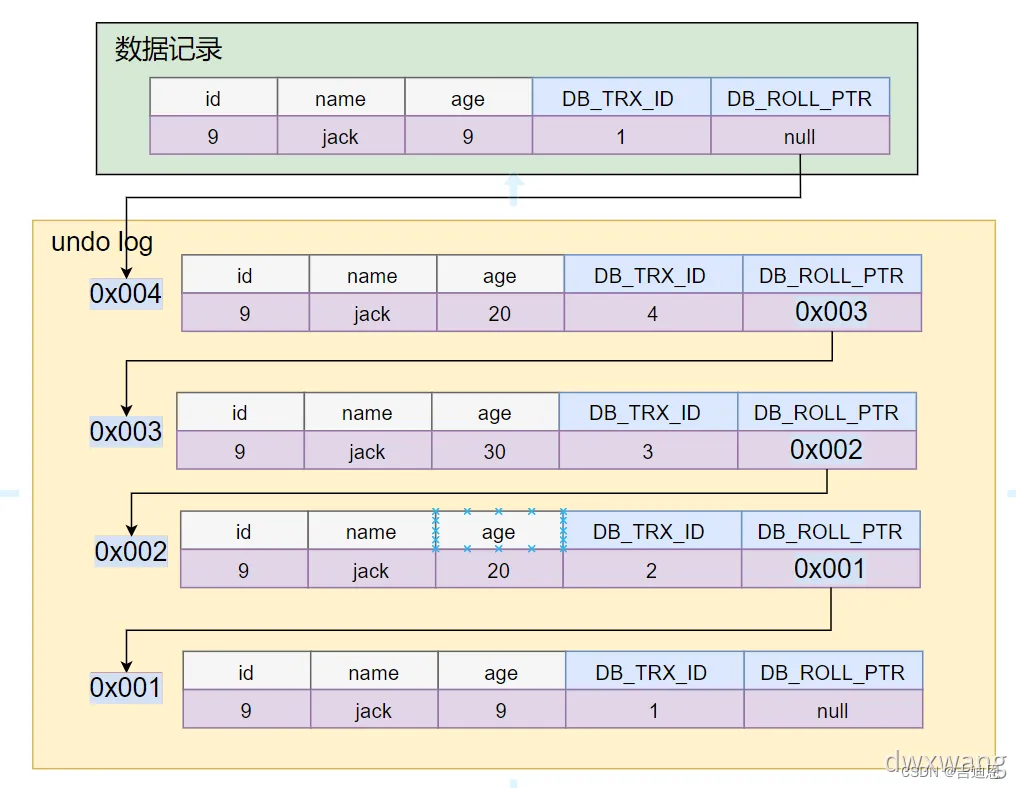
事务执行SQL语句时,产生一个读视图。也就是Read View , 实际上在innodb中,每个SQL语句执行前都会得到一个Read View , Read View的主要作用是来做可见性判断的,即判断当前事务可见哪个版本的数据 , Read View 主要包含几个字段 :
m_ids: 当前活跃的事务ID集合min_trx_id: 最小活跃事务IDmax_trx_id: 预分配事务ID,当前最大事务ID+1(因为事务ID是自增的)creator_trx_id: ReadView创建者的事务ID
在readview中就规定了版本链数据的访问规则 , trx_id 代表当前事物id:
trx_id == creator_trx_id: 数据是当前这个事务更改的 , 可以访问trx_id < min_trx_id: 说明数据已经提交了 , 可以访问数据trx_id > max_trx_id: 说明该事务是在ReadView生成后才开启 , 不可以访问数据min_trx_id <= trx_id <= max_trx_id: 如果trx_id不在m_ids中,是可以访问该版本的
基于MVCC查询一条记录,执行流程如下 :
- 获取事务自己的版本号,即事务ID
- 获取Read View
- 查询得到的数据,然后Read View中的事务版本号进行比较。
- 如果不符合Read View的可见性规则, 即就需要Undo log中历史快照;
- 最后返回符合规则的数据
不同的隔离级别,生成ReadView的时机不同:
- READ COMMITTED :在事务中每一次执行快照读时生成ReadView。
- REPEATABLE READ:仅在事务中第一次执行快照读时生成ReadView,后续复用该ReadView。
















 426
426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











