









🥕HBase入门到放弃🙄
🙄🙄
Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩、实时读写的分布式数据库。利用Hadoop HDFS作为其文件存储系统,利用Zookeeper作为其分布式协同服务主要用来存储非结构化和半结构化的松散数据(列存 NoSQL 数据库,通过键值对的形式进行查询key-value)。大数据处理数据流程,现由Kafka进行缓存,再由Hive(底层是MapReduce计算引擎)将数据转换成表,方便sql,最后存放到HBase(底层是HDFS)中,hive用于计算,hbase用于存储。
一、SQL语言(小知识)
SQL(Structure Query Language)语言是数据库的核心语言。SQL语言共分为四大类:数据定义语言DDL,数据操纵语言DML,数据查询语言DQL,数据控制语言DCL。
1、DDL和DML
数据定义语言DDL用来创建数据库中的各种对象:
表、视图、索引、同义词、聚簇...
CREATE TABLE/VIEW/INDEX/SYN/CLUSTER (DDL操作是隐性提交的,不能rollback)
DML简单说就是对数据进行插入insert,更新update,删除delete操作
2、DQL和DCL
DQL:
查询语句:select 字段 from 表名 where 条件 group by 分组关键字 order by 排序......
DCL:
数据控制语言DCL用来授予或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,对数据
库实行监视等,比如GRANT:授权或者 ROLLBACK就滚数据。
二、HBase数据模型
HBase 是一个稀疏的、分布式、持久、多维、排序的映射,它以行键(row key),列簇(columnFamily),列名(Column Qualifier)和时间戳(timestamp)为索引。(hdfs存储的都是字节数组)
命名空间:就是命名一个专门的文件存放表,以便分别存储逻辑分组行号:row key主键:唯一标识,最多有64k字节组成,一般在10~40个字节,存储时默认按照以字典排序列簇column family:就是多个列的集合,一个大的类型,列簇是固定的,但列时不固定的列column:就是普普通通的列,具体的标识时间戳 time stamp:数据版本:默认是时间戳,解决hdfs不能随时间修改数据的弊端,默认查最新数据(存放最新的,要么存放一段时间的内的数据)数据cell:在hbase中数据类型全是字符串
XShell小知识:sz:下载资源 rz:上传资源
三、 HBase高可用集群搭建
前提:Hadoop集群正常运行 和ZooKeeper集群正常运行,Hive正常运行,时间同步(最少三台虚拟机)
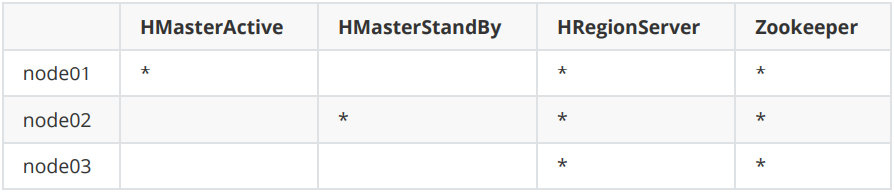

1、资源准备
[root@node01 ~]# tar -zxvf hbase-2.2.5-bin.tar.gz
[root@node01 ~]# mv hbase-2.2.5 /opt/yjx/
[root@node01 ~]# cd /opt/yjx/hbase-2.2.5/conf/
2、环境配置
[root@node01 conf]# vim hbase-env.sh
export HBASE_LOG_DIR=${HBASE_HOME}/logs
export JAVA_HOME=/usr/java/jdk1.8.0_231-amd64
export HBASE_MANAGES_ZK=false
export HADOOP_HOME=/opt/yjx/hadoop-3.1.2/
[root@node01 conf]# vim hbase-site.xml
<!-- 31dd -->
<!--设置HBase表数据,也就是真正的HBase数据在hdfs上的存储根目录-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hdfs-yjx/hbase</value>
</property>
<!--是否为分布式模式部署,true表示分布式部署-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--zookeeper集群的URL配置,多个host中间用逗号-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
<!--HBase在zookeeper上数据的根目录znode节点-->
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
<!-- 本地文件系统tmp目录,一般配置成local模式的设置一下,但是最好还是需要设置一下,因为很
多文件都会默认设置成它下面的-->
<property>
<name>hbase.tmp.dir</name>
<value>/var/yjx/hbase</value>
</property>
<!-- 使用本地文件系统设置为false,使用hdfs设置为true -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
[root@node01 conf] vim regionservers
node01
node02
node03
[root@node01 conf]# vim backup-masters
node02
拷贝Hadoop配置文件
[root@node01 conf]# cp /opt/yjx/hadoop-3.1.2/etc/hadoop/core-site.xml /opt/yjx/hbase2.2.5/conf/
[root@node01 conf]# cp /opt/yjx/hadoop-3.1.2/etc/hadoop/hdfs-site.xml /opt/yjx/hbase2.2.5/conf/
拷贝分发软件
[root@node02 ~]# scp -r root@node01:/opt/yjx/hbase-2.2.5 /opt/yjx/
[root@node03 ~]# scp -r root@node01:/opt/yjx/hbase-2.2.5 /opt/yjx/
修改环境变量[node01,node02,node03]
[root@node01 conf]# vim /etc/profile
export HBASE_HOME=/opt/yjx/hbase-2.2.5
export PATH=$HBASE_HOME/bin:$PATH
//记得刷新
//source /etc/profile
3、启动集群
先启动zookeeper,在启动hadoop环境,最后启动hbase
【123】 zkServer.sh start
[root@node01 conf]# start-all.sh
[root@node01 conf]# start-hbase.sh
启动后访问 http://192.168.168.101(虚拟机主机号):16010

四、HBase访问方式以及基本操作
1、HBase Shell方式
基本访问方式Hbase shell方式
//使用hbase提供的访问方式链接hbase服务
hbase shell
//退出客户端
exit

基本操作方式
//查看服务器
status
//查看版本号
version
//帮助命令很重要
help
//创建表
create '表名',{NAME=>'列簇',NAME=>'列簇'...}
create 'demo01',{Name=>'id',NAME=>'info'}
//简洁创建表
create '表名','列簇','列簇'
//查询表结构
describe '表名'
describe 'demo01'
//查看全部表
list
//查看表是否存在
exists '表名'
//添加数据
put '表名','数据','列簇:列','数据'.....
put 'demo02','wangwu',info:age','20'
//注:现在表的数据都在内存中,并没有落地到磁盘。如果这时候想要落地到磁盘只能手动落地,一般只有满128M才会自动写入到HDFS
//命令:flush ‘表名’
//删除表--先禁用---删除
disable '表明'
drop '表名'
//删除id为temp的值的‘info:age’字段
hbase(main):016:0>delete 'member','temp','info:age'
//查询表中有多少行:
hbase(main):019:0>count 'member'
//基本操作还有很多,不在一一列出
2、Java访问HBaseAPI
直接使用IDEA建一个javaMaven项目,引入依赖和之前在LInux环境中配置好的配置文件直接引入IDEA中即可
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<!-- Hadoop版本控制 -->
<hadoop.version>3.1.2</hadoop.version>
<!-- HBase版本控制 -->
<hbase.version>2.2.5</hbase.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
</dependencies>

Java实现DDL
Java实现DQL和DML不在一一例举
public class HelloHBaseDDL {
//获取HBase管理员类
private Admin admin;
//获取数据库连接
private Connection connection;
/**
* 命名空间
*
* @throws IOException
*/
@Test
public void createNameSpace() throws IOException {
NamespaceDescriptor mkNameSpace = NamespaceDescriptor.create("yjx").build();
this.admin.createNamespace(mkNameSpace);
System.out.println("HelloHBase.createNameSpace[表空间创建完成]");
}
/**
* 创建单列族的表
*
* @throws IOException
*/
@Test
public void createOneColumnFamilyTable() throws IOException {
TableDescriptorBuilder table = TableDescriptorBuilder.newBuilder(TableName.valueOf("yjx:teacher"));
ColumnFamilyDescriptorBuilder columnBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("info"));
ColumnFamilyDescriptor familyDescriptor = columnBuilder.build();
table.setColumnFamily(familyDescriptor);
admin.createTable(table.build());
}
/**
* 创建多列族的表
*
* @throws IOException
*/
@Test
public void createMultiPartColumnFamilyTable() throws IOException {
TableDescriptorBuilder table = TableDescriptorBuilder.newBuilder(TableName.valueOf("yjx:student"));
ColumnFamilyDescriptorBuilder infoCF = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("info"));
ColumnFamilyDescriptorBuilder scoreCF = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("score"));
List<ColumnFamilyDescriptor> columnFamilyDescriptors = new ArrayList<>();
columnFamilyDescriptors.add(infoCF.build());
columnFamilyDescriptors.add(scoreCF.build());
table.setColumnFamilies(columnFamilyDescriptors);
admin.createTable(table.build());
}
/**
* 查询所有表的信息
*
* @throws IOException
*/
@Test
public void listTables() throws IOException {
TableName[] tableNames = admin.listTableNames();
for (TableName tableName : tableNames) {
System.out.println(tableName);
}
}
/**
* 列出指定命名空间的表信息
*
* @throws IOException
*/
@Test
public void listTablesByNameSpace() throws IOException {
TableName[] tableNames = admin.listTableNamesByNamespace("yjx");
for (TableName tableName : tableNames) {
System.out.println(tableName);
}
}
@Before
public void init() throws IOException {
Configuration configuration = HBaseConfiguration.create();
this.connection = ConnectionFactory.createConnection(configuration);
this.admin = connection.getAdmin();
}
@After
public void destory() throws IOException {
if (admin != null) {
admin.close();
}
if (connection != null) {
connection.close();
}
}
}

五、HBase架构模型
HBase有三个主要组成部分:客户端库,主服务器和区域服务器。

⭐HBase架构
- Client客户端不多说,不支持多表联查
- HMaster—Hbase的主节点,单点故障,接受客户请求,仅限于DDL(单点故障,负载均衡,但已经实现高可用,但没有联邦机制,所以业务承载能力有限,但由于绝大部分都是查询,结构很少变化,CRUD操作,所以Master只负责DDL(DML,和DQL有其他节点承担),负责管理HReginonServer的健康情况,上线监督,分配任务,主备切换由zookeeper实现
- HRegionServer—具体工作节点:一般一台主机就是一个HRS,包含很多Region,HMaster负责分配Region,DML和DQL由它负责,存在心跳机制,心跳保持链接
- HRegion—表数据具体的存放位置,声明表会为表创建一个HRegion,存储的最小单元,每个都会保存一个表里某段连续数据,最初是一个表一个HRegion,当达到阈值10G则会被平分,这样一个表就被存放在多个HRegion中
- Store—有多少个列簇由多少个store,HRegion由一个或多个store组成,store分为MemStore,和StoreFile,MS—主要基于内存存放数据,每个store大概分配128M的空间,SF—是文件的硬盘存储,直接存储到HDFS上,称之为HFile
- HLog—HBase的日志机制,日志也会存储到HDFS,在任何机制之前记录日志到HDFS,以后MS丢失数据或者RS异常都能通过日志进行恢复,写任何操作之前险些日志,也有阈值溢写,每个Region都个对应一个日志信息
- Zookeeper------协调服务,主备选举于切换,记录当前集群的状态信息,挡主备切换时,集群状态可以被新集群读取到,记录集群存放信息位置,存储元数据信息

Store扩充说明:
- MemStore : 数据最开始优先写入到MemStore,当Flush的时候才会被写入到磁盘,默认情况下一个MemStore的大小为128M,当客户端数据库插入数据的时候,当内存使用到128M的时候,在申请一个128M,数据直接写道内存中,原本已经写满的写出到HDFS成为HFile
- StoreFile : 数据存储文件的映射,对应HDFS的HFile,一个Table对应多个Region,一个Region对应多个Store,一个Store对应一个MemStore和多个StoreFile,多个StoreFile内部有序,但外部无序,集群会设置阈值,到达阈值则会开始,将小文件合并成大文件

















 381
381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











