






缓存
缓存就是数据交换的缓冲区,是存储数据的临时地方,一般读写性能较高。
一般情况下数据存在数据库中,应用程序直接操作数据库。当应用应用程序访问量上万,数据库压力突然增大,如果需要减轻数据库服务器的压力,有以下几种方法:
-
数据库读写分离
-
数据库分库分表
-
使用缓存,并实现换粗你的读写分离
缓存原理:将应用程序已经访问过的内容或数据存储起来,当应用程序再次访问时先找缓存,缓存命中返回数据。不命中再查询数据库,并保存到缓存。
缓存分类
浏览器缓存,应用层缓存,数据库缓存,CPU缓存,磁盘缓存
缓存的作用
降低后端负载
提高读写效率,降低响应时间
缓存的成本
数据一致性成本
代码维护成本
运维成本
缓存更新策略
1.内存淘汰
说明:不用自己维护,利用Redis的内存淘汰机制,当内存不足时自动淘汰部分数据。下次查询时更新缓存。
一致性:差
维护成本:无
2.超时剔除
说明:给缓存数据添加TTL时间,到期后自动删除缓存。下次查询时更新缓存。
一致性:一般
维护成本:低
3.主动更新
说明:编写业务逻辑,在修改数据库的同时,更新缓存。
一致性:好
维护成本:高
主动更新策略
01:由缓存的调用者,在更新数据库的同时更新缓存(胜出)
02:缓存与数据库整合为一个服务,由服务来维护一致性。调用者调用该服务,无需关心缓存一致性问题
03:调用者只操作缓存,由其他的线程异步的将缓存数据持久化到数据库,最终保持一致
缓存更新策略的最佳实践方案
1.低一致性要求:使用Redis自带的内存淘汰机制
2.高一致性要求:主动更新,并以超时剔除作为兜底方案
读操作:
1.缓存命中则直接返回
2.缓存未命中则查询数据库,并写入缓存,设定超时时间
写操作:
1.先写数据库,然后再删除缓存
2.要确保数据库与缓存操作的原子性
缓存穿透
缓存穿透是指客户端请求的数据在缓存和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
常见的解决方案有两种:
1.缓存空对象
优点:实现简单,维护方便
缺点:额外的内存消耗。可能造成短期的不一致
2.布隆过滤
优点:内存占用较少,没有多余的key
缺点:实现复杂。存在误判的可能

其他方式:
增强id的复杂度,避免被猜测id规律
做好数据的基础格式校验
加强用户权限校验
做好热点参数的限流
缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力
解决方案:
给不同的key的TTL添加随机值
利用Redis集群提高服务的可用性
给缓存业务添加降级限流策略
给业务添加多级缓存
缓存击穿
缓存击穿问题也叫热点key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
常见的解决方案由两种:
互斥锁
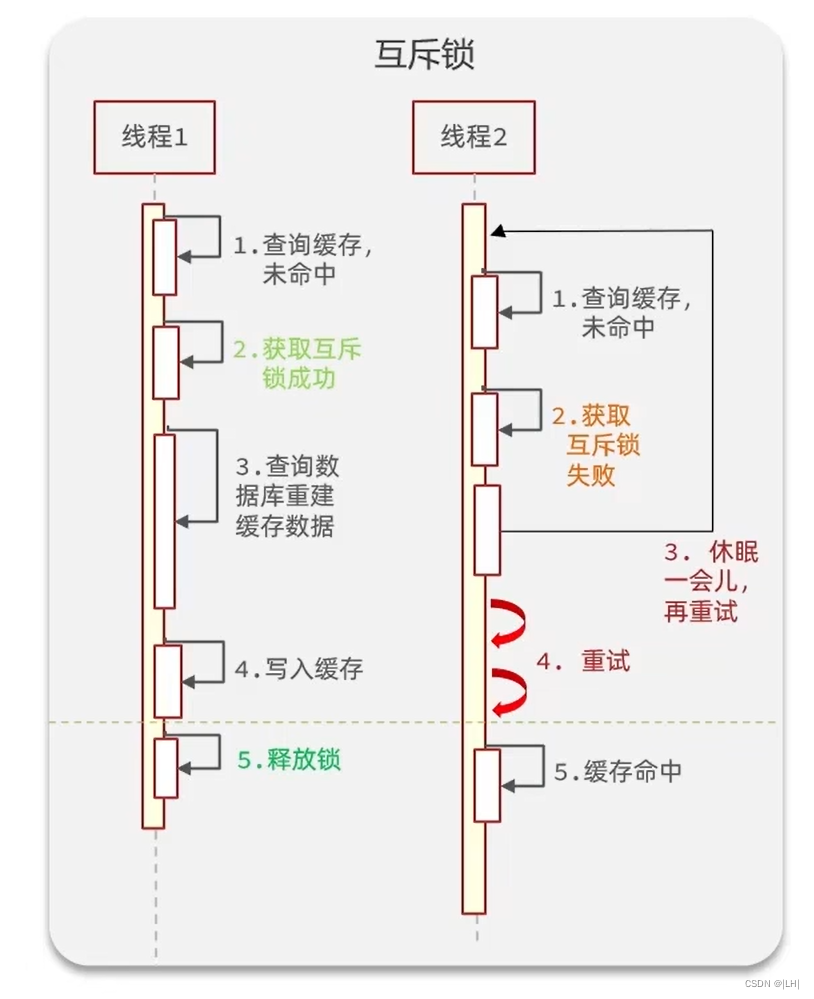
优点:没有额外的内存消耗。保证一致性。实现简单
缺点:线程需要等待,性能受影响。可能有死锁风险
逻辑过期

优点:线程无需等待,性能较好
缺点:不保证一致性。由额外的内存消耗。实现复杂。
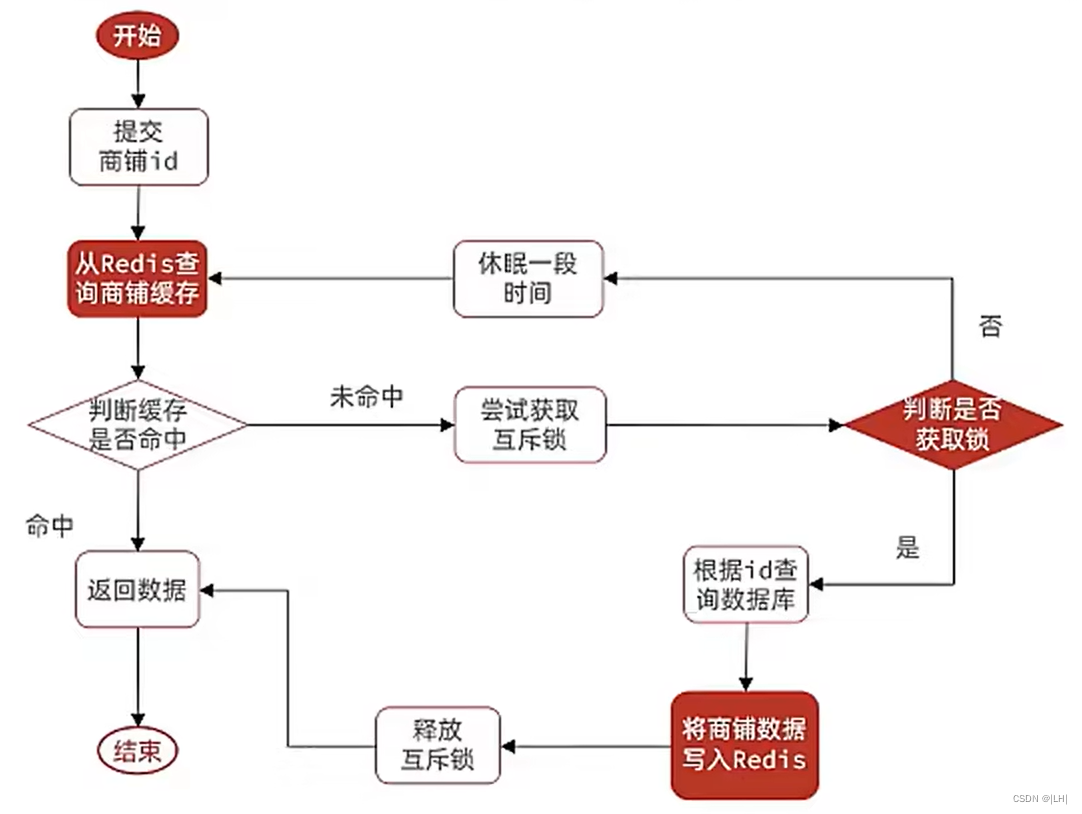
互斥锁解决缓存击穿问题逻辑
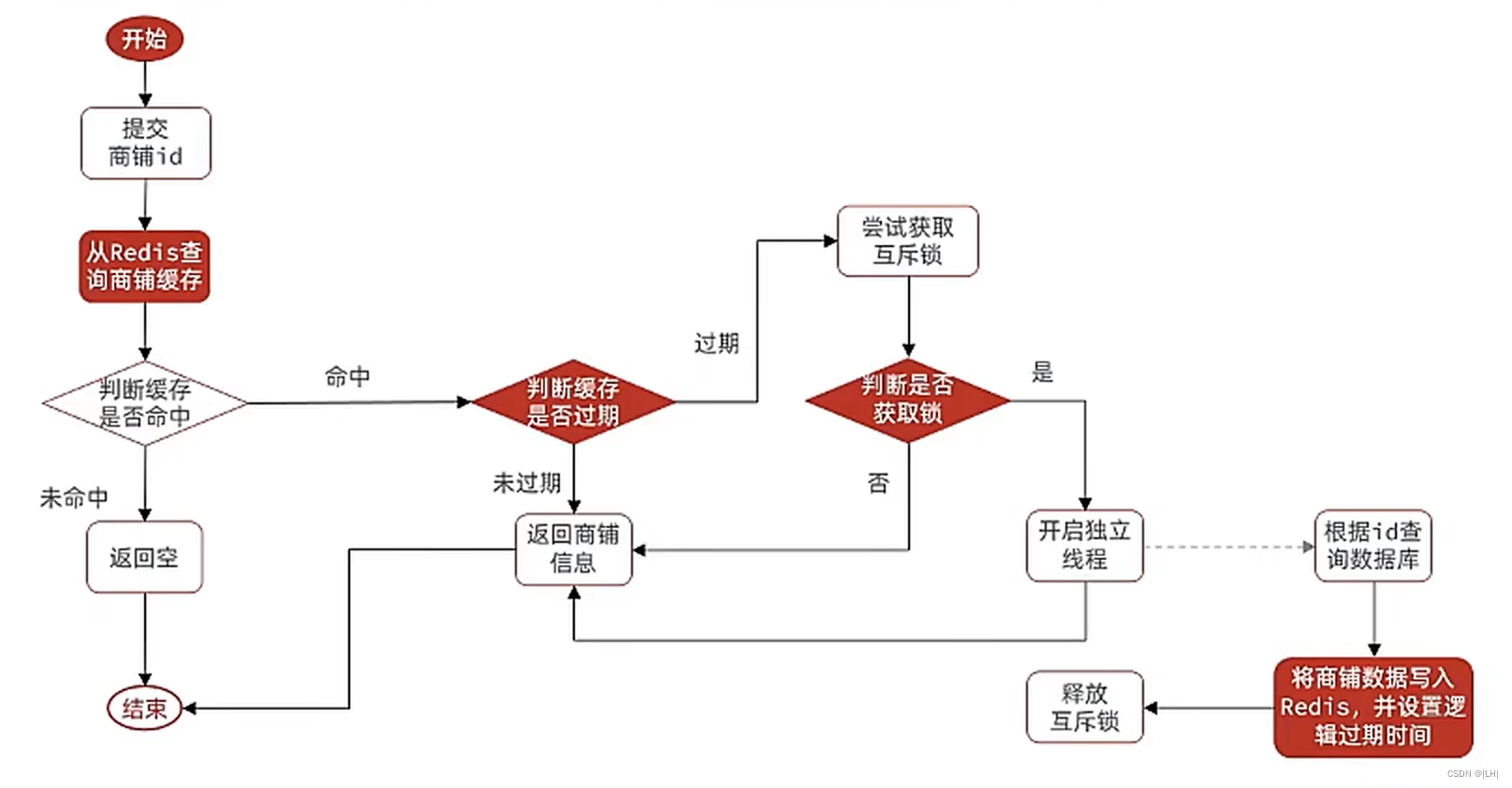
逻辑过期方式解决缓存击穿问题逻辑















 2645
2645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









