







转自http://www.centoscn.com/image-text/install/2014/1121/4158.html
http://www.cnblogs.com/imzye/p/5167599.html
,谢谢作者的贡献
1.1Hadoop介绍
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统(HDFS,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
对于Hadoop的集群来讲,可以分成两大类角色:Master和Salve。一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。从上面的介绍可以看出,HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。HDFS在集群上实现分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
1.2 环境说明
四个节点上均是CentOS6.5系统,并且有一个相同的用户 admin 。
Hadoop2.6.3
cmake-2.8.10.2
1.3网络配置
下面的例子将在Master上进行配置
1)查看机器主机名
#hostnamevim /etc/sysconfig/network3)修改当前机器IP--这个操作同样需要在其他Slave机器上进行配置
执行
#ls /etc/sysconfig/network-scripts#cp /etc/sysconfig/network-scripts/ifcfg-eth0 /etc/sysconfig/network-scripts/ifcfg-Auto_eth1注:因为我使用的是VMWare安装的CentOS6.5系统,安装好一个虚拟机后,在拷贝多个时,一个新的网卡名称被自动被虚拟机创建,所以这里的ifcfg-Auto_eth1根据你的虚拟机的实际名称修改
修改内容如下
IPADDR=192.168.1.177
GATEWAY=192.168.1.255
DNS1=255.255.255.0
查看IP
#ifconfig4)配置Hosts( 必须)---这个操作同样需要在其他Slave机器上进行配置
"/etc/hosts"这个文件是用来配置主机将用的DNS服务器信息,是记载LAN内接续的各主机的对应[HostName和IP]用的。当用户在进行网络连接时,首先查找该文件,寻找对应主机名(或域名)对应的IP地址。
我们要测试两台机器之间知否连通,一般用"ping 机器的IP",如果想用"ping 机器的主机名"发现找不见该名称的机器,解决的办法就是修改"/etc/hosts"这个文件,通过把LAN内的各主机的IP地址和HostName的一一对应写入这个文件的时候,就可以解决问题。
#vim /etc/hosts192.168.1.177 master
192.168.1.159 slave1
192.168.1.128 slave2
现在我们尝试使用ping命令看能否
#ping slave1
1.4所需软件
a.jdk1.8
b.hadoop-2.6.3
2.SSH无密码验证配置
Hadoop运行过程中需要管理远端Hadoop守护进程,在Hadoop启动以后,NameNode是通过SSH(Secure Shell)来启动和停止各个DataNode上的各种守护进程的。这就必须在节点之间执行指令的时候是不需要输入密码的形式,故我们需要配置SSH运用无密码公钥认证的形式,这样NameNode使用SSH无密码登录并启动DataName进程,同样原理,DataNode上也能使用SSH无密码登录到NameNode。
2.1安装和启动SSH协议---从服务器上也要执行如过程
#rpm –qa | grep openssh
#rpm –qa | grep rsync#yum install ssh 安装SSH协议
#yum install rsync (rsync是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件)
#service sshd restart 启动服务2.2配置Master无需密码登陆所有Slave
1)SSH无密码原理
Master(NameNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器Salve(DataNode | Tasktracker)上时,需要在Master上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到所有的Slave上。当Master通过SSH连接Salve时,Salve就会生成一个随机数并用Master的公钥对随机数进行加密,并发送给Master。Master收到加密数之后再用私钥解密,并将解密数回传给Slave,Slave确认解密数无误之后就允许Master进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将客户端Master复制到Slave上。
2)Master机器上生成密码对
在Master节点上执行以下命令:
#ssh-keygen –t rsa –P ''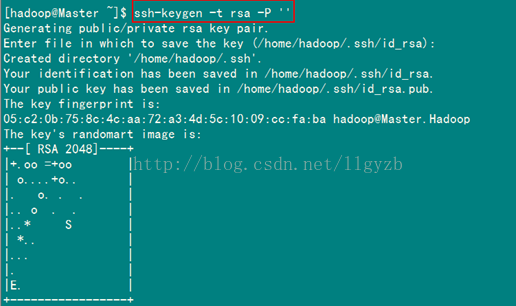
查看"/home/hadoop/"下是否有".ssh"文件夹(我在安装时是默认在/root/.ssh),且".ssh"文件下是否有两个刚生产的无密码密钥对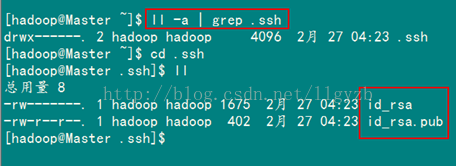
接着在Master节点上做如下配置,把id_rsa.pub追加到授权的key里面去。 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 在验证前,需要做两件事儿。第一件事儿是修改文件"authorized_keys"权限(权限的设置非常重要,因为不安全的设置安全设置,会让你不能使用RSA功能),另一件事儿是用root用户设置"/etc/ssh/sshd_config"的内容。使其无密码登录有效。1)修改文件"authorized_keys" chmod 600 ~/.ssh/authorized_keys
在验证前,需要做两件事儿。第一件事儿是修改文件"authorized_keys"权限(权限的设置非常重要,因为不安全的设置安全设置,会让你不能使用RSA功能),另一件事儿是用root用户设置"/etc/ssh/sshd_config"的内容。使其无密码登录有效。1)修改文件"authorized_keys" chmod 600 ~/.ssh/authorized_keys
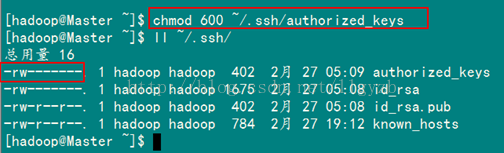
备注:如果不进行设置,在验证时,扔提示你输入密码,在这里花费了将近半天时间来查找原因。
2)设置SSH配置 用root用户登录服务器修改SSH配置文件"/etc/ssh/sshd_config"的下列内容。
#vim /etc/ssh/sshd_configPubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile .ssh/authorized_keys # 公钥文件路径(和上面生成的文件同)
设置完之后记得重启SSH服务,才能使刚才设置有效。
#service sshd restart #ssh localhost

从上图中得知无密码登录本级已经设置完毕,接下来的事儿是把公钥复制所有的Slave机器上。使用下面的命令格式进行复制公钥:
scp ~/.ssh/id_rsa.pub 远程用户名@远程服务器IP:~/
例如:
#scp ~/.ssh/id_rsa.pub hadoop@192.168.1.159:~/上面的命令是复制文件"id_rsa.pub"到服务器IP为"192.168.1.159"的用户为"hadoop"的"/home/hadoop/"下面。
下面就针对IP为"192.168.1.159"的slave1的节点进行配置。
1)把Master.Hadoop上的公钥复制到slave1上
#scp ~./ssh/id_rsa.pub hadoop@192.168.1.159:~/
从上图中我们得知,已经把文件"id_rsa.pub"传过去了,因为并没有建立起无密码连接,所以在连接时,仍然要提示输入输入slave1服务器用户hadoop的密码。为了确保确实已经把文件传过去了,slave1:192.168.1.3服务器,查看"/home/hadoop/"下是否存在这个文件。
2)在"/home/hadoop/"下创建".ssh"文件夹
这一步并不是必须的,如果在slave1的"/home/hadoop"已经存在就不需要创建了,因为我们之前并没有对Slave机器做过无密码登录配置,所以该文件是不存在的。用下面命令进行创建。(备注:用hadoop登录系统,如果不涉及系统文件修改,一般情况下都是用我们之前建立的普通用户hadoop进行执行命令。)
#mkdir ~/.ssh 然后是修改文件夹".ssh"的用户权限,把他的权限修改为"700",用下面命令执行:
#chmod 700 ~/.ssh

3)追加到授权文件"authorized_keys"
到目前为止master的公钥也有了,文件夹".ssh"也有了,且权限也修改了。这一步就是把master的公钥追加到slave1的授权文件"authorized_keys"中去。使用下面命令进行追加并修改"authorized_keys"文件权限:
#cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
#chmod 600 ~/.ssh/authorized_keys

4)用root用户修改"/etc/ssh/sshd_config"
具体步骤参考前面master的"设置SSH配置",具体分为两步:第1是修改配置文件;第2是重启SSH服务。
5)用master使用SSH无密码登录slave1
当前面的步骤设置完毕,就可以使用下面命令格式进行SSH无密码登录了。
ssh 远程服务器IP

从上图我们主要3个地方,第1个就是SSH无密码登录命令,第2、3个就是登录前后"@"后面的机器名变了,由"Master"变为了"Slave1",这就说明我们已经成功实现了SSH无密码登录了。
最后记得把"/home/hadoop/"目录下的"id_rsa.pub"文件删除掉。
rm –r ~/id_rsa.pub

到此为止,我们经过前5步已经实现了从"Master.Hadoop"到"Slave1.Hadoop"SSH无密码登录,下面就是重复上面的步骤把剩余的两台(Slave2.Hadoop和Slave3.Hadoop)Slave服务器进行配置。这样,我们就完成了"配置Master无密码登录所有的Slave服务器"。
2.3 配置所有Slave无密码登录Master
和Master无密码登录所有Slave原理一样,就是把Slave的公钥追加到Master的".ssh"文件夹下的"authorized_keys"中,记得是追加(>>)。
为了说明情况,我们现在就以"Slave1.Hadoop"无密码登录"Master.Hadoop"为例,进行一遍操作,也算是巩固一下前面所学知识,剩余的"Slave2.Hadoop"和"Slave3.Hadoop"就按照这个示例进行就可以了。
首先创建"Slave1.Hadoop"自己的公钥和私钥,并把自己的公钥追加到"authorized_keys"文件中。用到的命令如下:
ssh-keygen –t rsa –P ''
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

接着是用命令"scp"复制"Slave1.Hadoop"的公钥"id_rsa.pub"到"Master.Hadoop"的"/home/hadoop/"目录下,并追加到"Master.Hadoop"的"authorized_keys"中。
1)在"Slave1.Hadoop"服务器的操作
用到的命令如下:
scp ~/.ssh/id_rsa.pub hadoop@192.168.1.2:~/

2)在"Master.Hadoop"服务器的操作
用到的命令如下:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys

然后删除掉刚才复制过来的"id_rsa.pub"文件。

最后是测试从"Slave1.Hadoop"到"Master.Hadoop"无密码登录。

从上面结果中可以看到已经成功实现了,再试下从"Master.Hadoop"到"Slave1.Hadoop"无密码登录。
至此"Master.Hadoop"与"Slave1.Hadoop"之间可以互相无密码登录了,剩下的就是按照上面的步骤把剩余的"Slave2.Hadoop"和"Slave3.Hadoop"与"Master.Hadoop"之间建立起无密码登录。这样,Master能无密码验证登录每个Slave,每个Slave也能无密码验证登录到Master。
4、Hadoop集群安装
所有的机器上都要安装hadoop,现在就先在Master服务器安装,然后其他服务器按照步骤重复进行即可。安装和配置hadoop需要以"root"的身份进行。
4.1 安装hadoop
首先用root用户登录"Master.Hadoop"机器,查看我们之前用FTP上传至"/home/Hadoop"上传的"hadoop-2.6.3.tar.gz"。
接着把"hadoop-1.0.0.tar.gz"复制到"/usr"目录下面。
cp /home/hadoop/hadoop-1.0.0.tar.gz /usr
下一步进入"/usr"目录下,用下面命令把"hadoop-1.0.0.tar.gz"进行解压,并将其命名为"hadoop",把该文件夹的读权限分配给普通用户hadoop,然后删除"hadoop-1.0.0.tar.gz"安装包。
cd /usr #进入"/usr"目录
tar –zxvf hadoop-1.0.0.tar.gz #解压"hadoop-1.0.0.tar.gz"安装包
mv hadoop-1.0.0 hadoop #将"hadoop-1.0.0"文件夹重命名"hadoop"
chown –R hadoop:hadoop hadoop #将文件夹"hadoop"读权限分配给hadoop用户
rm –rf hadoop-1.0.0.tar.gz #删除"hadoop-1.0.0.tar.gz"安装包
最后在"/usr/hadoop"下面创建tmp文件夹,把Hadoop的安装路径添加到"/etc/profile"中,修改"/etc/profile"文件(配置java环境变量的文件),将以下语句添加到末尾,并使其有效:
# set hadoop path
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH :$HADOOP_HOME/bin
1)在"/usr/hadoop"创建"tmp"文件夹
mkdir /usr/hadoop/tmp
2)配置"/etc/profile"
vim /etc/profile
最后配置的文件如下

3)重启"/etc/profile"
source /etc/profile
4.2 配置hadoop
1)配置hadoop-env.sh
该"hadoop-env.sh"文件位于"/usr/hadoop/etc/hadoop"目录下。
在文件的末尾添加下面内容。
# set java environment
export JAVA_HOME=/usr/java/jdk1.6.0_31
Hadoop配置文件在conf目录下,之前的版本的配置文件主要是Hadoop-default.xml和Hadoop-site.xml。由于Hadoop发展迅速,代码量急剧增加,代码开发分为了core,hdfs和map/reduce三部分,配置文件也被分成了三个core-site.xml、hdfs-site.xml、mapred-site.xml。core-site.xml和hdfs-site.xml是站在HDFS角度上配置文件;core-site.xml和mapred-site.xml是站在MapReduce角度上配置文件。
2)配置core-site.xml文件
修改Hadoop核心配置文件core-site.xml,这里配置的是HDFS的地址和端口号。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
(备注:请先在 /usr/hadoop 目录下建立 tmp 文件夹)
<description>A base for other temporary directories.</description>
</property>
<!-- file system properties -->
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master</value>
</property>
<!--
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
-->
</configuration>
备注:如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被干掉,必须重新执行format才行,否则会出错。
3)配置hdfs-site.xml文件
修改Hadoop中HDFS的配置,配置的备份方式默认为3。
<configuration>
<!--
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop2/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop2/hdfs/data</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>
-->
<property>
<name>dfs.replication</name>
<value>2</value>
(备注:replication 是数据副本数量,默认为3,salve少于3台就会报错)
</property>
<configuration>
4)配置mapred-site.xml文件 (这个好像不用配置了,我没有配置也可以运行)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
将java路径加入hadoop-env.sh和yarn-env.sh
echo "export JAVA_HOME=/usr" >> hadoop-env.sh
echo "export JAVA_HOME=/usr" >> yarn-env.sh
5)配置masters文件 (这个文件和上面的配置文件在一个文件夹下,如果没有则需要新建masters文件)
有两种方案:
(1)第一种
修改localhost为Master.Hadoop
(2)第二种
去掉"localhost",加入Master机器的IP:192.168.1.2
为保险起见,启用第二种,因为万一忘记配置"/etc/hosts"局域网的DNS失效,这样就会出现意想不到的错误,但是一旦IP配对,网络畅通,就能通过IP找到相应主机。
用下面命令进行修改:
6)配置slaves文件(Master主机特有)
有两种方案:
(1)第一种
去掉"localhost",每行只添加一个主机名,把剩余的Slave主机名都填上。
例如:添加形式如下
Slave1.Hadoop
Slave2.Hadoop
Slave3.Hadoop
(2)第二种
去掉"localhost",加入集群中所有Slave机器的IP,也是每行一个。
例如:添加形式如下
192.168.1.3
192.168.1.4
192.168.1.5
原因和添加"masters"文件一样,选择第二种方式。
用下面命令进行修改:
现在在Master机器上的Hadoop配置就结束了,剩下的就是配置Slave机器上的Hadoop。
一种方式是按照上面的步骤,把Hadoop的安装包在用普通用户hadoop通过"scp"复制到其他机器的"/home/hadoop"目录下,然后根据实际情况进行安装配置,除了第6步,那是Master特有的。用下面命令格式进行。(备注:此时切换到普通用户hadoop)
scp ~/hadoop-1.0.0.tar.gz hadoop@服务器IP:~/
例如:从"Master.Hadoop"到"Slave1.Hadoop"复制Hadoop的安装包。
另一种方式是将 Master上配置好的hadoop所在文件夹"/usr/hadoop"复制到所有的Slave的"/usr"目录下(实际上Slave机器上的slavers文件是不必要的, 复制了也没问题)。用下面命令格式进行。(备注:此时用户可以为hadoop也可以为root)
scp -r /usr/hadoop root@服务器IP:/usr/
例如:从"Master.Hadoop"到"Slave1.Hadoop"复制配置Hadoop的文件。

上图中以root用户进行复制,当然不管是用户root还是hadoop,虽然Master机器上的"/usr/hadoop"文件夹用户hadoop有权限,但是Slave1上的hadoop用户却没有"/usr"权限,所以没有创建文件夹的权限。所以无论是哪个用户进行拷贝,右面都是"root@机器IP"格式。因为我们只是建立起了hadoop用户的SSH无密码连接,所以用root进行"scp"时,扔提示让你输入"Slave1.Hadoop"服务器用户root的密码。
查看"Slave1.Hadoop"服务器的"/usr"目录下是否已经存在"hadoop"文件夹,确认已经复制成功。查看结果如下:

从上图中知道,hadoop文件夹确实已经复制了,但是我们发现hadoop权限是root,所以我们现在要给"Slave1.Hadoop"服务器上的用户hadoop添加对"/usr/hadoop"读权限。
以root用户登录"Slave1.Hadoop",执行下面命令。
chown -R hadoop:hadoop(用户名:用户组) hadoop(文件夹)

接着在"Slave1 .Hadoop"上修改"/etc/profile"文件(配置 java 环境变量的文件),将以下语句添加到末尾,并使其有效(source /etc/profile):
# set hadoop environment
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH :$HADOOP_HOME/bin
如果不知道怎么设置,可以查看前面"Master.Hadoop"机器的"/etc/profile"文件的配置,到此为此在一台Slave机器上的Hadoop配置就结束了。剩下的事儿就是照葫芦画瓢把剩余的几台Slave机器按照
4.3 启动及验证
1)格式化HDFS文件系统
在"Master.Hadoop"上使用普通用户hadoop进行操作。(备注:只需一次,下次启动不再需要格式化,只需 start-all.sh)
hadoop namenode -format
某些书上和网上的某些资料中用下面命令执行。

我们在看好多文档包括有些书上,按照他们的hadoop环境变量进行配置后,并立即使其生效,但是执行发现没有找见"bin/hadoop"这个命令。
其实我们会发现我们的环境变量配置的是"$HADOOP_HOME/bin",我们已经把bin包含进入了,所以执行时,加上"bin"反而找不到该命令,除非我们的hadoop坏境变量如下设置。
# set hadoop path
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH : $HADOOP_HOME :$HADOOP_HOME/bin
这样就能直接使用"bin/hadoop"也可以直接使用"hadoop",现在不管哪种情况,hadoop命令都能找见了。我们也没有必要重新在设置hadoop环境变量了,只需要记住执行Hadoop命令时不需要在前面加"bin"就可以了。
执行如下命令:
#hadoop namenode -format

从上图中知道我们已经成功格式话了,但是美中不足就是出现了一个警告,从网上的得知这个警告并不影响hadoop执行,但是也有办法解决,详情看后面的"常见问题FAQ"。
5.启动集群
启动hdfs
#/usr/local/hadoop2/sbin/start-dfs.sh启动yarn#/usr/local/hadoop2/sbin/start-yarn.sh#/usr/local/hadoop2/bin/hdfs dfsadmin -report
集群运行状态:http://master_id:50070
集群应用状态:http://m.fredlab.org:8088
http://master_ip:8088
查看各个节点java进程
NameNode,m.fredlab.org上执行:jps
12058 ResourceManager
22298 NameNode
11914 SecondaryNameNode
11180 Jps
DataNode,s1.fredlab.org上执行:jps
13909 Jps
13494 DataNode















 215
215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









