







一、安装虚拟机
二、环境nat配置
Nat设置:查看得到192.168.201.2
su命令,打开以下文件,删除其他行以得到下图:

添加以下行:

对slave1和slave2也做同样操作:

三、配置JDK环境
共享目录share到Linux系统(/mnt/hgfs/share)





配置文件修改:
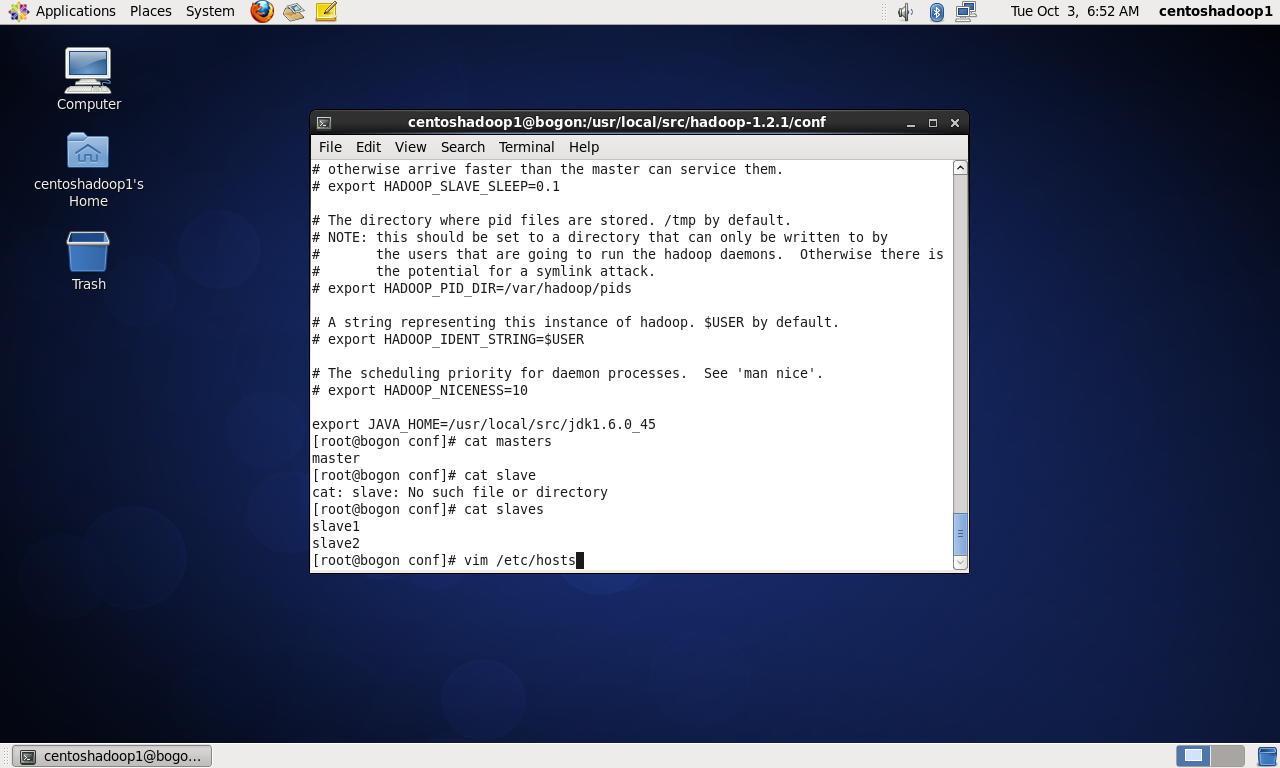
修改~/.bashrc文件



配置slave1和slave2:

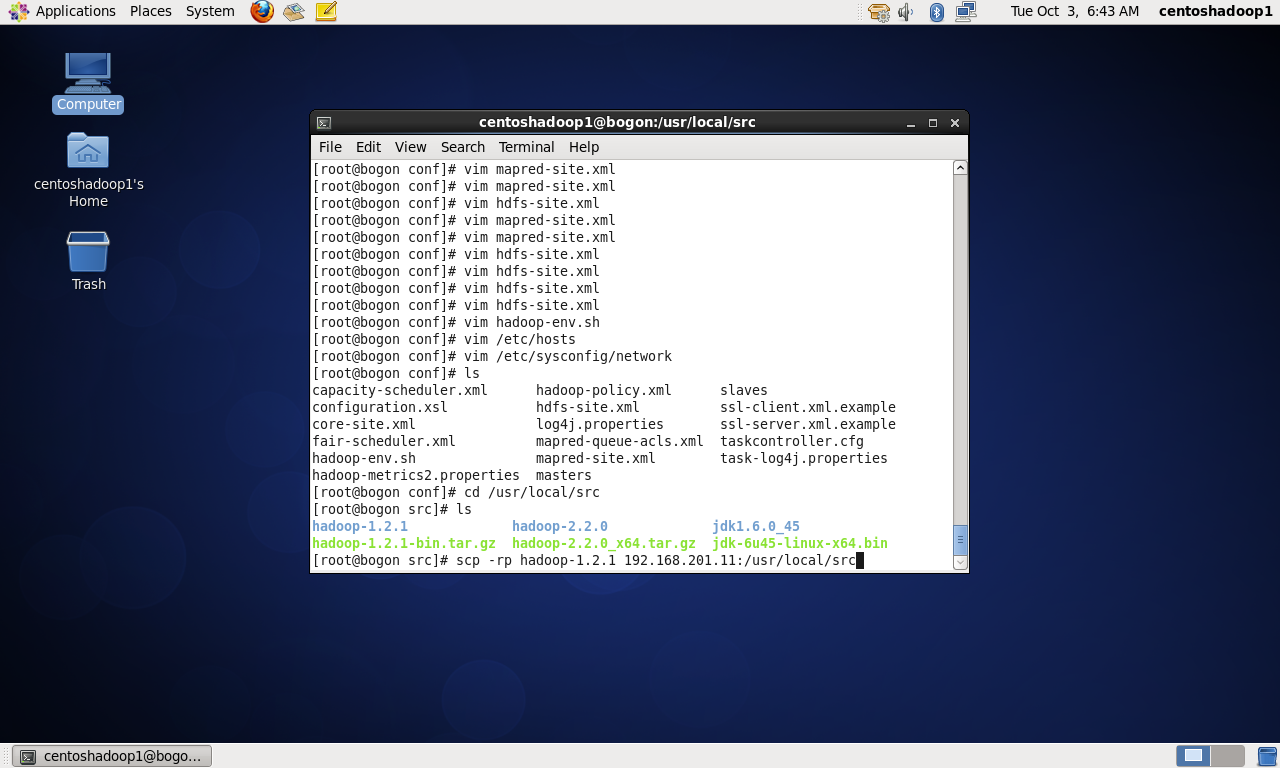
四、开始安装hadoop

tmp文件存放临时文件:

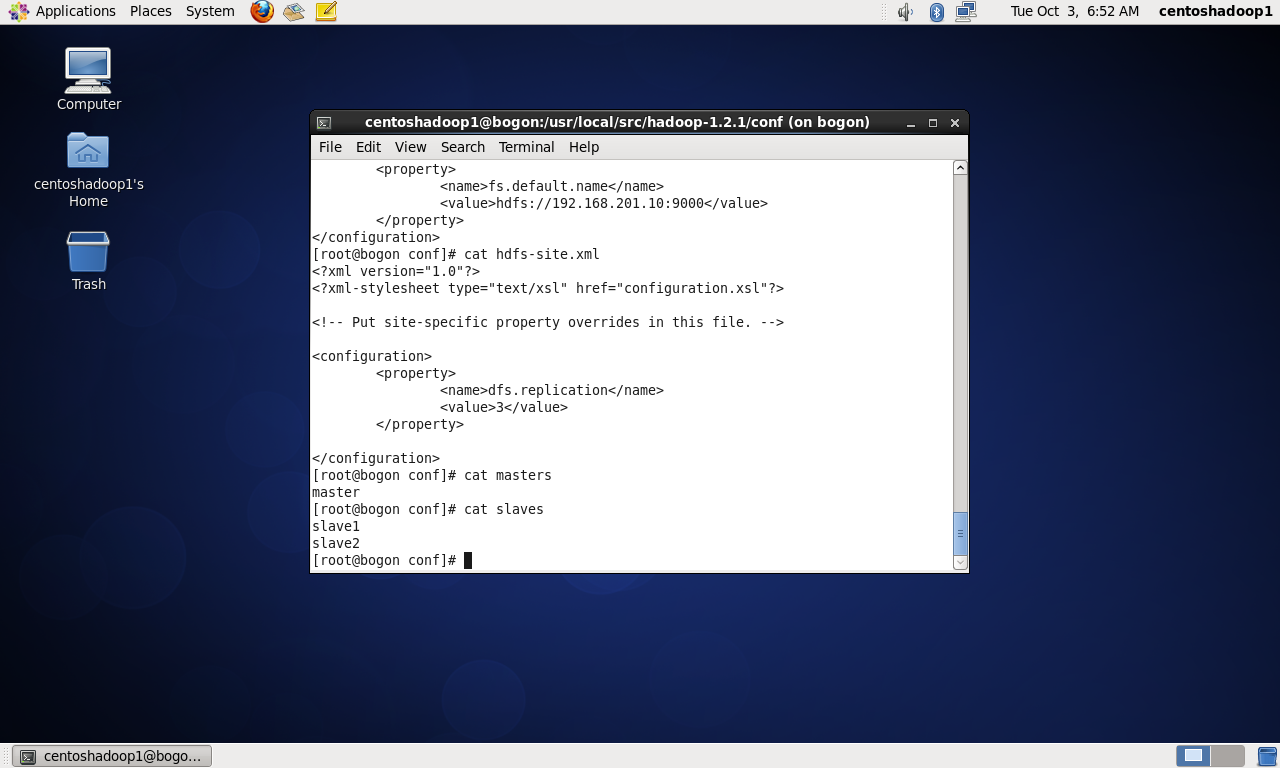
vim masters:把文件内容改为master











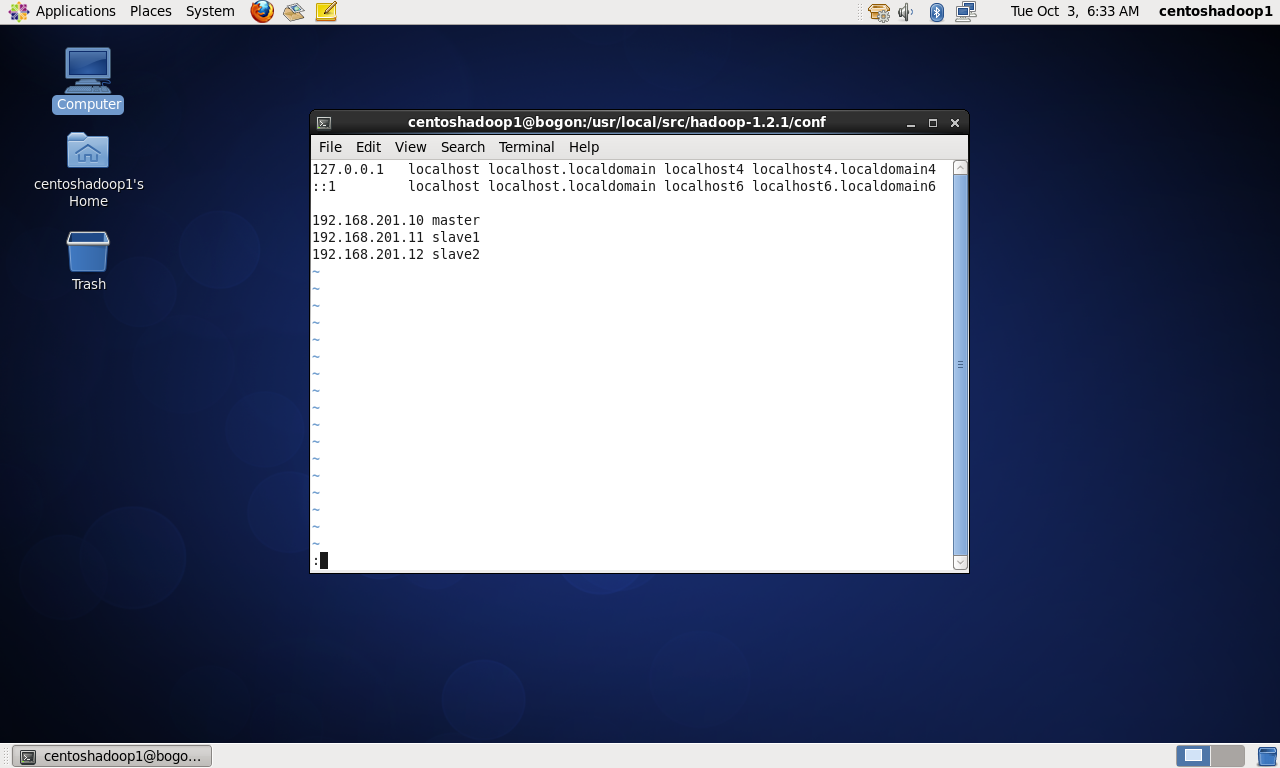
slave1和slave2做同样修改,为了访问机器的时候不用输入IP地址


slave1和slave2也做类似修改
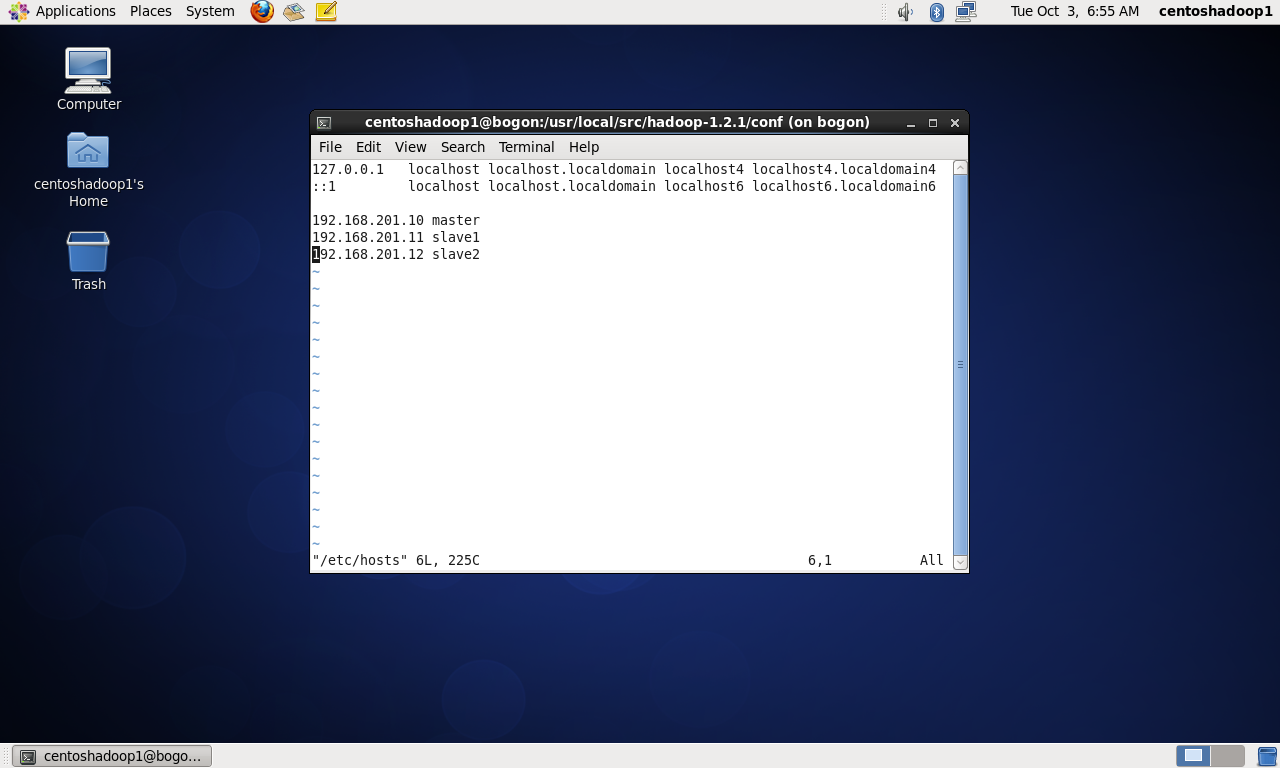


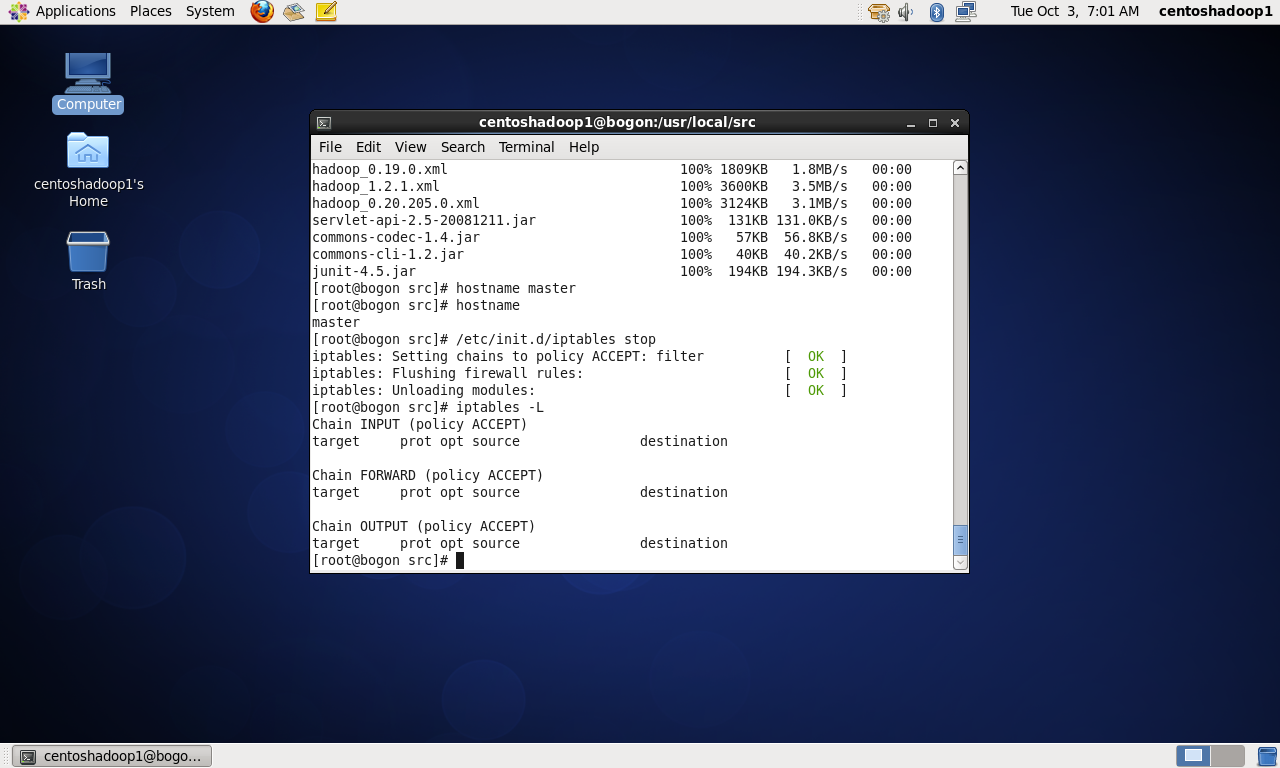
关闭防火墙
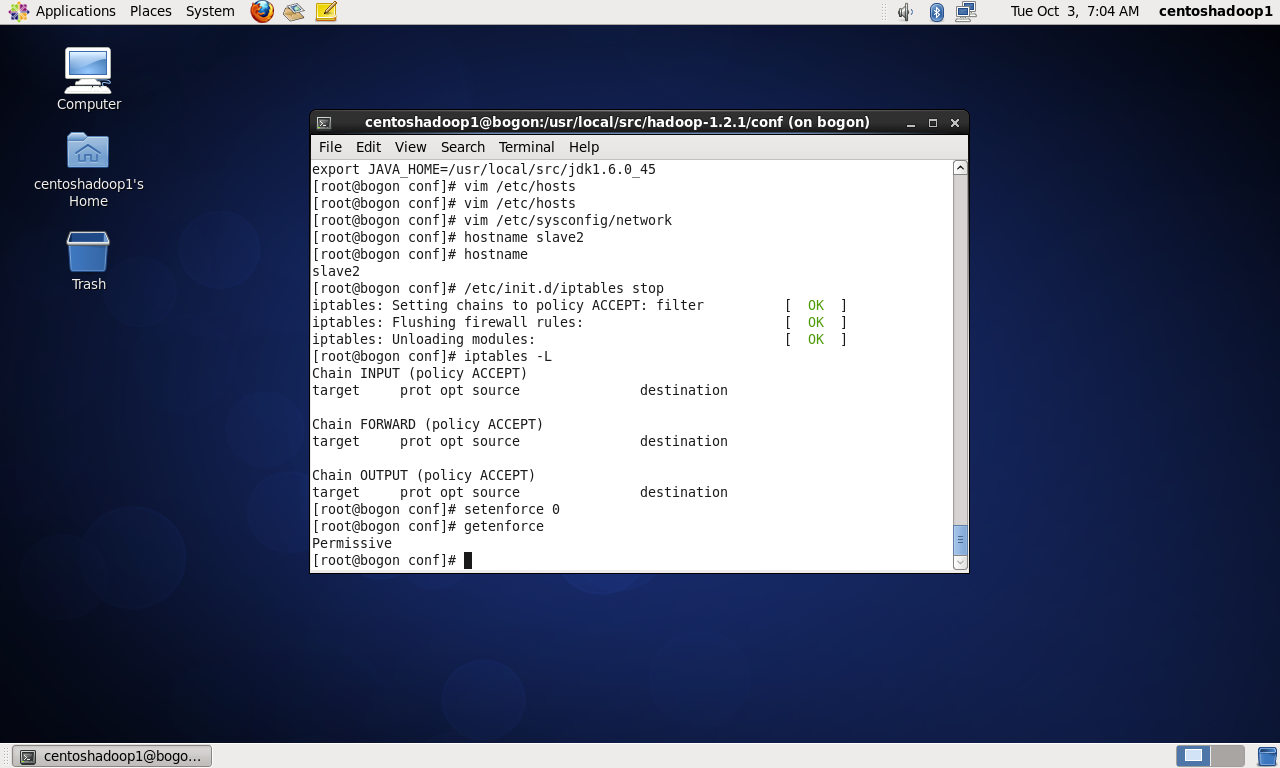
关闭selinux
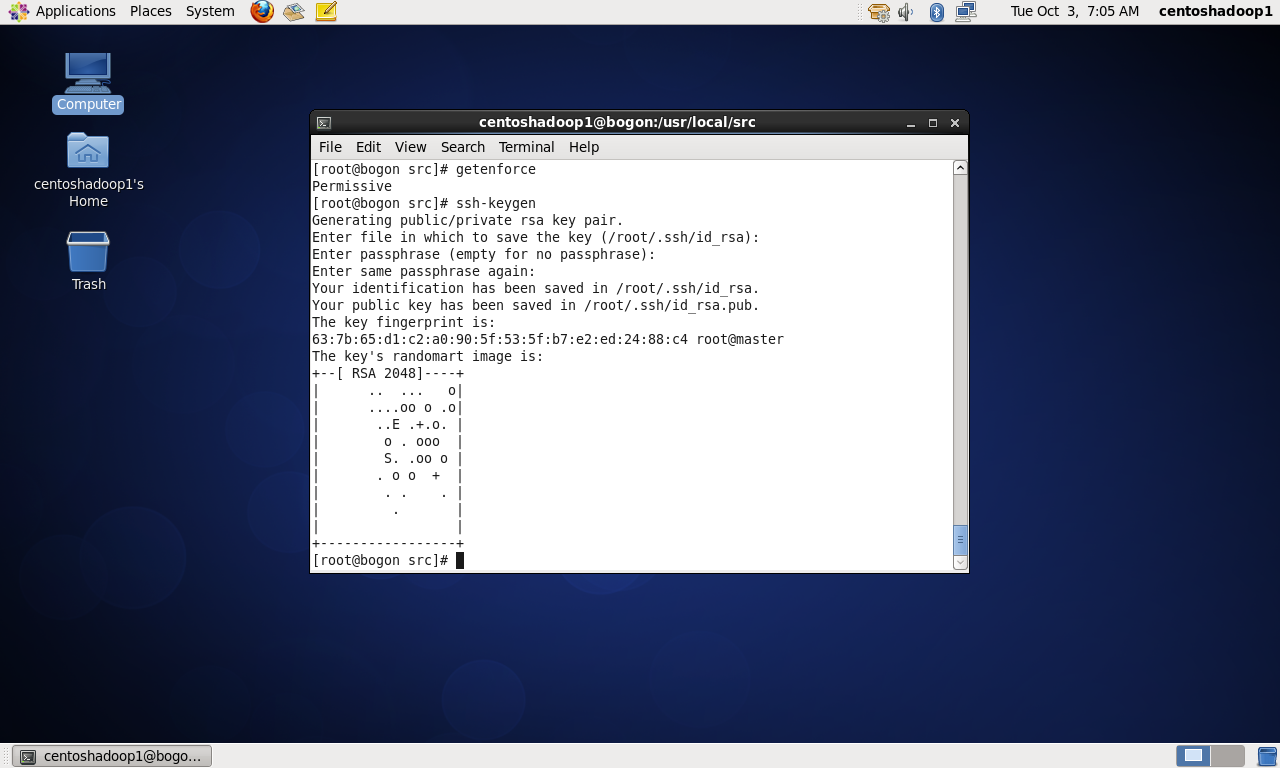
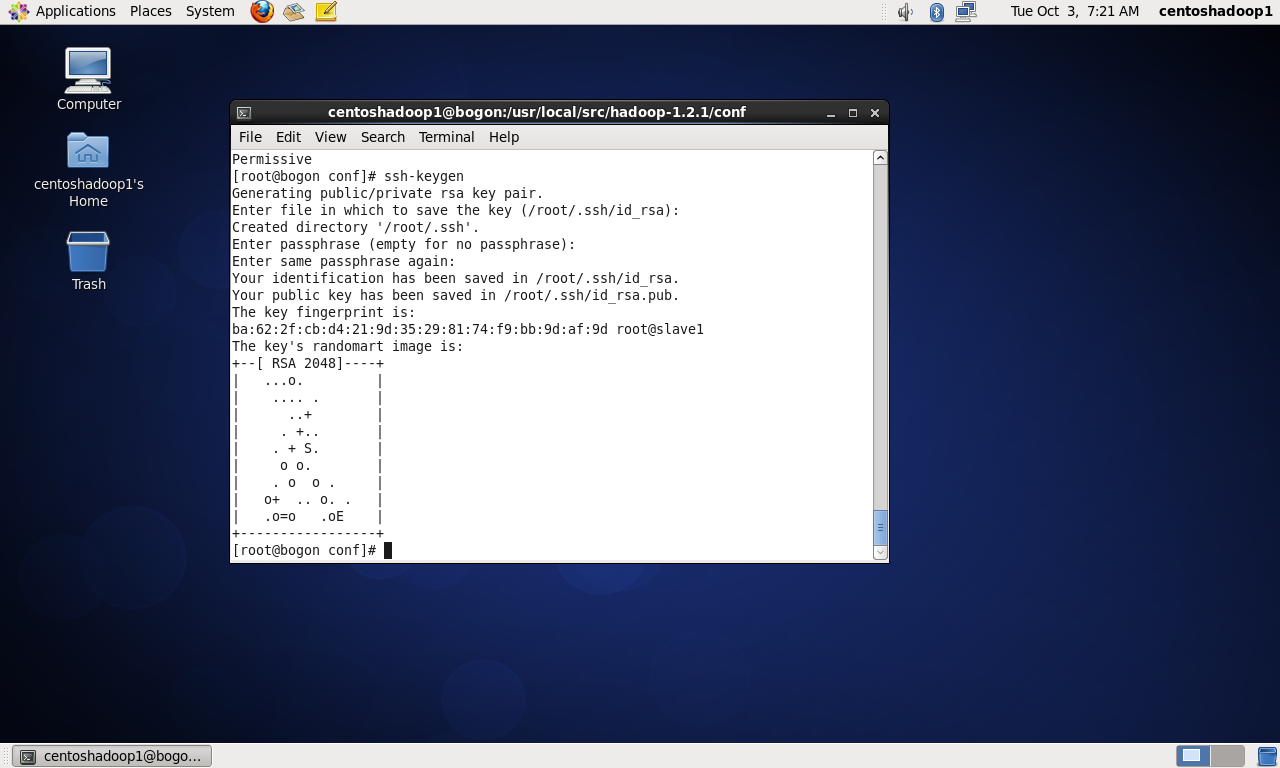
配置ssh免登陆密码
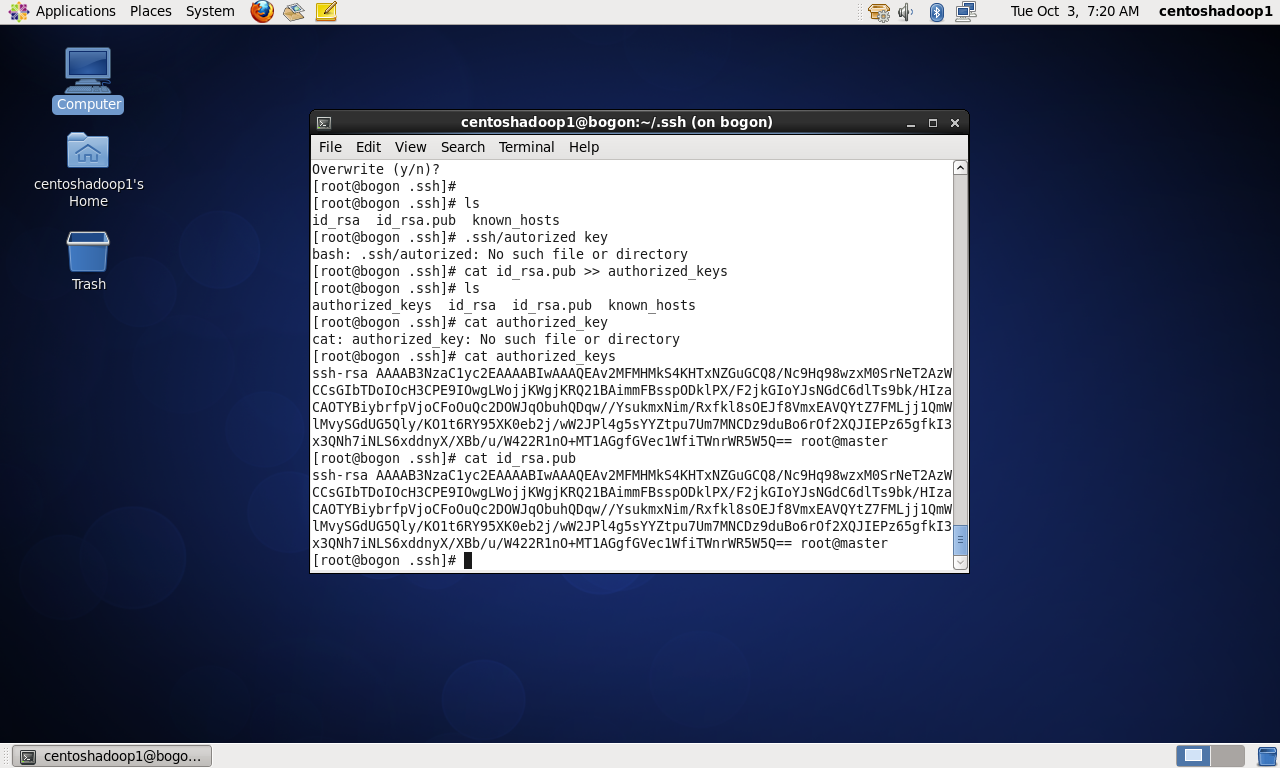
对slave1和slave2也做类似修改
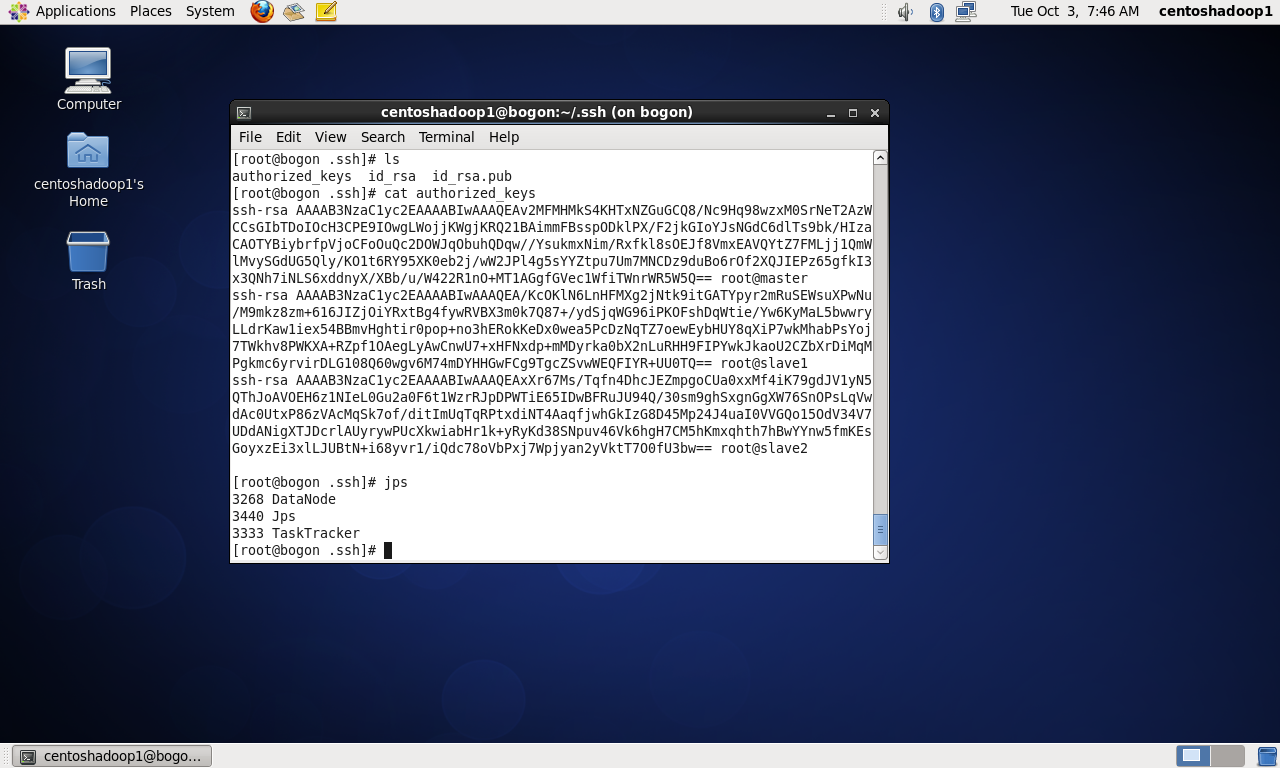
PS:注意本人操作的时候并没有authorized keys文件,所以通过master机器复制id_rsa.pub并重定向到authorized keys文件,从而创建了这个文件。
然后把slave1和slave2的id_rsa.pub文件的内容依次复制到master的authorized keys文件里。

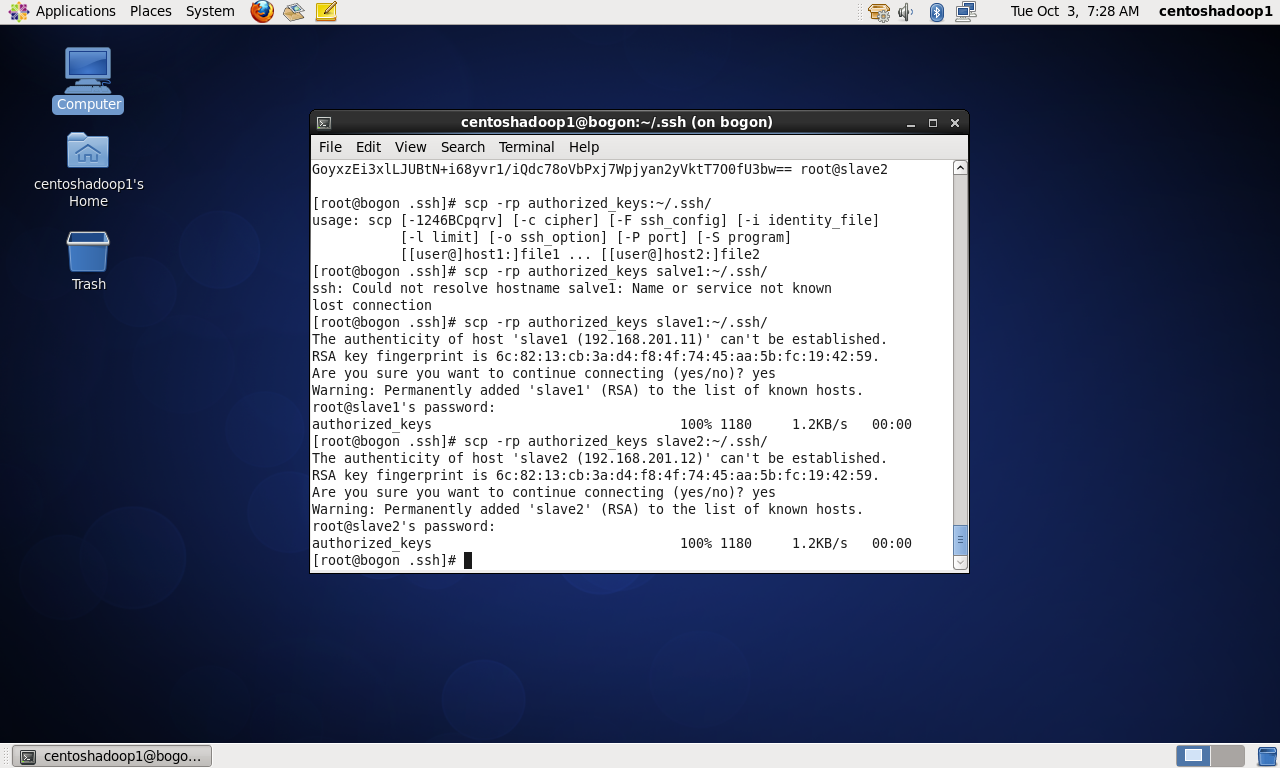
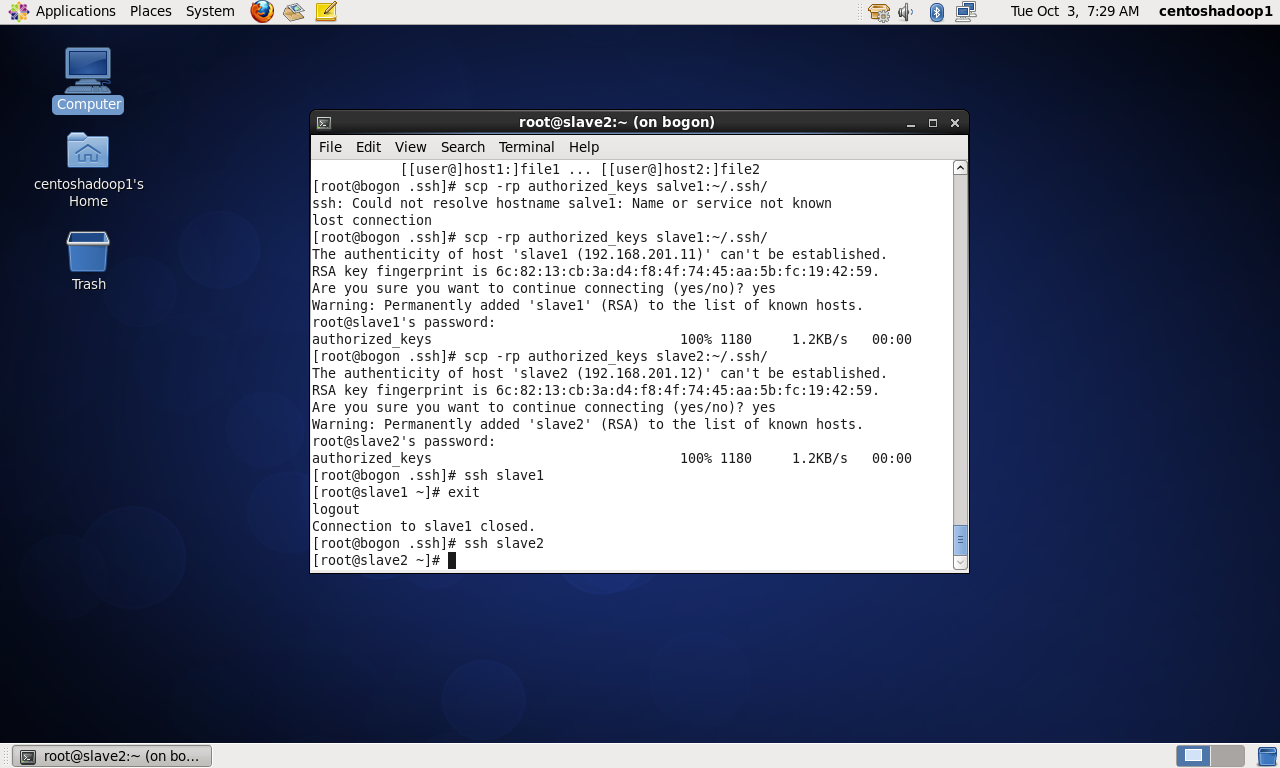
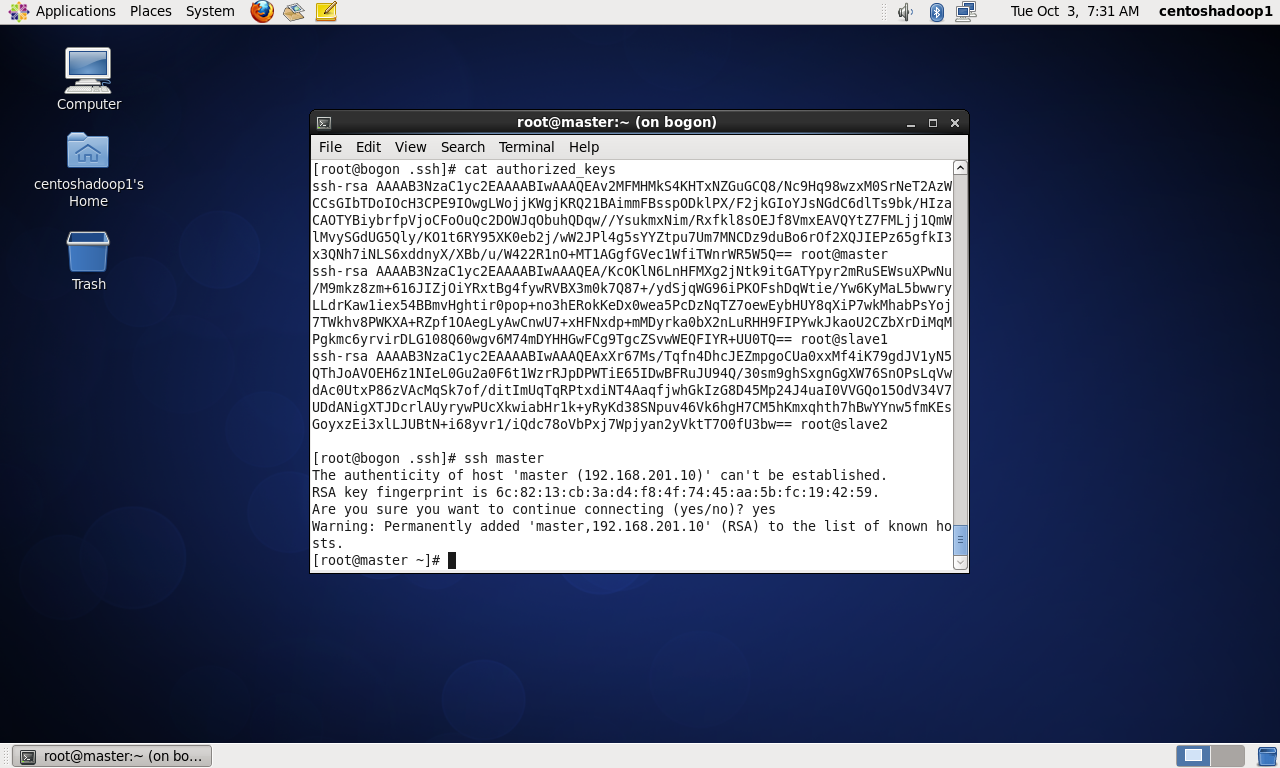
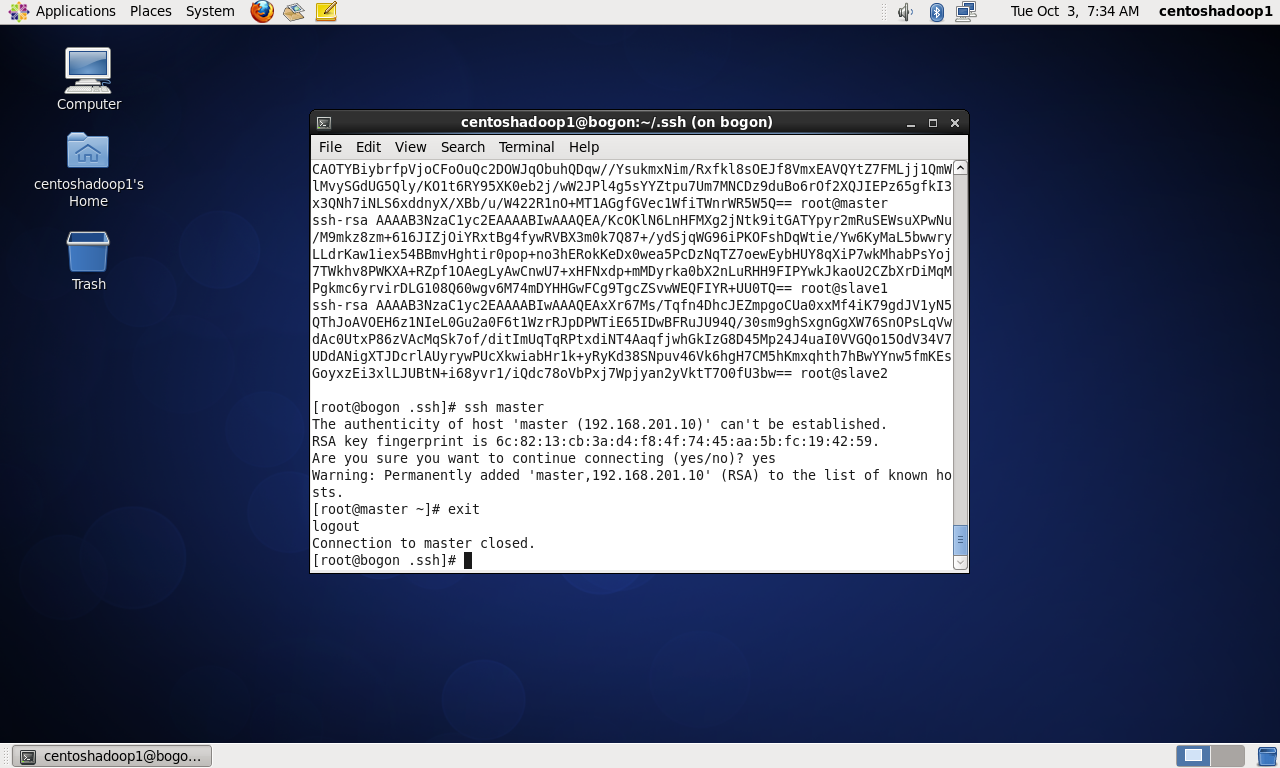

五、验证hadoop集群是否已搭建好9
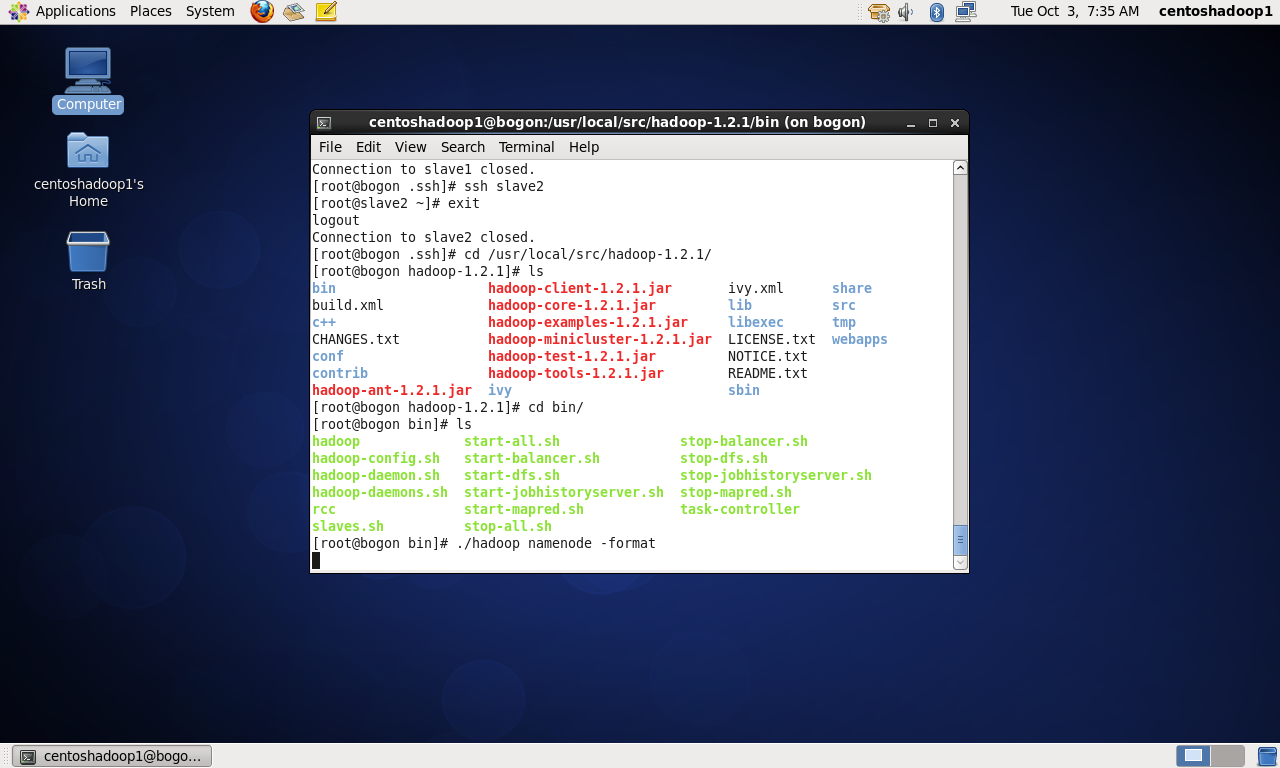
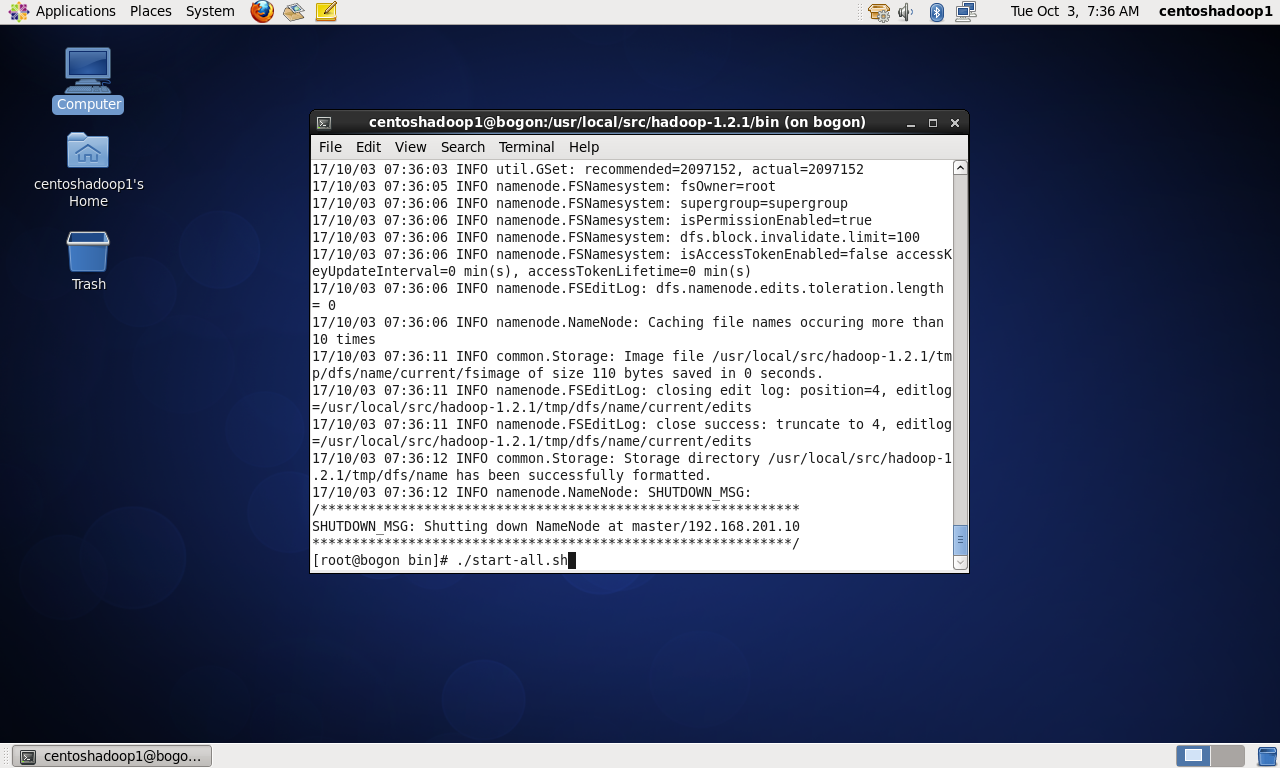


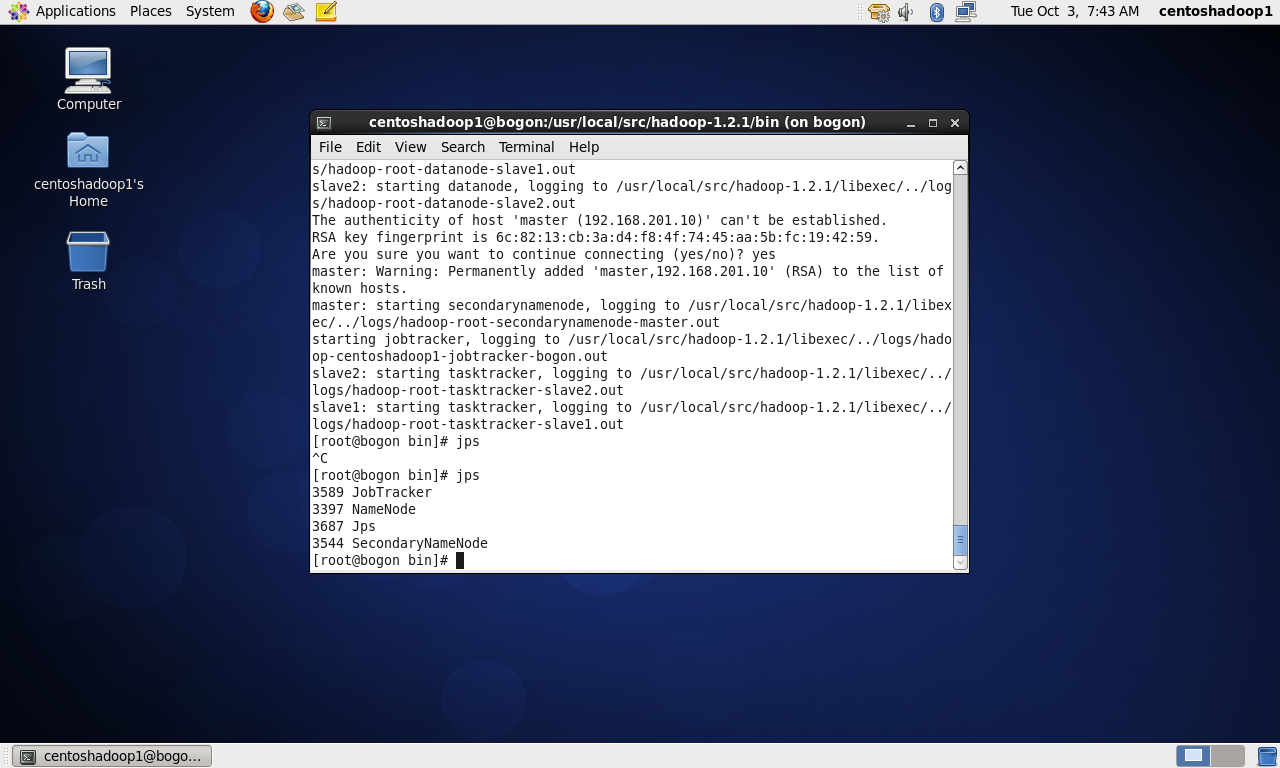
以下是针对slave1和slave2的验证
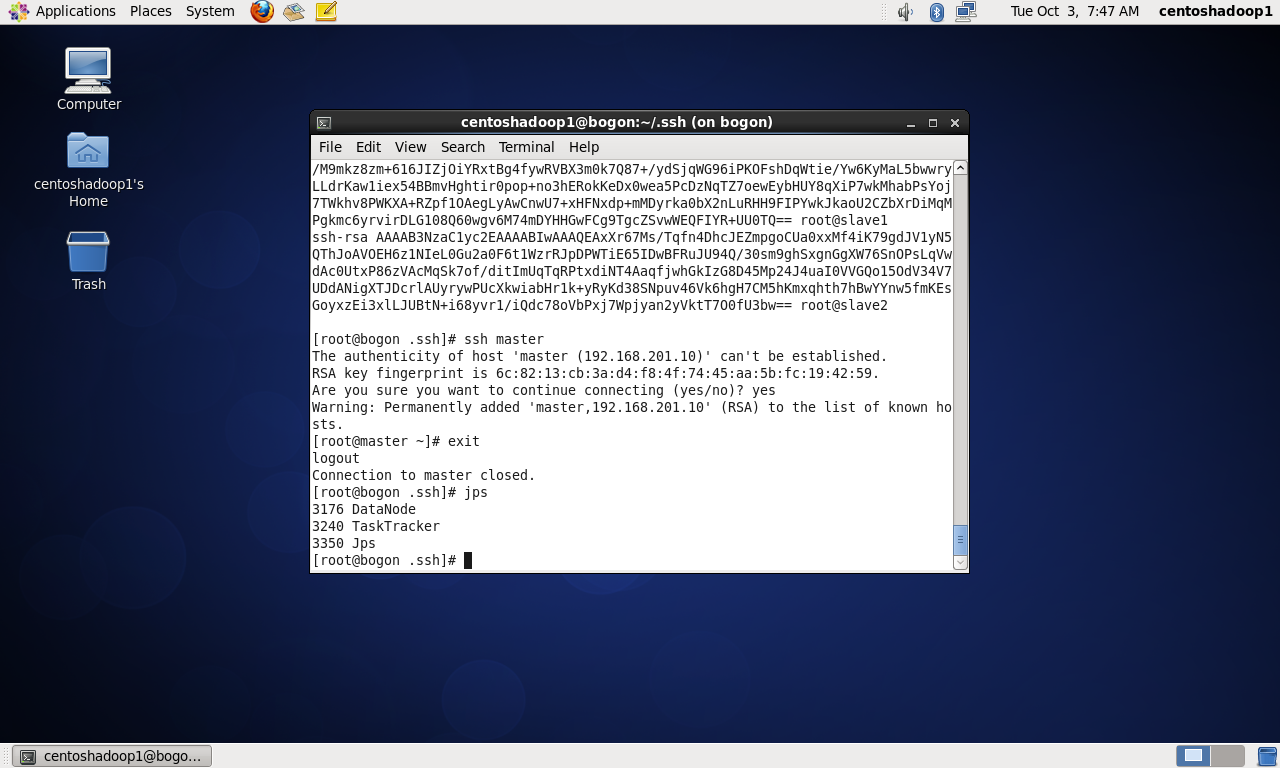
回到master机器上:
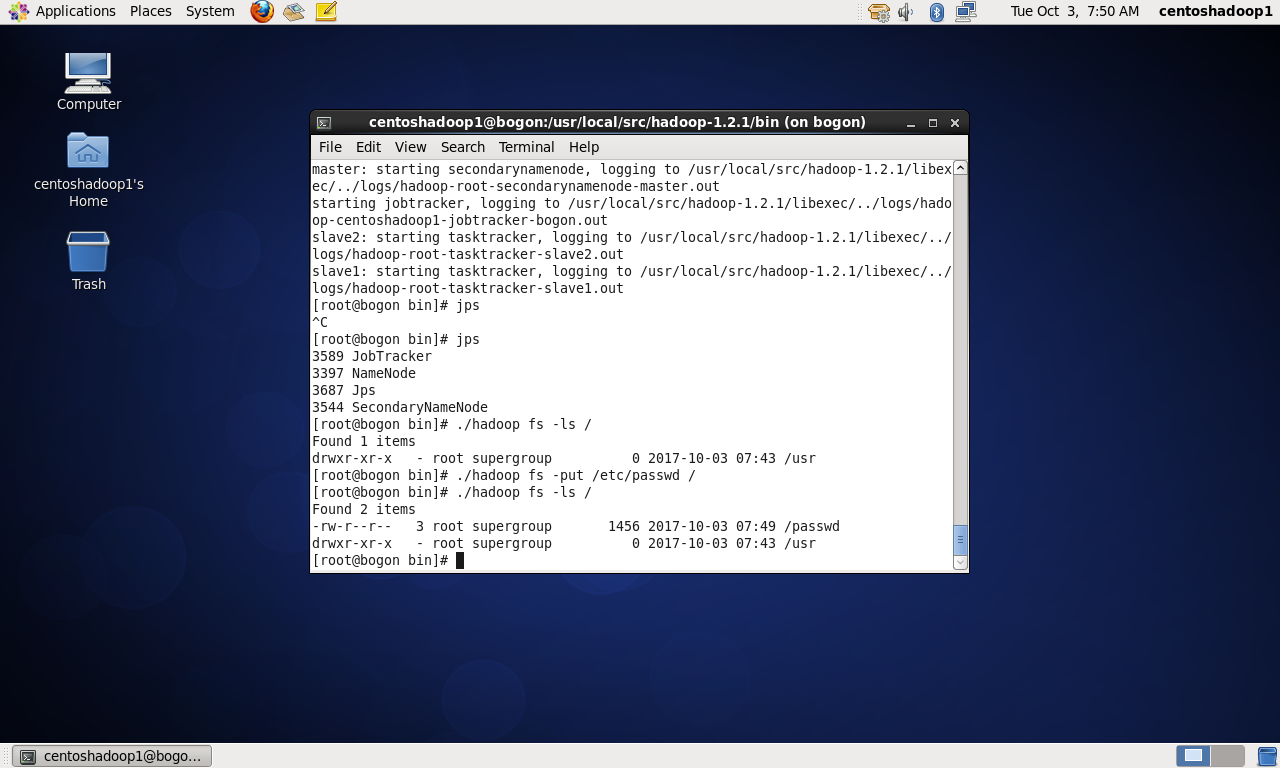

至此,成功搭建hadoop集群。
Hadoop安装教程参考:
1、http://www.cnblogs.com/studyzy/p/4389891.html
2、http://www.cnblogs.com/xzjf/p/7231519.html
3、http://blog.csdn.net/downing114/article/details/62883041(most important)
4、http://blog.csdn.net/se7en_q/article/details/47258007















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









