






二叉树
二叉树的定义:
链式存储:
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
//以下是练习
public class TreeNode{
int val;
TreeNode left;
TreeNode right;
TreeNode() { }
TreeNode(int val) { this.val = val; } //注意定义参数类型 ,别忘记写int
TreeNode(int val,TreeNode left,TreeNode right) {
this.val=val;
this.left=left;
this.right=right;
}
}结点 定义需要会手写!!!!!
二叉树的遍历方式
二叉树主要有两种遍历方式:
- 深度优先遍历:先往深走,遇到叶子节点再往回走。
- 广度优先遍历:一层一层的去遍历。
- 深度优先遍历
- 前序遍历(递归法,迭代法)
- 中序遍历(递归法,迭代法)
- 后序遍历(递归法,迭代法)
- 广度优先遍历
- 层次遍历(迭代法)
在深度优先遍历中:有三个顺序,前中后序遍历, 有同学总分不清这三个顺序,经常搞混,我这里教大家一个技巧。
这里前中后,其实指的就是中间节点的遍历顺序,只要大家记住 前中后序指的就是中间节点的位置就可以了。
看如下中间节点的顺序,就可以发现,中间节点的顺序就是所谓的遍历方式
- 前序遍历:中左右
- 中序遍历:左中右
- 后序遍历:左右中
二叉树的递归遍历(三种遍历)
// 前序遍历·递归·LC144_二叉树的前序遍历
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
//注意这里是TreeNode root, 跟C加加里的TreeNode *root不同
List<Integer> result = new ArrayList<Integer>();
preorder(root, result);
return result;
}
public void preorder(TreeNode root, List<Integer> result) {
if (root == null) { //这里的null是小写 ,结点root判断为空 用 root == null
return;
}
result.add(root.val);
preorder(root.left, result);
preorder(root.right, result);
}
}
// 中序遍历·递归·LC94_二叉树的中序遍历
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> result= new ArrayList<Integer>();
inorder(root,result);
return result;
}
void inorder(TreeNode root,List<Integer> result){
if(root == null) { return ; }
inorder(root.left,result);
result.add(root.val);
inorder(root.right,result);
}
}
// 后序遍历·递归·LC145_二叉树的后序遍历
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
postorder(root, res);
return res;
}
void postorder(TreeNode root, List<Integer> list) {
if (root == null) {
return;
}
postorder(root.left, list);
postorder(root.right, list);
list.add(root.val); // 注意这一句
}
}if (root == null) { //这里的null是小写 ,结点root判断为空 用 root == null
return;}
求二叉树的最大深度
前序查找
class Solution {
public:
int result;
void getDepth(TreeNode* node, int depth) {
result = depth > result ? depth : result; // 中
if (node->left == NULL && node->right == NULL) return ;
if (node->left) { // 左
depth++; // 深度+1
getDepth(node->left, depth);
depth--; // 回溯,深度-1
}
if (node->right) { // 右
depth++; // 深度+1
getDepth(node->right, depth);
depth--; // 回溯,深度-1
}
return ;
}
int maxDepth(TreeNode* root) {
result = 0;
if (root == 0) return result;
getDepth(root, 1);
return result;
}
};简化代码如下:
class Solution {
public:
int result;
void getDepth(TreeNode* node, int depth) {
result = depth > result ? depth : result; // 中
if (node->left == NULL && node->right == NULL) return ;
if (node->left) { // 左
getDepth(node->left, depth + 1);
}
if (node->right) { // 右
getDepth(node->right, depth + 1);
}
return ;
}
int maxDepth(TreeNode* root) {
result = 0;
if (root == 0) return result;
getDepth(root, 1);
return result;
}
};两者的区别: 回溯!!!! 递归函数自动回溯!
depth++; // 深度+1
getDepth(node->right, depth);
depth--;
在简化写法中 写成了:
getDepth(node->right, depth + 1);
为什么后者不需要 depth--?
在递归函数中,当递归调用结束后,会自动回溯到调用该递归函数的地方。也就是说,在递归函数中对深度的修改会在递归结束后自动回溯到调用该递归函数的地方。
在这段代码中,每次调用递归函数时,传递的参数depth+1会在递归结束后自动回溯到上一层递归的地方,所以不需要手动减少深度。
如果将getdepth(node->right, depth + 1)写成depth++; getdepth(node->right, depth);的话,确实需要在递归调用结束后手动减少深度。因为在这种情况下,depth的值在递归调用之前就已经增加了,所以在递归结束后需要手动减少深度,以保持深度的正确性
找树左下角的值
方法1:层序遍历是非常简单(迭代法)
方法2:递归遍历(递归法)
// 递归法
class Solution {
private int Deep = -1;
private int value = 0;
public int findBottomLeftValue(TreeNode root) {
value = root.val;
findLeftValue(root,0);
return value;
}
private void findLeftValue (TreeNode root,int deep) {
if (root == null) return;
if (root.left == null && root.right == null) {
if (deep > Deep) {
value = root.val;
Deep = deep;
}
}
if (root.left != null) findLeftValue(root.left,deep + 1);
if (root.right != null) findLeftValue(root.right,deep + 1);
}
}这里怎么保证得到是最左边的叶子节点的值?
关键在这里 if (deep > Deep) ,由于先遍历root.left,即先访问最大深度最左边的节点,Deep已经更新到最大值了,后面遍历到右边的节点, 也不会满足if条件语句,因此也不会改变value的值,这样保证value是最左边的叶子节点!
路径总和
完整正确代码:
class solution {
public boolean haspathsum(treenode root, int targetsum) {
if (root == null) {
return false;
}
targetsum -= root.val;
// 叶子结点
if (root.left == null && root.right == null) {
return targetsum == 0;
}
if (root.left != null) {
boolean left = haspathsum(root.left, targetsum);
if (left) { // 已经找到
return true;
}
}
if (root.right != null) {
boolean right = haspathsum(root.right, targetsum);
if (right) { // 已经找到
return true;
}
}
return false;
}
}这里有个容易犯错的地方,if (left)语句为什么后面不能添加 else, 返回false;或者能不能直接写成 return haspathsum(root.left, targetsum) ; 答案是不能的!
错误代码:
if(root.left!=null){
boolean x = hasPathSum(root.left,targetSum);
if(x){
return true;
}
return false;
}虽然这个代码段的逻辑是正确的,但是可能导致结果不符合预期的原因可能是在遍历树的过程中,没有正确地处理右子树的情况。
在你的代码中,当左子树存在时,首先递归调用hasPathSum函数来检查左子树是否存在满足条件的路径。如果左子树存在满足条件的路径,那么会立即返回true;否则,会继续执行下面的代码。
在下面的代码中,你返回了false,这是一个问题。因为在这种情况下,你没有正确处理右子树的情况。如果右子树存在满足条件的路径,但是在这里你返回了false,导致整个函数返回了false,而不是返回true。
为了解决这个问题,你可以在左子树的情况下,继续检查右子树是否存在满足条件的路径。只有当左子树和右子树都不存在满足条件的路径时,才返回false。下面是修复后的代码示例:
if (root.left != null) {
boolean left = hasPathSum(root.left, targetSum);
if (left) {
return true;
}
}
if (root.right != null) {
boolean right = hasPathSum(root.right, targetSum);
if (right) {
return true;
}
}
return false;
空节点也是二叉搜索树
进行判断是否是二叉搜索树时,注意二叉搜索树也可以为空,判定为true
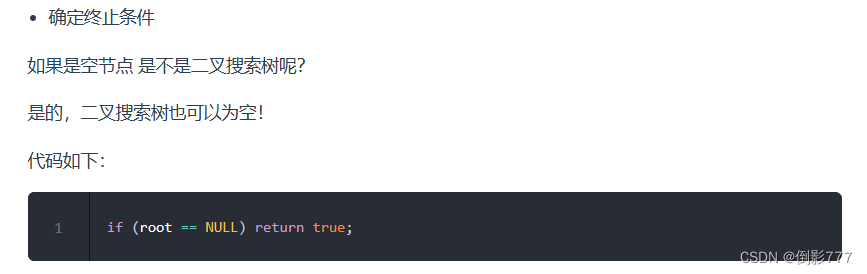
注意上面是C++写法,JAVA中null 要小写
JAVA语法相关
在Java中,常用的`List`接口的实现类有以下几种:
1. `ArrayList`:基于动态数组实现的`List`,支持随机访问和快速插入/删除操作。
2. `LinkedList`:基于双向链表实现的`List`,支持快速插入/删除操作,但随机访问的性能相对较差。
3. `Vector`:与`ArrayList`类似,但是是线程安全的,支持同步操作。不过在实际开发中,较少使用`Vector`,因为它的性能相对较差。
4. `Stack`:基于`Vector`实现的栈结构,它继承自`Vector`类,支持先进后出(LIFO)的操作。
这些实现类都实现了`List`接口,所以它们具有相似的操作方法。选择使用哪个实现类取决于具体的需求和性能要求。一般来说,如果需要频繁地进行插入和删除操作,可以考虑使用`LinkedList`。如果需要快速随机访问元素,可以使用`ArrayList`。如果需要线程安全的操作,可以使用`Vector`。如果需要栈结构,可以使用`Stack`。
List<Integer> res = new ArrayList<>(); 这里为什么是new ArrayList<>() 而不是new list()
在Java中,List是一个接口,不能直接实例化。因此,我们需要使用一个实现List接口的具体类来创建一个可操作的列表对象。ArrayList是List接口的一个常见实现类,它提供了动态数组的功能,并且可以根据需要自动调整大小。
所以,当我们想要创建一个新的列表对象时,我们使用new ArrayList<>()来实例化一个ArrayList对象,然后将其分配给List类型的变量。这样,我们可以利用List接口的方法来操作这个列表对象,而不需要关心具体的实现细节。
vector list 数组的区别
在vector中,可以用到的命令:
v.empty(); 用于判断是否v为空的。
v.size();用于确定v的长度。
v.push_back(t); 用于在v的最后加元素t
v[n];用于在读取第n个元素,(用于下标操作)
v1 = v2;把v2给v1
v1 = = v2;判断是否v1等于v2;
还可以用各种运算操作符来进行判断。!=;>=;<=;<;>.
Vector与数组的区别_vector和数组的区别-CSDN博客
添加元素时:
vec.puch_back(input)
list.add(input)
结点判断 ==null
if (root == null) { //这里的null是小写 ,结点root判断为空 用 root == null
return;}
JAVA通过值传递,没有指针
是的,C++中传递参数时可以使用指针来传递对象的引用。指针是一个变量,存储了另一个变量的内存地址。通过传递指针,可以直接修改原始对象的值。
而在Java中,没有指针的概念。Java中的对象引用是通过值传递的。当你将一个对象作为参数传递给方法时,在方法内部对该对象的修改会影响到原始对象。但是,你无法直接修改该引用指向的对象的地址。
Java的对象引用在内部实现上类似于指针,但是Java为了避免指针的复杂性和潜在的错误,提供了更简单和安全的方式来操作对象。这样可以减少由于指针操作而引起的错误和内存泄漏等问题。
Queue的定义
Queue<TreeNode> que = new LinkedList<TreeNode>();
que.offer(node); //插入队列
TreeNode tmpNode = que.poll()//排出队列队列和栈 加入新元素时:
queue 是add 或者offer ,两种都可以 ,就是队列满了时 报错有 区别
stack 是push 或者add
队列和栈 删除元素时:
queue 是poll();
stack 是pop();
在Java中,Queue接口没有提供pop()方法。但是,Java提供了另一个接口称为Deque(双端队列),它扩展了Queue接口,并提供了pop()方法。
pop()方法用于从队列的头部移除并返回元素。在Deque接口中,pop()方法相当于removeFirst()方法。
例如,使用LinkedList实现Deque接口:
Deque<Integer> deque = new LinkedList<>();
deque.add(1);
deque.add(2);
int element = deque.pop(); // 移除并返回队列的头部元素
需要注意的是,pop()方法在队列为空时会抛出NoSuchElementException异常。因此,在调用pop()方法之前,最好先使用isEmpty()方法检查队列是否为空。
总结:Queue接口本身没有提供pop()方法,但是可以使用Deque接口来实现类似的功能,其中pop()方法相当于removeFirst()方法。
true和false
boolean返回值true,false,是小写字母!
return true; ✓
return True; ×
new StringBuilder(s)
new StringBuilder(s). append(root.val).toString();
使用 new StringBuilder(s) 将字符串 s 转换为 StringBuilder 对象,然后使用 append() 方法将其他字符或字符串添加到该对象中。最后,可以使用 toString() 方法将 StringBuilder 对象转换回字符串形式。
static
在Java中,static关键字可以用于不同的上下文中,具体取决于你希望实现的功能。
-
静态成员变量:当你希望在整个类中共享一个变量时,可以将其声明为静态。静态变量只有一个副本,无论创建了多少个类的实例,它们都会共享相同的值。
-
静态方法:与静态变量类似,静态方法也属于类本身,而不是类的实例。它可以通过类名直接调用,而不需要创建类的实例。静态方法通常用于实现一些与类相关的功能,例如工具方法或计算属性。
-
静态代码块:静态代码块是在类加载时执行的代码块。它可以用于初始化静态变量或执行其他需要在类加载时完成的任务。
需要注意的是,静态成员属于类本身,而不是类的实例。因此,它们可以在没有实例的情况下被访问和使用。但是,静态成员无法直接访问非静态成员,因为非静态成员是与类的实例相关联的。
不需要new创建实例对象,就可以访问静态成员方法
成员方法没有加 static的话,需要先new一个对象,才能够访问成员方法
定义最值
Long型最小值定义如下:(比int型要小)
private long prev = Long.MIN_VALUE;最大值为:
private long prev = Long.MAX_VALUE;int型最大值:
int result = Integer.MAX_VALUE;返回最值
Math.min( ,) 返回最小值, 注意首字母大写,其他小写。
result = Math.min(result,root.val - pre.val);定义空节点
TreeNode pre =null;哈希表统计元素频率
构建哈希表
Map<Integer, Integer> map = new HashMap<>();统计元素频率:map.put ( x , map.getOrDefault ( x , 0 ) + 1 )
void searchBST(TreeNode curr, Map<Integer, Integer> map) {
if (curr == null) return;
map.put(curr.val, map.getOrDefault(curr.val, 0) + 1);
searchBST(curr.left, map);
searchBST(curr.right, map);
}List<Integer>转换成int []
首先要注意
Integer[] 和 int[] 有一些区别。
-
类型:Integer[] 是一个对象数组,而 int[] 是一个基本类型的数组。Integer 是Java中的包装类,用于将基本类型 int 包装成对象。因此,Integer[] 中的每个元素都是一个 Integer 对象,而 int[] 中的每个元素都是一个基本类型的 int。
-
空值:Integer[] 可以包含空值(null),而 int[] 不可以。在 Integer[] 中,可以将某些元素设置为 null,表示该位置没有值。但是在 int[] 中,每个元素都必须是一个有效的 int 值。
-
自动装箱与拆箱:由于 Integer 是一个对象,它可以自动装箱(将 int 值转换为 Integer 对象)和拆箱(将 Integer 对象转换为 int 值)。这意味着在使用 Integer[] 时,可以直接使用整数值,而无需手动进行装箱和拆箱操作。而在 int[] 中,只能使用基本类型的 int 值。
在使用数组时,您可以根据具体的需求选择使用 Integer[] 或 int[]。如果需要处理空值或者需要使用 Integer 对象的特性(如自动装箱和拆箱),则可以选择使用 Integer[]。如果只需要处理基本类型的 int 值且不需要空值或者对象特性,那么使用 int[] 会更高效。
stream()` 方法和 `mapToInt()` 方法
要将一个 `List<Integer>` 转换为 `int[]`,您可以使用 `stream()` 方法和 `mapToInt()` 方法来实现。下面是一个示例代码:
List<Integer> result = new ArrayList<>();
result.add(1);
result.add(2);
result.add(3);
int[] array = result.stream().mapToInt(Integer::intValue).toArray();在这个示例中,我们首先创建了一个 `List<Integer>` 对象 `result`,并向其中添加了一些整数值。然后,我们使用 `stream()` 方法将列表转换为流,然后使用 `mapToInt()` 方法将流中的每个元素转换为对应的 `int` 值。最后,我们使用 `toArray()` 方法将转换后的 `IntStream` 转换为 `int[]` 数组。现在,`array` 数组将包含与 `result` 列表中的元素相同的整数值。
直接使用 `toArray()` 方法将 `List<Integer>` 转换为 `Integer[ ],而不是转换成int[ ]!
实际上,您也可以直接使用 `toArray()` 方法将 `List<Integer>` 转换为 `Integer[]`,而不必使用流的方式。下面是一个使用 `toArray()` 方法的示例代码:
List<Integer> result = new ArrayList<>();
result.add(1);
result.add(2);
result.add(3);
Integer[] array = result.toArray(new Integer[result.size()]);在这个示例中,我们创建了一个 `List<Integer>` 对象 `result`,并向其中添加了一些整数值。然后,我们使用 `toArray()` 方法将 `result` 列表转换为 `Integer` 类型的数组。需要注意的是,我们需要通过传递一个具有正确大小的 `Integer[]` 数组作为参数来告知 `toArray()` 方法返回的数组类型。
所以,您可以根据实际需要选择使用 `stream()` 和 `mapToInt()` 方法转换为 `int[]` 数组,或者直接使用 `toArray()` 方法转换为 `Integer[]` 数组。
直接使用 toArray() 方法可以转换为int[]吗而不是Integer[]吗?
不,直接使用toArray()方法将List<Integer>转换为int[]是不可能的。因为Java中的数组只能存储基本类型的值,而Integer是一个对象类型。所以,如果要将List<Integer>转换为int[],需要使用循环遍历的方法,将每个Integer对象转换为int类型,然后存储到int数组中。代码示例如下:
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
int[] arr = new int[list.size()];
for(int i = 0; i < list.size(); i++) {
arr[i] = list.get(i);
}
// 现在,arr就是一个包含list中所有元素的int数组
求和避免越界写法
int mid = (left + right) / 2
这么写其实有一个问题,就是数值越界,例如left和right都是最大int,这么操作就越界了,在二分法 (opens new window)中尤其需要注意!
所以可以这么写:
int mid = left + ((right - left) / 2)
length、length()、size() 的区别
s.length
s.length()
什么时候必须加括号?
Length 数组的大小
length() 字符串的大小 StringBuilder 也使用length()
size() 集合类(map、set、list)的大小
length、length()、size() 的区别_size和length有什么区别_maoyudashen的博客-CSDN博客
StringBuilder 用法
将String s转换成StringBuilder 类型
StringBuilder sb = new StringBuilder(s);删除
s.deleteCharAt(i + 1);插入
s.insert(i + 1, '.');getLast()和get(path.size()-1)
如果定义是LinkedList<Integer>
LinkedList<Integer> path = new LinkedList<>();
可以使用
path.removeLast();
path.getLast()
如果定义是 List<Integer>
List<Integer>path=new LinkedList<>();
不能使用path.removeLast()和path.getLast()
需要使用path.get(path.size()-1)和path.remove(path.size()-1)
回溯
电话号码的字母组合
注意看下面的题解
这里题解下面,为什么频繁的组装String 不用StringBulider呢?两者的区别!
因为StringBuilder传入的都是同一个对象,所以在递归完成之后必须撤回上一次的操作,需要删除上一次添加的字符。而String每次改变之后传入的都是不同的对象。故无需撤销操作。


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









