






一、强化学习的旅程
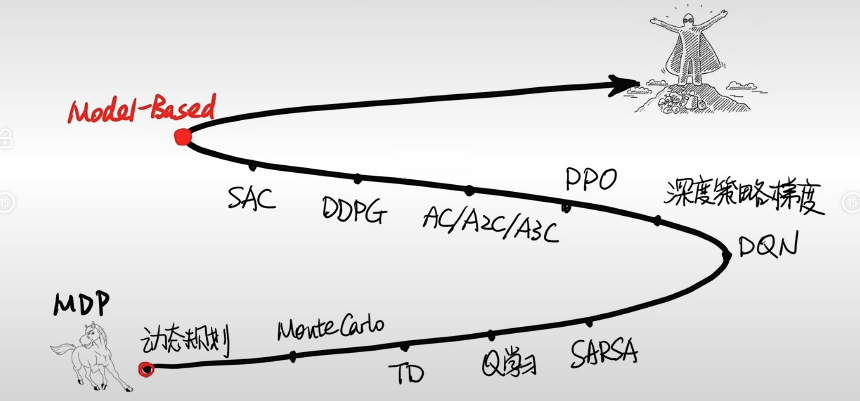
起点
- MDP(马尔可夫决策过程):是强化学习的基础框架,描述了智能体在环境中如何通过采取行动,根据环境反馈的奖励来进行决策。图中左下角以马的简笔画表示起点,寓意从这里开启强化学习探索。
演进路径上的算法
- 动态规划:基于 MDP,用于求解最优策略,通过将复杂问题分解为子问题并利用子问题的解来求解原问题。
- Monte Carlo(蒙特卡罗方法):通过大量随机采样来估计值函数等。比如在估计状态价值时,通过多次完整的试验(从起始状态到终止状态),计算平均回报来近似状态价值。
- TD(时间差分学习):结合了动态规划和蒙特卡罗方法的思想,不需要等到试验结束就可以更新值函数估计,通过当前估计和后续状态估计的差值来更新。
- Q - 学习:属于无模型的强化学习算法,用于学习状态 - 动作值函数(Q 函数),目标是找到最优的 Q 函数,从而确定最优策略。
- SARSA:也是无模型的在线策略学习算法 ,与 Q - 学习类似,但它的更新是基于当前策略下实际执行的动作和后续状态,更注重 “在线” 学习过程。
- DQN(深度 Q 网络):将深度学习与 Q - 学习相结合,使用神经网络来近似 Q 函数,解决了传统 Q - 学习在处理高维状态空间时的局限性,能处理像图像这类复杂的输入。
- 深度策略梯度:通过策略梯度方法直接优化策略网络,根据累计奖励来调整策略网络的参数,使得智能体采取的动作能获得更高奖励。
- PPO(近端策略优化算法):属于基于策略梯度的算法,对策略进行更新时,限制新策略与旧策略的差异不要过大,提升训练稳定性和样本效率。
- AC/A2C/A3C(演员 - 评论家算法及其变体):结合了基于值函数和基于策略的方法。“演员” 负责生成动作,“评论家” 负责评估动作的好坏,通过两者交互学习来优化策略。
- DDPG(深度确定性策略梯度):用于解决连续动作空间的强化学习问题,基于确定性策略梯度算法,结合深度学习来近似策略网络和值网络。
- SAC(软演员 - 评论家算法):也是处理连续动作空间问题,引入了熵正则化项,在追求奖励最大化的同时,鼓励策略的探索性,使训练更稳定,收敛性更好。
终点附近
- Model - Based(基于模型的强化学习):不同于之前一些无模型的强化学习算法,基于模型的强化学习会对环境进行建模,利用模型来预测环境动态,从而指导策略学习。
算法总览
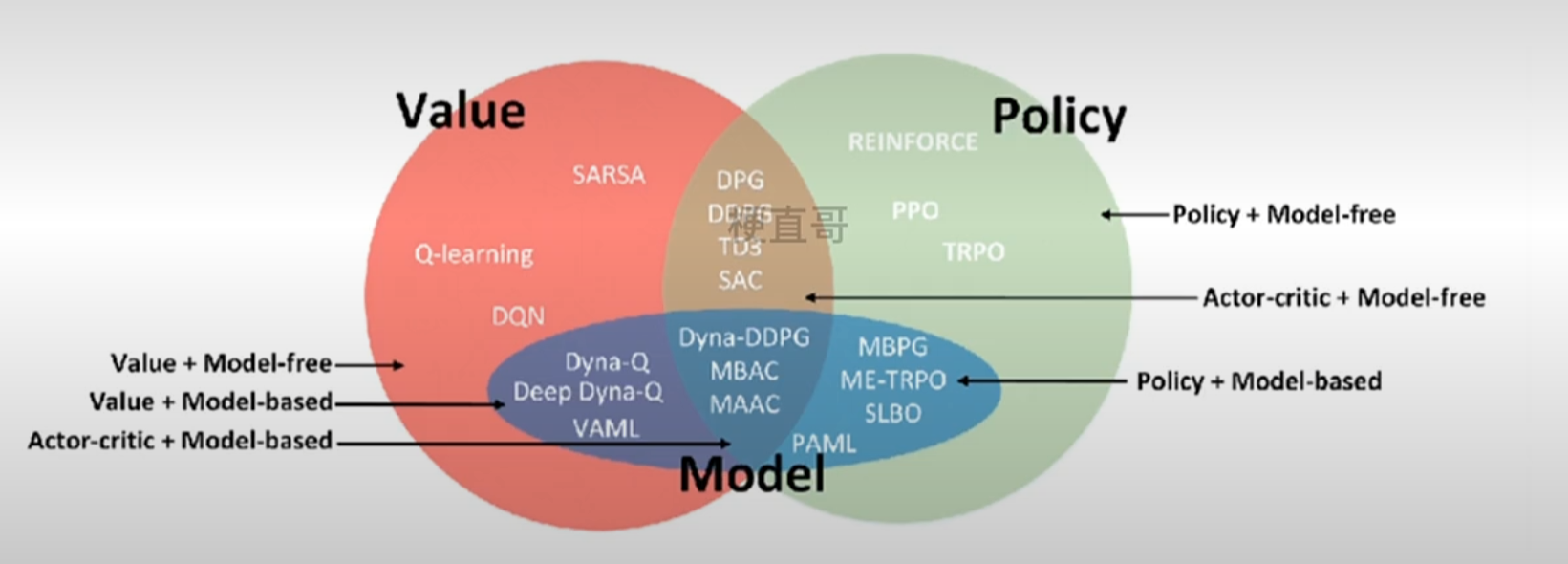
二、方法分类与选择
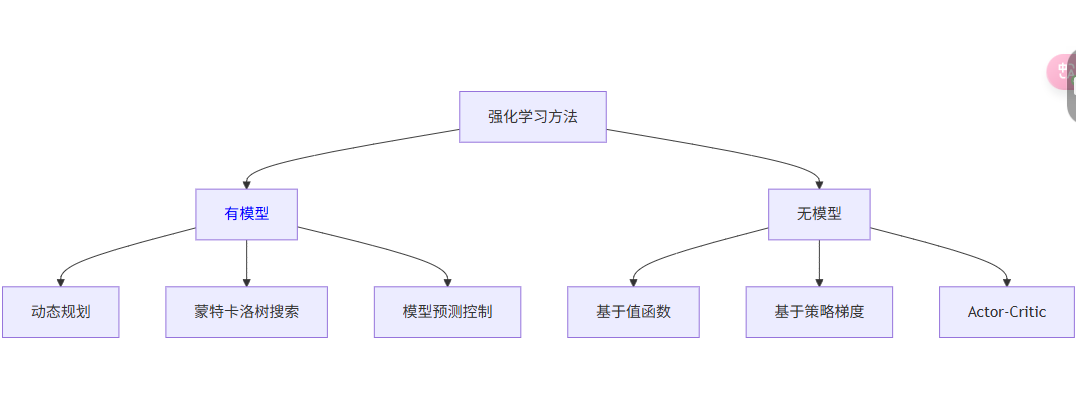
-
决策逻辑的起点:
选择强化学习算法的第一步是确认环境是否可建模。若环境已知且可模拟(如棋盘游戏、简单物理仿真),优先使用有模型方法;若环境复杂或未知(如真实机器人、开放世界游戏),则必须使用无模型方法。 -
方法论的根本差异:
- 有模型方法依赖对环境的“理解”(模型),强调规划(如动态规划中的贝尔曼方程)。
- 无模型方法依赖对环境的“体验”(数据),强调学习(如Q-Learning中的时序差分更新)。
-
实际应用的分水岭:
- 有模型方法多用于仿真可控场景(工业控制、游戏AI)。
- 无模型方法多用于真实复杂场景(自动驾驶、机械臂控制)。
三、优缺点分析
1. 有模型算法
优点
-
规划和决策优化能力强
-
原因:基于模型的方法可以利用环境模型(如状态转移概率、奖励函数)进行多步前瞻性规划(如动态规划、蒙特卡洛树搜索)。
-
例子:
-
机器人路径规划:通过构建地图模型,预先计算最优路径(如A*算法),避免实时探索的盲目性。
-
棋类游戏(如围棋、国际象棋):AlphaGo的蒙特卡洛树搜索(MCTS)通过模拟未来棋局选择最优策略。
-
-
-
数据效率高
-
原因:模型可以生成虚拟数据(仿真),减少对真实环境交互的依赖。
-
例子:
-
自动驾驶仿真:在CARLA等模拟器中训练策略,无需真实车辆上路,节省时间和成本。
-
机器人控制:利用物理引擎(如MuJoCo)生成训练数据,快速收敛。
-
-
-
策略评估与调试便捷
-
原因:通过模型模拟策略效果,无需真实执行。
-
例子:
-
游戏AI:快速测试不同策略在模拟环境中的胜率,优化算法参数。
-
工业控制:在数字孪生系统中验证控制策略的安全性。
-
-
缺点
-
模型误差问题
-
原因:模型难以完全精确拟合复杂环境(如非线性动力学、随机干扰)。
-
例子:
-
自动驾驶:忽略罕见天气(如冰雹)的模型可能导致实际行驶中决策失误。
-
机器人抓取:摩擦系数建模不准会使抓取动作失败。
-
-
-
模型学习复杂度高
-
原因:高维状态空间或动态交互场景下,模型训练难度大。
-
例子:
-
交通流建模:需模拟车辆、行人、信号灯的实时交互,计算成本极高。
-
医疗决策:患者生理参数模型需大量数据且难以泛化。
-
-
-
泛化能力受限
-
原因:模型依赖训练数据的分布,环境变化时可能失效。
-
例子:
-
室内 vs. 室外机器人导航:室内训练的SLAM模型在室外可能因光照、地形差异失败。
-
金融预测:基于历史数据的模型在突发经济危机中表现不佳。
-
-
2、无模型算法:
无模型算法优点
-
避免模型误差
-
原因:无模型算法直接通过与环境交互学习策略,无需预先构建环境动态模型(如状态转移概率、奖励函数)。
-
例子:在自动驾驶中,交通环境复杂多变,精确建模所有车辆和行人的行为几乎不可能。无模型算法(如PPO)通过实时交互数据学习策略,避免了因模型简化导致的决策偏差。
-
-
灵活性高
-
原因:不依赖固定环境模型,能适应动态变化的环境。
-
例子:在实时游戏(如《Dota 2》或《星际争霸》)中,对手策略和地图状态时刻变化。无模型算法(如A3C)可通过在线学习快速调整策略,而基于模型的方法可能因环境变化失效。
-
-
易于实现
-
原因:无需设计环境模型,仅需定义状态、动作和奖励函数。
-
例子:在机器人避障任务中,基于模型的方法需精确建模障碍物运动和传感器噪声,而无模型方法(如DQN)直接通过碰撞反馈优化策略,开发更简单。
-
无模型算法缺点
-
数据效率低
-
原因:依赖大量试错数据,采样效率远低于基于模型的方法。
-
例子:训练机械臂抓取物体时,无模型算法(如DDPG)可能需要数百万次尝试才能收敛,而基于模型的方法(如PILCO)可利用动力学模型加速学习。
-
-
学习速度慢
-
原因:通过试错逐步优化策略,收敛速度受探索效率限制。
-
例子:在高频交易中,市场状态瞬息万变,无模型算法(如SAC)可能无法快速适应新趋势,导致收益滞后。
-
-
缺乏前瞻性规划
-
原因:无模型算法通常基于当前状态或短期回报决策,难以进行多步推理。
-
例子:在围棋中,基于模型的蒙特卡洛树搜索(MCTS)可以模拟未来多步走法,而无模型方法(如AlphaGo的策略网络)更依赖即时评估,可能忽略长远优势。
-


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









