







 该项目旨在利用Python爬虫技术获取王者荣耀英雄的皮肤海报、导出英雄技能到txt文件,并将皮肤信息整理成Excel,最后利用技能txt生成词云库。详细步骤包括分析数据源、编写代码实现爬取和解析,并展示了运行结果。
该项目旨在利用Python爬虫技术获取王者荣耀英雄的皮肤海报、导出英雄技能到txt文件,并将皮肤信息整理成Excel,最后利用技能txt生成词云库。详细步骤包括分析数据源、编写代码实现爬取和解析,并展示了运行结果。
目录
项目背景:
王者荣耀是大家喜爱的休闲娱乐手游,拥有非常多的英雄,每个英雄又会有自己的皮肤,而官网中每个皮肤都有对应的高清海报,每个英雄拥有自己的独特技能。单独下载每一个英雄的皮肤和查看英雄技能非常耗时,利用爬虫我们就可以快速获得所有英雄的高清海报和技能介绍
一、爬取英雄皮肤海报
1、准备:
1、打开王者荣耀英雄资料网址
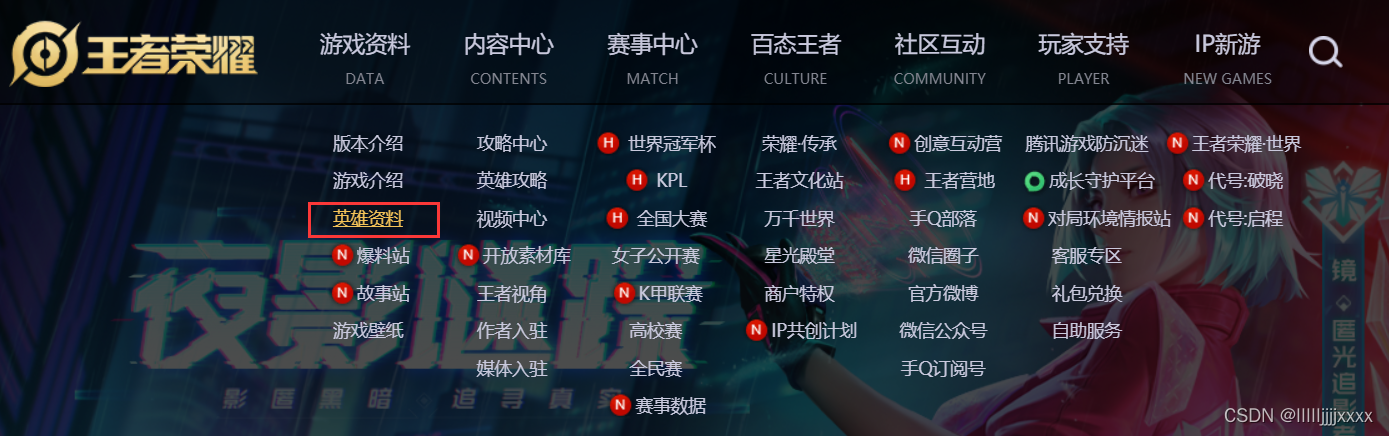
2、进入开发者工具,可以发现network中浏览器请求了一个herolist.json文件点开response中发现部分信息存在乱码,但是可以从看到ename的值,以及存在cname和skin_name,这时可以推测,这里存储的一定是关于英雄的某些信息

3、点击进入英雄的详情界面,通过对比url可以发现不同的英雄不管皮肤图片如何改变,浏览器上方的地址始终是不变的,变得只有数字,刚好廉颇的数字和刚才json文件中的ename对应,由此我们可以推测ename是每个英雄的id编号,cname是英雄名字
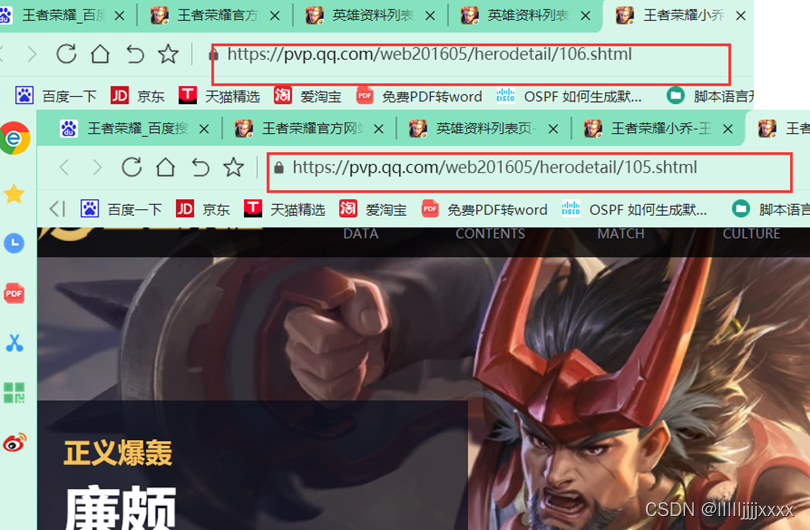
我们切换一下英雄的皮肤,会发现图片地址没有明显的变化,只是最后的数字序号改变了,我们将两个皮肤图片的地址放在一起比较一下:
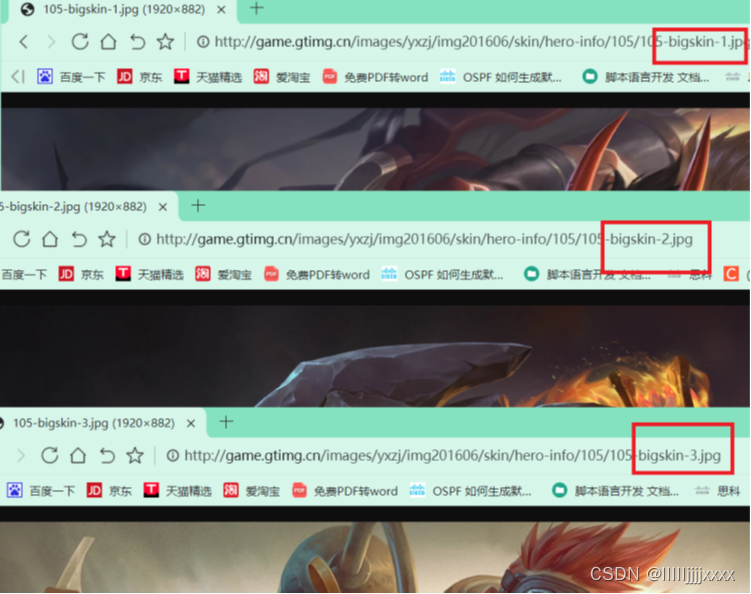
由此我们已知获得每个英雄的id就能获取每个英雄详情页,每个英雄的皮肤海报地址改变的只有数字序号
"https://pvp.qq.com/web201605/herodetail/%s.shtml"%heroId#英雄详情页
"http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/%s/%s-bigskin-%s.jpg"%(heroId,heroId,index+1)#英雄海报地址进入详情页源代码地址发现在ul标签中存放中英雄皮肤的名字

到这里,准备工作就完成了,其实进行到这里,整个工程就完成了一半了,接下来就是代码的实现了
2、代码实现
import requests
import json
from bs4 import BeautifulSoup
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5958.400 SLBrowser/10.0.3533.400'}
def getSoup(url):
resp = requests.get(url, headers=headers)
resp.encoding = 'gbk'
soup = BeautifulSoup(resp.text, 'lxml')
return soup
#获取json数据,尝试得知存在有英雄的SkinName信息缺失或不全的情况
#所以这里只取用json文件中英雄id和名字
#获取json数据,并解析成存有英雄id与名字的列表[[id,name],[id1,name1].......]
def jsonToHeroInfoList(jsonURL):
resp =requests.get(jsonURL)
jsonData = json.loads(resp.text)
heroInfoList = []
for data in jsonData:
hero_info =[]
hero_info.append(data['ename'])
hero_info.append(data['cname'])
heroInfoList.append(hero_info)
return heroInfoList
###通过存有英雄id与名字的列表[[id,name],[id1,name1].......],获取皮肤名字和图片的src
def getImgSrc(heroInfoList):
skinSrcList=[]
for heroInfo in heroInfoList:
heroName = heroInfo[1]
heroId = heroInfo[0]
#通过英雄id,进入英雄详情页获取皮肤名字和src
detailUrl = "https://pvp.qq.com/web201605/herodetail/%s.shtml"%heroId
soup = getSoup(detailUrl)
ul = soup.find('ul', class_="pic-pf-list pic-pf-list3")
skinNames = ul['data-imgname'].split('|')#split()通过指定分隔符对字符串进行切片
for index in range(len(skinNames)):
skinName =heroName+"-"+skinNames[index].split('&')[0]
imgSrc 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









