







LLM Blender:集成多个LLMs的不同优势获得更好的性能。集成学习。总体思想就是PAIRRANKER比较来自N个llm的输出,然后GENFUSER从排名前K的输出生成最终输出
LLM Blender由PAIRRANKER和GENFUSER组成。
PAIRRANKER:成对比较方法来区分候选输出之间的细微差异,用交叉注意编码器确定优选文本
GENFUSER:合并排名最高的候选答案,通过利用他们的优势和减轻弱点来产生更好的答案
具体来说每个LLM在不同的问题下都会产生不同的回答,例如,你问感冒了怎么办,每个LLM都会回答一个答案,然后可以得出一个最好的答案并记录,比如百度的文心一言,虽然总体能力没有GPT-4强,但在中国传统文化,写诗,韵脚,一些通假字等中文能力更强,在综合多个LLM的回答后选出最优的,不管哪方面的问题,都能有很好的鲁棒性。
原文链接:aclanthology.org/2023.acl-long.792.pdf
下面是翻译和个人理解
摘要
我们介绍了LLM-BLENDER,这是一个集成框架,旨在通过利用多个开源大型语言模型(llm)的不同优势来获得持续的卓越性能。我们的框架由两个模块组成:配对器和基因器,解决了不同例子的最佳llm可能显著不同的观察。成对器采用一种专门的成对比较方法来区分候选输出之间的细微差异。它联合编码输入文本和一对候选文本,使用交叉注意编码器来确定优选文本。我们的结果表明,配对排序者与基于chatgpt的排名的相关性最高。然后,GENFUSER旨在合并排名最高的候选人,通过利用他们的优势和减轻他们的弱点来产生更好的产量。为了方便大规模的评估,我们引入了一个基准数据集,Mix指示,它是一个具有oracle成对比较的多个指令数据集的混合。我们的llm混合器在各种指标上显著优于单个llm和基线方法,建立了一个巨大的性能差距。
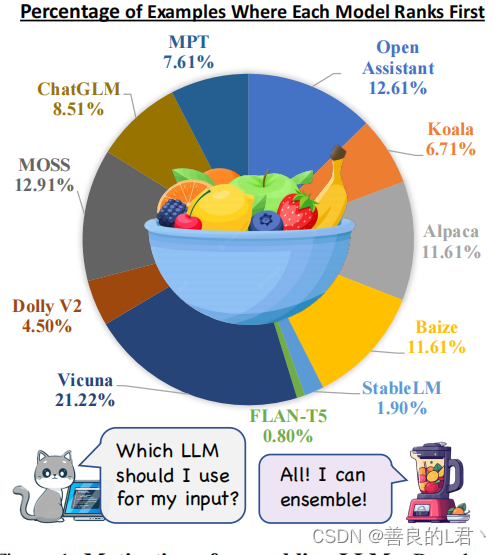
1 引言
大型语言模型(llm)在不同的任务中表现出令人印象深刻的表现,主要是因为它们能够遵循指令和访问广泛、高质量的数据,显示了人工通用智能的良好前景(Bubeck et al.,2023)。然而,著名的llm,如GPT-4和PaLM(Chowdhery et al.,2022)都是闭源的,限制了对其架构和训练数据的了解.开源LLMs皮西亚(比德曼等,2023),LLaMA(Touvron等,2023),和Flan-T5(钟等,2022)提供一个机会微调这些模型自定义指令数据集,使较小的发展但有效的人,如羊驼、维田(蒋等,2023)、开放助理(莱奥奈,2023)和MPT(马赛克,2023)。由于数据、架构和超参数的变化,开源llm表现出不同的优点和缺点,使它们相互互补。图1说明了我们收集的5,000条指令上的最佳llm的分布。更多的排名细节可以在Sec 5.1中找到。虽然Vicuna获得的比例最高,但它仅在21.22%的例子中排名第一。此外,饼状图表明,不同示例的最佳LLM可能存在显著差异,而且没有开源LLM主导着竞争对手。因此,动态地集成这些llm以为每个输入生成更好的响应是很重要的。考虑到llm的不同优缺点,开发一种利用其互补潜力的集成方法是至关重要的,从而提高鲁棒性、泛化和准确性。通过结合它们独特的贡献,我们可以减轻单个llm中的偏见、错误和不确定性,从而使输出更好地与人类的偏好相一致。
我们引入了llm-Blender,这是一种集成框架,旨在通过混合多个llm的输出来实现持续的优越性能。llm-Blender由两个模块组成:PAIRRANKER和GENFUSER。首先,配对器比较来自N个llm的输出,然后基因融合,从排名前K的输出生成最终输出。
现有的方法(Ravaut等,2022a;刘和刘,2021),包括奖励模型(欧阳等,2022),排名输出语言模型(y1,...,)在给定的输入x主要集中在单独评分每个山基于x,采用编码模块的形式。虽然当候选差异明显时,这种列表排序目标可以强大和有效,但当集成llm时,它可能不那么有效。在llm的输出候选模型中,候选差异可能非常微妙,因为它们都是由非常复杂的模型产生的,其中一个可能只比另一个稍微好一点。即使对人类来说,如果不进行直接比较,衡量候选质量也是一项挑战。
因此,我们提出了一种专门的成对比较方法,成对排序器(秒。3),有效地识别候选输出之间的细微差异,并提高排名性能。特别地,我们首先为每个输入收集N个模型(例如,图1中的N个= 11模型)的输出,然后创建N个(N个−1)/2对输出。我们联合编码输入x和两个候选输出yi和yj作为输入到一个交叉注意编码器(例如,RoBERTa(Liu等人,2019)),以fφ(x,yi,yj)的形式,以学习和确定哪个候选输出更好。在推理阶段,我们计算一个包含表示成对比较结果的对数的矩阵。给定这个矩阵,我们可以推断出给定输入x的N个输出的排序。随后,我们可以在每个输入中使用排名最高的候选项作为最终结果。因此,这种方法并不依赖于所有示例的单一模型;相反,对排序方通过全面比较所有候选对来为每个示例选择最佳模型。
尽管如此,这种方法可能会限制比现有的候选产品产生更好的产出的潜力。为了研究这种可能性,我们引入了基因使用者(秒。4)模块,融合N级候选项的前K,并为最终用户生成改进的输出。我们的目标是利用前K名候选人的优势,同时减轻他们的弱点。
为了评估LLM集成方法的有效性,我们引入了一个名为Mix指示t的基准数据集。2.2).在这个数据集中,我们使用N=11个流行的开源llm为各种格式为自结构的现有指令跟踪任务的每个输入生成N个候选对象(Wang et al.,2022)。该数据集包括100k个训练示例和5k个验证示例,用于训练一个候选排名模块,比如我们的配对排序器,以及5k个用于自动评估的oracle比较的测试示例。在第5节中,我们在MixDulect基准上的经验结果显示,llm搅拌机框架通过集成llm显著提高了整体性能。成对排序者所做的选择优于任何固定的单个LLM模型,这表明在基于参考的指标和GPT-Rank上都具有优越的性能。通过利用成对器的顶级选择,基因用户通过有效融合到最终输出进一步提高响应质量。llm搅拌器在传统指标(即BERTScore,BARTScore,BLUERT)和基于chatgpt的排名方面都获得了最高的分数。在12种方法中,LLM-搅拌机的平均排名为3.2,明显优于最佳LLM的3.90的排名。此外,llm搅拌机的产量以68.59%的例子排名前3,而Vicc
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









