









本次JS解密以有道翻译为例,相信各位看过之后绝对会有所收获!
1、网页查看


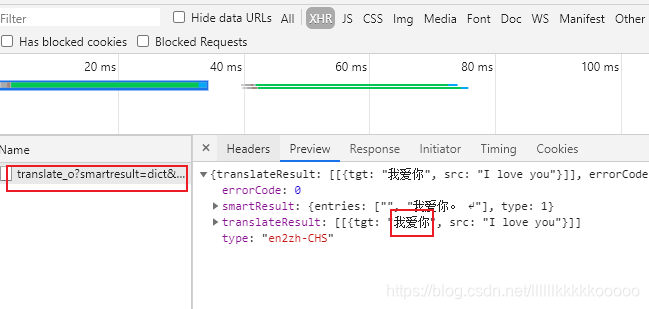


2、有道翻译简单实现源码
import requests
#请求头
#headers不能只有一个User-Agent,因为有道翻译是有一定的反扒机制的,所以我们直接全部带上
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Content-Length": "244",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Cookie": "OUTFOX_SEARCH_USER_ID=-1506602845@10.169.0.82; JSESSIONID=aaaUggpd8kfhja1AIJYpx; OUTFOX_SEARCH_USER_ID_NCOO=108436537.92676207; ___rl__test__cookies=1597502296408",
"Host": "fanyi.youdao.com",
"Origin": "http://fanyi.youdao.com",
"Referer": "http://fanyi.youdao.com/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36",
"X-Requested-With": "XMLHttpRequest",
}
#提交参数
params = {
"i": "I love you",
"from": "UTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": "15975022964104",
"sign": "7b7db70e0d1a786a43a6905c0daec508",
"lts": "1597502296410",
"bv": "9ef72dd6d1b2c04a72be6b706029503a",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME",
}
url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
#发起POST请求
response = requests.post(url=url,headers=headers,data=params).json()
print(response)

到这里表面上已经完成了有道翻译的代码,但其实还有问题,比如下方如果更换了需要翻译的内容就会报错


原因
我们在有道翻译重新翻译,会发起新的POST请求,而每次请求所带的参数值会有所不同,如果想要真正实现有道翻译功能,就要找到这四个参数值得生成方式,然后用python实现同样的功能才行

3、JS解密(详解)
Ctrl+Shift+f 进行搜索,输入sign


因为加密肯定是发起请求的时候加密所以我们搜索translate_o


调试
在有道翻译重新输入翻译内容,即可到断点处停下

但是发现数据已经是加密好了的

但由于我们是调试模式,可以返回到上一步,点击如下按钮

可以发现salt、sign、lts、bv都是通过 r 获取出来的,而 r 又是通过一个函数得到的

进入该函数
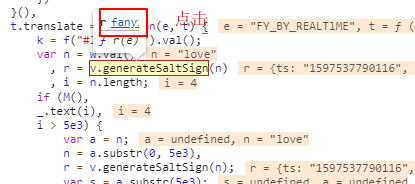
可以发现这里就是加密的地方

复制这段js代码,我们需要使用使用python代码来实现


可以看到是一模一样的,到这里算是有一点点小成功了😁

注意这里翻译的内容不同其bv也是不同的哦
接下来看lts,用python实现


可见python生成的时间戳和JS的有所不同,但细心的小伙伴肯定知道怎么把python的时间戳变成跟JS一样

这样就ok了
乘以1000转化为int舍弃小数位再转化为字符串,因为JS里是字符串

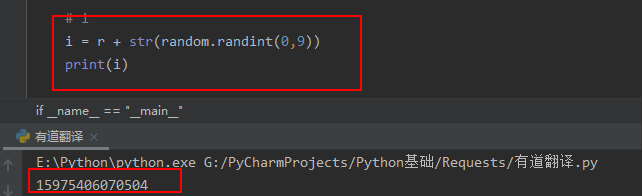
接下来看i,然后用python实现

最后

温馨提示:
可能会正在有道翻译更新时进行改变,但这不是什么问题,如果仔细看了JS解密的话,还是能够找到新的

4、python实现JS解密后的完整代码
import requests
from hashlib import md5
import time
import random
#请求地址
url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
appVersion = "5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36"
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Content-Length": "244",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Cookie": "OUTFOX_SEARCH_USER_ID=-1506602845@10.169.0.82; JSESSIONID=aaaUggpd8kfhja1AIJYpx; OUTFOX_SEARCH_USER_ID_NCOO=108436537.92676207; ___rl__test__cookies=1597502296408",
"Host": "fanyi.youdao.com",
"Origin": "http://fanyi.youdao.com",
"Referer": "http://fanyi.youdao.com/",
"user-agent": appVersion,
"X-Requested-With": "XMLHttpRequest",
}
def r(e):
# bv
t = md5(appVersion.encode()).hexdigest()
# lts
r = str(int(time.time() * 1000))
# i
i = r + str(random.randint(0,9))
return {
"ts": r,
"bv": t,
"salt": i,
"sign": md5(("fanyideskweb" + e + i + "]BjuETDhU)zqSxf-=B#7m").encode()).hexdigest()
}
def fanyi(word):
data = r(word)
params = {
"i": word,
"from": "UTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": data["salt"],
"sign": data["sign"],
"lts": data["ts"],
"bv": data["bv"],
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME",
}
response = requests.post(url=url,headers=headers,data=params)
#返回json数据
return response.json()
if __name__ == "__main__":
while True:
word = input("请输入要翻译的语句:")
result = fanyi(word)
#对返回的json数据进行提取,提取出我们需要的数据
r_data = result["translateResult"][0]
print(r_data[0]["src"])
print(r_data[0]["tgt"])
这代码我就不做过多解释了,相信大家都能看懂。
4.1、实现效果

5、JS解密后完整代码升级版
如果只是对一些词语、语句翻译那还不如直接在网址上进行翻译,本次升级版可以对文章句子进行分段翻译,更有助于提高英语阅读理解的能力。(特别适合我这样的英语学渣)😂
import requests
from hashlib import md5
import time
import random
#请求地址
url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
appVersion = "5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36"
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Content-Length": "244",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Cookie": "OUTFOX_SEARCH_USER_ID=-1506602845@10.169.0.82; JSESSIONID=aaaUggpd8kfhja1AIJYpx; OUTFOX_SEARCH_USER_ID_NCOO=108436537.92676207; ___rl__test__cookies=1597502296408",
"Host": "fanyi.youdao.com",
"Origin": "http://fanyi.youdao.com",
"Referer": "http://fanyi.youdao.com/",
"user-agent": appVersion,
"X-Requested-With": "XMLHttpRequest",
}
def r(e):
# bv
t = md5(appVersion.encode()).hexdigest()
# lts
r = str(int(time.time() * 1000))
# i
i = r + str(random.randint(0,9))
return {
"ts": r,
"bv": t,
"salt": i,
"sign": md5(("fanyideskweb" + e + i + "]BjuETDhU)zqSxf-=B#7m").encode()).hexdigest()
}
def fanyi(word):
data = r(word)
params = {
"i": word,
"from": "UTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": data["salt"],
"sign": data["sign"],
"lts": data["ts"],
"bv": data["bv"],
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME",
}
response = requests.post(url=url,headers=headers,data=params)
return response.json()
if __name__ == "__main__":
#打开需要翻译的文章
with open("文章.txt",mode="r",encoding="utf-8") as f:
#获取文章全部内容
text = f.read()
result = fanyi(text)
r_data = result["translateResult"]
#翻译结果保存
with open("test.txt",mode="w",encoding="utf-8") as f:
for data in r_data:
f.write(data[0]["tgt"])
f.write('\n')
f.write(data[0]["src"])
f.write('\n')
print(data[0]["tgt"])
print(data[0]["src"])
5.1、实现效果

CSDN独家福利降临!!!
最近CSDN有个独家出品的活动,也就是下面的《Python的全栈知识图谱》,路线规划的非常详细,尺寸 是870mm x 560mm 小伙伴们可以按照上面的流程进行系统的学习,不要像我当初一样没人带自己随便找本书乱学,系统的有规律的学习,它的基础才是最扎实的,在我们这行,《基础不牢,地动山摇》尤其明显。
最后,如果有兴趣的小伙伴们可以酌情购买,为未来铺好道路!!!

最后
我是 Code皮皮虾,一个热爱分享知识的 皮皮虾爱好者,未来的日子里会不断更新出对大家有益的博文,期待大家的关注!!!
创作不易,如果这篇博文对各位有帮助,希望各位小伙伴可以一键三连哦!,感谢支持,我们下次再见~~~
分享大纲
更多精彩内容分享,请点击 Hello World (●’◡’●)

















 2708
2708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









