






本篇文章是我的学习笔记,内容写的很随意。如果你想学习Python,不要看。
一.变量
1.变量类型
| 整数 | int类型的数据范围没有上限,只要内存足够,可以存储特别大的数 |
| 浮点数 | 只有一种类型float,没有double,但是这个跟其他语言的double没什么区别 |
| 字符串 | 使用 ' ' 或者 " " 括起来的 |
| 布尔 | True和False |
2.动态类型
python的数据类型可以在运行时发生变化,也就是我们定义一个a,开始时a是int类型,后面可以变成float:
a=134
print(a)
a=123.123
print(a)二.输入输出
1.输入
使用input函数输入:
b=input()
c=input("输入一个整数:")input 的参数相当于一个 "提示信息",不写也可以。
注意:input 的返回值是字符串类型,如果后续要操作,要强转类型。
2.输出
使用print函数输出
输出变量:
print(a)输出a=123:
a=123
print(f'a = {a}')使用 f 作为前缀的字符串,称为 f-string;{ } 来内嵌一个其他的变量/表达式。
三.运算符
1.算数运算符
1)整数/整数不会截断,比如1/2不是等于0,而是等于0.5;
2)**可以用来算乘方,2 ** 2,2**0.5,都可以;
3)//是取整除法,得到的是整数,会向下取整,比如:7 // 2=3,-7 // 2=-4;
2.关系运算符
整数和浮点数不用说,这里说一下字符串。
==和!=可以判断两个字符串的是否相等,是否不相等。
>,<等可以根据字符串字典序比较大小。
但是要注意==不可以判断浮点数是否相等。
3.逻辑运算符
| and | 与 |
| or | 或 |
| not | 取反 |
4.赋值运算符
连续赋值:
a=b=10多元赋值:
a,b=10,12两个变量交换
a,b=b,a注意python中没有++,--这种运算符。
四.条件语句
1.语法格式
1)if
if expression:
print(123)2)if-else
if expression:
print(123)
else:
print(456)3)if-elif-else
if expression:
print(123)
elif expression2:
print(456)
else:
print(789)观察上面代码,发现有下面几点与其他语言不同:
1)if后面的条件表达式没有括号了,同时{}没了,变成了:
2)多条件分支不是使用else if,而是使用elif
2.空语句
可以使用pass占一个位置:
if expression:
pass
else:
print(123)五.循环语句
1)while
直接举个例子:
while num <= 5:
num += 12)for
基本格式:
for 循环变量 in 可迭代对象:
循环体举个例子,打印1-10:
for i in range(1,11):
print(i)使用range函数可以生成[1,11)
打印2,4,6,8,10:
for i in range(2,12,2):
print(i)range后面还可以规定每次递增的大小
注意:if/while/for内定义变量,在其外部也能使用,这个和其他语言是不一样的。
六.函数
1)语法格式
直接举例子:
def test():
return 123
def test(a):
return a函数要先定义再使用。
2)参数
参数不用定义类型,动态类型,传什么是什么。
可以个参数设定一个默认值,在没有传这个参数的时候就使用这个参数:
def test(a,b,c=True):
if c:
print(a)
else:
print(b)可以通过关键词参数来指定传递,这样就算不按照顺序来也行:
def test(a,b):
print(a)
print(b)
test(b=1,a=2)3)返回值
这个nb了,可以一下返回多个值:
def test():
x=1
y=2
return x,y这个可以说是我梦寐以求的功能。
如果只想要其中某个返回值,在接收的时候可以使用_跳过:
def test():
x=1
y=2
return x,y
_,b=test()如果是想在函数内部,修改全局变量的值,需要使用 global 关键字声明,如果不用这个变量就会被当作函数内的局部变量,无法更改全局变量的值。
七.列表
1)创建
两种方法都行:
alist1=[]
alist2=list()里面可以存储不同的类型。
2)下标
下标可以是负数,表示倒数第几个元素。
3)切片操作
通过切片可以取出一组连续的元素,相当于取出子序列。
常规写法:
alist1=[1,2,3,4,5,6]
print(alist1[0:3])表示从下标0遍历到下标2位置。
忽略前后边界:
alist1=[1,2,3,4,5,6]
# 从头遍历到最后
print(alist1[0:])
print(alist1[:6])
print(alist1[:])规定自增大小:
alist1=[1,2,3,4,5,6]
# 从头遍历每次下标+2
print(alist1[::2])
# 从尾遍历每次下标-2
print(alist1[::-2])增加元素:
alist1=[1,2,3,4,5,6]
# 在尾部插入7
alist1.append(7)
# 在0下标插入3
alist1.insert(0,3)查找元素:
alist1=[1,2,3,4,5,6]
# in 用来判断in前面的是不是在集合之中
print(2 in alist1)
# index 查询元素所在的下标
print(alist1.index(3))删除元素:
alist1=[1,2,3,4,5,6]
# pop()可以删除尾部元素
alist1.pop()
# pop(n)可以删除指定下标n的元素
alist1.pop(0)
# remove(n)可以删除值为n的元素
alist1.remove(3)连接列表:
alist1=[1,2,3,4,5,6]
alist2=[7,8,9]
# 将两个链表合并
alist3=alist1+alist2
# 将链表2加在1的后面
alist1.extend(alist2)八.元组
元组的功能与列表是基本一致的,但是元组不能修改集合中的元素,列表可以。
元组在很多时候是默认的集合类型,比如一个函数返回多个值的时候。
九.字典
1)创建
hash1={ }
hash2=dict()2)查找
hash={
"id":1,
"name":"Tom"
}
# in 判断in前面的key是不是在集合中
print("id" in hash)
# 通过key取value
print(hash["id"])3)增加/更新元素
hash={
"id":1,
"name":"Tom"
}
# 如果新增的key没在集合中,添加新的
hash["class"]=1
# 如果新增的key已经存在在集合中,更新key的value
hash["id"]=24)删除元素
hash={
"id":1,
"name":"Tom"
}
hash.pop("id")5)取出key和value
hash={
"id":1,
"name":"Tom"
}
hash.keys()
hash.values()
# 获取所有键值对
hash.items()十.文件操作
1)打开文件
f=open("C:/code/test.txt","r")第一个参数是要打开的文件的路径;
第二个参数是打开方式,r是读的方式,w是写的方式,a是追加写的方式
2)关闭文件
f.close()一个程序能同时打开的文件数量是有上限的
3)写文件
f=open("C:/code/test.txt","w")
f.write("Hello World")
f.close()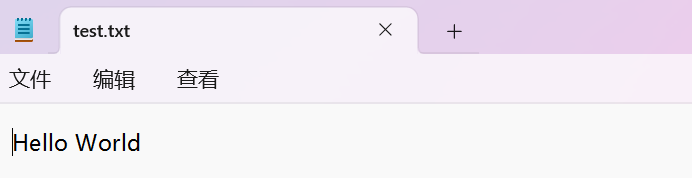
这里要注意,如果我们在打开文件的时候第二个参数选择w,那么我们在下次再打开这个文件的时候,文件的内容会被清除。
如果我们不想清楚,要使用a(追加写)。
4)读文件
f=open("C:/code/test.txt","r")
# 从文件中读两个字符
result=f.read(2)
print(result)
f.close()readlines可以将整个文件读出来,返回的结果是一个列表,每一行是一个元素:
f=open("C:/code/test.txt","r")
result=f.readlines()
print(result)
f.close()如果我们在本地的文本文件写中文读取时可能会出现乱码的情况,整个时候我们可以指定字符集:
f=open("C:/code/test.txt","r",encoding='utf8')
result=f.readlines()
print(result)
f.close()如果容易忘记关闭文件怎么办?Python提供了上下文管理器,我们使用with打开文件,当with内部代码执行完后会自动调用关闭方法:
with open("C:/code/test.txt","r",encoding='utf8') as f:
result=f.readlines()
print(result)
















 3091
3091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









