







 本文介绍了解决通过接口平台上传带有中文名的文件时出现乱码的问题。通过对比抓包数据、排查代码逻辑及更新库版本,最终解决了中文文件名编码异常导致的上传失败。
本文介绍了解决通过接口平台上传带有中文名的文件时出现乱码的问题。通过对比抓包数据、排查代码逻辑及更新库版本,最终解决了中文文件名编码异常导致的上传失败。
在接口平台中,有小伙伴反馈post请求上传文件返回未知异常
{
"statusCode": 50000,
"message": "Internal Server Error or IllegalArgumentException",
"errorMsg": "未知异常"
}
首先怀疑是不是服务的问题哈
使用postman工具上传发现可正常返回,好吧,确实是接口平台的问题
一、抓包对比
那抓包对比一下接口平台请求的数据和postman请求的数据的不同点在哪里
接口平台

postman

通过对比可以发现,通过接口平台请求的数据中filename由于是中文名导致乱码
filename*=utf-8''%E6%A0%B8%E5%BF%83%E6%95%99%E5%B8%88%E6%89%B9%E9%87%8F%E5%AF%BC%E5%85%A5%E6%A8%A1%E6%9D%BF%20.xlsx
二、代码逻辑
具体请求处理的逻辑
if not isinstance(self._content_.request_body, bytes):
for key,value in self._content_.request_body.items():
if isinstance(value,tuple) and value[0] == 'file':
# 文件路径
file_path = value[1]
if file_path is not None:
self._content_.request_body[key] = (os.path.basename(file_path), open(file_path, 'rb').read())
encode_data = encode_multipart_formdata(self._content_.request_body)
self._content_.header['Content-Type'] = encode_data[1]
self._content_.request_body = encode_data[0]
response = requests.post(self._content_.url, headers=self._content_.header, data=self._content_.request_body, params=self._content_.query_params)
查看代码请求的数据
<class 'tuple'>: (b'--afb7944bfb744a7cbd3fc5685cd4a6d7\r\nContent-Disposition: form-data; name="file"; filename*=utf-8\'\'%E6%A0%B8%E5%BF%83%E6%95%99%E5%B8%88%E6%89%B9%E9%87%8F%E5%AF%BC%E5%85%A5%E6%A8%A1%E6%9D%BF%20.xlsx\r\nContent-Type: application/vnd.openxmlformats-officedocument.spreadsheetml.sheet\r\n\r\nPK\x03\x04\n\x00\x00\x00\x00\x00\x87N\xe2@\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\t\x00\x00\x00docProps/PK\x03\x04\x14\x00\x00\x00\x08\x00\x87N\xe2@\x96\xb0=\xf9;\x01\x00\x00j\x02\x00\x00\x10\x00\x00\x00docProps/app.xml\x9d\x92\xc1J\x031\x14E\xf7\x82\xff\x10\xb2o3mE\xa4dR\x04\x11w\x0e\xb4\xea:f\xde\xb4\x81\x99dH\x9eC\xeb\xb7\xb8\xd0\x85\xe0\x1f\xb8\xd1\xbfQ\xf13\xccL\xa0NE7\xee\xee\xcb}\xdc\x9c\x1b\xc2g\xeb\xaa$\r8\xaf\xadI\xe9h\x98P\x02F\xd9\\\x9beJ/\x16\xa7\x83#J<J\x93\xcb\xd2\x1aH\xe9\x06<\x9d\x89\xfd=\x9e9[\x83C\r\x9e\x84\x08\xe3S\xbaB\xac\xa7\x8cy\xb5\x82J\xfaa\xb0Mp\n\xeb*\x89atKf\x8bB+8\xb1\xea\xa6\x02\x83l\x9c$\x87\x0c\xd6\x08&\x87|Po\x03iL\x9c6\xf8\xdf\xd0\xdc\xaa\x96\xcf_.6u\x00\x16\xfc\xb8\xaeK\xad$\x86\x96\xe2*\x9b\x93\xcf\x87\xa7\x8f\xfb\x17\xce\xfa\xe7\xfc\x0cd\xdb;\xdd\x988\xc7`us\xe6^\xc32\xca\x9c\t_V\x1c\x0b\xe1A\xbd\x07O\'\x12[\xd3\xd1y\x10\n\x0b\x80\xa0\xabtG{{T\x0e\xc5^\xfb\x08\xab\n.n \x8a\x9e \x07\xbaT\xc0\xe3\xb7\xd7:\x80(s\x02\xf8e\xfd\xec\xd3\xdaYk\xd8~\xda\x94z\xaaEi\xce\xe0\xc7-B\xda}\xaai\xdf\xf5\xae\x91\xba\xbf(\xdc\xd0G\xff\xc2\x81\xfc\xd5\xc7\xed\x7f\xfb\xe0\xf1q\x1f~\x03PK\x01\x02\x14\x00\x14\x00\x00\x00\x08\x00\x87N\xe2@oy\x05"s\x01\x00\x00\x1d\x06\x00\x00\x13\x00\x00\x00\x00\x00\x00\x00\x01\x00')
发现确实在发出数据时已经中文编码异常
三、代码排查
有两处可能的异常,一个是文件读取,一个是编码文件格式
3.1 open
文件读取的代码如下
self._content_.request_body[key] = (os.path.basename(file_path), open(file_path, 'rb').read())
返回结果
<class 'dict'>: {'file': ('核心数据批量导入模板 .xlsx', b'PK\x03\x04\n\x00\x00\x00\x00\x00\x87N\xe2@\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\t\x00\x00\x00docProps/PK\x03\x04\x14\x00\x00\x00\x08\x00\x87N\xe2@\x96\xb0=\xf9;\x01\x00\x00j\x02\x00\x00\x10\x00\x00\x00docProps/app.xml\x9d\x92\xc1J\x031\x14E\xf7\x82\xff\x10\xb2o3mE\xa4dR\x04\x11w\x0e\xb4\xea:f\xde\xb4\x81\x99dH\x9eC\xeb\xb7\xb8\xd0\x85\xe0\x1f\xb8\xd1\xbfQ\xf13\xccL\xa0NE7\xee\xee\xcb}\xdc\x9c\x1b\xc2g\xeb\xaa$\r8\xaf\xadI\xe9h\x98P\x02F\xd9\\\x9beJ/\x16\xa7\x83#J<J\x93\xcb\xd2\x1aH\xe9\x06<\x9d\x89\xfd=\x9e9[\x83C\r\x9e\x84\x08\xe3S\xbaB\xac\xa7\x8cy\xb5\x82J\xfaa\xb0Mp\n\xeb*\x89atKf\x8bB+8\sheet1.xmlPK\x01\x02\x14\x00\x14\x00\x00\x00\x08\x00\x87N\xe2@j\xcd\xdc\xfd\xa7\x02\x00\x00\xaa\x08\x00\x00\x18\x00\x00\x00\x00\x00\x00\x00\x01\x00 \x00\x00\x00\xe9#\x00\x00xl/worksheets/sheet2.xmlPK\x01\x02\x14\x00\x14\x00\x00\x00\x08\x00\x87N\xe2@\x1d{\xe8+\xad\x01\x00\x00H\x03\x00\x00\x18\x00\x00\x00\x00\x00\x00\x00\x01\x00 \x00\x00\x00\xc6&\x00\x00xl/worksheets/sheet3.xmlPK\x05\x06\x00\x00\x00\x00\x13\x00\x13\x00\x93\x04\x00\x00QC\x00\x00\x00\x00')}
3.2 encode_multipart_formdata
encode_data = encode_multipart_formdata(self._content_.request_body)
返回的结果
<class 'tuple'>: (b'--c9762a8ce7f441d493ccd3262ca77d6f\r\nContent-Disposition: form-data; name="file"; filename*=utf-8\'\'%E6%A0%B8%E5%BF%83%E6%95%99%E5%B8%88%E6%89%B9%E9%87%8F%E5%AF%BC%E5%85%A5%E6%A8%A1%E6%9D%BF%20.xlsx\r\nContent-Type: application/vnd.openxmlformats-officedocument.spreadsheetml.sheet\r\n\r\nPK\x03\x04\n\x00\x00\x00\x00\x00\x87N\xe2@\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\t\x00\x00\x00docProps/PK\x03\x04\x14\x00\x00\x00\x08\x00\x87N\xe2@\x96\xb0=\xf9;\x01\x00\x00j\x02\x00\x00\x10\x00\x00\x00docProps/app.xml\x9d\x92\xc1J\x031\x14E\xf7\x82\xff\x10\xb2o3mE\xa4dR\x04\x11w\x0e\xb4\xea:f\xde\xb4\x81\x99dH\x9eC\xeb\xb7\xb8\xd0\x85\xe0\x1f\xb8\xd1\xbfQ\xf13\xccL\xa0NE7\xee\xee\xcb}\xdc\x9c\x1b\xc2g\xeb\xaa$\r8\xaf\xadI\xe9h\x98P\x02F\xd9\\\x9beJ/\x16\xa7\x83#J<J\x93\xcb\xd2\x1aH\xe9\x06<\x9d\x89\xfd=\x9e9[\x83C\r\x9e\x84\x08\xe3S\xbaB\xac\xa7\x8cy\xb5\x82J\xfaa\xb0Mp\n\xeb*\x89atKf\x8bB+8\xb1\xea\xa6\x02\x83l\x9c$\x87\x0c\xd6\x08&\x87|Po\x03iL\x9c6\xf8\xdf\xd0\xdc\xaa\x96\xcf_.6u\x00\x16\xfc\xb8\xaeK\xad$\x86\x96\xe2*\x9b\x93\xcf\x87\xa7\x8f\xfb\x17\xce\xfa\xe7\xfc\x0cd\sheet1.xmlPK\x01\x02\x14\x00\x14\x00\x00\x00\x08\x00\x87N\xe2@j\xcd\xdc\xfd\xa7\x02\x00\x00\xaa\x08\x00\x00\x18\x00\x00\x00\x00\x00\x00\x00\x01\x00 \x00\x00\x00\xe9#\x00\x00xl/worksheets/sheet2.xmlPK\x01\x02\x14\x00\x14\x00\x00\x00\x08\x00\x87N\xe2@\x1d{\xe8+\xad\x01\x00\x00H\x03\x00\x00\x18\x00\x00\x00\x00\x00\x00\x00\x01\x00 \x00\x00\x00\xc6&\x00\x00xl/worksheets/sheet3.xmlPK\x05\x06\x00\x00\x00\x00\x13\x00\x13\x00\x93\x04\x00\x00QC\x00\x00\x00\x00\r\n--c9762a8ce7f441d493ccd3262ca77d6f--\r\n', 'multipart/form-data; boundary=c9762a8ce7f441d493ccd3262ca77d6f')
四、编码格式
那是否可以在encode_multipart_formdata增加指定编码格式解决这个问题呢?
查看encode_multipart_formdata的源码
def encode_multipart_formdata(fields, boundary=None):
"""
Encode a dictionary of ``fields`` using the multipart/form-data MIME format.
:param fields:
Dictionary of fields or list of (key, :class:`~urllib3.fields.RequestField`).
:param boundary:
If not specified, then a random boundary will be generated using
:func:`mimetools.choose_boundary`.
"""
body = BytesIO()
if boundary is None:
boundary = choose_boundary()
for field in iter_field_objects(fields):
body.write(b('--%s\r\n' % (boundary)))
writer(body).write(field.render_headers())
data = field.data
if isinstance(data, int):
data = str(data) # Backwards compatibility
if isinstance(data, six.text_type):
writer(body).write(data)
else:
body.write(data)
body.write(b'\r\n')
body.write(b('--%s--\r\n' % (boundary)))
content_type = str('multipart/form-data; boundary=%s' % boundary)
return body.getvalue(), content_type
并不能指定编码格式
网上找到一种解决的方式
修改requests库所引用的urllib3库的源文件fields.py
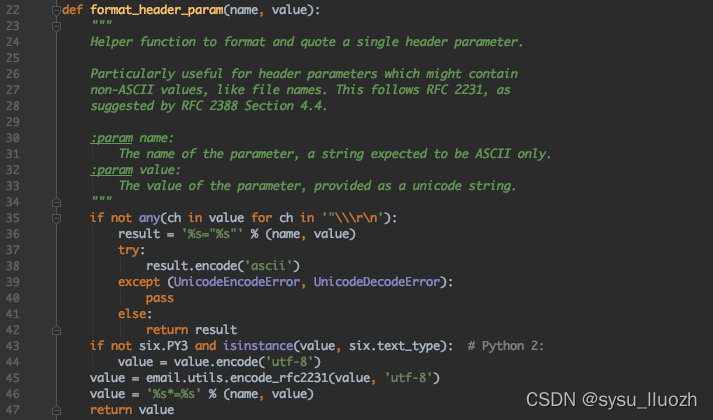
- 注释掉图中第45行代码
value = email.utils.encode_rfc2231(value, 'utf-8')
- 把图中第46行代码修改
value = '%s="%s"' % (name, value)
实测有效,但是这样包依赖相对比较麻烦
五、解决方案
那是否有更优雅的方式可以解决这个问题么?可以看看requests库或者urllib3库中是否有提出这个问题
在requests库的issues中有提到这个问题

作者提到

查看urllib3库中的issues
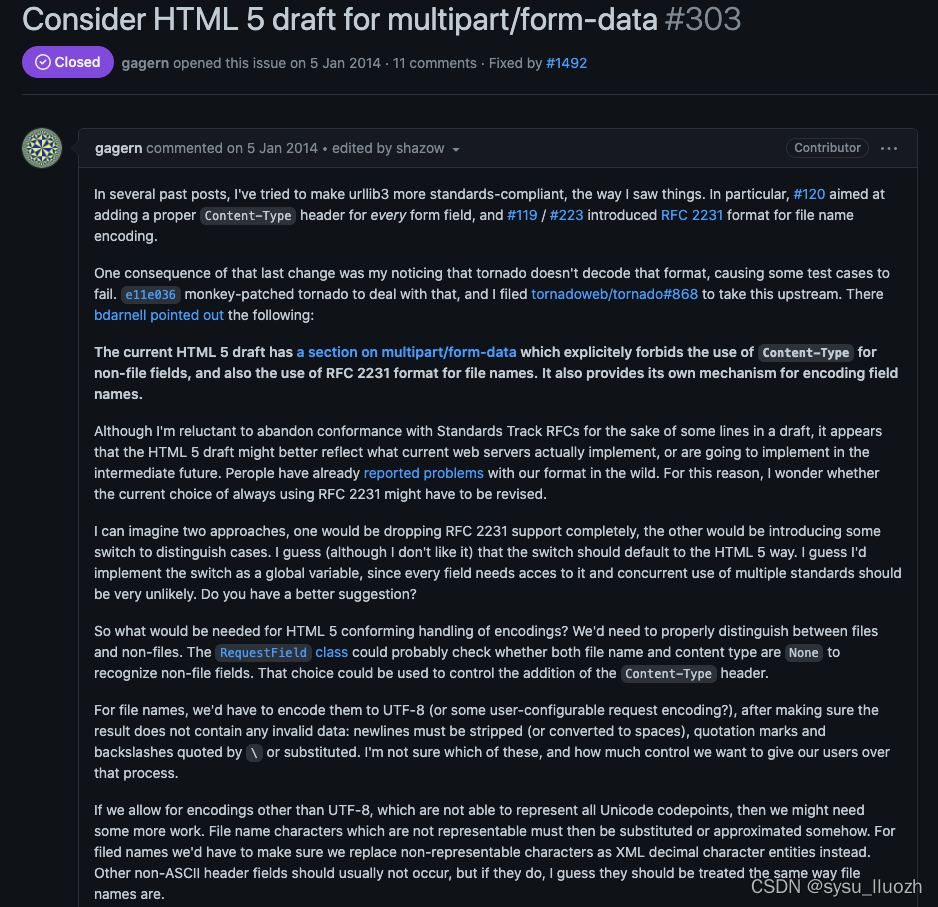
作者针对此问题已解决
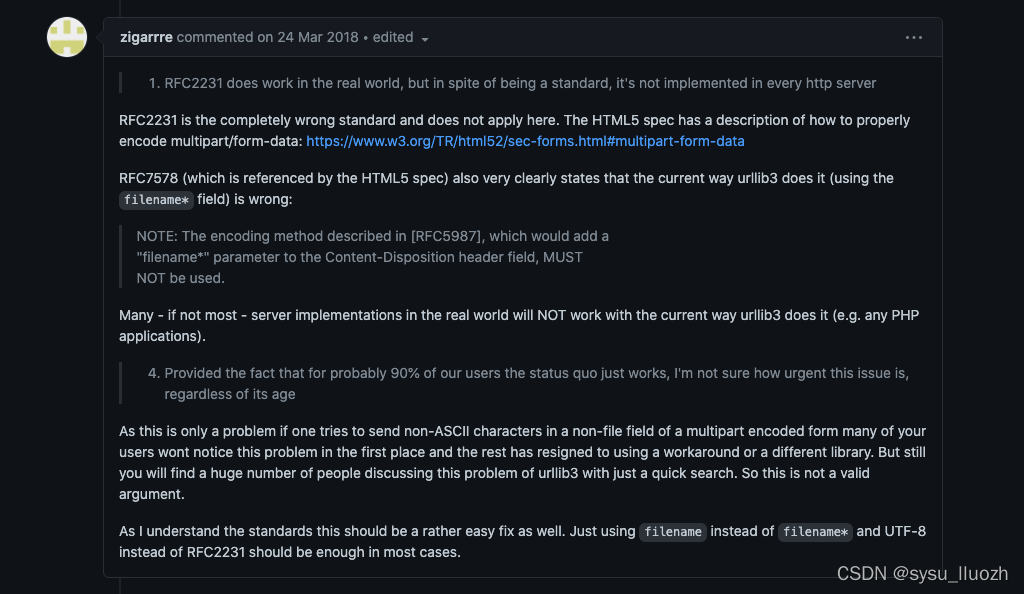
六、问题修复
查看当前使用requests和urllib3的版本:
requests 2.18.1
urllib3 1.21.1
可以看到当前使用的requests库和urllib3库均在此问题之前,更新requests库和urllib3库的版本
pip3 install requests==2.22.0
pip3 install urllib3==1.25.7
可以查看此时urllib3库的源文件fields.py
def format_header_param_rfc2231(name, value):
"""
Helper function to format and quote a single header parameter using the
strategy defined in RFC 2231.
Particularly useful for header parameters which might contain
non-ASCII values, like file names. This follows RFC 2388 Section 4.4.
:param name:
The name of the parameter, a string expected to be ASCII only.
:param value:
The value of the parameter, provided as ``bytes`` or `str``.
:ret:
An RFC-2231-formatted unicode string.
"""
if isinstance(value, six.binary_type):
value = value.decode("utf-8")
if not any(ch in value for ch in '"\\\r\n'):
result = u'%s="%s"' % (name, value)
try:
result.encode("ascii")
except (UnicodeEncodeError, UnicodeDecodeError):
pass
else:
return result
if six.PY2: # Python 2:
value = value.encode("utf-8")
# encode_rfc2231 accepts an encoded string and returns an ascii-encoded
# string in Python 2 but accepts and returns unicode strings in Python 3
value = email.utils.encode_rfc2231(value, "utf-8")
value = "%s*=%s" % (name, value)
if six.PY2: # Python 2:
value = value.decode("utf-8")
return value
可以看到已兼容解决编码的问题
使用更新后的库进行请求测试验证,问题已解决



















 1950
1950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











