






本文内容整理自 Apache IoTDB committer 陈荣钊的设计文档。
IoTDB 集群元数据分区信息、数据分区信息均在 ConfigNode 共识组中由分区表进行管理。
基本概念
共识组
集群共有三类共识组,如下图所示:
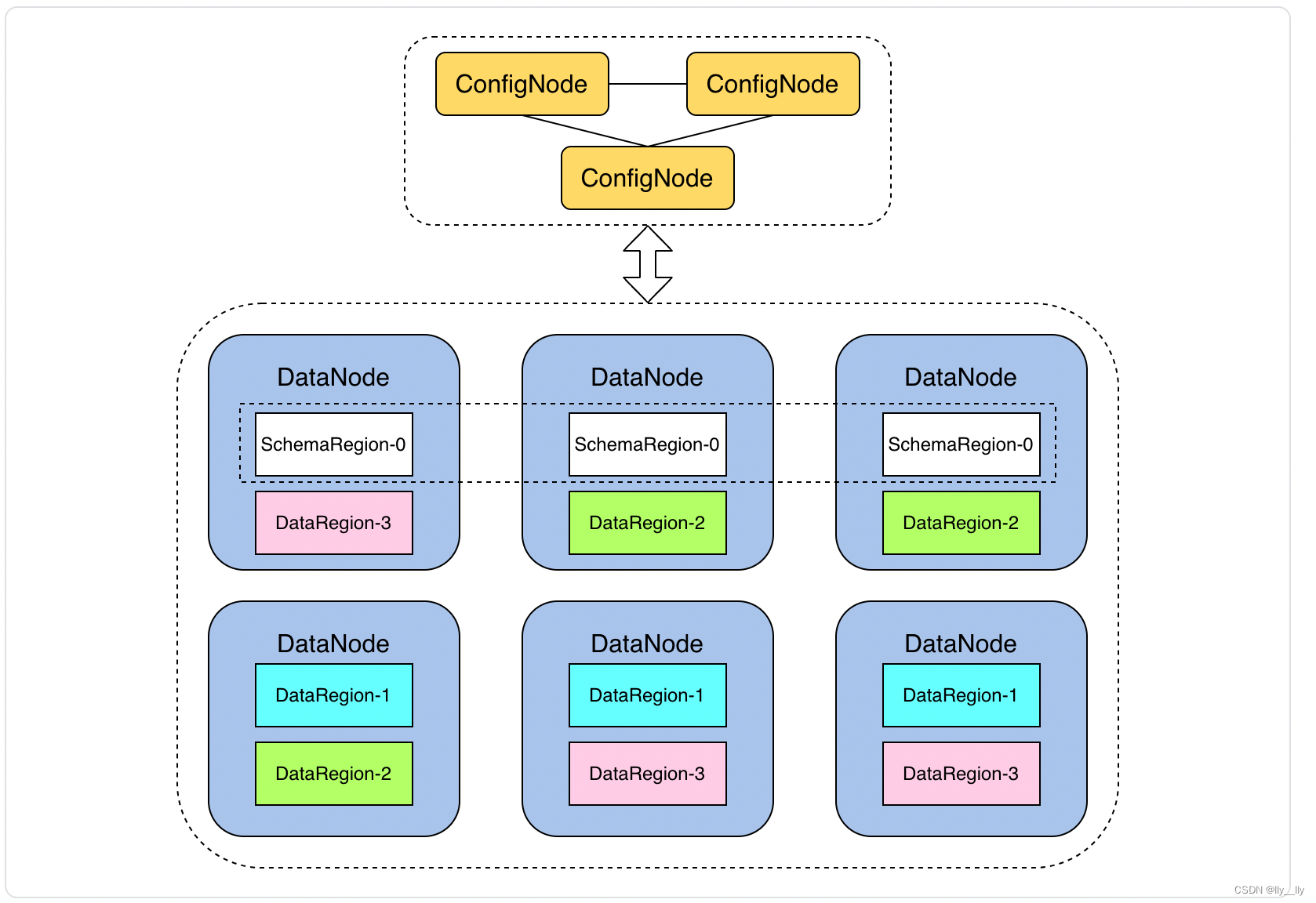
对各共识组及共识组成员的解释如下:
- ConfigNodeGroup: 集群所有 ConfigNode 组成一个 ConfigNode 共识组,通过共识协议维护一致的分区表
- SchemaRegion: 元数据管理引擎,相当于一组元数据的副本(管理多个元数据分区)
- SchemaRegionGroup: 由一组 SchemaRegion 组成的共识组(如图中三个 SchemaRegion-0)
- DataRegion: 数据管理引擎,相当于一组数据的副本(管理多个数据分区)
- DataRegionGroup: 由一组 DataRegion 组成的共识组(如图中三个 DataRegion-1,三个DataRegion-2 和三个 DataRegion-3)
分区槽
序列分区槽(SeriesPartitionSlot)
定义:序列分区槽是对时间序列的纵向管理机制,每个数据库持有固定数量的序列分区槽(默认 10000 个),该数据库管理的每个时间序列都将通过序列分区算法被分配给唯一的序列分区槽管理。
优势:记录设备或时间序列级别的分区会导致分区信息过大,维护成本过高。因为一旦记录该 map 就意味着整个集群每创建一个设备或时间序列就需要在 ConfigNode 共识组进行一次共识同步,这会导致 ConfigNode 内存开销成为瓶颈,而且经过实验,在 java 中如果使用 hashmap<String, Integer> 进行存储,在 device 数目为 1 亿,device 长度约为 25 时(类似于 root.G201.FRG-DOF-027-Z100)需要 15 GB 的内存,在上亿 device 以上的场景捉襟见肘。因此可以引入序列分区槽来解决该问题。通过 Hash 分组避免 device → SeriesPartitionSlot 的映射占用过多内存。 设备组的个数是调度灵活度和数据分区表大小之间的权衡,目前默认个数为 10000
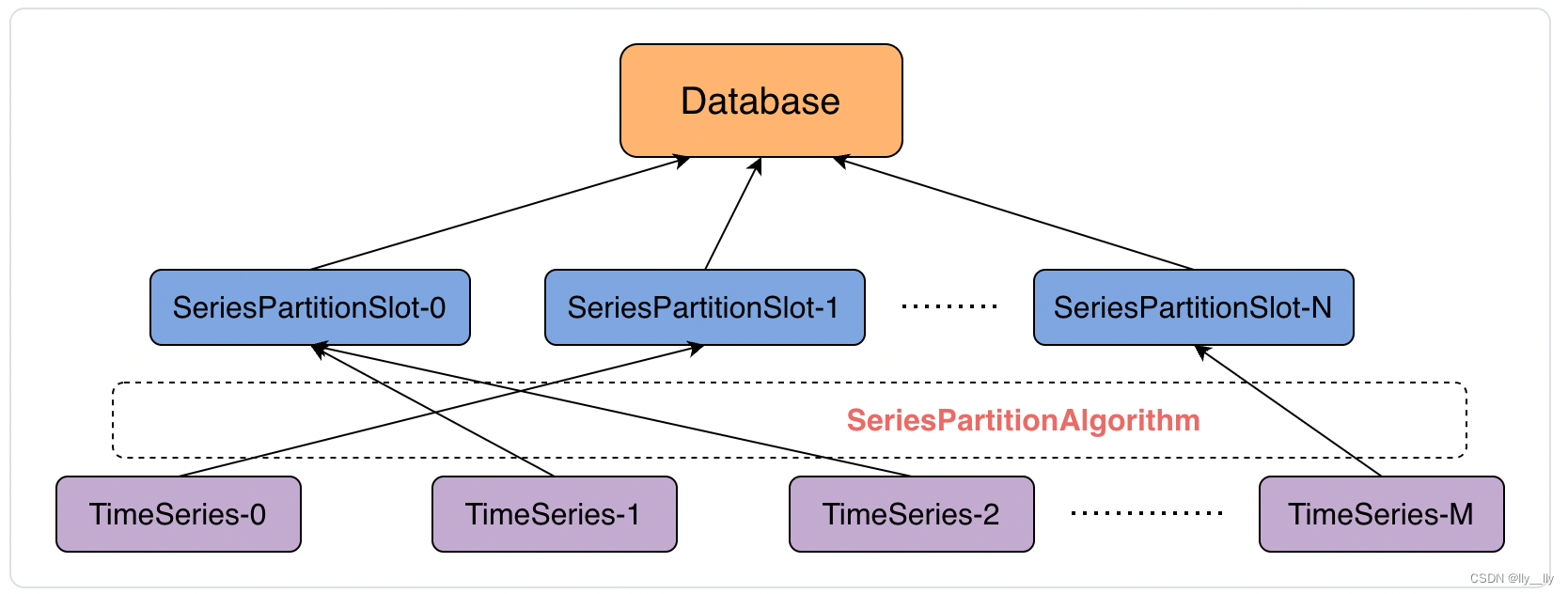
时间分区槽(TimePartitionSlot)
定义: 一个序列分区槽和一个时间分区槽可以组合产生一个数据分区(当该序列分区槽在该时间分区槽下有对应数据时)。
优势:每个时间序列都将持续产生数据,若是一个时间序列产生的全部数据持续存储于一个节点,可能会导致单点压力过大和数据偏斜,且集群新增的 DataNode 可能无法得到有效利用。时间分区槽以对时序数据横向分片的形式使得集群时序数据的存储易于规划。
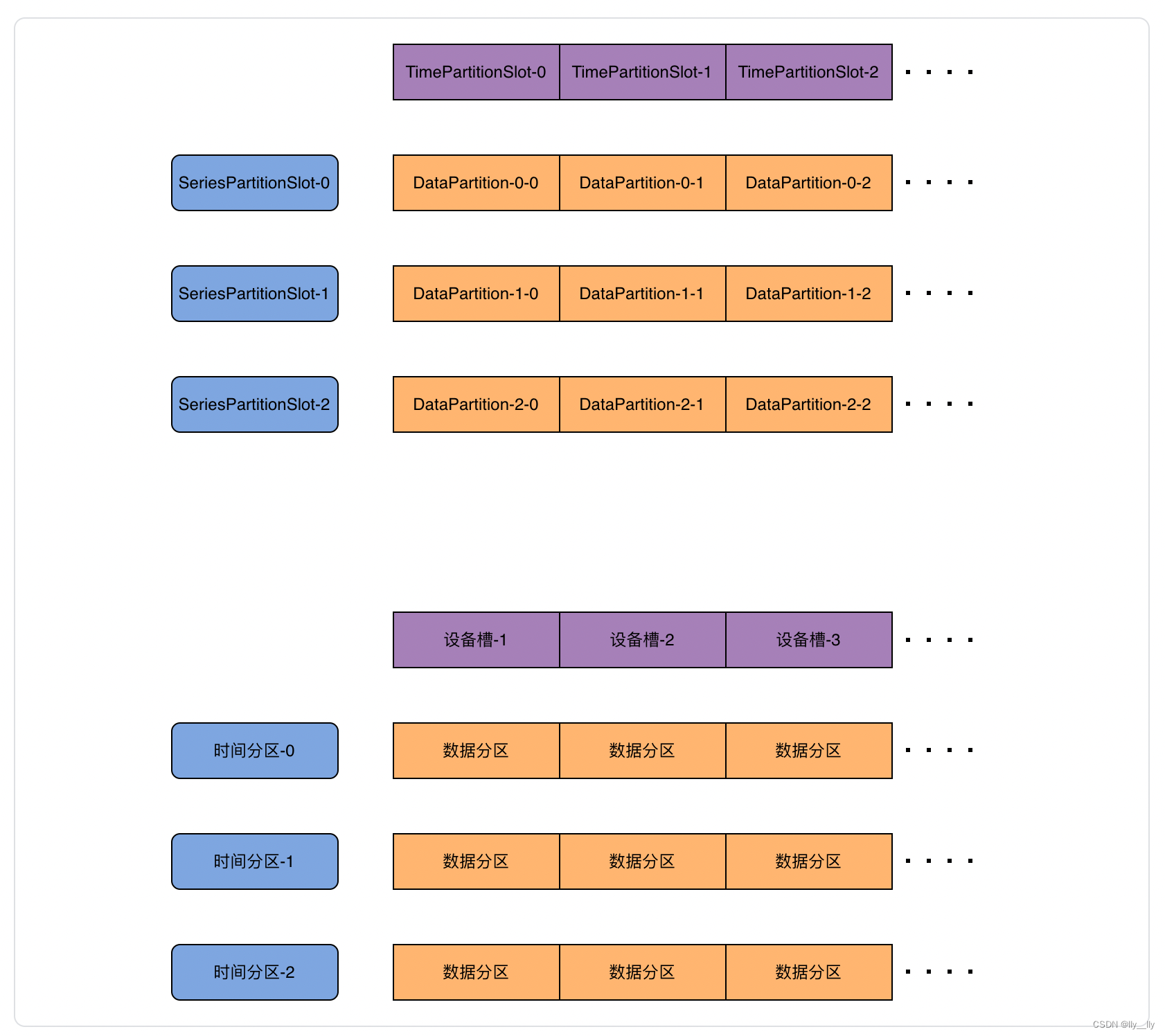
元数据分区方案
将时间序列元数据按照设备ID分到不同序列分区槽,即每个序列分区槽产生一个元数据分区,包含多个设备的元数据。
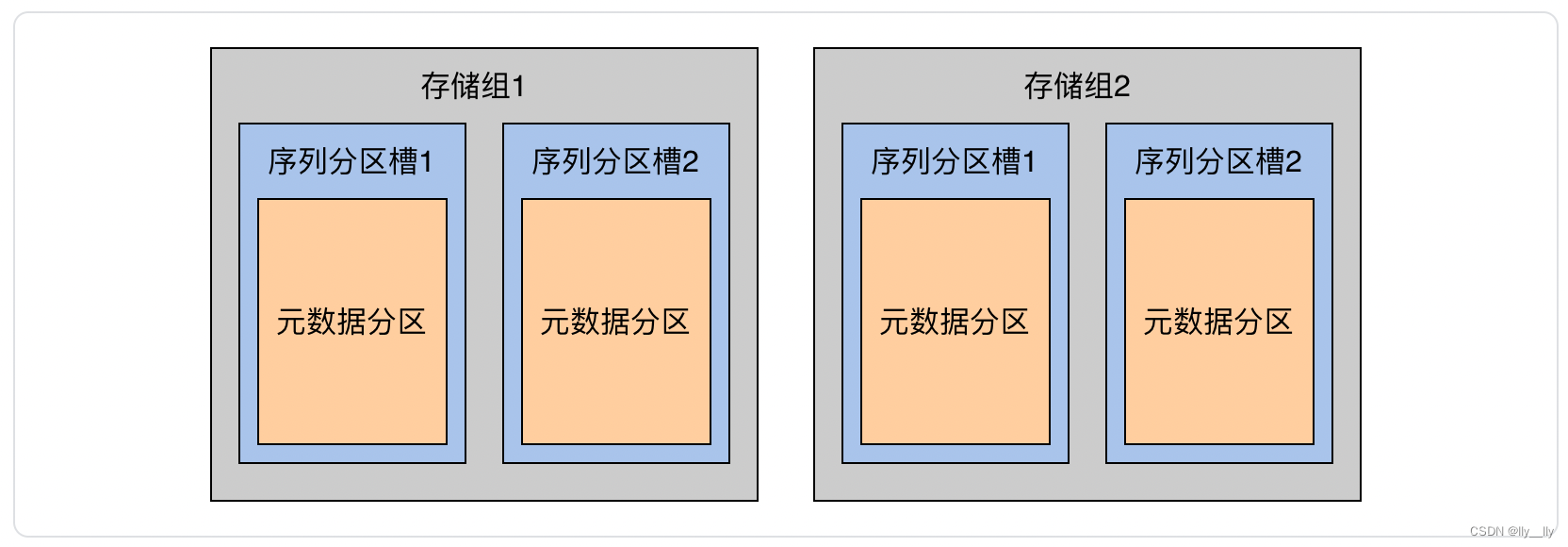
元数据分区表
集群元数据分区由元数据分区表管理,如下图所示:
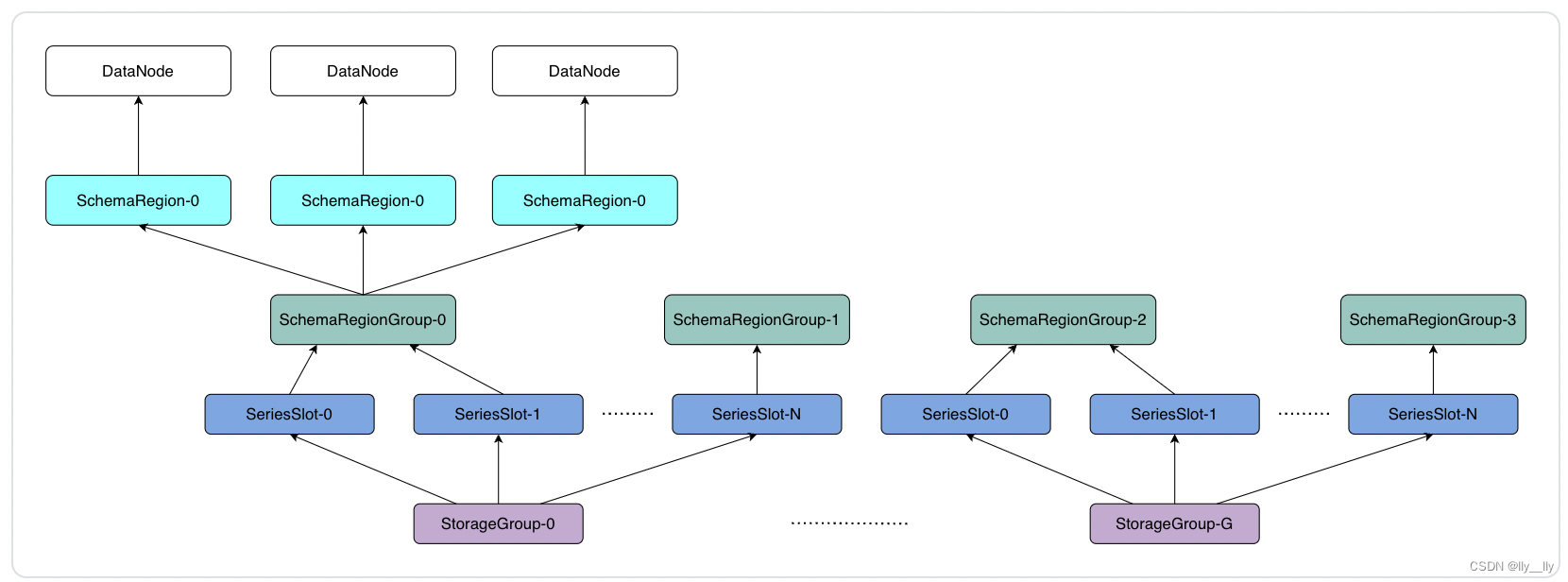
数据结构(SchemaPartitionTable)
public class SchemaPartitionTable {
// Map<序列分区槽,SchemaRegion 编号>
private final Map<TSeriesPartitionSlot, TConsensusGroupId> schemaPartitionMap;
}
- Map<数据库, Map<序列分区槽, SchemaRegion 共识组>>
- 单个数据库的内存开销估计:10000 序列分区槽 * (4(TSeriesPartitionSlot) + 8(TConsensusGroupId)) ≈ 0.11 MB
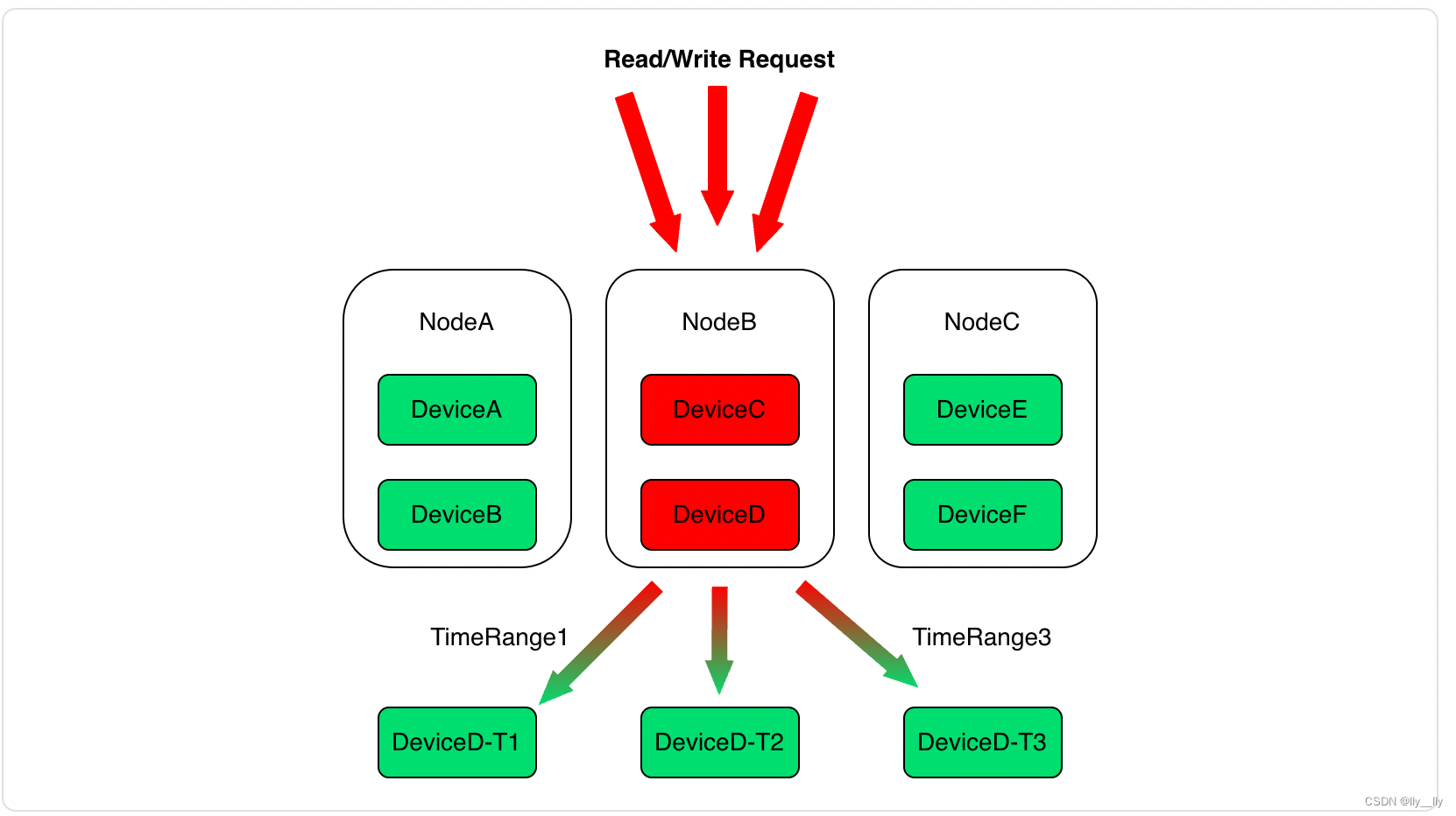
数据分区方案
- 纵向(按数据库)分片:根据设备 ID 的前缀找到所属的数据库
- 纵向(按设备)分片:将设备 hash 到 N(默认10000,集群第一次启动时确定,之后不可变更) 个序列分区槽(SeriesPartitionSlot)里
- 横向(按时间)分片:默认 1 天进行分片(数据库内的数据组织粒度与此时间分片粒度保持一致)
即每个序列分区槽在每个时间分区下产生一个数据分区
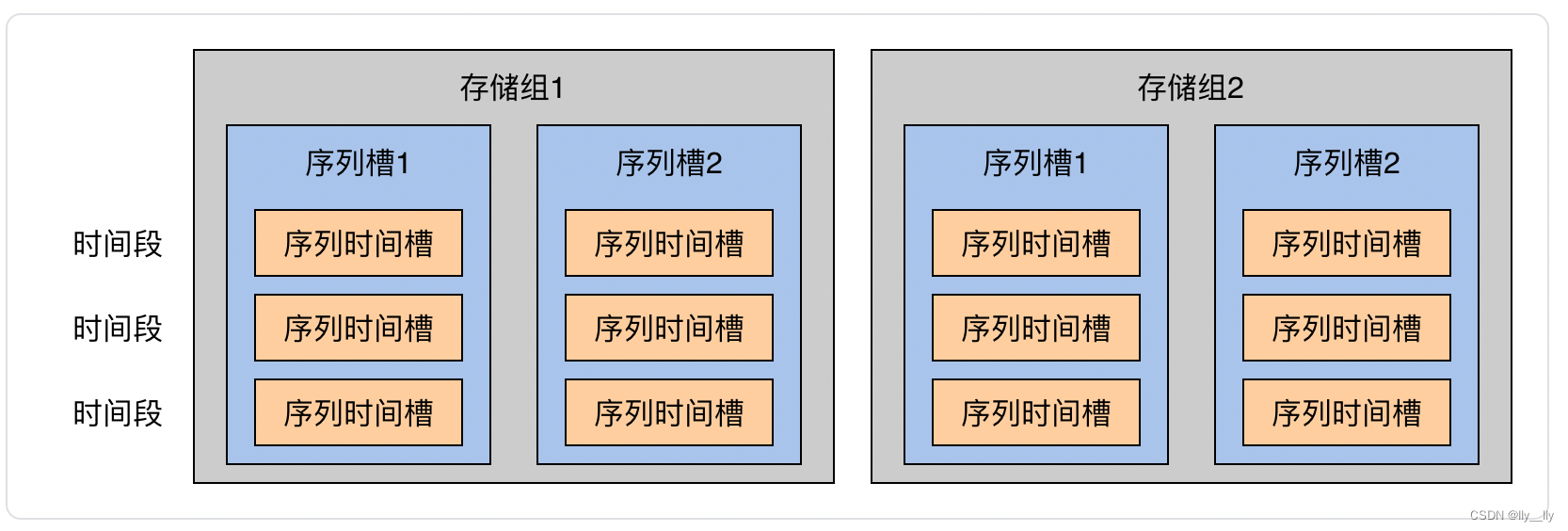

数据分区表
集群数据分区由数据分区表管理,如下图所示:
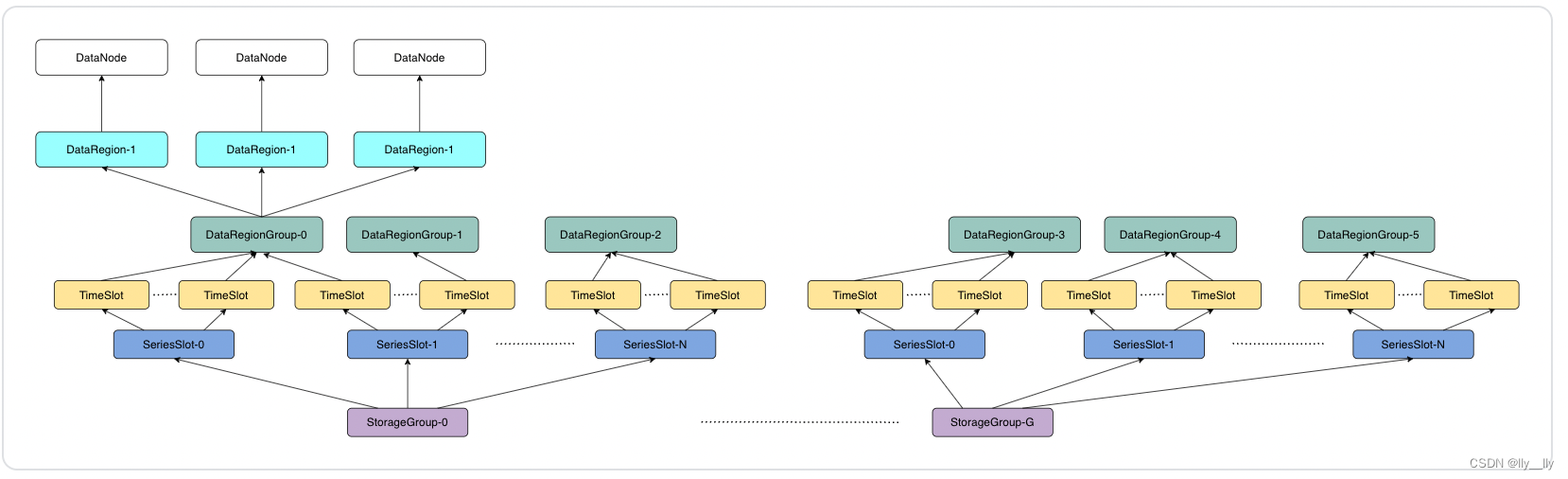
数据结构(DataPartitionTable)
public class DataPartitionTable {
private final Map<TSeriesPartitionSlot, SeriesPartitionTable> dataPartitionMap;
}
public class SeriesPartitionTable {
private final Map<TTimePartitionSlot, List<TConsensusGroupId>> seriesPartitionMap;
}
- Map<数据库, Map<序列分区槽, Map<时间段, List<DataRegion 共识组>>>>
- 单个数据库的内存开销估计:10000 序列分区槽 * 365 (一天一个分区运行 1 年) * 10 (持续运行 10 年) *(4(TSeriesPartitionSlot) + 8(TTimePartitionSlot) + 8(TConsensusGroupId)) ≈ 0.68G
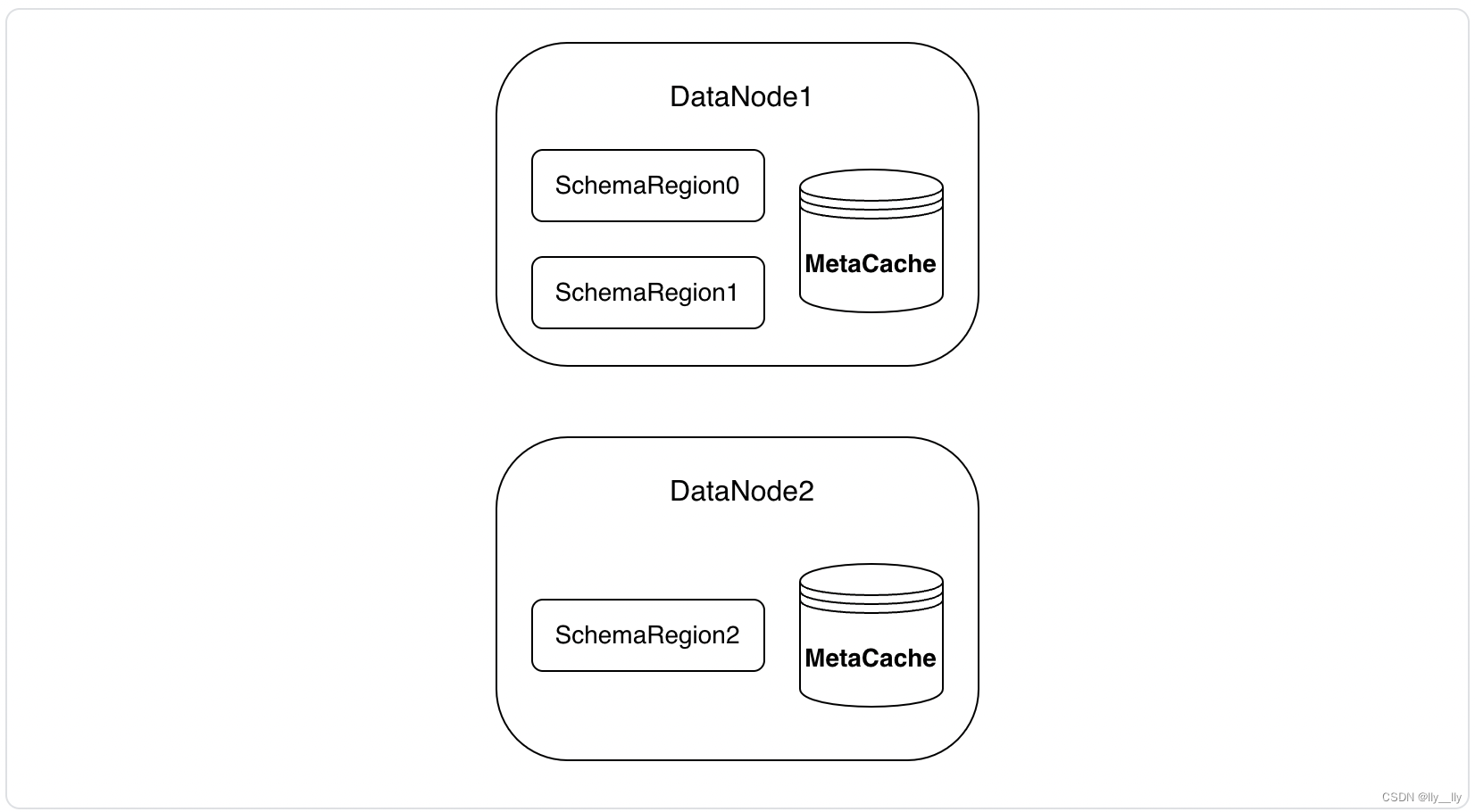
元数据分区和数据分区互相独立
参考元数据和数据分区方案,可以看到 IoTDB 中元数据分区和数据分区是独立的,由 SchemaRegion 和 DataRegion 分别管理。这是由于数据分区还有按时间维度的划分,一个 Device 的数据可能落在多个数据分区中,所以没有把两种分区合并为 Region 一起存储。如果每个数据分区都存储了那个数据分区下的元数据信息,会导致元数据信息的冗余存储。同时,做某些元数据查询时,比如 count timeseries 时,需要拉取所有数据分区上的元数据信息,然后进行合并去重。
元数据/数据分区分配方案
当 ConfigNode-leader 接收到 getOrCreateSchemaPartition/getOrCreateDataPartition 请求时,通过以下流程进行分区分配:
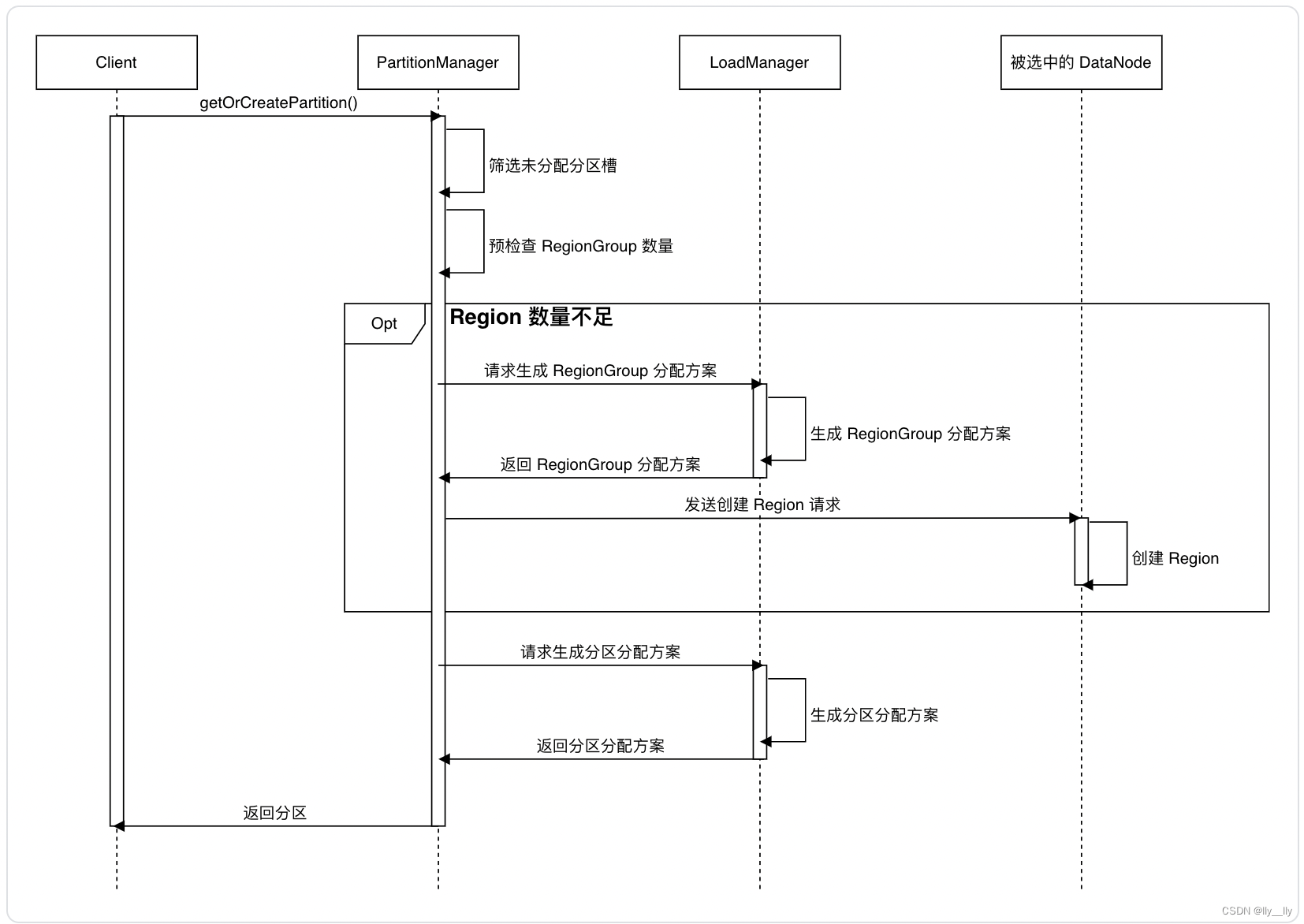
分区分配基本流程描述:
- 首先计算时间序列对应的序列分区槽
- 检查该 Database 是否有足够数量的 Region,如果没有,需要先进行 Region 扩容
- 判断 Region 数量是否足够需要结合参数 schema_region_group_extension_policy/data_region_group_extension_policy
- 采用贪心算法,Region 会分配给当前所有 DataNode 中管理 Region 数最少的 DataNode
- 将分区分配给 Region:
- 每个序列分区槽将产生一个元数据分区,采用贪心算法在 SchemaRegionGroup 之间均匀分配新出现的元数据分区:即新出现的元数据分区总是分配给当前拥有元数据分区数最少的 SchemaRegionGroup
- 每个序列分区槽在每个时间分区槽下产生一个数据分区,对于每个数据分区:
- 继承策略:若设置参数 enable_data_partition_inherit_policy = true,且该数据分区对应序列分区槽下,前一个时间分区槽对应的数据分区已被分配,那么该数据分区将继承前一个分区所在 DataRegionGroup
- 贪心策略:将新出现的数据分区分配给当前拥有数据分区数最少的 DataRegionGroup














 2914
2914











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









