







此篇文章根据 国外的两个文档进行相关分析以及个人理解。
http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf Doug Lea文章原地址
http://www.dre.vanderbilt.edu/~schmidt/PDF/reactor-siemens.pdf 论文地址
1.什么是Reactor模式
Reactor是一种广泛应用在服务器端开发的设计模式,是一种基于事件驱动的设计模式,所谓的事件驱动通俗点说就是回调的方式。我们知道,对于应用服务器,一个主要规律就是,CPU的处理速度是要远远快于IO速度的,如果CPU为了IO操作(例如从Socket读取一段数据)而阻塞显然是不划算的。好一点的方法是分为多进程或者线程去进行处理,但是这样会带来一些进程切换的开销,试想一个进程一个数据读了500ms,期间进程切换到它3次,但是CPU却什么都不能干,就这么切换走了,是不是也不划算,这时先驱们找到了事件驱动,或者叫回调的方式,来完成这件事情。这种方式就是,应用业务向一个中间人注册一个回调(event handler),当IO就绪后,就这个中间人产生一个事件,并通知此handler进行处理。
2.为什么要了解Reactor模式以及如何使用
有助于我们理解Netty设计模式,以及它们的源码分析,而且不单单Netty采用此设计模式,其他的网络应用服务器开发也应用了此模式。
下面我们根据http://www.dre.vanderbilt.edu/~schmidt/PDF/reactor-siemens.pdf 文章分析一下Reactor模式
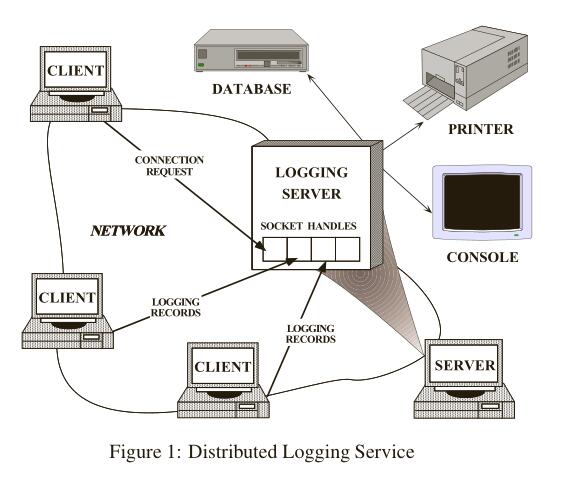
对于一个事件驱动的分布式日志登录服务系统,如下图1所示。
--------------------------------------------------------------------------------------------------------------------------------------------------------
客户端应用通过日志服务来录入它们当前状态和记录,这些状态可记录可能包含了错误通知信息、断点调试信息等。日志记录被发送到一个中央日服务器上,该服务器可以处理日志和连接用户请求。客户端想要记录日志信息,首先必须发送一个连接请求给服务器。服务器通过一个“处理工厂”来监听客户端对应的地址信息,以等待这些连接请求的到来。当一个连接请求到来时,“处理工厂”就创建一个handle,其代表了连接的端点,用来建立客户端和服务器之间的连接。当handle收到来自客户端的请求连接时,就会返回给服务器。一旦客户端连接成功,它们就可以同时发送日志记录到服务器。
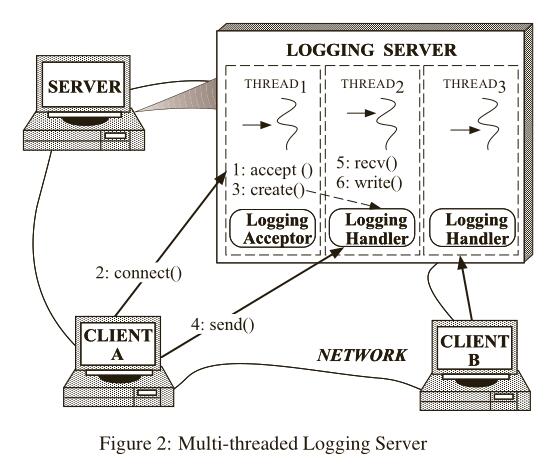
或许最有效的方法来开发一个并发日志系统是使用多线程,这样可以同时处多个理客户端请求,如下图2所示。
--------------------------------------------------------------------------------------------------------------------------------------------------------
然而,多线程实现这样的分布式日志系统可能会面临下面的问题:
可用性:服务器必须能够处理传入请求即使是等待其他请求到达的。特别是,一个服务器不能无限期地处理任何单一来源的事件而排斥其他事件源。因为这可能大大延迟响应其他客户的时间。
效率:一个服务器应该做到延迟最小化、吞吐量最大化,避免不必要地使用CPU。多线程可能会导致糟糕的性能由于上下文切换、同步和数据移动。
编程简洁:服务器的设计上应该简化使用合适的并发策略。多线程可能需要复杂的并发控制方案。
可移植性:多线程不是可用在所有操作系统平台。
适应性:集成新的或改进服务,如改变消息格式或添加服务器端缓存,应该承担最小的现有代码的修改和维护成本。例如,实现新应用程序服务应该不需要修改通用事件多路分解和调度机制。
针对上面的问题,可以集成同步多路分解事件并分发相应的事件处理程序来处理相应的事件。对于每一个应用程序所提供的服务,引入一个单独的事件处理器处理某些类型的事件。所有事件处理程序实现了相同的接口。事件处理程序注册一个初始调度程序,它使用一个同步事件信号分离器等待事件发生。当事件发生时,同步事件信号分离器通知初始调度器,它同步告知事件处理程序去关联对应的事件。事件处理程序然后分派事件到实现了所请求服务的方法中。
上述日志系统的Reactor模式类图如下所示:
由图可已看出Reactor模式的角色构成一种有5种:
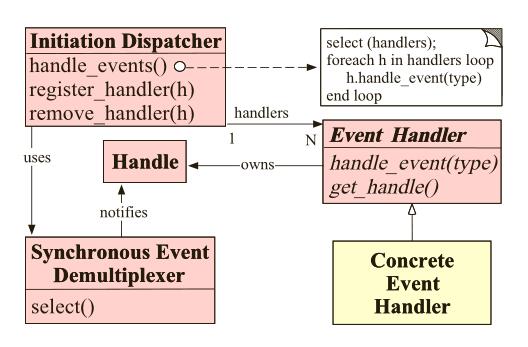
--------------------------------------------------------------------------------------------------------------------------------------------------------1. Handle(句柄或者描述符):本质上表示一种资源,是有操作系统提供的;该资源用于一个个的事件,比如说文件描述符,或者针对网络编程中的Socket描述符。事件即可已来自于外部,也可以来自于内部;外部事件比如说客户端的连接请求,客户端发送过来数据等;内部事件比如操作系统产生的定时器事件等。它本质就是一个文件描述符。Handle是事件产生的发源地,例如客户端链接服务器端,以及发送数据事件等。
2. Synchronous Event Demultipexer(同步事件分离器):它本身就是一个系统调用,用于等待事件发生(事件可能是一个,也可能是多个)。调用方在调用它的时候会被阻塞,一直阻塞到同步事件分离器上有事件产生为止。对于Liunx来说,同步事件分离器指的是常用的IO多路复用器,不如select、poll、epoll等。在JAVA NIO中,同步事件分离器对应的组件就是Selector;对应的阻塞方法就是select方法。
3. Event Handler(事件处理器):本身由多个回调方法构成,这些回调方法构成了与应用相关的对于某个事件的反馈机制。而JAVA NIO 并未给我们提供相关的事件处理器,我们都是自己处理的,而Netty 提供了很多的回调方法 例如 通道注册,通道激活,通道读数据等回调方法。Netty相比NiO来说,在事件处理器方面提供了大量的回调方法,提供了在特定事件产生时实现相应的回调方法进行业务逻辑的处理。
4. Concrete Event Handler(具体事件处理器):它是Event Handler 的实现,它本身实现了事件处理器锁提供的各个回调方法,从而实现了特定于业务的逻辑,它本质就是我们编写的一个个的处理器实现。
5. Initiation Dispathcher(初始分发器):实际上就是Reactor角色。它本身定义了一些规范,这些规范用于控制事件的调度方式,同时又提供了应用进行事件处理器的,注册、删除等设施。它本身是整个事件处理器的核心所在,Initiation Dispathcher会通过同步事件分离器来等待事件的发生。一旦事件发生,Initiation Dispathcher首先会分离出一每一个事件,然后调用事件处理器,最后调用相关的回调方法来处理这些事件。
客户端连接到日志服务器所经过的一系列步骤如下图所示:
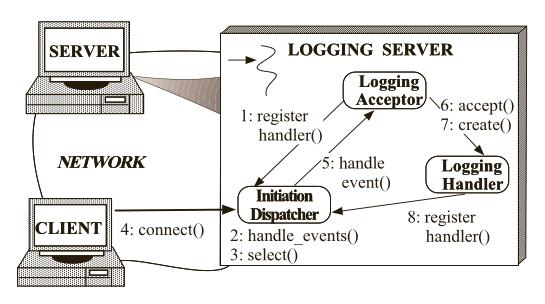
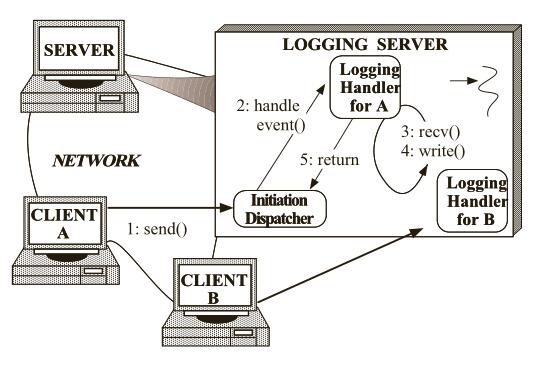
日志服务器记录日志所经过的一系列步骤如下图所示:
3.如何使用Reactor模式
在网络服务和分布式对象中,对于网络中的某一个请求处理,我们比较关注的内容大致为
Read request : 读请求
Decode request :解码
Process service :系统里的业务处理
Encode reply :编码
Send reply : 响应
我们来看传统的数据传输方式:一个客户端连接服务器端,服务器端 就会生成一个线程去做相对应IO操作以及业务逻辑处理。

传统的数据传输方式有什么问题呢?每一个客户端会连接服务端就会产生一个线程,如果10万个客户端那么就会产生10万个线程,而每个服务端的CPU和内存资源是有限的,并且线程的切换会耗费CPU资源,而且这种模型由于IO在阻塞时会一直等待,因此在用户负载增加时,性能下降的非常快。 我们来看相关模式的代码:
class Server implements Runnable { public void run() { try { ServerSocket ss = new ServerSocket(PORT); while (!Thread.interrupted()) new Thread(new Handler(ss.accept())).start(); //创建新线程来handle // or, single-threaded, or a thread pool } catch (IOException ex) { /* ... */ } } static class Handler implements Runnable { final Socket socket; Handler(Socket s) { socket = s; } public void run() { try { byte[] input = new byte[MAX_INPUT]; socket.getInputStream().read(input); byte[] output = process(input); socket.getOutputStream().write(output); } catch (IOException ex) { /* ... */ } } private byte[] process(byte[] cmd) { /* ... */ } } }
基础Reacotor 版本:

对比原有的方式进行了改进,客户端不变服务器端会有一个Reactor线程对象,它去检测监听客户端向服务器发起的连接,当连接建立好后或触发相应的事件之后,Reactor会通过派发给特定的处理器,也就是说由一个不断等待和循环的单独进程(线程)来做这件事,它接受所有handler的注册,并负责先操作系统查询IO是否就绪,在就绪后就调用指定handler进行处理。
这里补充一下NIO相关的支持:
Channel 通道 :它就像自来水管道一样,网络数据通过channle读取和写入,支持非阻塞的读。
Buffer : 缓冲区,可以被Channel 直接读写
Selectors:选择器,用来检查Channel 上IO事件的产生
SelectionKeys: 维护IO事件的状态和绑定信息
我们来看相关模式的代码:
class Reactor implements Runnable { final Selector selector; final ServerSocketChannel serverSocket; Reactor(int port) throws IOException { //Reactor初始化 selector = Selector.open(); serverSocket = ServerSocketChannel.open(); serverSocket.socket().bind(new InetSocketAddress(port)); serverSocket.configureBlocking(false); //非阻塞 SelectionKey sk = serverSocket.register(selector, SelectionKey.OP_ACCEPT); //分步处理,第一步,接收accept事件 sk.attach(new Acceptor()); //attach callback object, Acceptor } public void run() { try { while (!Thread.interrupted()) { selector.select(); Set selected = selector.selectedKeys(); Iterator it = selected.iterator(); while (it.hasNext()) dispatch((SelectionKey)(it.next()); //Reactor负责dispatch收到的事件 selected.clear(); } } catch (IOException ex) { /* ... */ } } void dispatch(SelectionKey k) { Runnable r = (Runnable)(k.attachment()); //调用之前注册的callback对象 if (r != null) r.run(); } class Acceptor implements Runnable { // inner public void run() { try { SocketChannel c = serverSocket.accept(); if (c != null) new Handler(selector, c); } catch(IOException ex) { /* ... */ } } } } final class Handler implements Runnable { final SocketChannel socket; final SelectionKey sk; ByteBuffer input = ByteBuffer.allocate(MAXIN); ByteBuffer output = ByteBuffer.allocate(MAXOUT); static final int READING = 0, SENDING = 1; int state = READING; Handler(Selector sel, SocketChannel c) throws IOException { socket = c; c.configureBlocking(false); // Optionally try first read now sk = socket.register(sel, 0); sk.attach(this); //将Handler作为callback对象 sk.interestOps(SelectionKey.OP_READ); //第二步,接收Read事件 sel.wakeup(); } boolean inputIsComplete() { /* ... */ } boolean outputIsComplete() { /* ... */ } void process() { /* ... */ } public void run() { try { if (state == READING) read(); else if (state == SENDING) send(); } catch (IOException ex) { /* ... */ } } void read() throws IOException { socket.read(input); if (inputIsComplete()) { process(); state = SENDING; // Normally also do first write now sk.interestOps(SelectionKey.OP_WRITE); //第三步,接收write事件 } } void send() throws IOException { socket.write(output); if (outputIsComplete()) sk.cancel(); //write完就结束了, 关闭select key } } //上面 的实现用Handler来同时处理Read和Write事件, 所以里面出现状态判断//我们可以用State-Object pattern来更优雅的实现class Handler { // ... public void run() { // initial state is reader socket.read(input); if (inputIsComplete()) { process(); sk.attach(new Sender()); //状态迁移, Read后变成write, 用Sender作为新的callback对象 sk.interest(SelectionKey.OP_WRITE); sk.selector().wakeup(); } } class Sender implements Runnable { public void run(){ // ... socket.write(output); if (outputIsComplete()) sk.cancel(); } } }
使用多个Reacotrs以及多线程版本:
相对基础Reactor版本,Reactor进行分发后的业务操作处理显然没有 Reactor处理的快,因为reactor主要作用是接收,主要的是后续的业务操作,如果大量的业务操作处理的很慢会拖累Reactor分发的速度,这样我们就将业务操作交给非IO操作的线程池去处理。
4.总结一下Reator 模式的优缺点:

1.占用更少的资源 这种方式并不需要对每个客户端产生一个线程。
2.它的成本更低,因为线程少了,上下文切换就少了
3.相比传统的简单模型,Reactor增加了一定的复杂性,因而有一定的门槛,并且不易于调试















 461
461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









