







1.大小端的存储介绍
当我们使用编译器观察内存的时候,经常会发现我们预期中储存的数据和我们真正在内存中储存的数据刚好反过来。
举个例子:定义一个int a=10,在内存中存储的数据预期是0000 0000 0000 0000 0000 0000 0000 1010转换成十六进制也就是00 00 00 0a,但是当我们通过监视窗口观察内存情况的时候就会发现实际情况是0a 00 00 00

这里就涉及到了我们内存存储的大小端概念了。那么什么是大小端呢?
相信大家对于内存中数据的高地址和低地址都不陌生,在系统中数据是根据地址在内存中存储的,由于内存在计算机中是连续排列的,如下图(也可以是竖着排列,横着表示所占篇幅较小)我们可以知道地址编号较小的就是低地址,编号较高的就是高地址,系统的编号仅仅代表着一个位置,其真实存储数据的形式如下:


(数据的低位也就是从右向左代表十进制的数值,数值越大位越高,如下图所示)

大端存储是指将数据的低位保存在内存的高地址中,而数据的高位保存在内存的低地址中。而小端存储刚好相反,是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中。
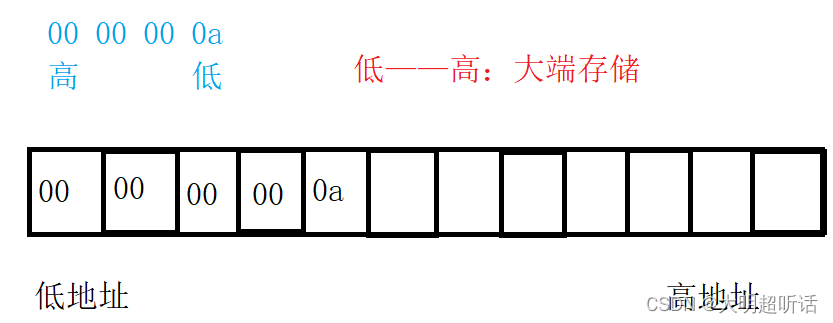
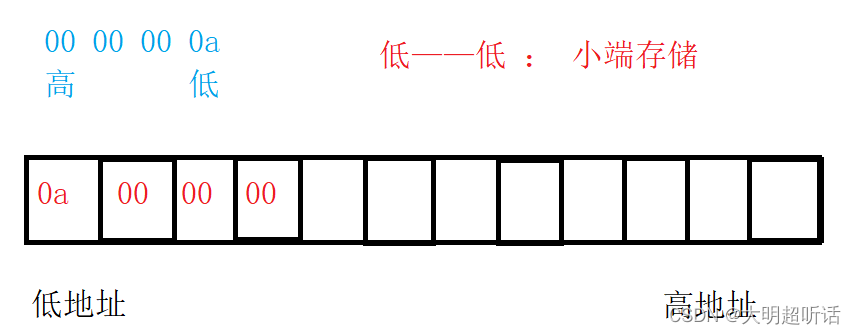
就像上面我们举的例子一样,也可以简便记忆:相同(低低)就是小端存储,不相同(低高)就是大端存储。那么我们该怎样判断我们的编译器采用的是大端存储还是小端存储呢?观察法是不是太low了?能不能用程序来测试大小端呢?那么接下来我们就来回答我们的疑惑。
2.指针强转验证大小端
相信大家对指针都不陌生,指针类型决定了指针进行解引用操作的时候一次性访问几个字节,那么我们就可以利用这个特性进行大小端的验证。
首先我们需要创建一个整型变量,由于我们的整形变量的大小是四个字节,我们要判断大小端存储,只需要第一个字节中的数据就可以看出来,比如我们上面举例中的:第一个字节是00就是大端存储,第一个字节是0a就是小端存储。我们的字符型指针的大小刚好为一个字节,我们就可以利用指针强转进行内存大小端的验证。那么接下来我们就把我们的想法直接写成代码的形式。

#include<stdio.h>
int main()
{
int a = 10;
int* pa = &a; //创建一个整形指针进行有序存储进入内存之中
char* pc = (char*)pa; //将整形指针强转为字符型指针便于拿出第一个字节中的数据
int n = *pc;
printf("%d", n); //将第一个字节中的数据打印出来进行判断大小端
return 0;
}上面就是我们判断大小端的方法之一,是不是感觉收获到了不少?别着急,正题还在后面呢。
3.联合体的介绍
首先我们需要先介绍一下联合体的概念,所谓的联合体跟我们的结构体有一点相似,都是一堆不同形式数据的集合,但是不同的是我们联合体的内存是公用的,就一个例子:

#include<stdio.h>
//创建一个联合体求联合体的大小来论证结构体共用内存的含义
union exp
{
char c ;
int n = 10;
};
int main()
{
int ret = sizeof(exp);
printf("%d", ret);
return 0;
}我们可以发现上面的联合体里面有一个字符和一个一个整型,按道理来说最少也要有5个字节可是我们sizeof计算出来的结果却是4个字节,这其中的原因就是联合体会共用内存进行储存数据。

所以对于我们的联合体是一把双刃剑,用的好可以节省系统的内存空间,用的不好会使我们的内存储存一塌糊涂。我们刚好可以利用联合体的这个特性来进行我们大小端的判断。
4.利用联合体判断大小端
我们可以由上面联合体共用内存的特性可以设计我们的程序,对我们联合体中的整形数据进行赋初值,之后拿出我们联合体中的char元素,所以我们拿出的就是我们需要判断的第一个字节。

#include<stdio.h>
union exp
{
char c ;
int n = 10;
}a1;
int main()
{
printf("%d", a1.c);
return 0;
}上面就是我们的实验效果,和我们之前的猜想一样首字节储存数据为10,说明我们数据的存储是低低——小端存储。
此上就是我们本次博客的全部内容了,是不是对自己的编译器的存储方式很好奇?快去试一试吧!看看自己的编译器到底用的是小端存储还是大端存储吧!祝您天天开心,回见。
















 2726
2726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











