







如何快速从10亿数据中判断元素是否存在
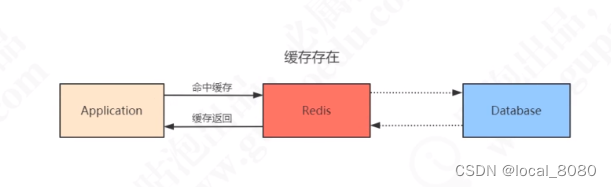
此时,如果出现大量访问redis中不存在的数据时,访问量就会去访问数据库,这时,可能会导致数据库连接池不支持那么多的连接而出现JDBC连接失败的问题

我们首先想到的就是布隆过滤器,布隆过滤器的原理是什么呢?
布隆过滤器的底层逻辑其实就是讲数据库里缓存的字段信息加载到布隆过滤器中进行预热判断
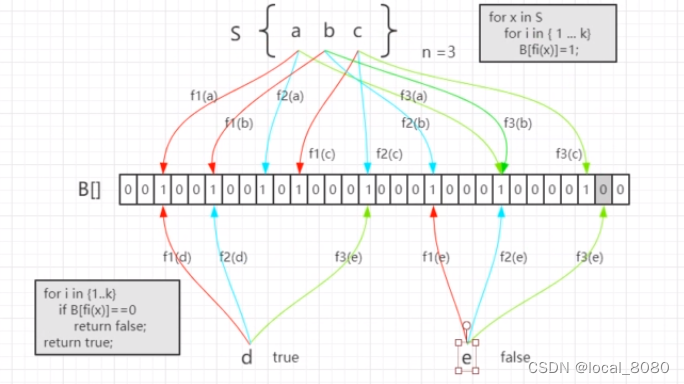
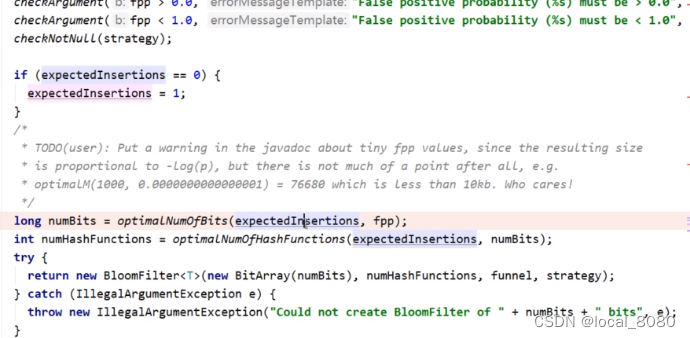
因为布隆过滤器会有一定的误差(因为是通过多次的hash值判断是否存在元素,但是也会有元素不存在,但是hash值与存在元素相同的情况),因此,布隆过滤器会通过设置误差值来自定义需要几次的hash(误差值>0),但是也会存在误差
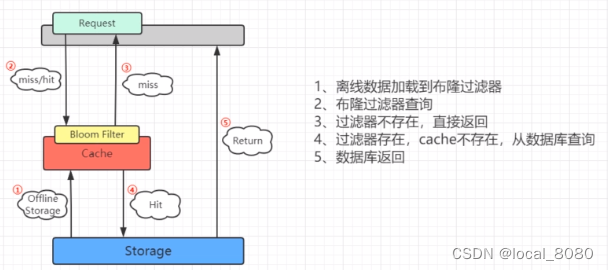
因此,当布隆过滤器返回的值为不存在时,此时,数据库里的值是肯定不存在的,也没有去查redis缓存或者数据库的必要;当布隆过滤器查询的值为存在时,此时,数据库里可能存在这个值,也可能不存在,但是这个误差是在设置的误差范围上下,默认的误差是0.3,此时可以去访问缓存和数据库,这样也就不会造成大面积的线程访问数据库。
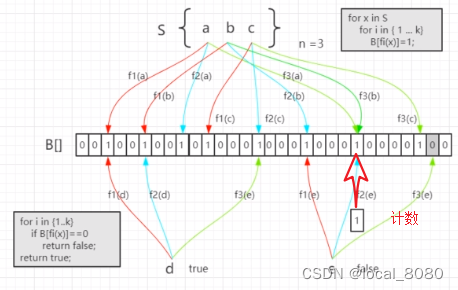
原本的布隆过滤器是不支持删除操作的,因为一旦删除,就会影响到其他的hash值出现问题,造成数据不存在的现象,因此,后期又有了带计数的布隆过滤器,就是在hash值的基础上,加上了计数,缓存的时候,出现相同的hash值,就会在所在的位置计数器上+1,在删除时,再在计数器上-1,这样就不会造成误删操作了。
源码:
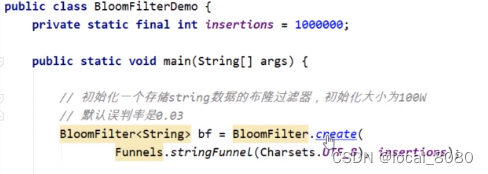

还是回到开始的那个问题,在10亿数据中判断是否存在
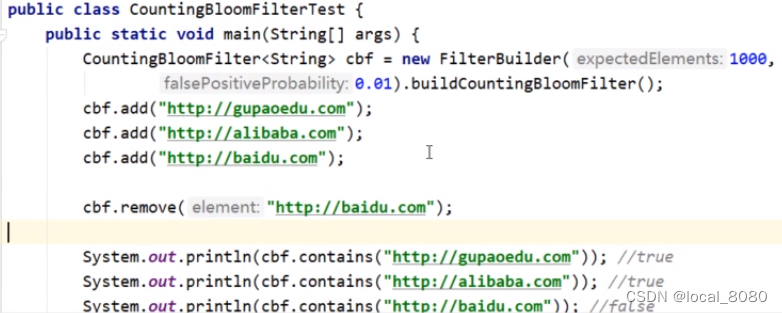















 4741
4741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









