









Grep 命令的介绍
grep 这个命令是一个全局查找正则表达式并且打印结果行的命令。它的输入是一个文件或者是一个标准输入(stdin),或者是一个“-”连字符(),???待查阅后解释。它的输出一般是打印在屏幕上。grep 家族里还有 egrep 和 fgrep 这两个命令,
Grep 是如何工作的
grep命令在一个或多个文件中查找某个字符模式。如果这个模式中包含空格,就必须用引号把它括起来。grep命令中,模式可以是一个被引号括括起来的字符串,也可以是单个词,位于模式之后所有的单词都被视为文件名。grep将输出发送到屏幕,它不会对输入文件进行任何修改或变化,下面我们以一个命令来说明。
命令格式
grep [选项] 模式 [文件....]
案例 1:
[root@Practice_Server ~]# grep root /etc/passwd``root:x:0:0:root:/root:/bin/bash``operator:x:11:0:operator:/root:/sbin/nologin
说明
grep 将在文件中查找/etc/passwd 中查找模式 Tom。如果查找成功,文件中相应行会显示在屏幕上,如果没有找到指定的模式,就不会有任何输出,如果指定的文件不是一个合法的文件,屏幕上就会显示报错信息。如果发现了要查找的模式,grep 就返回退出状态 0,表示成功,如果没找到,返回的退出状态为 1,而找不到指定文件时,退出状态将是 2。
grep 的程序输入可以来自标准输入或管道,而不仅仅是文件。如果忘了指定文件,grep会以为你要它从标准输入(即键盘)获取输入,于是停下来等你键入一些字符。如果输入来自管道,就会有另一条命令的输出通过管道变成 grep 命令的输入,如果匹配到要查找的模式,grep 会把输出打印在屏幕上。
案例 2:
[root@Practice_Server ~]# ps -ef | grep root
ps 命令的输出被送到 grep,然后所有包含 root 的行都被打印在屏幕上。
正则表达式元字符和选项
元字符也是一种字符,但他表达的含义不同于字符本身的字面含义。例如,**^和$**就是元字符。grep 支持很多正则表达式元字符,以便用户更精确的定义要查找模式。
元字符 | 功能 | 示例 | 示例的匹配对象 |
| ^ | 行首定位符 | /^love/ | 匹配所有以 love 开头的行 |
| $ | 行尾定位符 | /love$/ | 匹配所有以 love 结尾的行 |
| . | 匹配除换行外的单个字符 | /l..e/ | 匹配包含字符 l、后跟两个任意字符、再跟字母e 的行 |
| * | 匹配零个或多个前导字符 | /*love/ | 匹配在零个或多个空格紧跟着模式 love 的行 |
| [] | 匹配指定字符组内任一字符 | /[Ll]ove/ | 匹配包含 love 和 Love 的行 |
| [^] | 匹配不在指定字符组内任一字符 | /[^A-KM-Z]ove/ | 匹配包含 ove,但ove 之前的那个字符不在 A 至K 或M至Z 间的行 |
| \(..\) | 保存已匹配的字符 | ||
| & | 保存查找串以便在替换串中引用 | s/love/**&**/ | 符号&代表查找串。字符串 love将替换前后各加了两个**的引 用,即love 变成**love** |
| \< | 词首定位符 | /\<love/ | 匹配包含以 love 开头的单词的 行 |
| \> | 词尾定位符 | /love\>/ | 匹配包含以 love 结尾的单词的 行 |
| x\{m\} | 连续 m 个 x | /o\{5\}/ | 分别匹配出现连续 5 个字母 o、至少 5 个连续的 o、或 5~10 个连续的 o 的行 |
| x\{m,\} | 至少 m 个 x | /o\{5,\}/ | |
| x\{m,n\} | 至少 m 个 x,但不超过 n 个 x | /o\{5,10\}/ |
grep 选项
grep 选线用于调整执行查找或显示结果的方式。例如通过选线来关闭大小写敏感、要求显示行号,或者只显示报错信息等。
| 选项 | 功能 |
| -E | 如果加这个选项,那么后面的匹配模式就是扩展的正则表达式,也就是 grep -E = egrep |
| -i | 比较字符时忽略大小写区别 |
| -w | 把表达式作为词来查找,相当于正则中的"\<...\>"(...表示你自定义的规则) |
| -x | 被匹配到的内容,正好是整个行,相当于正则"^...$" |
| -v | 取反,也就是输出我们定义模式相反的内容 |
| -c | count.统计,统计匹配结果的行数,主要不是匹配结果的次数,是行数。 |
| -m | 只匹配规定的行数,之后的内容就不在匹配了 |
| -n | 在输出的结果里显示行号,这里要清楚的是这里所谓的行号是该行内容在原 文件中的行号,而不是在输出结果中行号 |
| -o | 只显示匹配内容,grep 默认是显示满足匹配条件的一行,加上这个参数就只 显示匹配结果,比如我们要匹配一个 ip 地址,就只需要结果,而不需要该行 的内容 |
| -R | 递归匹配。如果要在一个目录中多个文件或目录匹配内容,则需要这个参数 |
| -B | 输出满足条件行的前几行,比如 grep -B 3 "aa" file 表示在 file 中输出有 aa 的 行,同时还要输出 aa 的前 3 行 |
| -B | 这个与-B 类似,输出满足条件行的后几行 |
| -C | 这个相当于同时用-B -A,也就是前后都输出 |
使用正则表达式 grep 实例
[root@Practice_Server ~]# cat grep.txt` `northwest NW Charles Main 3.0 .98 3 34``western WE Sharon Gray 5.3 .97 5 23``southwest SW Lewis Dalsass 2.7 .8 2 18``southern SO Suan Chin 5.1 .95 4 15``southeast SE Patricia Hemenway 4.0 .7 4 17``eastern EA TB Savage 4.4 .84 5 20``northeast NE AM Main Jr. 5.1 .94 3 13``north NO Margot Weber 4.5 .89 5 9``central CT Ann Stephens 5.7 .94 5 13
案例 1:
[root@Practice_Server ~]# grep NW grep.txt``northwest NW Charles Main 3.0 .98 3 34
说明:
打印文件 grep.txt 文件包含正则表达式 NW 的行
案例 2:
[root@Practice_Server ~]# grep ^n grep.txt``northwest NW Charles Main 3.0 .98 3 34``northeast NE AM Main Jr. 5.1 .94 3 13``north NO Margot Weber 4.5 .89 5 9
说明:
打印以字母 n 开头的行,(^)行首定位符
案例 3:
[root@Practice_Server ~]# grep "4$" grep.txt``northwest NW Charles Main 3.0 .98 3 34
说明:
打印所有以数字 4 结尾的行。($)行尾定位符
案例 4:
[root@Practice_Server ~]# grep 'TB Savage' grep.txt``eastern EA TB Savage 4.4 .84 5 20
说明:
打印所有包含 TB Savage 的行。如果不用引号(这个例子中,使用单引号或双引号都可以),TB 和 Savage 之间的空格将导致 grep 会在 Savage 和 grep.txt 查找 TB。所以,如果字符串之间有空格,必须要用引号引起来。
案例 5:
[root@Practice_Server ~]# grep '5\..' grep.txt``western WE Sharon Gray 5.3 .97 5 23``southern SO Suan Chin 5.1 .95 4 15``northeast NE AM Main Jr. 5.1 .94 3 13``central CT Ann Stephens 5.7 .94 5 13
说明:
打印所有包含数字 5,后面跟一个.号 再跟一个任意字符的行。(.)号代表单个字符,被**(\)转义后,只代表本身一个.号。**
案例 6:
[root@Practice_Server ~]# grep '^[we]' grep.txt``western WE Sharon Gray 5.3 .97 5 23``eastern EA TB Savage 4.4 .84 5 20
说明:
打印所有字母 w 和 e 开头的行。[]表示任意一个字符都可以匹配。
案例 7:
[root@Practice_Server ~]# grep '[^0-9]' grep.txt``northwest NW Charles Main 3.0 .98 3 34``western WE Sharon Gray 5.3 .97 5 23``southwest SW Lewis Dalsass 2.7 .8 2 18``southern SO Suan Chin 5.1 .95 4 15``southeast SE Patricia Hemenway 4.0 .7 4 17``eastern EA TB Savage 4.4 .84 5 20``northeast NE AM Main Jr. 5.1 .94 3 13``north NO Margot Weber 4.5 .89 5 9``central CT Ann Stephens 5.7 .94 5 13
说明:
打印包含非数字字符的行。由于至少每一行有一个非数字字符,因此说有行都被打印。
案例 8:
[root@Practice_Server ~]# grep '[A-Z][A-Z] [A-Z]' grep.txt``eastern EA TB Savage 4.4 .84 5 20``northeast NE AM Main Jr. 5.1 .94 3 13
说明:
打印了包含两个大写字符、后跟一个空格和一个大写字符的行,例如 TB Savage 和 AM Main Jr。
案例 9:
[root@Practice_Server ~]# grep 'ss* ' grep.txt``northwest NW Charles Main 3.0 .98 3 34``southwest SW Lewis Dalsass 2.7 .8 2 18``central CT Ann Stephens 5.7 .94 5 13
说明:
打印包含一个 s、后跟 0 个或多个连着的 s 和一个空格的文本行。
案例 10:
[root@Practice_Server ~]# grep '[a-z]\{9\}' grep.txt``northwest NW Charles Main 3.0 .98 3 34``southwest SW Lewis Dalsass 2.7 .8 2 18``southeast SE Patricia Hemenway 4.0 .7 4 17``northeast NE AM Main Jr. 5.1 .94 3 13
说明:
**打印所有出现至少 9 个小写字母连在一起的行,例如,northwest,southwest,southeast,**northeast。
案例 11:
[root@Practice_Server ~]# grep '\(3\)\.[0-9].*\1 *\1' grep.txt
说明:
如果某一行包含一个 3 后面跟一个句点和一个数字,再任意多个字符(.*),然后跟一个 3****个或任意多个制表符,再接一个 3,则打印该行。
案例 12:
[root@Practice_Server ~]# grep '\<north\>' grep.txt``north NO Margot Weber 4.5 .89 5 9
说明:
打印所有包含单词 north 的行。“\<”是词首定位符“\>”是词尾定位符。
案例 13:
[root@Practice_Server ~]# grep '\<[a-z].*n\>' grep.txt``northwest NW Charles Main 3.0 .98 3 34``western WE Sharon Gray 5.3 .97 5 23``southern SO Suan Chin 5.1 .95 4 15``eastern EA TB Savage 4.4 .84 5 20``northeast NE AM Main Jr. 5.1 .94 3 13``central CT Ann Stephens 5.7 .94 5 13
说明:
打印所有包含以小写字母开头,以 n 结尾,中间由任意多个字符组成的单词的行。注意****符号.*,他代表任意字符,包括空格。
grep 选项测试案例
测试文件同上面那个
案例 14:
[root@Practice_Server ~]# grep -n 'north' grep.txt``1:northwest NW Charles Main 3.0 .98 3 34``7:northeast NE AM Main Jr. 5.1 .94 3 13``8:north NO Margot Weber 4.5 .89 5 9
说明:
选项-n 在找到指定模式的行前面加上其行号再一并输出。
案例 15:
[root@Practice_Server ~]# grep -i 'pat' grep.txt``southeast SE Patricia Hemenway 4.0 .7 4 17
说明:
选项-i 关闭大小写敏感性。表达式 pat 包含任意大小写的组合都符合。
案例 16:
[root@Practice_Server ~]# grep -v 'Suan Chin' grep.txt``northwest NW Charles Main 3.0 .98 3 34``western WE Sharon Gray 5.3 .97 5 23``southwest SW Lewis Dalsass 2.7 .8 2 18``southeast SE Patricia Hemenway 4.0 .7 4 17``eastern EA TB Savage 4.4 .84 5 20``northeast NE AM Main Jr. 5.1 .94 3 13``north NO Margot Weber 4.5 .89 5 9``central CT Ann Stephens 5.7 .94 5 13
说明:
这个实例中,选项-v 打印所有不含模式 Suan Chin 的行。选项-v 可用来删除输入文件汇中特定的条目。如果真要删除这些条目,就要把 grep 的输出重定向到一个临时文件中,然后把临时文件的名字改成原文件的名字。
注意不能从原文件重定向到原文件,这样会破坏原文件的。
案例 17:
[root@Practice_Server ~]# grep -l 'SE*' sed.txt grep.tx``sed.txt``grep.txt
说明:
选项-l 使 grep 只输出包含模式的文件名,而不输出文本行。
案例 18:
[root@Practice_Server ~]# grep -c 'west' grep.txt``3
说明:
**选项-c 让 grep 打印出含有模式的行的数目。这个数字并不代表模式的出现次数。例如,**即使 west 在某行中出现 3 次,这行也只计一次。
案例 19:
[root@Practice_Server ~]# grep -w 'north' grep.txt``north NO Margot Weber 4.5 .89 5 9
说明:
选项-w只查找作为一个词,而不是词的一部分出现的模式。这条命令只打印包含词north****的行,而不打印那些 northwest、northwest 等中出现的行。
grep 与管道
grep 的输入不一定都是文件,它也常常从管道读取输入。
案例 20:
[root@Practice_Server ~]# ls | grep "grep"``grep.txt``[root@Practice_Server ~]# ls | grep "^gr"``grep.txt
说明:
**ls 的命令的输出通过管道传给 grep。输出结果字母 gr 开头的所有行都被打印出来了,**也就是说,被选中的目录被打印出来了。
egrep 扩展
egrep 在 grep 的基础上增加了更多的元字符。但是 egrep 不允许使用\(\),\{\}.
元字符 | 功能 | 示例 | 示例的匹配对象 |
| ^ | 行首定位符 | /^love/ | 匹配所有以 love 开头的行 |
| $ | 行尾定位符 | /love$/ | 匹配所有以 love 结尾的行 |
| . | 匹配除换行外的单个字符 | /l..e/ | 匹配包含字符 l、后跟两个任 意字符、再跟字母 e 的行 |
| * | 匹配零个或多个前导字符 | /*love/ | 匹配在零个或多个空格紧跟 着模式 love 的行 |
| [] | 匹配指定字符组内任一字符 | /[Ll]ove/ | 匹配包含 love 和 Love 的行 |
| [^] | 匹配不在指定字符组内任一字符 | /[^A-KM-Z]ove/ | 匹配包含 ove,但 ove 之前的那个字符不在 A 至 K 或 M 至 Z |
egrep 新增的元字符 | |||
| + | 匹配一个或多个加号前面的字符 | '[a-z]+ove' | 匹配一个或多个小写字母后 跟 ove 的字符串。move love approve |
| ? | 匹配 0 个或一个前导字符 | 'lo?ve' | 匹配 l 后跟一个或 0 个字母 o以及 ve 的字符串。love lve |
| a|b | 匹配 a 或 b | 'love|hate' | 匹配 love 和 hate 这两个表达 式之一 |
| () | 字符组 | 'love(able|ly)(ov+)' | 匹配 loveable 或 lovely 匹配 ov 的一次或多次出现 |
案例 21:
[root@Practice_Server ~]# egrep "west|north" grep.txt` `northwest NW Charles Main 3.0 .98 3 34``western WE Sharon Gray 5.3 .97 5 23``southwest SW Lewis Dalsass 2.7 .8 2 18``northeast NE AM Main Jr. 5.1 .94 3 13``north NO Margot Weber 4.5 .89 5 9
说明:
grep 不支持“|”这个,egrep 支持“|”,egrep 查到了,包含 west 或者 north 的行。
题外话
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
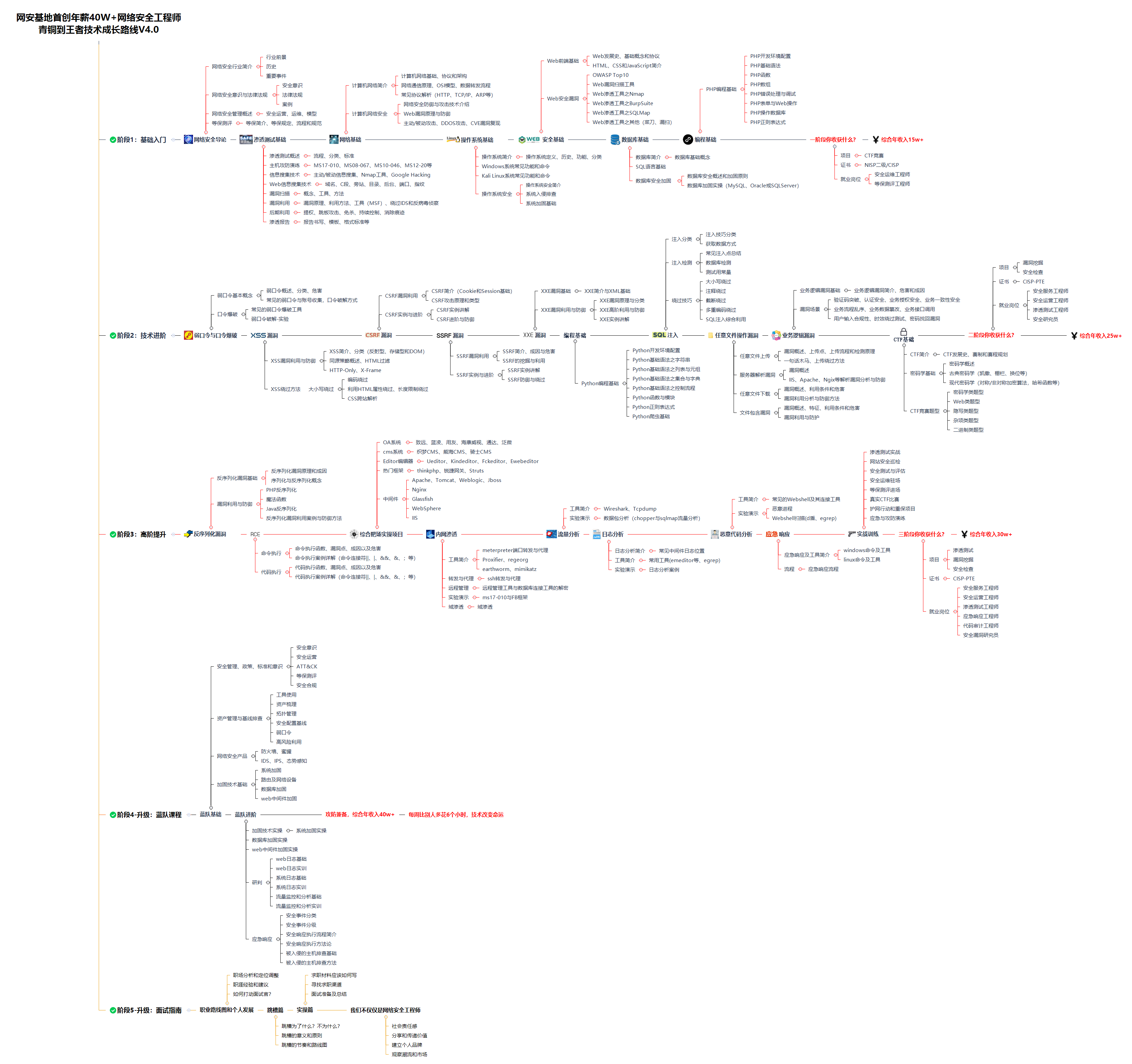
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。
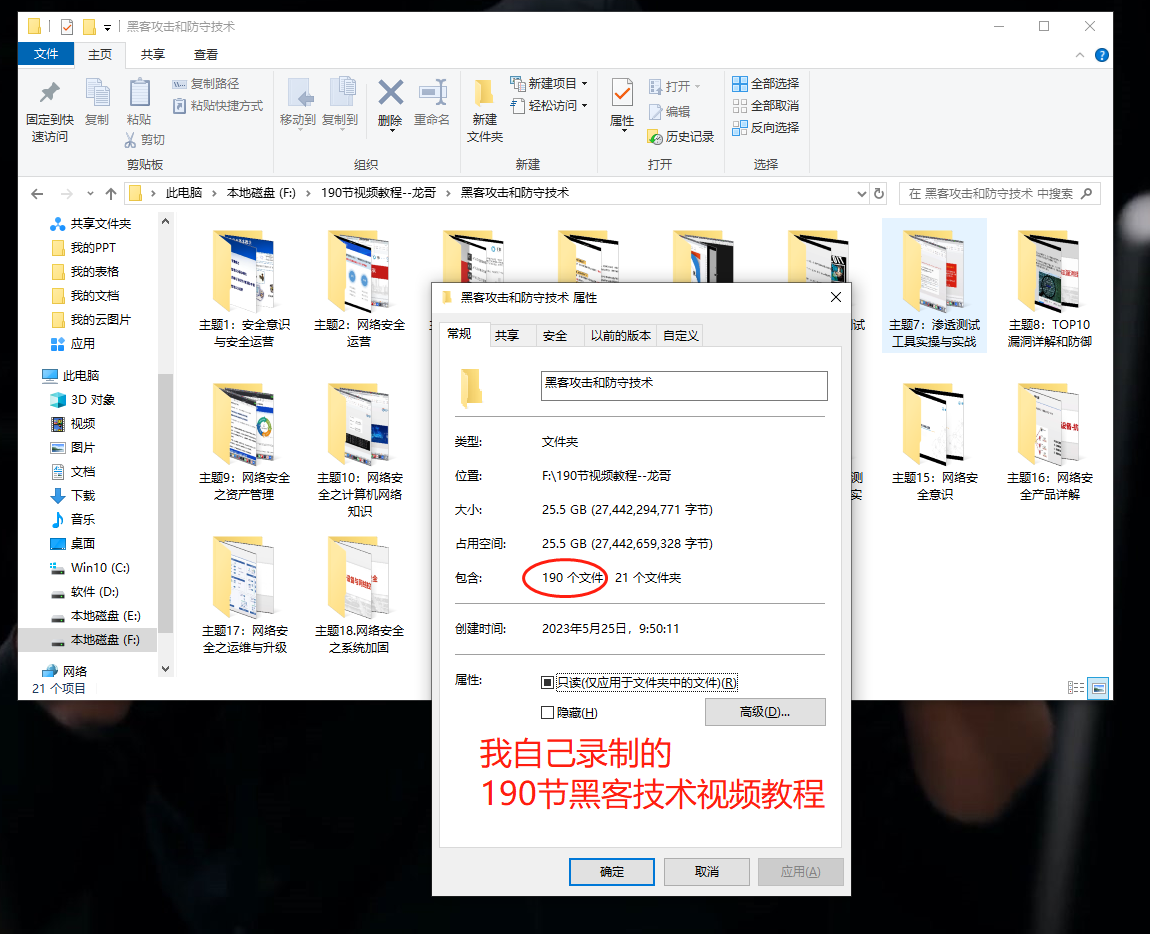
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。

















 306
306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









