







概述
为啥要进行分库分表?
单表数据量太大,比如超过5000w行,查询时扫描的行太多,SQL效率低,CPU出现瓶颈。
数据的切分就是通过某种特定的条件,将存放在同一个数据库或同一个表的数据分散存放到多个数据库(主机)或多个表中,以达到分散单台设备负载的效果,即分库分表。
根据切分规则的类型,可分为:
- 垂直(纵向)切分:根据业务模块或字段来划分出不同的数据库或表。可解决跨页问题,实现应用解耦合;
- 水平(横向)切分:根据表中数据行的业务概念,将同一个表中的数据按照某种条件(一般是日期)拆分到一台或多台数据库(主机)上,可实现冷热隔离。
根据涉及到库和表,又分为:
- 分库:将一个表的数据放到多个数据库实例的多个表;
- 分表:将一个表的数据放到多个表中,多个表还在同一个数据库实例。
垂直分表
比较常见,通俗说法叫做大表拆小表,拆分是基于关系型数据库中的列(字段)进行的。通常,某个表中的字段比较多,可新建立一张扩展表,将不经常使用或长度较大的字段拆分出去放到扩展表中。
字段很多时,拆分开确实更便于开发和维护。某种意义上也能避免跨页问题(MySQL、MS SQL底层都是通过数据页来存储的,跨页可能会造成额外的性能开销)。
拆分字段的操作建议在数据库设计阶段就做好。如果是在发展过程中拆分,则需要改写以前的查询语句,会额外带来一定的成本和风险,建议谨慎。
垂直分库分表
按照业务模块来划分出不同的数据库。数据库由多个表构成,每个表对应不同的业务,垂直切分是指按照业务将表进行分类,将其分布到不同的数据库上,将数据分担到不同的库上(专库专用)。
系统层面的服务化拆分操作,能够解决业务系统层面的耦合和性能瓶颈,有利于系统的扩展维护。与服务的治理和降级机制类似,也能对不同业务类型的数据进行分级管理、维护、监控、扩展等。
数据库往往最容易成为应用系统的瓶颈,而数据库本身属于有状态的,相对于Web和应用服务器来讲,是比较难实现横向扩展的。数据库的连接资源比较宝贵且单机处理能力也有限,在高并发场景下,垂直分库一定程度上能够突破IO、连接数及单机硬件资源的瓶颈,是大型分布式系统中优化数据库架构的重要手段。
把冷热数据分开存放,即冷热分离。冷数据查询较多,更新较少,适合用MyISAM引擎;热数据更新比较频繁,适合使用InnoDB引擎。这也是垂直拆分的一种。
优点:
- 拆分后业务清晰,拆分规则明确;
- 系统之间进行整合或扩展很容易;
- 按照成本、应用的等级、应用的类型等将表放到不同的机器上,便于管理;
- 便于实现动静分离、冷热分离的数据库表的设计模式;
- 数据维护简单。
缺点:
- 部分业务表无法Join关联,只能通过接口方式解决,提高系统的复杂度;
- 受每种业务的不同限制,存在单库性能瓶颈,不易进行数据扩展和提升性能;
- 事务处理复杂。
水平分表
也叫横向分表,Scale Out,将表中不同的数据行按照一定规律分布到不同的数据库表中(在同一个数据库中),降低单表数据量,优化查询性能。最常见的方式就是通过主键或时间等字段进行Hash和取模后拆分。
水平分表,能够降低单表的数据量,可缓解查询性能瓶颈。但本质上这些表还保存在同一个库中,库级别还是会有IO瓶颈及响应慢的问题。分表未分库的优势是没有分布式事务问题,也方便运维管理。
水平分库分表
拆分出来的表保存在不同的数据库中。
某种意义上来讲,有些系统中使用的冷热数据分离(将一些使用较少的历史数据迁移到其他的数据库中。而在业务功能上,通常默认只提供热点数据的查询)。在高并发和海量数据的场景下,分库分表能够有效缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源的瓶颈。投入的硬件成本也会更高。同时,这也会带来一些复杂的技术问题和挑战(跨分片的复杂查询,跨分片事务等)。
问题
垂直分库带来跨库Join问题
拆分后,数据库可能会分布在不同实例和主机上,Join将变得非常麻烦。另外,基于架构规范,性能,安全性等因素考虑,一般是禁止跨库Join的。
几种解决思路:
-
全局表
所谓全局表,就是有可能系统中所有模块都可能会依赖到的一些表。类似于数据字典。为了避免跨库Join查询,可将这类表在其他每个数据库中均保存一份。同时,这类数据通常也很少发生修改(甚至几乎不会),所以也不用太担心一致性问题。 -
字段冗余
反范式设计,通常是为了性能来避免Join查询。空间换时间。但其适用场景也比较有限,比较适合依赖字段较少的情况。数据一致性问题,可借助数据库中的触发器或在业务代码层面去保证。当然也需要结合实际业务场景来看一致性的要求。 -
数据同步
定时A库中的tab_a表和B库中tbl_b有关联,可定时将指定的表做同步。当然,同步本来会对数据库带来一定影响,需要在性能影响和数据时效性中取得一个平衡。这样来避免复杂的跨库查询,如ETL工具。 -
系统层组装
在系统层面,通过调用不同模块的组件或服务,获取到数据并进行字段拼装。实践起来不简单,尤其是数据库设计上存在问题但又无法轻易调整时。
一般用最后一种方式。通过RPC或REST方式,批量或单独请求其他多个服务的多个接口,拿到响应后组装数据。节点间的网络通讯可能会是性能瓶颈,所以需要高效的序列化协议,且调用接口时尽可能只返回需要的数据,而不是把这个表PO实体类全部字段信息返回。
分库带来分布式事务问题
当然分库分表之前,对于SOA或微服务也同样存在分布式事务难题。这是一个很大的话题,可参考分布式事务理论。
不停机分库分表迁移
基于水平分库分表,拆分策略为常用的hash法。
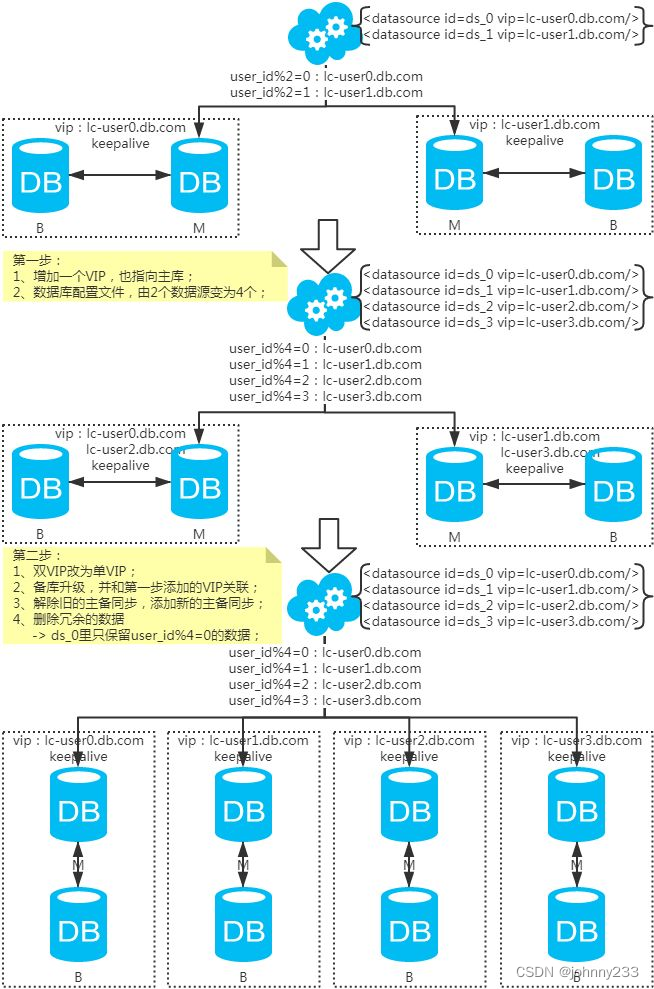
水平扩容库(升级从库法)
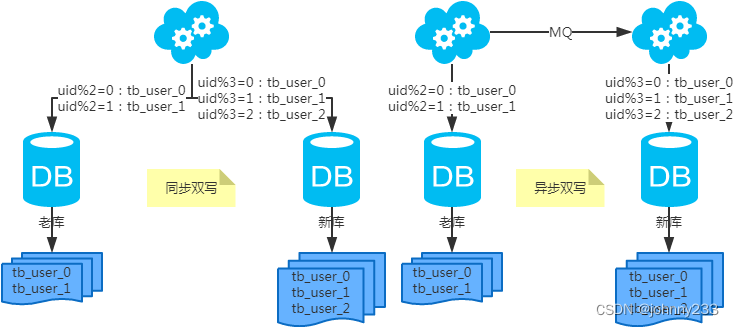
水平扩容表(双写迁移法)
分片
Sharding。为了切分,可能会出现冗余字段,用作区分字段或叫做分库的标记字段。水平切分时,涉及到查询时的路由和落数据时的分片维度
- 路由
在设计表时需要确定对表按照什么样的规则进行分库分表。针对输入的请求,通过分库分表规则查找到对应的表和库的过程叫作路由。 - 分片维度
对数据切片有不同的切片维度,可参考Mycat提供的切片方式,最常用的两种:
哈希切片
对数据的某个字段求哈希,再除以分片总数后取模,取模后相同的数据为一个分片。
按照哈希分片常应用于数据没有时效性的情况,比如所有数据无论是在什么时间产生的,都需要进行处理或查询。
好处:数据切片比较均匀,对数据压力分散的效果较好;缺点是数据分散后,对于查询需求需要进行聚合处理,数据迁移麻烦。
时间切片
按照时间的范围将数据分布到不同的分片上的,如可将交易数据按照月进行切片,或按季度进行切片,由交易数据的数量级来决定按照什么样的时间周期对数据进行切片。
这种切片方式适用于有明显时间特点的数据。通过按照时间进行切片,针对不同的访问频率使用不同档次的硬件资源来节省成本。
优势:数据迁移方便;
缺点:数据分布不均匀。
可结合使用这两种分片方式,如:对交易数据先按照季度进行切片,然后对于某一季度的数据按照主键哈希进行切片。
实战
步骤
根据容量(当前容量和增长量)评估分库或分表个数->选key(均匀)->分表规则(hash或range等)->执行(一般双写)->扩容问题(尽量减少数据移动)。
工具
针对分库分表的需求,有不少优秀的开源中间件框架(工具)。
中间件的形态可简单理解为3种:
- SDK:通过依赖的形式引入代码,比如ShardingSphere;性能最好,但和语言强耦合;
- Proxy:独立部署,对于所有业务方来说,就像一个普通的数据库,业务方的查询发送过去后,就会执行分库分表进行路由转发,执行实际的查询,再把查询结果返回给业务方。ShardingSphere也支持这种形态。性能最差,所有数据库查询都发送给它,容易成功性能瓶颈。优点是跟编程语言无关
- Sidecar:目前并没有非常成熟的产品,比较偏理论上的概念,指一个独立组件,为应用程序提供分库分表功能。Sidecar作为应用程序的伴随服务运行,类似于服务网格中的Sidecar容器,与应用程序实例部署在一起,但作为独立的进程运行。
mybatis-mate
MyBatisPlus提供的企业级模块:
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-mate-starter</artifactId>
</dependency>
ShardingSphere
前身是Sharding-JDBC,定位为轻量级Java框架,在JDBC层提供额外服务。使用客户端直连数据库,以Jar包形式提供服务,无需额外部署和依赖,增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
</dependency>
配置分库分表策略application.properties:
# 数据源
sharding.jdbc.datasource.names=db0,db1,db2
# 库1
sharding.jdbc.datasource.db0.type=com.zaxxer.hikari.HikariDataSource
sharding.jdbc.datasource.db0.driver-class-name=com.mysql.cj.jdbc.Driver
sharding.jdbc.datasource.db0.jdbc-url=jdbc:mysql://localhost:3306/db0?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC
sharding.jdbc.datasource.db0.username=root
sharding.jdbc.datasource.db0.password=root
# 库2
sharding.jdbc.datasource.db1.type=com.zaxxer.hikari.HikariDataSource
sharding.jdbc.datasource.db1.driver-class-name=com.mysql.cj.jdbc.Driver
sharding.jdbc.datasource.db1.jdbc-url=jdbc:mysql://localhost:3306/db1?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC
sharding.jdbc.datasource.db1.username=root
sharding.jdbc.datasource.db1.password=Aa123456
# 库3
sharding.jdbc.datasource.db2.type=com.zaxxer.hikari.HikariDataSource
sharding.jdbc.datasource.db2.driver-class-name=com.mysql.cj.jdbc.Driver
sharding.jdbc.datasource.db2.jdbc-url=jdbc:mysql://localhost:3306/db2?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC
sharding.jdbc.datasource.db2.username=root
sharding.jdbc.datasource.db2.password=Aa123456
# 水平拆分的数据库(表) 配置分库 + 分表策略 行表达式分片策略
# 分库策略
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=db$->{id % 3}
# 分表策略,book逻辑表,主要取决于id行
sharding.jdbc.config.sharding.tables.book.actual-data-nodes=db$->{0..2}.book_$->{0..2}
sharding.jdbc.config.sharding.tables.book.table-strategy.inline.sharding-column=count
# 分片算法表达式
sharding.jdbc.config.sharding.tables.book.table-strategy.inline.algorithm-expression=book_$->{count % 3}
# 主键 UUID 18位数 如果是分布式还要进行一个设置,防止主键重复
#sharding.jdbc.config.sharding.tables.user.key-generator-column-name=id
spring.main.allow-bean-definition-overriding=true
# 打印执行语句
sharding.jdbc.config.props.sql.show=true
# 读写隔离配置
# 配置默认数据源ds1主要用于写
spring.shardingsphere.sharding.default-data-source-name=ds1
# 配置主从名称
spring.shardingsphere.masterslave.name=ms
# 置主库master负责写
spring.shardingsphere.masterslave.master-data-source-name=ds1
# 配置从库slave
spring.shardingsphere.masterslave.slave-data-source-names=ds2,ds3
# 配置slave节点的负载均衡均衡策略,采用轮询机制
spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin
# 整合mybatis的配置
mybatis.type-aliases-package=com.ppdai.shardingjdbc.entity
# 读写分离
sharding.jdbc.datasource.dsmaster=
建表脚本
分片规则配置
Sharding-JDBC的分片逻辑非常灵活,支持分片策略自定义、复数分片键、多运算符分片等功能
SQL路由
SQL路由是根据分片规则配置,将SQL定位至真正的数据源。主要分为单表路由、Binding表路由和笛卡尔积路由。
单表路由最为简单,但路由结果不一定落入唯一库(表),因为支持根据between和in这样的操作符进行分片,所以最终结果仍然可能落入多个库(表)。
Binding表可理解为分库分表规则完全一致的主从表。举例说明:订单表和订单详情表都根据订单ID作为分片键,任意时刻分片逻辑均相同。这样的关联查询和单表查询难度和性能相当。
笛卡尔积查询最为复杂,因为无法根据Binding关系定位分片规则的一致性,所以非Binding表的关联查询需要拆解为笛卡尔积组合执行。查询性能较低,而且数据库连接数较高,需谨慎使用。


















 4221
4221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











