







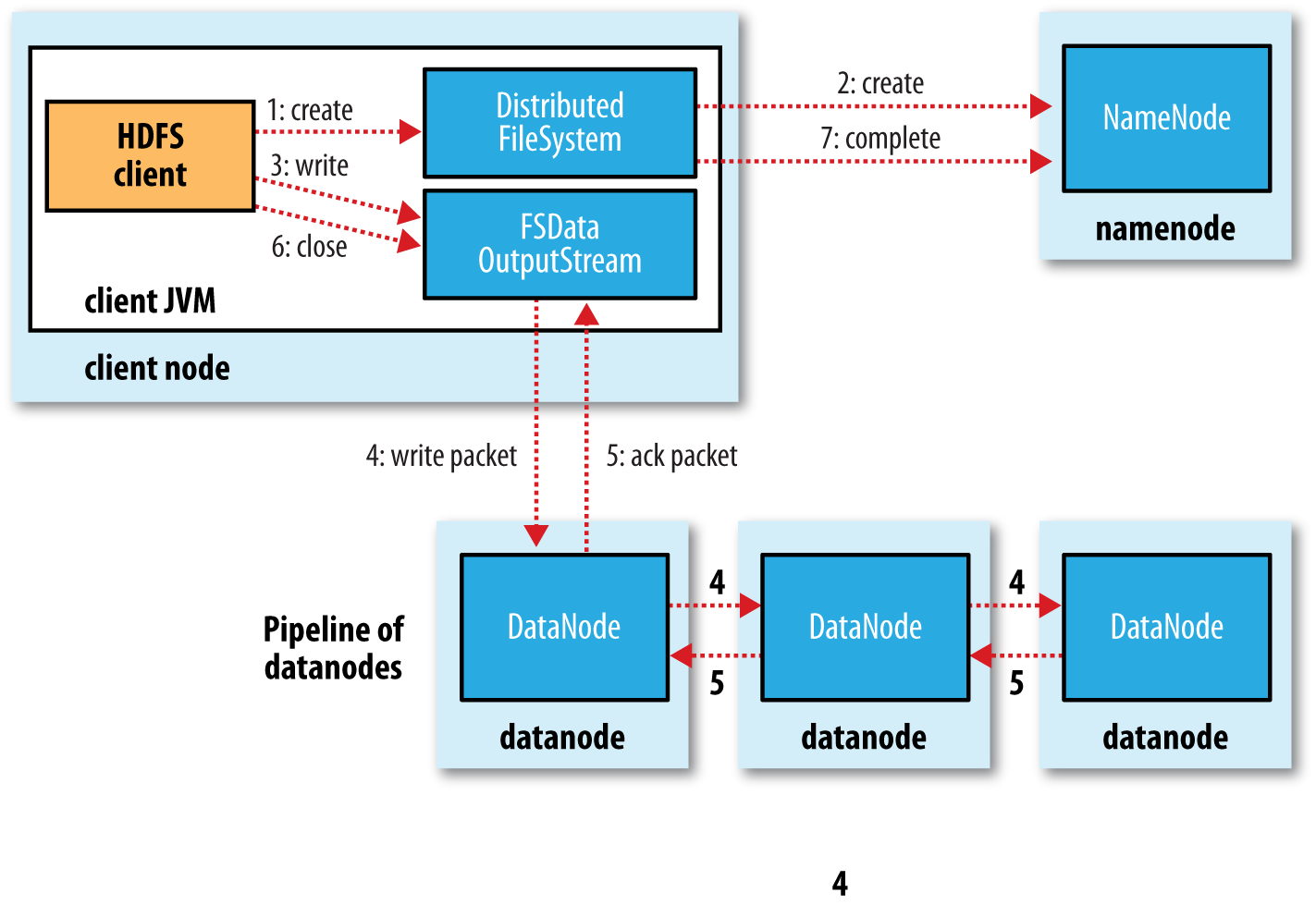
- 客户端调用create()来创建文件
- DistributedFileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件。
- 元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
- DistributedFileSystem返回DFSOutputStream,客户端用于写数据。
- 客户端开始写入数据,DFSOutputStream将数据分成块,写入data queue。
- Data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。
- Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
- DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
当发生问题时:
- 关闭pipeline,将ack queue中的数据块放入data queue的开始(以便失败节点之后的节点不要丢失当前数据块)。
- 通过与NameNode通信, 当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。
- 失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。
- 元数据节点h会检测到此数据块是复制块数不足,将来会再创建第三份备份。
notice:
- 客户端调用create()来创建文件
- DistributedFileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件。
- 元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
- DistributedFileSystem返回DFSOutputStream,客户端用于写数据。
- 客户端开始写入数据,DFSOutputStream将数据分成块,写入data queue。
- Data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。
- Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
- DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
当发生问题时:
- 关闭pipeline,将ack queue中的数据块放入data queue的开始(以便失败节点之后的节点不要丢失当前数据块)。
- 通过与NameNode通信, 当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。
- 失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。
- 元数据节点h会检测到此数据块是复制块数不足,将来会再创建第三份备份。
notice:
It’s possible, but unlikely, for
multiple datanodes to fail while a block is being written.
As long as
dfs.namenode.replication.min replicas (which defaults to 1)
are written,
the write will succeed, and the block will be asynchronously replicated across the cluster
until its target replication factor is reached (
dfs.replication , which defaults to 3).















 1580
1580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









