







给定查询,有关网页的综合排名=网页排名(PageRank)*相关性(TF-IDF)
网页质量
对于一个特定的查询,搜索结果的排名取决于两组信息,关于网页的质量和这个查询与每个网页的相关性信息。
PageRank算法--衡量网页质量
简单说,民主表决。
一个网页被很多其他网页链接,它的认可度高,可靠性高,计算排名时,需要给予较大的权重。
二维矩阵相乘的问题,用迭代方法解决。
Bi=A*Bi-1
B为一维向量,bi标识第n个网页的排名
A为矩阵,amn表示第m个网页指向第n个网页的链接数。
网页排名对于零概率或小概率事件需要进行平滑处理。
利用稀疏矩阵计算技巧简化计算量——>发明了Mapreduce并行计算工具。
http://hi.baidu.com/mshltkiygobbrtq/item/772ac099020562f42916479e
Google 不断的重复计算每个页面的 PageRank。如果您给每个页面一个随机 PageRank 值(非0),那么经过不断的重复计算,这些页面的 PR 值会趋向于正常和稳定。这就是搜索引擎使用它的原因。
这个方程式引入了随机浏览的概念,即有人上网无聊随机打开一些页面,点一些链接。一个页面的PageRank值也影响了它被随机浏览的概率。为了便于理解,这里假设上网者不断点网页上的链接,最终到了一个没有任何链出页面的网页,这时候上网者会随机到另外的网页开始浏览。
为了对那些有链出的页面公平,q = 0.15(q的意义见上文)的算法被用到了所有页面上, 估算页面可能被上网者放入书签的概率。
所以,这个等式如下:
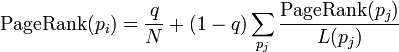
p1,p2,…,pN是被研究的页面,M(pi)是链入pi页面的数量,L(pj)是pj链出页面的数量,而N是所有页面的数量。
PageRank值是一个特殊矩阵中的特征向量。这个特征向量为

R是等式的答案
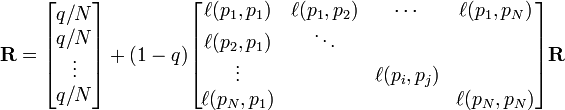
如果pj不链向pi, 而且对每个j都成立时,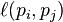 等于 0
等于 0
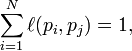
这项技术主要的弊端是,旧的页面等级会比新页面高,因为新页面,即使是非常好的页面,也不会有很多链接,除非他是一个站点的子站点。
这就是 PageRank 需要多项算法结合的原因。PageRank 似乎倾向于维基百科页面,在条目名称的搜索结果中总在大多数或者其他所有页面之前。原因主要是维基百科内相互的链接很多,并且有很多站点链入。
Google 经常处罚恶意提高 PageRank 的行为。Google 究竟怎样区分正常的链接交换和不正常的链接堆积仍然是商业机密。
代码参考如下:
http://blog.csdn.net/midgard/article/details/7061721
确定网页和查询的相关性
搜索关键词权重的科学度量TF-IDF
单文本词频(Term Frequency),关键词次数除以网页总字数。
查询和网页相关性:TF1+TF2……+TFn (n个关键词),缺陷如下:
1、除去停止词(对确定网页主题没有用处):的 和 是……
2、关键词权重:一个词预测主题能力强,权重大。
一个关键词在很少的网页中出现,则容易锁定,权重应该大。
逆文本频率指数(Inverse Document Frequency, IDF): log(D / Dw)
D 为全部网页数,Dw为关键词出现的网页数。
改进后公式:
TF1*IDF1+TF2*IDF2+……+TFn*IDFn















 1182
1182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









