






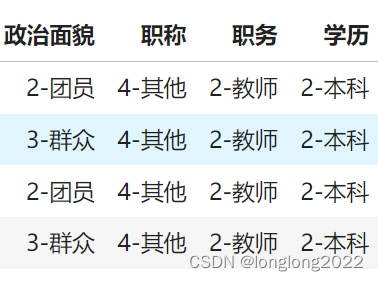
今天遇到这样的一个表格,部分字段如下图,要求统一提取第一个字符(前面还有一列性别,不相邻)
,开始想到了用这种方式实现:
xxb[['性别', '政治面貌', '职称', '职务', '学历']]=xxb[['性别', '政治面貌', '职称', '职务', '学历']].apply(lambda x:x.str[0]),
这样写虽然能实现但是不太美观,想到了最近在学习链式编程,尝试用下面代码,居然成功了!
use_cols=['性别', '政治面貌', '职称', '职务', '学历']
(
xxb
.pipe(lambda x:x.assign(**x.loc[:,use_cols].apply(lambda y:y.str[0])))
)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









